

Why you should consider RandAugment for Image Data Augmentation
Why you should consider RandAugment for Image Data Augmentation
Two words Timothy: Performance and Cost-Efficiency

If you liked this post, make sure you hit the heart icon in this email.
This is a reader-supported publication. To support my writing you can give me a tip at Paypal or Venmo. Any amount helps a lot.
Recommend this publication to Substack over here
Subscribe to my other publication, Tech Made Simple, here
So if you read my last article (check it out here), I broke down how researchers at Google substantially outperformed current Image Classification systems while using exponentially fewer resources (spoiler: magic). The researchers mentioned using RandAugment to create input noise. Naturally, I was curious about this. And what I learned was amazing. So read on about why RandAugment is the best in the game. Through this article, we will understand how this deceptively powerful data augmentation policy works. Presenting RandAugment: Practical automated data augmentation with a reduced search space by Cubuk et al.
Background Information
Here’s a video describing the importance of Data Augmentation, and how RandAugment works. As a TL;DR- RandAugment works very well because it can add a lot of chaos to your input, in a cost-effective manner. This was a big departure from the standard in Computer Vision, which involved using very fancy policies to try to generate custom datasets. This is costly, and RandAugment is actually better.
RandAugment is that simple. Take an image, input 2 integers N and M. N will be the number of random transformations and M is the magnitude of the transformations. With just these parameters, RandAugment is able to generate drastically different images and improve learners. For example, in the video (N=2) we have a possible 13²= 169 images at a given M value. This randomness gives it an edge of ML-based data augmentation since we’re dealing with more random data. This makes learning the trends in the noise impossible. The simplicity means that “RandAugment can be used uniformly
across different tasks and datasets and works out of the box,
matching or surpassing all previous automated augmentation approaches on CIFAR-10/100, SVHN, and ImageNet.”

Why Quality Noise Matters
(Why Learned Augmentation fails)
We demonstrate that the optimal strength of a data augmentation depends on the model size and training set size. This observation indicates that a separate optimization of an augmentation policy on a smaller proxy task may be sub-optimal for learning and transferring augmentation policies.
This is a quote from the paper. At first this seemingly simple statement too trivial to pay attention to. However, this is not something that should be overlooked. As a general rule, the smaller the data sample, the more extreme the behavior. The paper however presents a new angle.

The team varies two factors: model size and network size. Figure 3a demonstrates the relative gains in accuracy of a model trained across increasing distortion magnitudes for different Wide-ResNet models. Figure 3a demonstrates systematic trends across distortion magnitudes. In particular, plotting all Wide-ResNet architectures versus the optimal distortion magnitude highlights a clear monotonic trend across increasing network sizes (Figure 3b). Larger networks demand larger data distortions for regularization. A learned policy based on provides a fixed distortion magnitude (Figure 3b, dashed line) for all architectures thus is clearly sub-optimal.
Figures 3b and d (right column)also show something similar. It’s clear that models trained on smaller training sets may gain more improvement from data augmentation (e.g. 3.0% versus 1.5% in Figure 3c). This makes sense since the relative increase in data-size on the addition of another image is higher for smaller datasets. Interestingly, “Figure 3d demonstrates that the optimal distortion magnitude increases monotonically with training set size.” Combining both these factors, “this trend highlights the need for increasing the strength of data augmentation on larger datasets and the shortcomings of optimizing learned augmentation policies on a proxy task comprised of a subset of the training data. Namely, the learned augmentation may learn an augmentation strength more tailored to the proxy task instead of the larger task of interest.”
Namely, the learned augmentation may learn an augmentation strength more tailored to the proxy task instead of the larger task of interest
In a nutshell, RandAugment wins because it can scale in proportion to the data and network in a cost-efficient manner. This makes it extremely good for larger networks, and larger datasets.
Measuring Performance
Now that we understand what RandAugment does, and why it’s so effective, let's get into the details of the evaluations. By evaluating the different metrics used, we can understand potential extensions to the paper. It lets us evaluate the strengths of this technique by viewing performance across benchmarks.
Average

The average performance is stunning. RandAugment goes through a dramatically smaller. AA, the next smallest has a Nonillion times bigger search space. That is a difference of 1,000,000,000,000,000,000,000,000,000,000 times. Yikes. And RA still does better than it. PBA has the biggest search space. The number of possible solutions, is greater than the number of atoms in our Sun (by a factor of 10,000). RA beats that too.
Over different model sizes
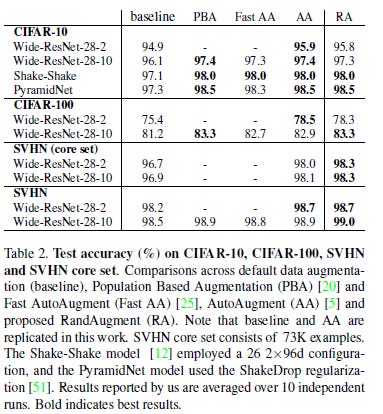
This table is a perfect representation of the point brought up in the Noise section.We see that as Model size increases, RA pulls ahead of the other Augmentation techniques. This is consistent across different architectures.
Image Classification (ImageNet)

ImageNet is the industry standard for Image Classification. RA sets itself apart from the other Augmentation techniques across all the architectures of ImageNet.
Object Detection
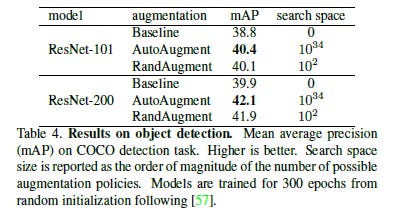
Object detection is a thriving area. It is crucial for self-driving cars and other such areas. In this task, we see RA have lower performance than AA. However, it’s interesting to note that RA still improves the baseline and is competitive with AA. This is impressive since AA uses 15K GPU hours, while RA was tuned on 6 parameters.
For Machine Learning a base in Software Engineering, Math, and Computer Science is crucial. It will help you conceptualize, build, and optimize your ML. My daily newsletter, Technology Made Simple covers topics in Algorithm Design, Math, Recent Events in Tech, Software Engineering, and much more to make you a better Machine Learning Engineer. I have a special discount for my readers.

Save the time, energy, and money you would burn by going through all those videos, courses, products, and ‘coaches’ and easily find all your needs met in one place.

I am currently running a 20% discount for a WHOLE YEAR, so make sure to check it out. Using this discount will drop the prices-
800 INR (10 USD) → 533 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
You can learn more about the newsletter here. If you’d like to talk to me about your project/company/organization, scroll below and use my contact links to reach out to me.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819