

Direction vs Magnitude- What really matters for Learning Rate Schedulers in Deep Learning [Breakdowns]
Direction vs Magnitude- What really matters for Learning Rate Schedulers in Deep Learning [Breakdowns]
Research by Google AI and Princeton university shares some interesting conclusions

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a discount.
p.s. you can learn more about the paid plan here. If your company is looking looking for software/tech consulting- my company is open to helping more clients. We help with everything- from staffing to consulting, all the way to end to website/application development. Message me using LinkedIn, by replying to this email, or on the social media links at the end of the article to discuss your needs and see if you’d be a good match.
Much of an ML model’s learning results depend on the model’s learning rate. The learning rate is a tuning parameter in an optimization algorithm that determines the step size at each iteration while moving toward a minimum of a loss function. Since it influences the extent to which newly acquired information overrides old information, it metaphorically represents the speed at which a machine learning model “learns”.
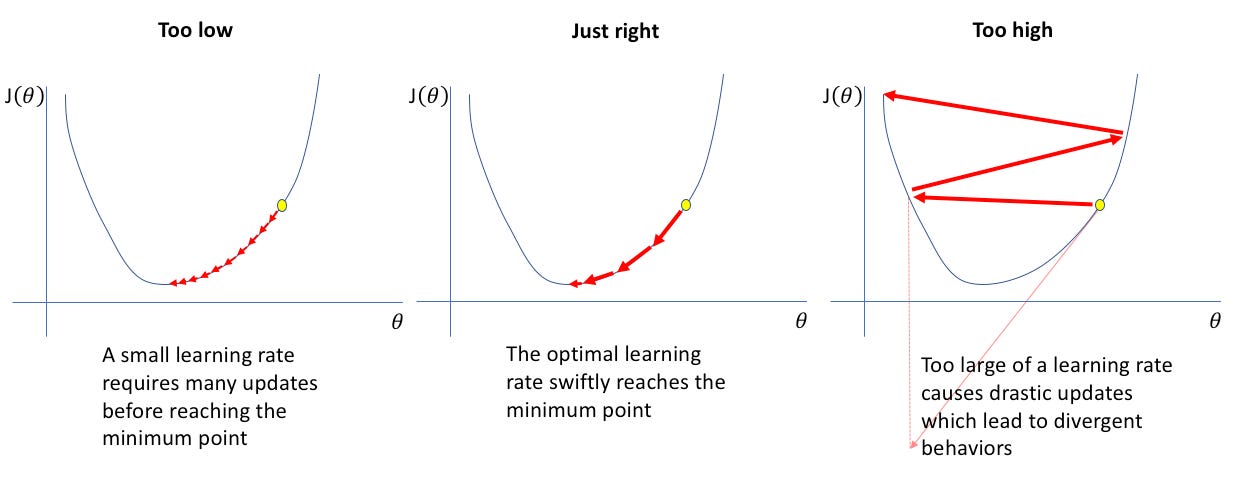
The importance of the Learning Rate can’t be underestimated. That is why there is a lot of research towards both discovering new learning rate schedules (how LR should change over time) and comparing existing ones. Researchers at Google AI, Tel Aviv University, and Princeton collaborated together to write Disentangling Adaptive Gradient Methods from Learning Rates. The paper looks at “how adaptive gradient methods interact with the learning rate schedule.” In this article, we will be going over the paper to answer a very interesting question- when it comes to learning rate, what really makes the difference, the stepsize of your LR or the direction it takes?
Understanding the context
To understand the paper, it is important to understand the basics of the theory they are operating with. Generally, it is assumed that learning rate schedulers like Adam are great because they are able to compute two aspects: the Magnitude and the Direction. Think of the magnitude being the absolute value of the step size, and direction equating to the direction the step is taken in. Remember, since a lot of input data in Machine Learning is high-dimensional, choosing the right direction to traverse is not trivial. The image below is a good overview of second-moment optimizers. Don’t worry if you can’t understand everything, just notice how we are changing the different values based on the gradient we calculate.

The authors in the paper attempt to isolate how important choosing the correct step size is in learning behavior. They do so by proposing a grafting experiment. Instead of taking the magnitude and direction from the same optimizer, we take them from two different optimizers.

