
Learnings from SimCLR: A framework Contrastive Learning for Visual Representations [Breakdowns]
The framework is simpler AND outperformed everything

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Machine Learning is a diverse field with lots of different aspects. One of the chief concerns of ML is the learning of visual representations (pictures/diagrams etc corresponding to areas). This has applications in all kinds of problems, ranging from Computer Vision, Object Detection, to more futuristic applications like learning from and developing schematics. Recently, people have started to look into Contrastive Learning as an alternative to supervised and unsupervised learning. It involves teaching the model to learn the general features of a dataset without labels by teaching the model which data points are similar or different. The focus thus shifts to learning about what makes two samples different. I will be getting into more detail about this technique, so be sure to follow my content across the platforms to stay updated.
Contrastive learning is a machine learning technique used to learn the general features of a dataset without labels by teaching the model which data points are similar or different.
The authors of “A Simple Framework for Contrastive Learning of Visual Representations” decided to look into the use of contrastive learning in learning visual representations. And naturally, I was excited to learn more. Self Supervised learning is a promising field with lots of potential applications. In this article, I will be sharing what I found most interesting about the research and what they discovered. If you thought I missed something, or have any other comments, be sure to share them with me. It’s always a pleasure hearing from you guys.
Takeaway 1: Simple Data Augmentation Works
It’s no secret I’m a huge fan of data augmentation. Both my Deepfake Detection research, and a lot of my content, often talk about how useful it is. However according to the authors, “While data augmentation has been widely used in both supervised and unsupervised representation learning (Krizhevsky et al., 2012; Hénaff et al., 2019; Bachman et al., 2019), it has not been considered as a systematic way to define the contrastive prediction task.” This paper shows how useful Data Augmentation can be in contrastive learning.
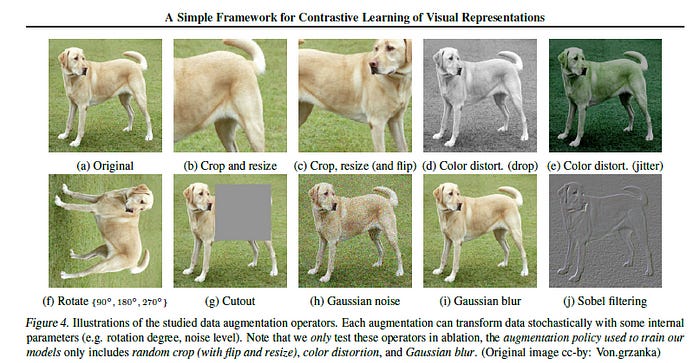
The above picture is a list of all the different transformations that could br applied to an original image for data augmentation (in the paper).

To understand the significance of the papers we should understand the two kinds of views (global/local and adjacent). Both involve predicting the image by focusing on a particular area (called receptive field). This can however be quite complex. But here’s the good news. “We show that this complexity can be avoided by performing simple random cropping (with resizing) of target images, which creates a family of predictive tasks subsuming the above mentioned two, as shown in Figure 3.” This “decouples the predictive task from other components such as the neural network architecture”. In simple words, we are able to create a large diversity of possible results by implementing simple random cropping.

We also find that Contrastive Learning requires much stronger augmentation. Higher augmentation intensity improves the performance of contrastive learners. Here, complex augmentation protocols are actually less effective than simple cropping. We see the superiority of simple cropping (with strong augmentation) over complex protocols in the table above.
“In this context, AutoAugment (Cubuk et al., 2019), a sophisticated augmentation policy found using supervised learning, does not work better than simple cropping+ (stronger) color distortion”.
The introduction of greater diversity in Machine Learning has applications beyond Contrastive Learning. In my piece, How Did Google Researchers Beat ImageNet While Using Fewer Resources? we saw the positive impact that adding noise into the training process could have on the overall performance, robustness, and even training costs.
Noisy Student Training achieves 88.4% top-1 accuracy on ImageNet, which is 2.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 61.0% to 83.7%, reduces ImageNet-C mean corruption error from 45.7 to 28.3, and reduces ImageNet-P mean flip rate from 27.8 to 12.2.
Takeaway 2: Bigger models with larger batches leads to better performance

While that statement might seem obvious, the Figure 7 tells us an interesting story. We see that contrastive learning starts catching up to supervised models as we increase model size. As the research team pointed out, “Figure 7 shows, perhaps unsurprisingly, that increasing depth and width both improve performance. While similar findings hold for supervised learning (He et al., 2016), we find the gap between supervised models and linear classifiers trained on unsupervised models shrinks as the model size increases, suggesting that unsupervised learning benefits more from bigger models than its supervised counterpart.” Here unsupervised learning refers to unsupervised contrastive learning.
With this we see another interesting trend. We see that contrastive learning models benefit more from large batch sizes/more training epochs.
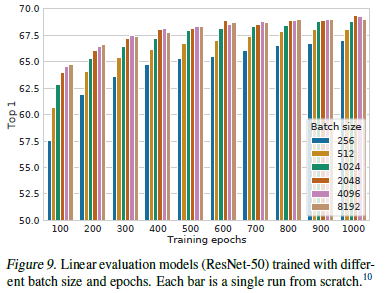
“With more training steps/epochs, the gaps between different batch sizes decrease or disappear, provided the batches are randomly resampled. In contrast to supervised learning (Goyal et al., 2017), in contrastive learning, larger batch sizes provide more negative examples, facilitating convergence (i.e. taking fewer epochs and steps for a given accuracy). Training longer also provides more negative examples, improving the results.”
Takeaway 3: Contrastive Learning has potential

Above is the performance of SimCLR compared to some baseline learners. Section 6 of the paper goes over various tests in various contexts, comparing the performance of SimCLR to State of the Art models. I will not go over the full section since explaining the tests and various tasks will require a series by itself, but would recommend that you read the paper. If anyone has any doubts feel free to leave them in the comments (or reach out to me using the links at the very end) and we can discuss them. However, based of the results shared, we can conclude that Contrastive Learning can be a very powerful tool, and should be researched further.
Final Notes
There are other takeaways that you might find interesting in the paper. I chose to focus on these three since I found them to be the ones that had the most potential to be generalized to more kinds of tasks. The performance of Contrastive Learning validates the author’s statements that it is undervalued. I believe that Contrastive Learning might help us solve problems traditionally difficult for supervised learning (problems where labeling can be very expensive for eg.) I would recommend keeping an eye out for more problems being tackled with Contrastive Learning.
Do you think Contrastive Learning has great potential? Let me know.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819