
Why Tree-Based Models Beat Deep Learning on Tabular Data[Breakdowns]
A much-needed reality check for AI Researchers and Engineers caught up in the hype around Deep Learning

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Before getting into this, a small announcement. I will be graduating soon, and am looking for roles in AI and Machine Learning. My resume is here and you can find my LinkedIn profile here. More information at the end of this breakdown.
With all the hype around Deep Learning and the new 100-Billion Parameter models, it can be easy to forget that these large neural networks are just tools, and they have all their biases and weaknesses. One of the ideas that I stress through my content is that you should have a strong base of diverse skill sets so that you can solve problems in an effective and efficient manner.
In this article, I will be breaking down the paper- Why do tree-based models still outperform deep learning on tabular data? The paper explains a phenomenon observed by Machine Learning Practitioners all over the world working in all kinds of domains- Tree Based models (like Random Forests), have been much better than Deep Learning/Neural Networks when it comes to analyzing tabular data. I will be sharing their findings to help you understand why this happens, and how you can use these lessons to create the best AI pipelines to handle the challenges you come across.
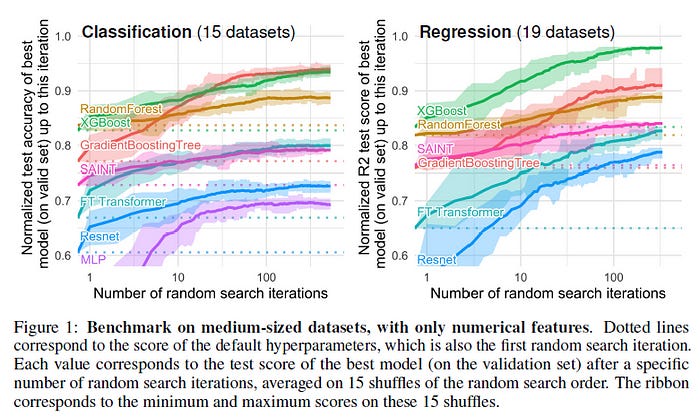
Points to note about the Paper
Before we start looking at the discoveries made by the paper, we should first understand some important aspects of the paper. This will help us contextualize the findings and better evaluate the results. Too many people skip straight to the results and don’t take enough time to evaluate the context. This is a fatal sin, and if you do this, I will stop loving you.
One thing that stood out to me was that the paper had a lot of preprocessing. Some like removing Missing Data will handicap Tree Performance. As I’ve covered in this article- How to handle missing environmental data, Random Forests are very good for situations with missing data. I used them a lot when I was working with Johns Hopkins University to build a system to predict how changing health-system policy would affect public health. The data was extremely noisy, with tons of features and dimensions. The robustness and benefits of RF made them better than more ‘advanced’ solutions, which would break very easily.

Most of this is pretty standard stuff. I’m personally not a huge fan of applying too many preprocessing techniques because it can lead to you losing a lot of nuance about your dataset, but the steps taken here would produce datasets that are similar to the ones found when working. However keep these constraints in mind when evaluating your final results, because they will matter. If your datasets look very different, then take these results with a pinch of salt.
They also used random search for hyperparameter tuning. This is also industry standard, but in my experience, Bayesian Search is much better for sweeping through more extensive search spaces. I’ll make a video on it soon, so make sure you’re following my YouTube channel to stay updated with it. The link to that (and all my other work) will be at the end of this article.
With that out of the way, time to answer the main question that you clicked this article- Why do Tree-Based Methods beat Deep Learning?
Reason 1: Neural Nets are biased to overly smooth solutions
This was the first reason that the authors shared that Deep Learning Neural Networks couldn’t compete with Random Forests. Simply put, when it comes to non-smooth functions/decision boundaries, Neural Networks struggle to create the best-fit functions. Random Forests do much better with weird/jagged/irregular patterns.