Then by comparing the behavior of the grafted optimizers across a variety of tasks, we can check how important the step size is to the overall performance of the model learning. If we see relatively consistent performance across tasks where the magnitude used the same optimizer protocol (despite directions being different), we can conclude that Step Size is most important. And vice versa.
Performance on Computer Vision
To be applicable to Deep Learning as a whole, it is important to test out our grafted schedules on the subfields of AI (especially now that the trend is towards multi-modal architectures). So let’s first look at Computer Vision and how grafted optimizers do with it. “We ran all pairs of grafted optimizers on a 50-layer residual network [HZRS16] with 26M parameters, trained on ImageNet classification [DDS+09]. We used a batch size of 4096, enabled by the large-scale training infrastructure, and a learning rate schedule consisting of a linear warmup and stepwise exponential decay.”
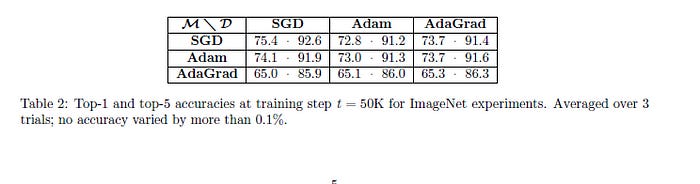
The results are very interesting. We see that the values of each row are relatively consistent (both top-1 and top-5 accuracy) across the rows (step size from the same optimizer). There is quite a bit of variance across the columns (direction from the same optimizer). This leads to a very interesting conclusion. The step size seems to be the dominating factor for model learning behavior. This is articulated by the authors through the statement, “Figure 1 shows at a glance our main empirical observation: that the shapes of the training curves are clustered by the choice of M, the optimizer which supplies the step magnitude.”
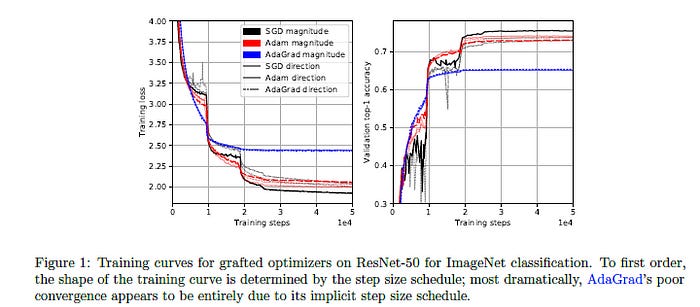
This is interesting enough on its own. But when you think about it, this leads to an interesting application. Imagine a dataset where we have 1 optimizer being worse than another. However, Optimizer 1 is cheaper to run. So we use Optimizer 2 to calculate the step size, and graft that onto 1. This would improve performance on 1 while being cheaper than Optimizer 2. Look at the findings for AdaGrad for a proof of concept of this idea.

For those interested in the implementation of the graft, this is in the appendix. Check it out for a lot of the little configuration/technical details. It will be helpful if you want to implement something similar.
NLP Performance
Next, we move on to natural language processing. According to the authors, “For a realistic large-scale NLP setting, we trained all grafted optimizers on a 6-layer Transformer network [VSP+17] with 375M parameters, on the WMT14 English-French translation task, which has 36.3M sentence pairs. Again, we use a large batch size (384 sequences), enabling very robust training setups. More details can be found in Appendix C.3.” The performance is seen below
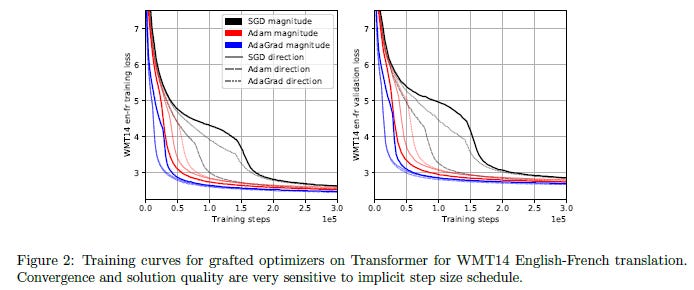
Looking at the table below (conducted over a separate task), we see that once again, the values across the rows are a lot more stable than the values across columns (though this task has a more stable performance overall). This once again implies the idea that magnitude is a stronger factor than direction.
In fact, we see the best result comes from a grafted performer. The authors even highlight this in the paper with their comments, “Interestingly, beyond demonstrating the same clustering of performance metrics by the choice of M, these experiments show that it is possible for a grafted optimizer to outperform both base methods M and D; see Figure 2 for loss curves, and Table 3.3 for the downstream BLEU metric, with which our results are consistent. Again, we are not making claims of categorical superiority under careful tuning, and only the power of bootstrapping; we stress that we did not even tune the global learning rate scalar.”
The combination of the results across both Computer Vision and NLP is pretty convincing to me. It was quite surprising how comprehensively we could show the dominance of the step size. The potential for bootstrapping is also fascinating, and it would be interesting if we could build evaluation protocols to be able to identify the best combinations for a particular problem.
If any of you would like to work on this topic, feel free to reach out to me. If you’re looking for AI Consultancy, Software Engineering implementation, or more- my company, SVAM, helps clients in many ways: application development, strategy consulting, and staffing. Feel free to reach out and share your needs, and we can work something out.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819