


AI Market Intelligence: March 2025
What are the most important AI Developments to watch for Founders and Investors

Sam L, you are an absolute legend. Thank you for forwarding my email. Ifykyk.
Also- thank you to everyone who reached out to me to meet me during my SF trip. I unfortunately wasn’t able to meet all of you (or reply to your messages- which is my bad)- but I’ll make sure to come by SF again. In the meantime, if you’re coming to NYC (or already live here)- shoot me a message and I’d love to meet you. Onwards with the main piece-
Given how many great developments are happening in AI these days, it’s impossible for me to write about all the important market trends individually. So, I’ve decided to start a monthly series talking about the most important developments in AI to ensure that I don’t miss anything important.
In this article, we will talk about the following-
A major acquisition in the startup world and why it’s much more important than you think (also, not to brag, but I’ve been pointing to the acquired startup as an excellent investment for 2 years now).
How a Tech Giant is silently collapsing from the inside (losing talent to competitors, internal struggles, leadership losing support, etc).
What you should focus on from DeepSeek’s Open Source Week.
2 extremely significant technical developments for AI Founders
and much more.
Normally, I would paywall something like this but we’ve had a lot of new readers recently (we’ve added 30K Substack Followers in the last 2 months), so consider this a welcome gift (and as a thank you to all you dedicated cultists that spread our gospel far and wide) this will be a free article. Let me know what y’all think.
Each of these articles takes a long time to research and write, and your premium subscription allows me to deliver the highest quality information to you. If you agree that high-quality work deserves compensation, please consider a premium subscription. We have a flexible subscription plan that lets you pay what you can here.
PS- Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.

Executive Highlights (TL;DR of the article)
Here are important pieces of information you should know-
1. Nvidia Acquires Gretel.AI: Synthetic Data Comes of Age
What Happened: Nvidia reportedly acquired Gretel.AI, a leader in generating synthetic data, in a nine-figure deal surpassing Gretel’s last valuation of $320 million.
Strategic Implications:
Deep Market Intelligence: Nvidia gains visibility into emerging AI applications through synthetic data consumption patterns, positioning them strategically for future chip specialization.
Integration into AI Stack: Beyond hardware, Nvidia is embedding itself deeply into the AI pipeline by controlling critical training data resources.
Synthetic Data Validation: This acquisition signals mainstream acceptance, boosting credibility and adoption.
On a more fuzzy level- this is great indication of Nvidia’s cut-throat and proactive culture, which increasingly seems like a competitive advantage when compared to the slow-moving pace of Big Tech. Speaking of which-
2. Google's Internal Crisis: How Culture is Beating Technicals
What's Happening: Based on various conversations I’m having Google faces increasing internal dysfunction, characterized by risk aversion, bureaucratic paralysis, talent drain, and intensifying internal conflicts.
Strategic Risks:
Technical Advantage Neutralized: Despite world-class AI research, Google’s culture undermines its ability to execute and innovate, severely weakening its market leadership.
Opportunity for Agile Competitors: Google's internal chaos presents opportunities for smaller, agile companies to exploit these weaknesses through poaching and by building competing products to steal market share.
As I’m writing this, I can’t help but compare Google to Leon Edwards- all the right attributes but hamstrung by a lack of urgency and killer instinct. Google, “Don’t let him bully you son!”.

