
Neural Network model confidence is notoriously unreliable. Is this this the solution?[Breakdowns]
Introducing Label Dispersion. A better Metric for Evaluating Machine Learning Model Uncertainty?

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Computer Vision has seen some really innovative uses of traditional Machine Learning techniques, alongside heavy investment. And for good reason. Images are an expensive input to process. Given how useful Computer Vision is in various lucrative applications, there are huge incentives to create a low-cost, high-performance learning agent. Among these various innovations is a very interesting Machine Learning protocol called Active Learning. Done right, Active Learning will lead to lower training costs while not sacrificing performance. To maximize performance in Active Learning, we need a reliable way to evaluate how confident a model is with a particular sample. The authors of “When Deep Learners Change Their Mind: Learning Dynamics for Active Learning” present a new metric for doing just that.
In this article, I will introduce the basic idea of active learning, and why you should keep your eye on it. Once we have a good understanding of it, we will go into Label Dispersion, their proposed metric for evaluating uncertainty in a trained machine learning network. We will look at the concept, and evaluate the performance. While the paper is tested on Computer Vision classification tasks- the idea can even be extended to other domains- including regression. I have used spinoffs in a variety of tasks - from supply chain risk forecasting to tuning large models for specific tasks- and saw some great results with it. If any of you would like t to discuss more details, I’d be happy to talk. You can reach out by replying to this email or using my social media links at the end of the article.
Understanding Active Learning
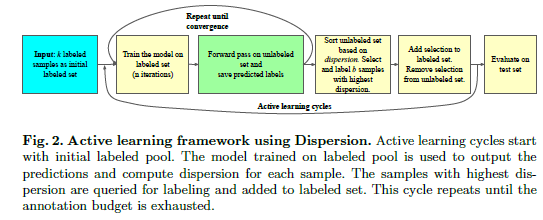
A good definition of Active Learning is, “Active learning is a special case of machine learning in which a learning algorithm can interactively query a user (or some other information source) to label new data points with the desired outputs.” In simple words, after training with an initial labeled data set, we traverse through an unlabeled dataset to select the “best” samples. These samples are sent to a teacher (could even be a human)who then labels the data sample and adds it to the labeled pool. The model is retrained. You might be wondering what benefit this has over something like Semi-Supervised Learning. Having a human annotate the data samples is expensive, so why not just implement SSL and use pseudo-labels?The answer is simple.
While the cost of annotation per data sample is higher, Active Learning uses a fraction of the total samples.
This is the secret. Active Learning offsets the need for immense data pools typically seen in Computer Vision Research (literal Petabytes of data). Active Learning is definitely something you should know about for the future and I will be doing more dedicated articles on it in the future.
Such vastly superior scaling would mean that we could go from 3% to 2% error by only adding a few carefully chosen training examples, rather than collecting 10x more random ones
-From Meta AI’s paper- - Beyond neural scaling laws: beating power law scaling via data pruning
So how is Model Uncertainty relevant in Active Learning?
Quick answer, most Active Learning agents select samples they are most uncertain about. The logic is the following. If your model is already confident about a sample, annotating and adding that to the training pool is kind of useless. Data points that models aren’t confident about will work best when annotated and added to our list. Therefore, an accurate way to evaluate the uncertainty of a model is our best bet in creating a high-performing Active Learning Learning Agent.
This is why you often see many advanced Deep Learning pipelines compute and share model confidence in their outputs. It serves as an additional way to identify weaknesses in your systems and also catch when it might be time to retrain your models. However, there is one issue- neural network confidence scores are very meh.
Why Network Confidence is not Enough

The above image explains our problem clearly. Often Neural Networks can be very confident about their predictions, even when that prediction is actually wrong. This can cause two problems:
They will pass by samples that they should be learning because of overconfidence. They will think they understand a sample really well. Take a look at image d. The network has 0.99 confidence on a wrong prediction.
Similarly, the model will pick other images where it has faulty lower confidence. This is not as bad as the first case, but it makes your learning more inefficient. For larger-scale projects, this can add up.
Label Dispersion: A new metric
Now that we see why Model Confidence by itself is not the best metric, let’s look at Label Dispersion. For me, there are a few considerations that make a metric great. One is performance (obviously). It should also be relatively inexpensive to compute. And lastly, the metric should make sense (on a logical level).

Above is the math they use to calculate label dispersion. The notation might seem intimidating but the idea is deceptively simple. We have our model predict the label of an image a bunch of times. If we have the same prediction, we will have a low label dispersion. Look at the image below. Since the model always predicts a car, it has low dispersion. If we have different labels being predicted, then our model is “confused” about them. This means a higher value. While the other images (b,c,d) have similar prediction confidence, they have significantly higher label dispersion values.
This approach checks off 2 of our 3 criteria. It makes sense on an intuitive level and is relatively inexpensive to compute (predicting a sample using a trained model is always cheap). The table, in the beginning, showed promising results. Let’s look at other performances to see how well Label Dispersion holds up.
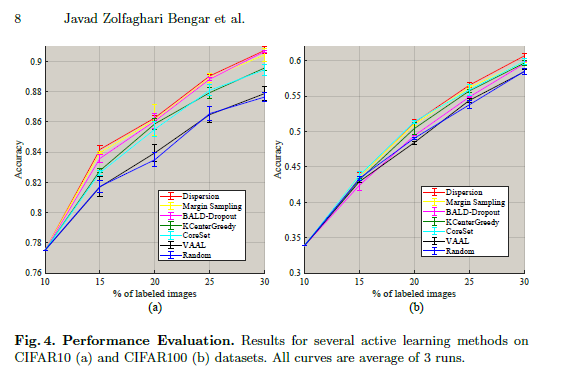
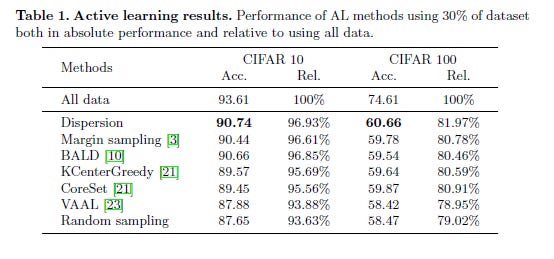
On the benchmarks CIFAR10 and CIFAR100, we see dispersion performing very well in terms of accuracy. This is a very promising sign and shows the potential of Label Dispersion as a metric for calculating model uncertainty. This checks off our final criteria on the checklist.
Conclusion
Based on the paper's results, Label Dispersion is certainly a promising metric that we can use in Active Learning. I will be looking into it more. Being a new metric, it needs some more testing in more contexts and benchmarks before anything conclusive can be said. However, it is a very promising metric so keep your eyes open for it. People will definitely be using it more in the future. As I mentioned earlier- I use variants of this for my own tasks. I had a small discussion about this below-
If you like what you read, I am now on the job market. My resume can be found over here. A quick summary of my skill set-
Machine Learning Engineer- I have worked on various tasks such as generative AI + text processing, modeling global supply chains, evaluating government policy (impacting over 200 Million people), and even developing an algorithm to beat Apple on Parkinson's Disease detection.
AI Writer- 30K+ email subscribers, 2M+ impressions on LinkedIn, 600K+ blog post readers over 2022.
If you would like to speak more, you can reach me through my LinkedIn here.
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819