


A follow up on o1's Medical Capabilities + major concern about it's utility in Medical Diagnosis
A conversation about marketing, evals, and AI.

Very quick summary of the email-
I am retracting our earlier statement that OpenAI deliberately cherry-picked the medical diagnostic example to make o1 seem better than it is. After further research- it seems that this is not a case of malice but a mistake caused by extremely lazy evaluations and carelessness.
I also noticed that GPT seems to over-estimate the probability of (and thus over-diagnose) a very rare condition, which is a major flag and must be studied further. This (and its weird probability distributions for diseases) lead me to caution people against using o1 in Medical Diagnosis (unless o1 main is a complete departure from the preview).

In the future, I think any group making claims of great performance on Medical Diagnosis must release their testing outputs on this domain, so that we can evaluate and verify their results more transparently. Lives are literally at stake if we screw up evals. Share more of your testing results, and let the results speak for themselves.
Background
Our most recent post- “Fact-checking the new o1 'Strawberry' for healthcare”- has ballooned beyond anything I was expecting-

As a reminder, the Fact-Checking post pointed out these key ideas-
Running the prompt- making a diagnosis based on a given phenotype profile (a set of phenotypes- the observable characteristics of an organism, resulting from the interaction between its genes and the environment- that are present and excluded)- on ChatGPT o1 leads to inconsistent diagnosis (it does not pick the same diagnosis every time).
This inconsistency is not made very explicit.
Each time o1 picked any diagnosis (whether correct or incorrect)- it would rationalize it’s call very well.
The above three combined are problematic.
To make themselves look better, OAI had specifically cherry picked a run where they got the desired answer and never mentioned the other times. This is very problematic.
For diagnostic purposes, it is better to provide models that provide probability distributions + deep insights so that doctors can make their own call.


This has had led to some very interesting conversations, including one very brief one with OpenAI employee B, who was involved in creating the original question.
Why we weren’t able to recreate the OAI claims
B shared the following: Sergei (our guest author) was not able to reproduce the experiment because Sergei used the o1 preview, while the experiment was created and tested on the main o1 model (which isn’t publicly available). Therefore, this wasn’t a case of cherry-picking but rather an apples-to-oranges comparison (which oranges totally win btw). B did not comment on any of the other points.
Unless I’m given a strong reason not to, I prefer to take people’s words at face-value. So I decided to confirm this for myself and subsequently print a retraction. So I mosied over to the OAI announcement blog, where I saw something interesting. The Blogpost mentions the preview model specifically-

This loops back into our original problem- OAI promotes the performance of it’s model without acknowledging massive limitations. If a doctor was to see this blogpost without prior understanding of GPT’s limitations, they might get swept by the hype and use the preview, leading to a misdiagnosis. While I believe that end users are responsible for using a product safely, I think technical solution providers have a duty to make usersclearly aware of any limitations upfront. When not doing so, the provider should be held responsible for any damages arising from misuse.
But I didn’t want to immediately start pointing fingers and screaming outrage, so I went back to B to get their inputs on what was going on. Here is what I believe happened-
B mentioned that they had tested O1 (main) for the prompt a bunch of times. O1 always had the same outputs (KBG).
This was communicated to the author(s) of the blog post, who didn’t bother rigorously verifying. They likely ran the prompt once or twice, got KBG and assumed that the performance of o1 main translated to the preview (this part is my speculation, B made no such comments).
I wanted to see how easy this would have been to catch, so I decided to run the experiments myself. I fed the same prompt to 10 different instances of o1 (all completely fresh to avoid any context contamination from previous chats).
My Experiments with o1 Preview and one concerning result
The results were interesting-
6 KBG.
4 Floating Harbor Syndrome.
1 Kabuki.
I wanted to see if this pattern would hold up even if I asked o1 for the three most likely diagnoses instead of just one. Interestingly, for the 5 times I ran it, it gave me 5 different distributions with different diseases(KBG the only overlap between the 5). This would line up with our base hypothesis that the writer of the blog post might have been careless in their evals and overestimated the stability of their prediction models. Taking B’s statements, my own experiences with AI Evals being rushed/skipped, and the results of these experiments, I retract my claim that OAI was deliberately misleading and switch to the claim that OAI was negligent in their communications. While it is unlikely, I can see how people acting in good faith can get to this situation. Corners are often cut to please the gods of Rapid Deployment.
I didn’t think I would have to teach OAI folk the importance of cross-validation. Perhaps this article will be useful to them (I do this with my clients, in-case you want a good set of eyes)-

