


How Facebook and UC Berkley Modernized CNNs to match Transformers [Breakdowns]
With all the insane hype around GPT4, DALLE, PaLM, and many more, now is the perfect time to cover this paper.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Go through the Machine Learning news these days, and you will see Transformers everywhere. And for good reason. Since their introduction, Transformers have taken the world of Deep Learning by storm. While they were traditionally associated with Natural Language Processing, Transformers are now being used in Computer Vision Pipelines too. Just in the last few weeks, we have seen the use of Transformers in some insane applications in Computer Vision. Thus, it seemed like Transformers would replace Convolutional Neural Networks (CNNs) for generic Computer Vision tasks.
Researchers at Facebook AI however have something to add. In their paper, “A ConvNet for the 2020s”, the authors posit that a large part of the reason that Transformers have been outperforming CNNs in Vision-related tasks has been the superior training protocols used by Transformers (which are a newer architecture). Thus, by improving the pipeline around the models, they argue that we can close the performance gap between Transformers and CNNs. In their words,
In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way.
The results are quite interesting, and they show that CNNs can even outperform Transformers in certain tasks. This is more proof that your Deep Learning Pipelines can be improved with better training, rather than simply going for bigger models. In this article, I will cover some interesting findings from their paper. But first some context into Transformers and CNNs and the advantage of each kind of architecture in Computer Vision tasks.
CNNs: The OG Computer Vision Networks
Convolutional Neural Networks have been the OG Computer Vision Architecture since their inception. In fact, the foundations of CNNs are older than I am. CNNs were literally built for vision.
So what’s so good about CNNs? The main idea behind Convolutional Neural Nets is that they go through the image, segment by segment, and extract the main features from it. The earlier layers of the CNN often extract the more crude features, such as edges and colors. However, adding more layers allows for feature extraction at a very high resolution of detail.
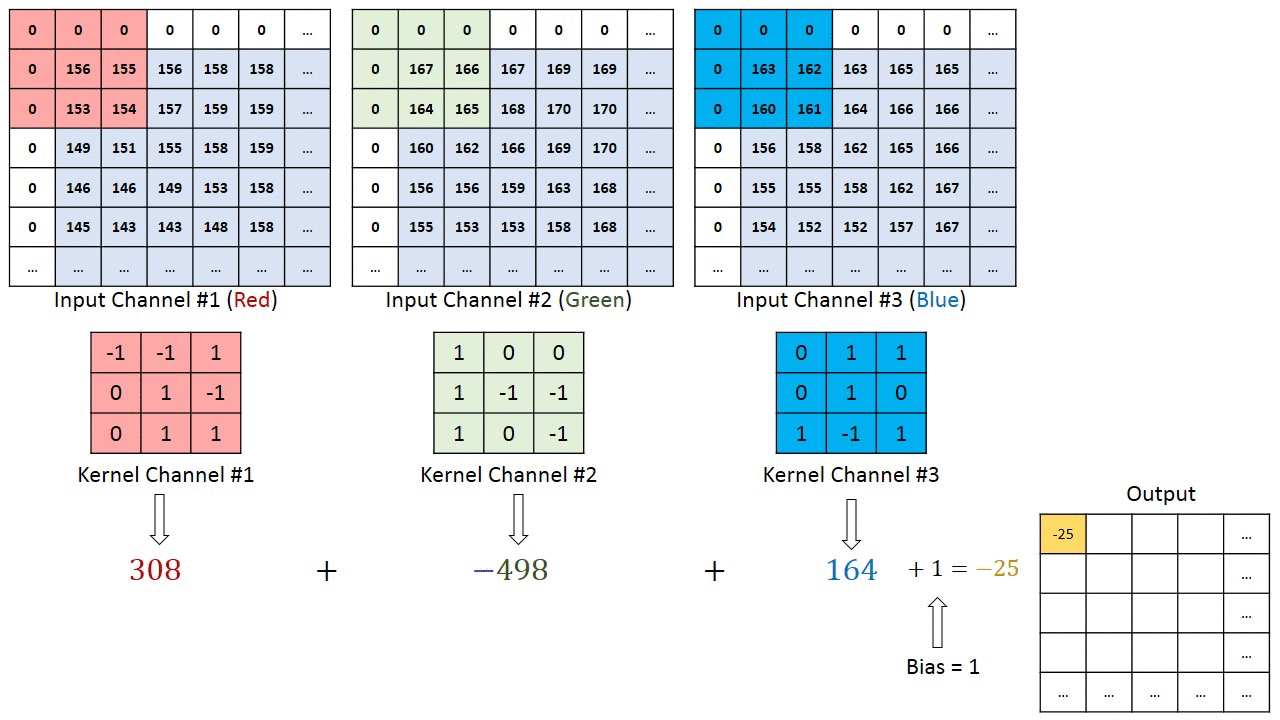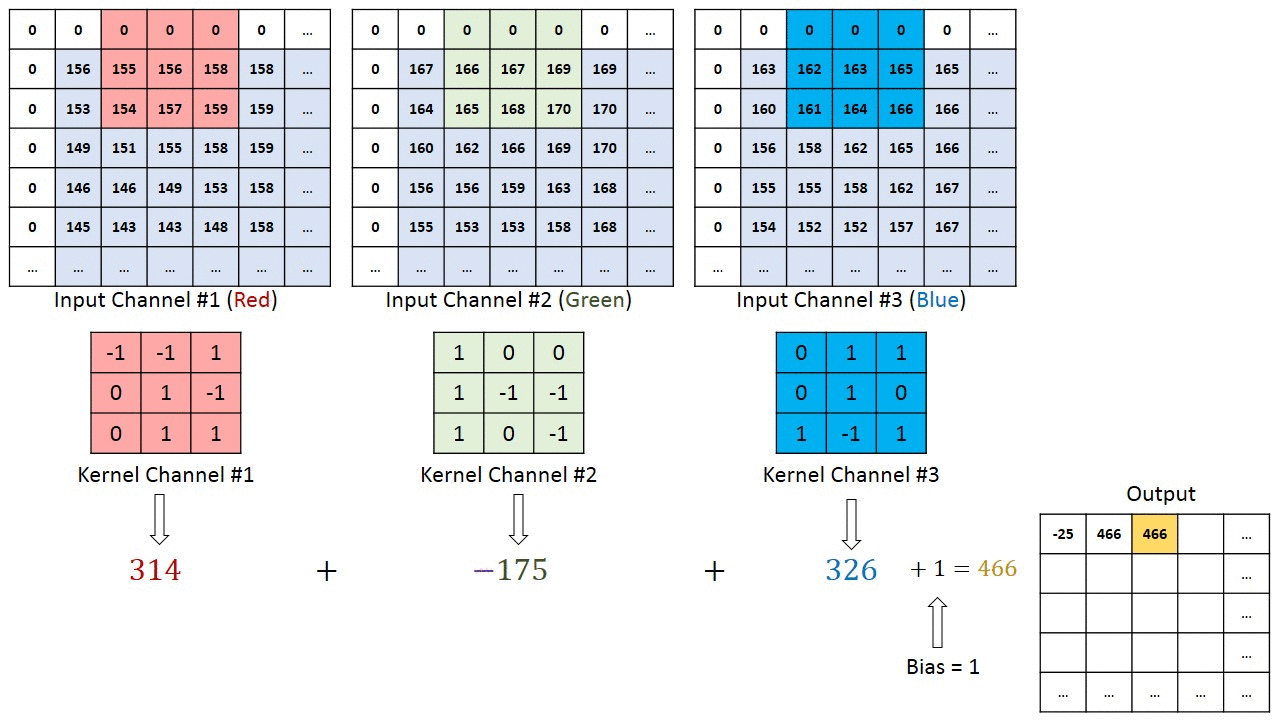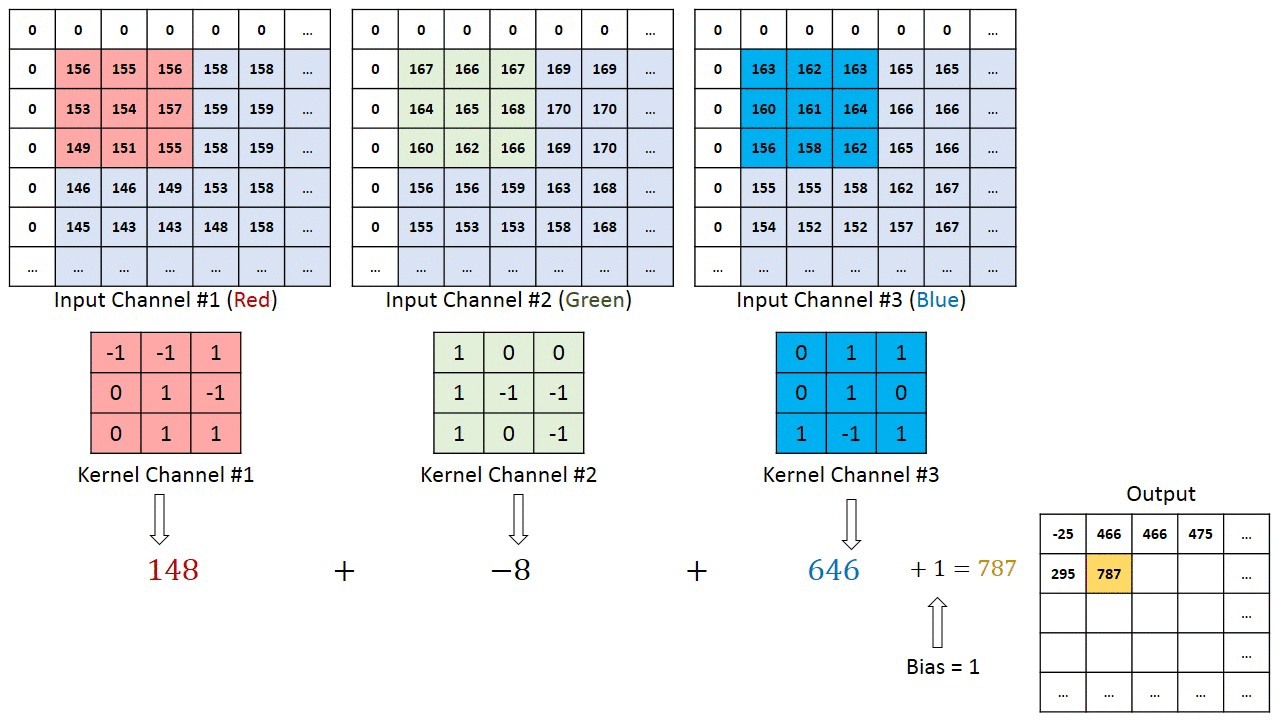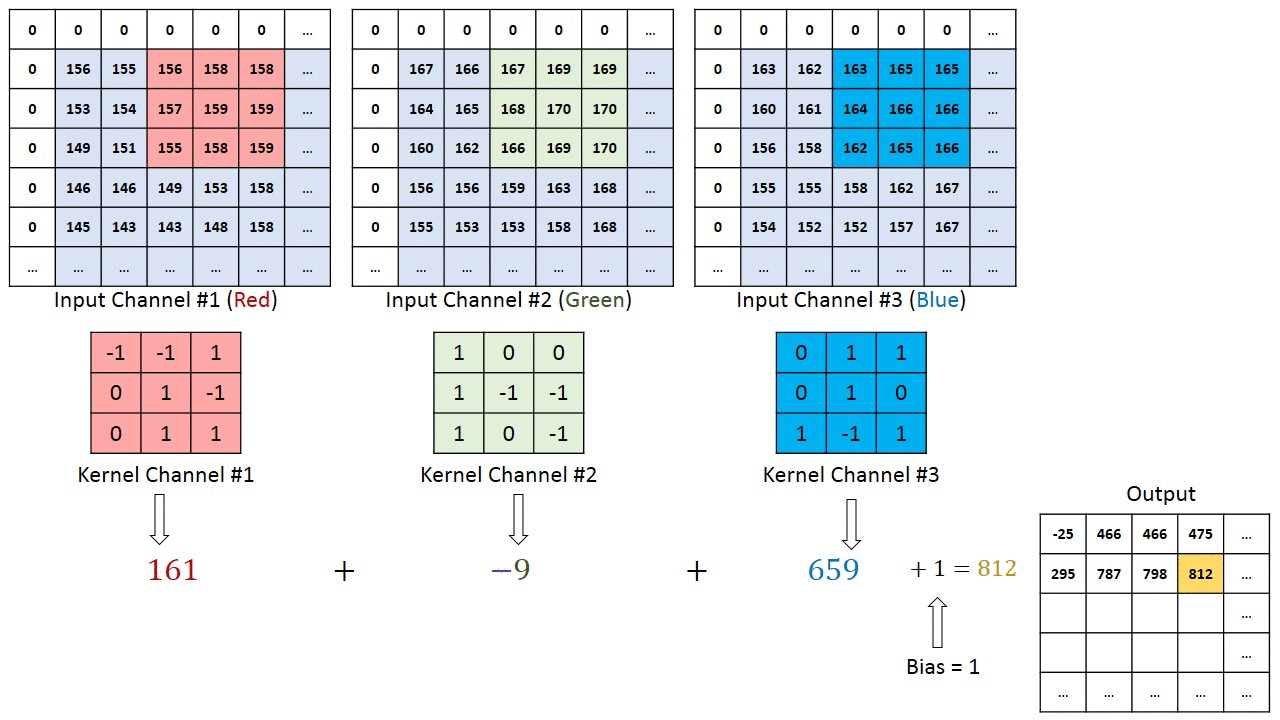
This article goes into CNNs in more detail. For our purposes one thing is important: CNNs have been the go-to for Computer Vision primarily due to their ability to build feature maps.