3. MCP (Model Context Protocol): Standardizing AI Integration
What It Is: Anthropic's open standard for simplifying AI applications' connections with data sources and tools, functioning as a universal translator for AI agents.
Strategic Implications:
Accelerating Agentic AI: Enables widespread adoption of proactive, context-driven AI systems by standardizing data interaction.
Rapid Consolidation: Likely to trigger consolidation around key standards, positioning early movers advantageously.
Opportunities:
Vertical-specific middleware, workflow platforms, security/compliance tools, and infrastructure plays.
Adoption Challenge:
Success hinges heavily on rapid ecosystem adoption and community buy-in. Given the reception, this shouldn’t be a problem for the field, but standing out for individual players will be difficult.
4. GPT-3.5-turbo's Resurgence: Architecture Beats Raw Power
What Happened: Arcade.dev demonstrated that GPT-3.5-turbo (an older, cheaper model) could outperform newer models like o1-mini on complex tasks when given effective external tools.
Strategic Insights:
Architecture Over Pure Power: Effective design unlocks potential in less powerful, cost-effective models, shifting investment priorities toward better architecture rather than solely larger models.
No other lesson; reread that.
Go back and reread.
We’re not done there. Go back.
Make sure you embed (ha) that in your subconscious.
5. DeepSeek's Open Source Week: Building Agentic AI Foundations
What Happened: Chinese startup DeepSeek released five critical open-source tools addressing AI scaling and performance challenges.
The Tools:
FlashMLA: Faster attention mechanism for long sequences.
DeepEP: Simplified communication for Mixture-of-Experts (MoE) models.
DeepGEMM: Efficient matrix multiplication using FP8 precision.
DualPipe & EPLB: Optimized pipeline parallelism and load balancing for large model training.
3FS: High-performance distributed file system for AI workloads.
This is huge for developers, and I expect a lot of possible startups to pop up arounf this space, especially around tools like 3FS (high-performance file system) and DeepEP (simplified MoE model management).
Of everything that happened in AI, these are the spaces I would look at most closely. Let’s break them down more closely.
Nvidia acquires Gretel
Nvidia has reportedly acquired Gretel, a San Diego-based startup that’s developed a platform to generate synthetic AI training data. Terms of the acquisition are unknown. The price tag was said to be nine figures, exceeding Gretel’s most recent valuation of $320 million
Nvidia made a huge acquisition of the synthetic data provider Gretel. This stands out to me for several reasons-
