


How is SinGAN-Seg solving the Medical Machine Learning’s Data Problem?[Breakdowns]
An innovative approach +encouraging results make this paper worthwhile

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Medical Machine Learning has serious issues when it comes to reproducibility and data.
Thanks to differing data regulations, data sharing across borders can be difficult. This can lead to a lot of problems when it comes to the reproducibility of their research. To read more about the replication crisis, check out this article that explains this issue and what to do about it.
More specific to Medical Machine Learning, datasets themselves are often small. Creating larger datasets requires a lot of expert time invested. This is because, unlike normal Image Datasets which can be annotated by regular people, medical datasets should only be annotated by experts.
This is precisely what the authors of “SinGAN-Seg: Synthetic Training Data Generation for Medical Image Segmentation” set out to solve. Their goal, create a data generation architecture that can generate multiple images from a single input. And have those generated images be useful in the tasks of image segmentation. Why did they go after these goals? And how did they do attempt to do this? And was this attempt a success? I’ll be going over all of that and more in this article.
We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labeling would be impossible.
- Synthetic Data is becoming increasingly prevalent in a lot of Machine Learning Applications. The following text is taken from, Fake It Till You Make It -Face analysis in the wild using synthetic data alone, a publication by Microsoft.
Why use fake Images?
This might be something that stands out to you. There are over 7 Billion people in the world right now. Certainly, we can generate enough data just by using real-life images. Wouldn’t we be better off looking into auto-labeling/marking solutions? With all the Computer Vision work that is going into this field, it’s not unreasonable to want to focus on it.
However, that overlooks a crucial fact. As of now, there is no standardized policy on sharing Medical Data in Research. This implies that a Team based in Norway might not be able to share the medical data they use with a team in India (especially if it contains medical data of Norweigian Citizens). And as stated earlier, the replication crisis is a very real concern. If we use synthetic images, there are no such regulations stopping us. This makes the data sharable and the research reproducible.

Another point to note is that “real” data is not necessarily better than synthetic data. It might be difficult to get high-quality images of polyps inside the body. While low-quality images can be crucial for improving your models later on, when dataset sizes are small, you’ll only hurt the model's performance. Since Dataset Size is an issue in this field, it is smart to look into different data augmentation policies. It has shown to be an area with a high return on investment in multiple fields of Machine Learning.
The Experiment Process
In the words of the authors, “In the pipeline of SinGAN-Seg, there are as depicted in Figure 1 two main steps: (1) training novel SinGAN-Seg generative models and (2) style transferring.” Following is what the architecture looks like:

Step 1 is relatively straightforward. Building off the SinGAN architecture, we generate a lot of images (in this case of polyps). The tweak in SinGAN-Seg comes from the additional input (a ground truth mask). This makes the input (and output) 4 channels (RGB+ Ground Truth) instead of the usual 3(RGB) in the original SinGAN architecture. In the words of the paper-
“The main purpose of this modification is to generate four-channels synthetic output, which consists of a synthetic image and the corresponding ground truth mask.”
What really struck me as innovative was the second step.

Neural Style Transfer is one of those concepts which I’m not completely over. You can take the content of one image, and the style of another and combine them. I’ll be going into the concept on my YouTube, so be sure to subscribe right here to keep updated. How is this seeming wizardry relevant in our case?
The authors of this paper do something genius. To imitate the kind of images that real-life data is going to produce, they used style transfer to transfer the style of the real images onto the generated images. This is brilliant. This means that we have synthetic images that look and feel like real-life data.
This is brilliant. This means that we have synthetic images that look and feel like real-life data. For a more complete breakdown of this really cool system check out the following video. It goes into more detail about the steps (including a cool quote from the authors). It also goes into some ways others might be able to apply this in their own Machine Learning Projects.
Evaluation
People who read my work are very practical people, always looking for results. Not to worry, because the authors provide plenty of results. One of the things that brought a smile to my face was how rigorous they were in the various evaluations. They made sure to show both how their synthetic data both stacks up against real data, and if the synthetic data was a valid data augmentation for smaller datasets. On top of this, we see the team use a variety of metrics. “Finally, dice loss, IOU score, F-score, accuracy, recall, and precision were calculated for comparisons using validation folds.” See that. They use cross-validation!!
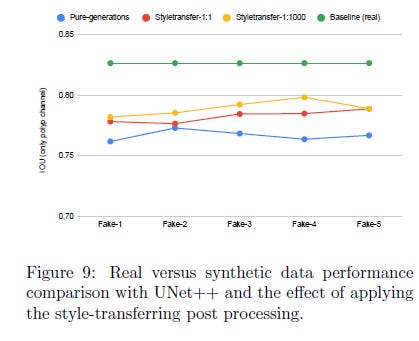
This is the result of the first set of experiments they performed. Here we take 4 different datasets and evaluate their architecture. Green is the baseline (real images only). Then we have the two kinds of style transferred synthetic images (yellow and red) and finally the pure synthetic images (blue). We see two interesting things: 1) Real outperforms everything and 2) Styletransfer has a benefit in the performance compared to pure generations. There also isn’t a massive difference in the performance between the real and the style transfers. For a more complete understanding of the performance of the various datasets, check out the following table:

This gives us a rather interesting result. We see that the synthetic images (more so the style transferred ones) can even be used as an alternative when we might have any data sharing restrictions on real data. “According to the results presented in Table 1, the UNet++ segmentation network perform better when the real data is used as training data compared to using synthetic data as training data. ”
However, the small performance gap between real and synthetic data as training data implies that the synthetic data generated from the SinGAN-Seg can use as an alternative to sharing segmentation data instead of real datasets, which are restricted to share.
This is a quote from the authors of the paper. And the results are hard to argue with.
But there is another part to this. Can synthetic data be used as a good data augmentation for small datasets? According to the authors, “This study showed that these synthetic data generated from a small real dataset can improve the performance of segmentation machine learning models. For example, when the real polyp dataset size is 5 to train our UNnet++ model, the synthetic dataset with 50 samples showed 30% improvement over the IOU score of using the real data samples.” We see a clear indication that with very small datasets, this is a great way to boost the performance of your segmentation tasks.
Closing
This paper was very exciting. I was most impressed by the use of the style transfer, and how we could generate unlimited samples from a single input. This definitely has a lot of scope in the future. I can see this being very powerful as data-sharing policies become standardized and we integrate more policies into the augmentation.
Right now, the fact that we can have great performance with minimal expert time invested in the annotation is a huge plus. I have worked with synthetic generative data in detecting certain heart conditions (and also in using generative AI-based text modelers), and both have shown to have a lot of potential. I will be covering those soon, in another writeup.
Before you go, I have a question for you. Some of you may remember an earlier writeup where I broke down how Amazon makes AI more trustworthy. I was curious to see which of these techniques my readers thought had the most potential. I’d love it if you would take a second to answer the poll over here.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819