While I was trying to evaluate the outcomes and see if I could learn anything else that was interesting, I spotted something that made me question GPT’s language comprehension. Firstly, while the diseases differed, 4 out of the 5 generations we got had the 70-20-10 split. This could be a complete accident, but if it’s not, I would be very, very hesitant using o1 for any kind of medical diagnosis.
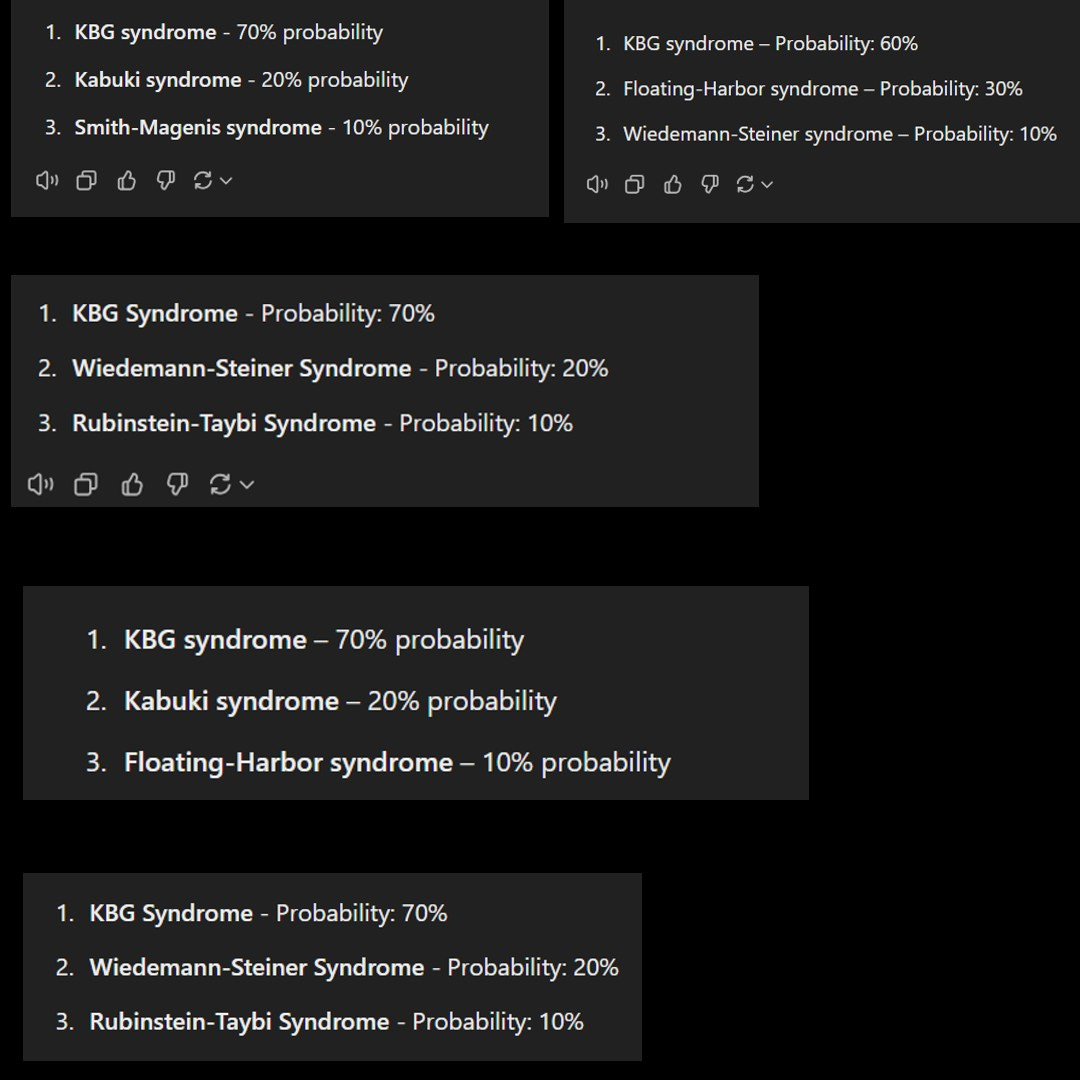
Looking at these probabilities, it’s interesting that the Floating Harbor, which was diagnosed frequently in the individual case, doesn’t show up as frequently over here. So I googled the disease and came across a very interesting piece of information-
Floating–Harbor syndrome, also known as Pelletier–Leisti syndrome, is a rare disease with fewer than 50 cases described in the literature -Wikipedia
Less than 50 cases. Compared to that, o1 is radically overestimating the chance of it happening. Given how rare this disease (the low prior probability), I am naturally suspicious of any system that weighs it this highly (the classic “calculate the probability of cancer” intro to Bayes Theory that I’m sure all of us remember) -

