
Intel's Research on why Small Batch sizes lead to greater generalization in Deep Learning[Breakdowns]
Is there something inherently wrong with larger Batch sizes?

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Batch Size is among the important hyperparameters in Machine Learning. It is the hyperparameter that defines the number of samples to work through before updating the internal model parameters.

The batch size can make or break the performance of many deep learning-based neural networks. Therefore it should not come as a surprise that there is a lot of research that goes into evaluating the best batch-size protocols for your learning agents. For example with SGD, you might use batch gradient descent (using all the training samples in your batch) or mini-batch (using a portion of training data) or even update after every sample. And these can change the effect on your learners.

Accuracy is not the only performance metric we care about. Generalization is one such metric. After all, our model is useless if it can’t perform well on unseen data. And it has been noticed that the use of larger batch sizes leads to worse network generalization. The authors of the paper, “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima” seek to investigate this phenomenon and discover why this happens. Their findings were interesting, and I will present them to you in this article. Understanding this will allow you to make better decisions for your own Neural Networks and ML pipelines.
Understanding the Hypothesis
To understand any paper, it is important to first understand what the authors are trying to prove. The authors claim that they were able to discover why large batch sizes lead to worse generalization.
numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions — and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation.
There is a lot stated here, so let’s take it step by step. The image below is an elegant depiction of the difference between sharp minima and flat minima.

Once you’ve understood the distinction, let’s understand the two (related) major claims that the authors validate:
Using a large batch size will create your agent to have a very sharp loss landscape. And this sharp loss landscape is what will drop the generalizing ability of the network.
Smaller batch sizes create flatter landscapes. This is due to the noise in gradient estimation.
The authors highlight this in the paper by stating the following:

We will now go over the evidence they provide. Some of the ways they set up their experiments is interesting and will teach you a lot about setting up experiments.
Defining Sharpness
Sharpness seems like an intuitive concept to grasp and visualize. It does have some complications, however. Remember Machine Learning operates on higher dimensional data. Computing/visualization across this might be expensive. The authors even acknowledge how expensive it is to compute the magnitude of the eigenvectors. Therefore they use a simpler heuristic. They check around the neighborhood of a solution. The largest value the function can achieve is used to calculate the sensitivity.
we employ a sensitivity measure that, although imperfect, is computationally feasible, even for large networks. It is based on exploring a small neighborhood of a solution and computing the largest value that the function f can attain in that neighborhood. We use that value to measure the sensitivity of the training function at the given local minimizer. Now, since the maximization process is not accurate, and to avoid being mislead by the case when a large value of f is attained only in a tiny subspace of Rn, we perform the maximization both in the entire space Rn as well as in random manifolds.
Notice that the authors integrate a degree of cross-validation into the procedure. While it may seem too simplistic to just take multiple samples from your solution space, this is a very powerful method that will work for most cases. If you’re interested in the formal notation of their calculations it looks like this

Before we proceed, just a quick PSA. I am looking for work starting in June. My resume can be found here and this is my LinkedIn account with more details. Now on with the article.
Reviewing the Evidence
Now that we understand the basic terms/definitions that the authors use, let’s look at some of the evidence presented. Obviously, I won’t be able to share everything in the paper/appendix. If you’re interested in all the details, you can read the paper. If you want a fully annotated variation of the paper, with important aspects highlighted + with my thoughts, reach out to me.

To the left, you can see the plot of the cross entropy loss against the sharpness. It is important to note that as you move to the right, our loss is actually getting smaller. So what does the graph mean? We notice that as our learners mature (loss reduces) the sharpness of the Large Batch learners increases. In the words of the authors, “For larger values of the loss function, i.e., near the initial point, SB and LB method yield similar values of sharpness. As the loss function reduces, the sharpness of the iterates corresponding to the LB method rapidly increases, whereas for the SB method, the sharpness stays relatively constant initially and then reduces, suggesting an exploration phase followed by convergence to a flat minimizer.”
The authors have several other experiments to show the results. Aside from testing on different kinds of networks, they also used warm starting on both small-batch and large-batch networks. The results are pretty consistent with what we’ve seen so far.
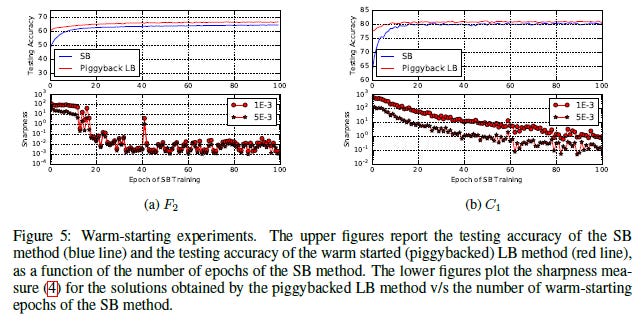
One of the interesting takeaways I found in the paper was when they demonstrated how this lower generalization was not related to the Models overfitting or overtraining when using larger batch sizes. It is very easy to assume overfitting is the cause of lower generalization (it generally is), but the authors argue against this. To understand their argument, take a look at this table

Notice that Small Batch training has generally better training performance. Even in networks where we have lower training accuracy for SB training, we notice a higher training accuracy. Read the following passage by the authors
We emphasize that the generalization gap is not due to over-fitting or over-training as commonly observed in statistics. This phenomenon manifest themselves in the form of a testing accuracy curve that, at a certain iterate peaks, and then decays due to the model learning idiosyncrasies of the training data. This is not what we observe in our experiments; see Figure 2 for the training–testing curve of the F2 and C1 networks, which are representative of the rest. As such, early-stopping heuristics aimed at preventing models from over-fitting would not help reduce the generalization gap.
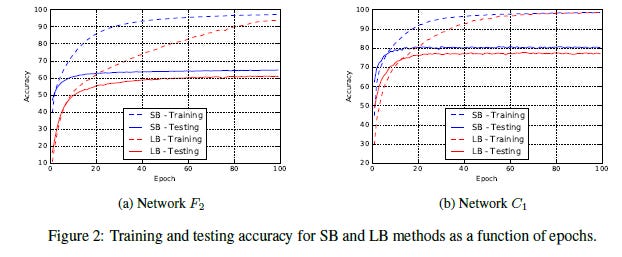
In easy words, the if this were a case of overfitting, we would not see the consistently lower performance of the LB methods. Instead, by stopping earlier, we would avoid overfitting, and the performances would be closer. This is not what we observe. Our learning curve paints a very different picture. If you want to learn how to use/analyze learning curves check out the following video. Here I break down the nuances of LCs combining all the various things I learnt over the years. I use real life examples from my projects along with how I tackled the different challenges we saw.

That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Using this discount will drop the prices-
800 INR (10 USD) → 640 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819