I’ve been bullish on synthetic data for a long time since it has very strong synergistic flywheels with some of the most important aspects in Tech right now (HPC, AI, Climate Science, etc). Gretel is the best provider of Synthetic Data.
The move into Synthetic Data might seem random but it serves a few benefits- it deepens Nvidia’s place in the AI Training stack (Gretel is used everywhere, and Synthetic Data is itself key for many future developments in the Tech, such as Quantum Computing and Green Energy). Nvidia’s acquisition of Gretel is going to provide tons of market intelligence on what fields are buying the data for next-gen systems (and, thus, how Nvidia should specialize their upcoming chips to stay ahead). The added revenue and diversification also can’t hurt.
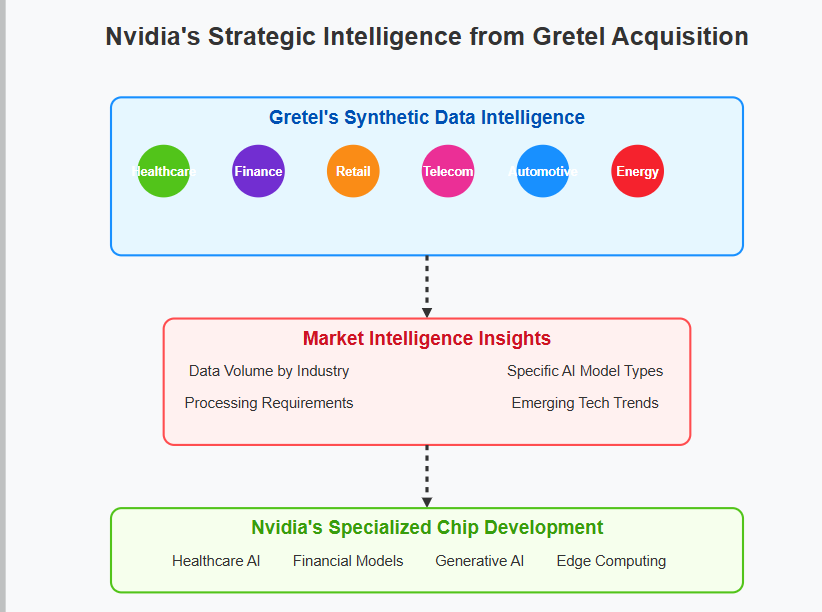
I’ve been skeptical of Nvidia’s ability to justify their valuation, especially in a world where their biggest customers will also make their own chips. However, this acquisition is a good indicator of what would make Nvidia a good buy- its proactive culture. By far, they are the most active tech company in seeking out the next play, and this culture will allow them to outcompete the hyperscalers who are moving much slower (Google, for example, had a great in with Gretel but fumbled the bag).
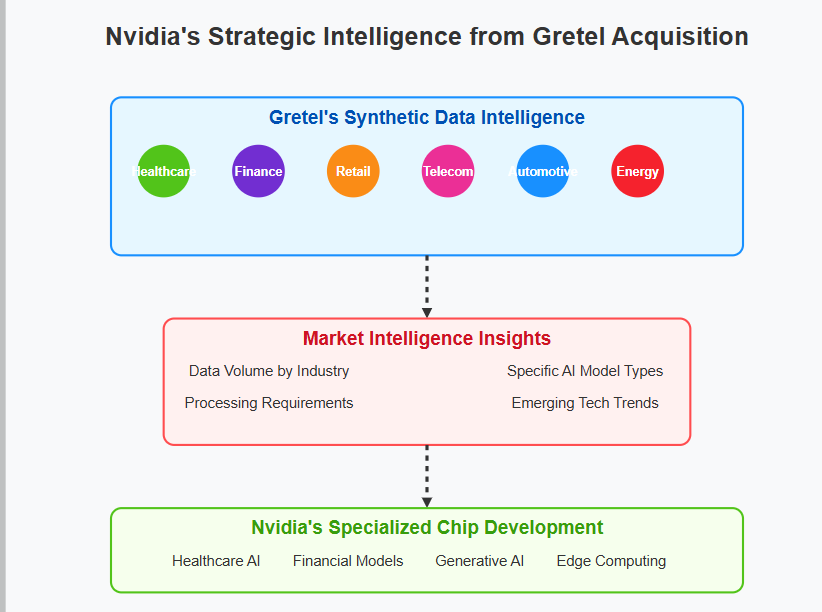
As a tech guy, I used to base many of my earlier opinions on tech and business fundamentals. However, as I’m growing a bit wiser in the ways of the world and internal company politics, I think culture might be the bigger factor in determining the long-term success of a company. And that skews heavily towards Nvidia. To quote our earlier piece on DeepSeek-
I don’t know enough about the technicalities of this, but from my several conversations within these groups- Nvidia seems to have a better killer instinct and culture. The fundamentals still seem to skew toward hyperscalers, so pick your poison based on what you think is more important (I’m personally biased towards Culture, especially given that Nvidia does have the paper and team to push).
If you’re an investor or a founder, I would bet heavily on Synthetic Data. There is still space in the market, especially when it comes to more specialized generations of Synthetic Data or in related fields like automated review of datasets that spike up in demand with an increased use of Synthetic Data). However, these gaps will get wiped out quickly if you don’t act on them.
We will now move to the other end of the culture spectrum. Let’s talk about a tech giant choking itself.

WTF is going on at Google
Multiple sources tell me that Google is having a rough go-
There is a strong sense of risk aversion choking development and releases. Ironically, this also leads to a lot of panic and rushed releases (such as with Gemini, which, while powerful, is also an extremely unstable model that breaks very randomly).

A snippet of my conversation with a source at Google. Redacted personal information. Competitors and Startups are snatching some of their best talent.
The bureaucracy creates an interesting tension- very motivated employees aren’t able to push things through, and other, less motivated employees hide behind the bureaucracy as an excuse to not contribute anything. This is a classic left hook, right cross for company culture, and it’s breeding a culture of complacency and resentment.

Many key technical employees are more openly turning hostile against management, and I hear some people are even gearing up for power struggles. None of this bodes well for the Big G. I wouldn’t be too surprised if we see some major shakeups over there. Bets anyone?

For the longest time, I’ve been positive about Google as a company. I’ve always felt like many recent crashes of their stock were based on nonsensical reasons and a misunderstanding of AI (something we’ve covered here on many occasions). And their research teams continue to churn out masterpiece on masterpiece, which is true even now. However, at this stage, I’ve lost faith in them as a company, and they need a Dr. Gero to deep clean their useless Yamcha guts.
As an example of how much the culture has decayed, let’s look at the recent Mistral release. Much was made of their OCR model outperforming giants like Google and OAI-
Mistral OCR has shown superior performance in benchmarks against other leading OCR models, including Google Document AI, Azure OCR, and OpenAI's GPT-4o. It scored an overall accuracy of 94.89, excelling particularly in mathematical expressions, scanned documents, and table recognition.
Mistral OCR can handle a vast range of scripts, fonts, and languages, which is crucial for global organizations dealing with diverse documentation. The API processes up to 2000 pages per minute on a single node, ensuring high throughput for demanding environments.
However, this misses a very crucial (but hilarious nuance). Google’s Document AI isn’t their best OCR model. Gemini 2.0 is cheaper, better, and absolutely sons the competition- which is why more and more people I know are all using it aggressively for OCR.
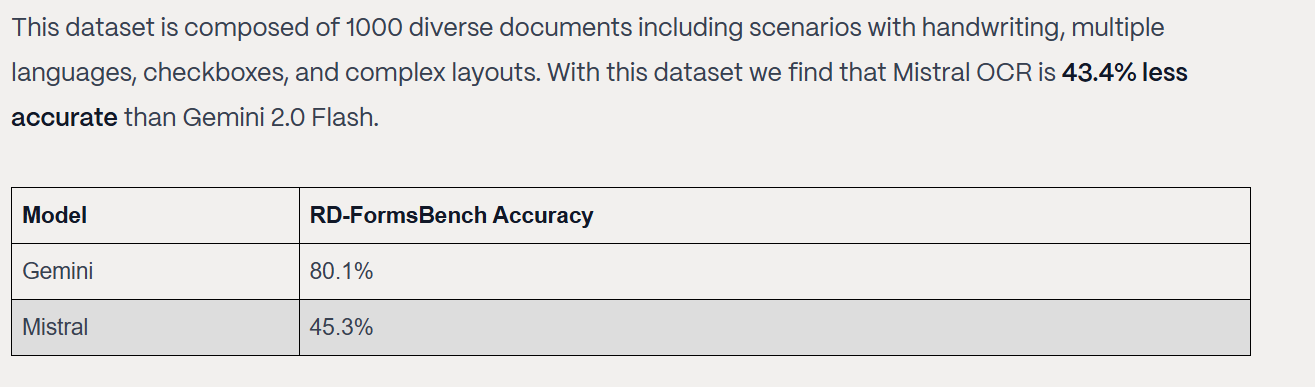
However, this hasn’t been integrated into Google’s Document AI, allowing Mistral to parade their victory over Google, mostly unchecked. You’ll see issues like this everywhere. I’m probably one of the 4 people in the world that knows that Google Cloud has a video embedding model on GCP (1 other person being someone I paid to test it). However, there’s a good reason that this hasn’t become more prominent- the video embedding model is bad. Really bad. It’s hard to use, performance is okay (not bad, but no audio and the video retrieval is hit or miss), and runs into all kinds of errors.
Google could have easily upgraded this with their VideoPrism (or at least provided an easy API as an alternative), but instead, this very promising foundation model has been relegated to the shadow realm- right next to any chances of Vegeta fans seeing our GOAT get a meaningful W.
This is the same company that released their Bard model wrapped around Lambda and not PaLM, even though the latter was multi-modal, high performing, and had diverse sets of capabilities- in early 2022 (months before ChatGPT was released).
I’m not in the business of player-hating, so I’m going to move on but I really hope the point is clear. Google has been extremely negligent in execution, and if this slovenly culture of eating cake continues, then heads will roll.
Control Devansh, Control. No more player-hating. Let’s move to something cheery.
MCP deserves the Hype it’s Getting (and How to Profit from It)
Usually, when LinkedIn influencers start talking about how an AI will transform the world and finally get the aliens to drop in on a visit- I turn the other way. However, even very broken clocks are right twice a day.
The Model Context Protocol (MCP) is an open standard developed by Anthropic to streamline the connection between AI applications and various data sources and tools. By offering a universal interface, MCP eliminates the need for custom integrations for each data source, allowing AI systems to access and utilize external information more efficiently. This standardization enhances AI capabilities, simplifies development, and promotes scalability in AI applications.
 and How It Works")
MCP aligns very well with the great Agentic Rebuild- where our internet and apps are being designed to be interactive with Agents- since it will allow Agents a standard way to interact with all the data streams by abstracting away the API changes that are bound to happen with any data/interface provider.
This is a fantastic development in AI infrastructure, and I would invest heavily in this. The best part- unlike other AI infra plays- is that this isn’t capital intensive and is thus an excellent place for more resource-strapped startups to come in and have outsized ROIs. Good talent and distribution will be key, but that’s where investing in the right Open Source communities would be key. Speaking of which, your boy has his own- with access to millions of potential active contributors, investors, and consumers. Investing there would give you access to the best talent, startups, market intelligence, and more. Nudge, nudge, wink, wink.
If you’re looking for some specific, actionable tips (aside from funding my community- which will have the best ROI), here’s a breakdown of what I would do, based on the multiple conversations I’ve had-
For Founders Building on MCP
Build Vertical-Specific Agent Middleware
Example: Middleware that transforms legacy enterprise APIs (Salesforce, SAP) into MCP-compatible formats.
Action: Develop lightweight, no-code adapter tools ("Zapier for MCP") allowing non-technical users to map internal data to MCP standards. Monetize through enterprise custom integrations.
Launch an MCP-Native "Agentic Workflow" Platform
Example: A platform enabling users to chain MCP-connected data streams (e.g., Slack + Google Sheets + Snowflake) into automated agent workflows.
Playbook: Partner early with Anthropic adopters (startups utilizing Claude API) to develop practical, customer-driven workflows.
Solve MCP’s "Cold Start" Problem
Gap: MCP’s growth depends on wide adoption by data providers.
Action: Create an open-source toolkit for auto-generating MCP wrappers for common databases (PostgreSQL, AWS S3). