
Understanding Spine-Net: How changing architectures can boost performance[Breakdowns]
Superior Performance in Object Detection and Localization. Top performance in Classification. Is this for you?

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Before we begin, I’ve been reading a bit into fine-tuning LLMs, and that field has really taken a life of its own. I’m holding a small discussion with my network about what they’re looking for in this field, what resources they’re using etc on LinkedIn here. I’d love it if you could drop by and give your 2 cents. Any such input allows me to write articles that are more geared toward your needs. Onwards with the articles-
Computer Vision is a thriving field. It has many applications from disease detection to self-driving cars. These diverse sets of problems come with their unique challenges and corresponding challenges. The authors of SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization attempt to solve one of the biggest challenges in that field. Many standard image classification architectures struggle with object detection and localization. The research folks at Google came up with a possible explanation for why this is the case. They also present an architecture that tackles this. In this article, I will talk about their proposed architecture and how a Scale-Permuted Backbone might help with Vision tasks.

Background
So what is the problem with image classification networks? To quote the authors of the paper, “Intuitively, a scale-decreased backbone throws away the spatial information by down-sampling, making it challenging to recover by a decoder network. ” What is a scale-decreased backbone? Simply put, it’s a network where you reduce the resolution of the data the deeper you go in. This is standard practice for most image classification networks.
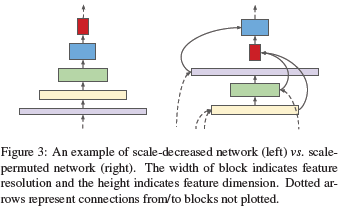
While that approach works for classification, this doesn’t work as well for detection. This is because “High resolution may be needed to detect the presence of a feature”. So the authors suggest a scale-permuted network, where we have both down and upsampling in the layers. This is supposed to be better for catching smaller objects and challenging features.
Shaping the Dimensions
You might be wondering how they keep messing around with the dimensions. Since the backbone is not fixed like with scale-decreased networks, it can get chaotic really quickly. To address this the authors did the following

Section 3.2 has a great example explaining the process. Check it out, if you have a hard time understanding this figure. Simply put, they run a lot of functions the specifics of which are determined dynamically by the parent and target blocks.
For bottleneck block, C in = C out = 4C; and for residual block, C in = C out = C. As it is important to keep the computational cost in resampling low, we introduce a scaling factor α (default value 0.5) to adjust the output feature dimension C out in a parent block to αC. Then, we use a nearest-neighbor interpolation for up-sampling or a stride2 3 × 3 convolution (followed by stride-2 max poolings if necessary) for down-sampling feature map to match to the target resolution. Finally, a 1 × 1 convolution is applied to match feature dimension αC to the target feature dimension C in.
Iterating through the different possible architectures
Now that we have an understanding of how we can resample features from different blocks to create our scale-permuted network, we encounter the next problem. How do we pick the best configuration? There are obviously multiple options.
This is where Neural Architecture Search comes in. It is a way of automating the designing of your neural networks. While it sounds exciting, there are a lot of nuances to using it well. To understand that concept better, check out the YouTube Playlist linked here. I made it to help people understand the topic better. I will keep updating it, so subscribe if you’re interested in that (or other machine-learning topics).
The thing to note is that NAS can be very expensive. The authors used a recurrent-neural network-based controller. However, by placing constraints and picking a smaller scaling factor, they were able to keep the costs under control. There is also the issue of bias in architectures created through NAS, which we covered in this issue of AI Made Simple.
Results
Now for the details, we have been waiting for. How well does this new architecture perform? Very well in fact.
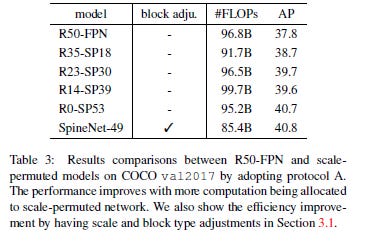
When compared to the ResNet architectures we see Spine-Net 49 has a higher AP (average precision) and a lower number of flops used. That’s a higher performance at lower costs. To summarize the table, “Compared to the R50-FPN baseline, R0-SP53 uses similar building blocks and gains 2:9% AP with a learned scale permutations and cross-scale connections. The SpineNet- 49 model further improves efficiency by reducing FLOPs by 10% while achieving the same accuracy as R0-SP53 by adding scale and block type adjustments.”
More experiments on different tasks/datasets show a similar result

And when we try to transfer SpineNet onto image classification tasks, we again see a fantastic performance at a lower cost.

All of this is very exciting. I will certainly keep an eye out for more experiments with a Spine permuted backbone. And when I do I will be sure to share. If you guys come across any interesting implementations, be sure to share them with me.
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
You really should put in the training cost/time for there architectural search. This might be useful at Google but not for most people doing real application unless they just use Spinenet as a 'better' ResNet.