If I had to guess why, one possible reason could be the use of a gradient in Neural Networks. Gradients rely on differentiable search spaces, which are by definition smooth. Pointy, broken, and random functions can’t be differentiated. This is one of the reasons that I recommend learning about AI concepts like Evolutionary Algorithms, traditional searches, and more basic concepts, that can be used for great results in a variety of situations when NNs fail.
For a more concrete example of the difference in Decision Boundaries between the tree-based methods(RandomForests) and Deep Learners take a look at the image below-
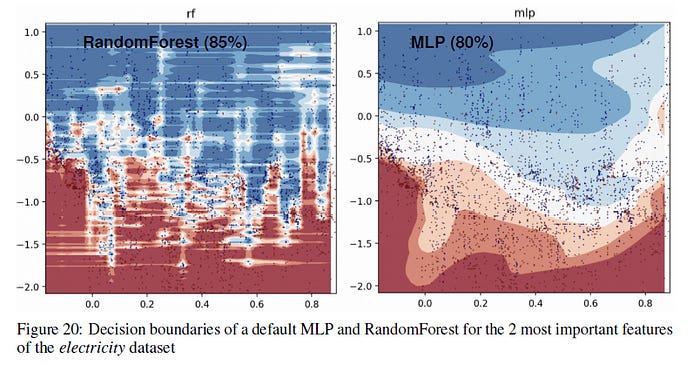
In the Appendix, the authors had the following statement wrt to the above visualization
In this part, we can see that the RandomForest is able to learn irregular patterns on the x-axis (which corresponds to the date feature) that the MLP does not learn. We show this difference for default hyperparameters but it seems to us that this is a typical behavior of neural networks, and it is actually hard, albeit not impossible, to find hyperparameters to successfully learn these patterns.
This is obviously really important. This becomes even more remarkable when you realize that Tree-Based methods have much lower tuning costs, making them much better when it comes to bang-for-buck solutions.
Finding 2: Uninformative features affect more MLP-like NNs
Another huge factor, especially for those of you that work with giant datasets that encode multiple relationships at once. If you’re feeding irrelevant features to your Neural Network, the results will be terrible (and you will waste a lot more resources training your models). This is why spending a lot of time on EDA/Domain Exploration is so important. This will help understand the features, and ensure that everything runs smoothly.
The authors of the paper test the model performances when adding (random)and removing useless (more correctly-less important)features. Based on their results two interesting things showed up-
Removing a lot of features reduced the performance gap between the models. This clearly implies that a big advantage of Trees is their ability to stay insulated from the effects of worse features.
Adding random features to the dataset shows us a much sharper decline in the networks than in the tree-based methods. ResNet especially gets hammered by these useless features. I’m assuming the attention mechanism in the transformer protects it to some degree.
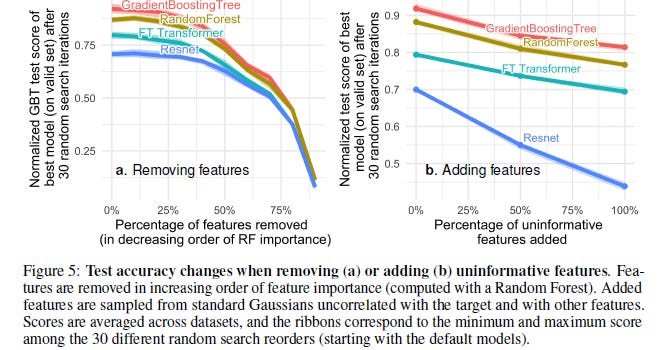
A possible explanation for this phenomenon might just be in the way Decision Trees are designed. Anyone who has taken an intro to AI class will know about the concepts of Information Gain and Entropy in Decision Trees. These allow Decision Trees to pick the best Paths going forward by comparing the remaining features to pick the one that would allow for the best choices. To those not familiar with the concept (or RFs), I would suggest watching StatQuests videos on these concepts. I’m linking his guide to RandomForests here.
Getting back to the point, there is one final thing that makes RFs better performers than NNs when it comes to tabular data. That is rotational invariance.
Finding 3: NNs are invariant to rotation. Actual Data is not
Neural Networks are invariant to rotation. That means if you rotate the dataset, it will not change their performance. After rotating the datasets, the performance ranking of different learners flips, with ResNets (which were the worst), coming out on top. They maintain their original performance, while all other learners actually lose quite a bit of performance.
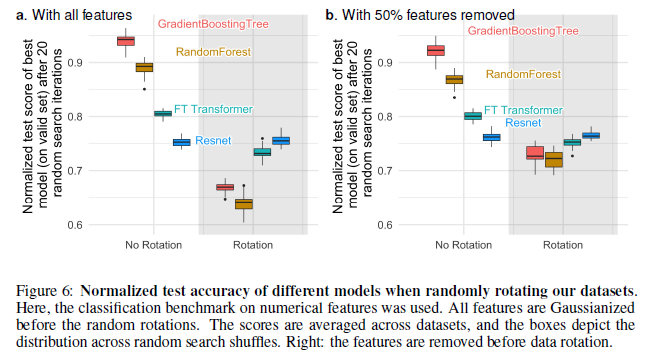
This is pretty interesting, but I have to learn more about it. Specifically, what does rotating datasets actually mean? This was not something I understood upon reading, so I reached out to some in my network to understand what this means. Basically speaking, 'Invariant to rotations' corresponds to the fact that correctly configured NNs learn shapes rather than function params (e.g. NNs learn what shape edges form in edge detection), which can be rotated relative to a set of axes in the data and still be detected.
On the other hand, a LinReg or RRF training is going to approximate a finite set of scalars (i.e. a gradient and y-intercept with LinReg and [a tree's] 'branch'-marginal probabilities with RRF). These structures are not invariant to the axes being rotated (e.g. rotating the axes in a LinReg is going to completely destroy the benefits from that training you just did). Thus, they make good examples of models that are not "rotation invariant". Shoutout to my reader Jimmy for this explanation.
I’m still open to learning more about this, so if you have any ideas, feel free to reach out.
Meanwhile, let’s look into why rotational variance is important. According to the authors, taking linear combinations of features (which is what makes ResNets invariant) might actually misrepresent features and their relationships.
…there is a natural basis (here, the original basis) which encodes best data-biases, and which can not be recovered by models invariant to rotations which potentially mixes features with very different statistical properties
Based on the performance drops, this is clearly a very important factor that needs to be considered. Going forward, I can see a lot of value in investigating the best data orientations. But I want to learn more about this before making any real comments on this.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Using this discount will drop the prices-
800 INR (10 USD) → 533 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
> Most of this is pretty standard stuff. I’m personally not a huge fan of applying too many preprocessing techniques because it can lead to you losing a lot of nuance about your dataset, but the steps taken here would produce datasets that are similar to the ones found when working.
Why not consider preprocessing like hyperparameter tuning? Isn’t it something that, if it improves model output, it’s worth doing?