There’s a chance that this phenotype is only there in FHS (a very skewed posterior), but that would invalidate the other outcomes. Either way, these results make me extremely skeptical about the utility of o1 as a good diagnostic tool.
Given the variable nature of the problem (and my lack of expertise in Medicine), there is always going to be more nuance that can be added. This is why I think we should do the following-
OpenAI (and future providers) should be very clear, explicit, and straight in sharing the limitations of their systems when it comes zero-fault fields like Medicine.
Anyone claiming to have a powerful foundation model for these tasks should be sharing their evals (or at least a lot more of them) so that users can spot gaps, understand capabilities, and make more informed decisions. Too many groups use technical complexity as a shield against consumer protection, and that can’t be allowed in these more sensitive fields. If you’re as good as you claim to be, let the results speak for themselves.
To OpenAI: If you think my critique contains mistakes, misrepresented results, or anything else, the floor is yours. I will happily share a rebuttal to my post as long as I think it’s good-faith, high-quality, and meaningfully addresses my concerns.
If you’d like to support our mission to conduct and share independent AI Research, please consider a premium subscription to this newsletter below-
And if you want to talk about these ideas, send me a message below-
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Always fascinating, relevant, and consequential content, Devansh. I believe extreme diligence and accountability are unquestionably in order for these often 'obscure' generative machines, especially in this early, rapid growth and experimental phase of foundation models.
That being said, I also fear the risk of pursuing an abstract ideal benchmark that ignores (rather than measures against) the very flawed reality of human performance.
You mention 'zero-fault fields', but few of these are deterministic or perfectly served by experts - especially when unaided by algorithms. Here's from 'Noise' by Danny Kahneman and Olivier Sibony:
"In medicine, between-person noise, or interrater reliability, is usually measured by the kappa statistic. The higher the kappa, the less noise. A kappa value of 1 reflects perfect agreement; a value of 0 reflects exactly as much agreement as you would expect between monkeys throwing darts onto a list of possible diagnoses. In some domains of medical diagnosis, reliability as measured by this coefficient has been found to be “slight” or “poor,” which means that noise is very high. It is often found to be “fair,” which is of course better but which also indicates significant noise. On the important question of which drug-drug interactions are clinically significant, generalist physicians, reviewing one hundred randomly selected drug-drug interactions, showed “poor agreement.”" ...
“These cases of interpersonal noise dominate the existing research, but there are also findings of occasion noise. Radiologists sometimes offer a different view when assessing the same image again and thus disagree with themselves (albeit less often than they disagree with others).”...
“In short, doctors are significantly more likely to order cancer screenings early in the morning than late in the afternoon. In a large sample, the order rates of breast and colon screening tests were highest at 8 a.m., at 63.7%. They decreased throughout the morning to 48.7% at 11 a.m. They increased to 56.2% at noon—and then decreased to 47.8% at 5 p.m. It follows that patients with appointment times later in the day were less likely to receive guideline-recommended cancer screening.”
Poor diagnostic interrater reliability has been documented in the assessment of heart disease, endometriosis, tuberculosis, melanoma, breast cancer, etc.
Now, please consider that Florida's Surgeon General is telling older Floridians and others at the highest risk from COVID-19 to avoid most booster shots, saying they are potentially dangerous against the professional consensus. What if o-1 issued such a recommendation? (I could quote dozens of such cases in Florida alone; you get the point.)
Again, this is not to suggest we let these models go unchecked, but we should probably adopt the 'Exsupero Ursus ' (outrun the bear) principle and consider their outperformance of the average human a great achievement and starting point.
Please keep up the great work!
Thank you for the follow up Devansh, always interesting.
I'm interested in repeatability and accuracy of the models, they are confident in output instead of giving you different options. My experience when trying to use ML algorithms in engineering is that you receive stares from the classical control and safety disciplines; they would never go something they can't understand. Without a proof behind why a decision was made, any ML/AI model won't be accepted for deploying as a control system (without human in the loop, personally I think even with human it'll be difficult).
I was particularly interested in the approach of AlphaGeometry you covered back in January, a (symbolic) reasoning engine paired with an LLM. I think this approach is more similar to how our brains work in general where we have one (or more) reasoning engine running on what we're seeing, and conscious thought deciding what to do about it (and how to communicate our thoughts where applicable).
From past research projects there are multiple ML algorithms that are accurate with diagnosis in small well trained scopes, a LLM could interrogate as many are applicable at once and aggregate the answer.