Transformers- The New Generation?
Transformers are the cousins of CNNs. They are improvements on traditional Recurrent Neural Networks (RNNs). RNNs were created to handle temporal data, where the past follows the future. Let’s take a simple example. Imagine the sentence, “Don’t eat my _”. To fill in the _, we need to take context from the previous words in the sentence. Filling out random words wouldn’t do us any good. Unlike Traditional Networks, RNNs take information from Prior Inputs.

However, RNNs have a flaw. Since they work on sequential data, data order is important. This makes them impossible to parallelize since we have to feed the inputs in orders. Transformers were created to solve this issue. Transformers use attention to identify important parts of the input and use store those in memory.

Since Transformers can be parallelized, we have seen some enormous datasets being trained. Googles BERT and OpenAI’s GPT3 are some notable examples. We have seen them achieve some insane functionality. However, there is one question this leaves — Transformers were built for NLP, so why are they good for Computer Vision? Is it just blind luck + lots of training?

Transformers are very effective because of the way they handle inputs. Transformers leverage encoders and decoders. Encoders take your input and encode it into a latent space. The Decoder takes vectors from the latent space and transforms them back.
This can be used in a variety of ways in Computer Vision. Adversarial Learning, Reconstruction, Image Storage, and Generation are some notable examples. It also plays a crucial role in DALL-E. We take the text input and encode it into the latent space. Then we can take a decoder that decodes the latent vectors into an image. This is how we are able to generate images from text descriptions.

The attention mechanism in Transformers allows them to identify the parts of a sentence that are important. Attention allows Transformers to filter out the noise and capture relationships between words that are even far apart.
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution
Everyone already knows this in the context of NLP. What I didn’t know is that this holds true even for CV. The attention mechanism allows Transformers to keep a “global view of the image” allowing them to extract features very different to ConvNets. Remember, CNNs use kernels to extract features, which restricts means that they find the local features. Attention allows Transformers to bypass this.
Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers.
The above quote is taken from the very interesting, Do Vision Transformers See Like Convolutional Neural Networks? It’s interesting enough that I will do a breakdown of this paper later. The important aspect is the following quote, also from the paper.
…demonstrating that access to more global information also leads to quantitatively different features than computed by the local receptive fields in the lower layers of the ResNet
Clearly, Transformers are very powerful. The attention mechanism, large-scale training, and modern architecture have seen them become the backbones for a lot of vision tasks. So the question is, do pure CNNs stand a chance? Here is a comparison of the new CNN training method compared to vision Transformers, taken from the paper.
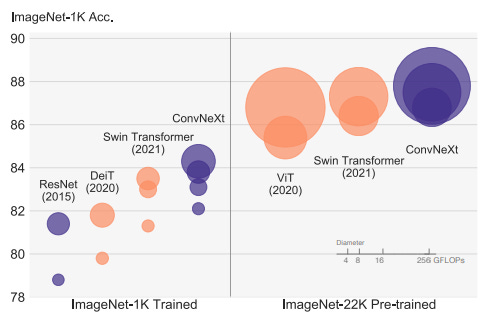
Clearly, this is very exciting stuff. By improving the training pipelines around the CNN architecture, we can match SOTA transformers. This goes to show the power of setting up good Machine Learning training pipelines. They can compensate for using weaker models and are often more cost-effective.
Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
Modernizing The CNN Infrastructure
Clearly, we can improve our standard models and achieve amazing performance. Let’s talk about some of the interesting design tweaks they did to make this possible (to know them all, make sure you read the paper). I will also go over some insights I had reading this paper, and that I would love to discuss with y’all. Share your thoughts in the comments/with me through IG/LinkedIn/Twitter (links at the end of this article).
Increasing Kernel Size
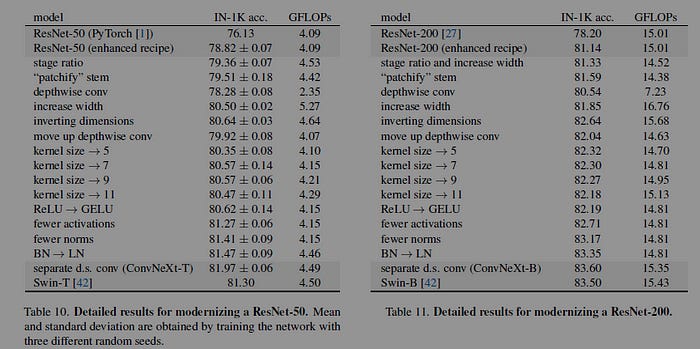
Transformers use larger kernel sizes than ConvNets. The authors point out, “Although Swin Transformers reintroduced the local window to the self-attention block, the window size is at least 7x7, significantly larger than the ResNe(X)t kernel size of 33. Here we revisit the use of large kernel-sized convolutions for ConvNets.” The authors experiment with Kernel Sizes and find that larger sizes improve performance. However, they find that the benefits of increasing kernel size vanish after getting to 7x7 kernels.
With all of these preparations, the benefit of adopting larger kernel-sized convolutions is significant. We experimented with several kernel sizes, including 3, 5, 7, 9, and 11. The network’s performance increases from 79.9% (33) to 80.6% (77), while the network’s FLOPs stay roughly the same.
Inverted BottleNeck Design
The bottleneck design is common in neural networks. Many encoder-decoder pairs tend to downsample input into the latent space and upsample from the latent space. However, the authors found using an inverted bottleneck design to be superior (and is something used by Transformers).
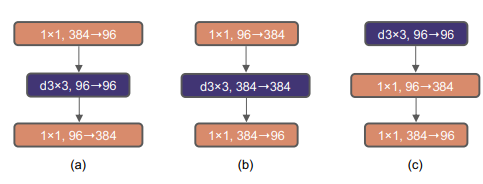
The benefit of this design pattern is shown below-
Here we explore the inverted bottleneck design. Figure 3 (a) to (b) illustrate the configurations. Despite the increased FLOPs for the depthwise convolution layer, this change reduces the whole network FLOPs to 4.6G, due to the significant FLOPs reduction in the downsampling residual blocks’ shortcut 1×1 conv layer. Interestingly, this results in slightly improved performance (80.5% to 80.6%). In the ResNet-200 / Swin-B regime, this step brings even more gain (81.9% to 82.6%) also with reduced FLOPs.
The increased performance in larger networks is an interesting occurrence. I would be interested in seeing if this improved performance continues to scale with the bigger models. This would have a lot of potential in the extremely large-scale language models that have become the trend today. If somebody has an idea of why it happens, please do share. I’d love to learn.
Tweaking Activation Functions
As I’ve covered before, activation functions are a big deal. The authors made some changes to ResNet blocks to resemble the Transformers. The first was changing the activation functions to GeLU (Gaussian Error) from ReLU

The authors also changed the number of activation functions in a block. They, “As depicted in Figure 4, we eliminate all GELU layers from the residual block except for one between two 1x1 layers, replicating the style of a Transformer block. ” This resulted in a 0.7% improvement.
Separating Downsampling Layers
Another inspiration from Transformers, the authors decided to separate downsampling. Instead of doing it all at the start of a stage (like traditional ResNet), they have downsampling between layers as well (like vision transformers). The ConvNeXt Block thus looks like this-

This has quite an impact, with the authors pointing out that by following this strategy “We can improve the accuracy to 82.0%, significantly exceeding Swin-T’s 81.3%.”
Note on AGI
The changes I covered are by no means comprehensive. There were a ton of changes the authors implemented to make their networks more “modern”. Fortunately, they list the changes in the appendix of the paper, along with the benefit each change brought with it.
As I was reading this paper, it got me thinking about Artificial General Intelligence (AGI). Many of these changes were inspired by the success in other models/networks (the authors took inspiration from both Transformers and other CNNs). Given the results of research into data imputation, learning rates, batch sizes, architectures, etc. it leads me to a question- Is the Key to AGI in “a perfect training protocol”. Is there a perfect configuration for training, across tasks? I cover this in slightly more detail in this 6 Minute video but would love to hear your thoughts.
That’s it for this article. Interesting AGI hypotheticals aside, this paper once again shows us the importance of constantly learning about the foundational research going on in Machine Learning.
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819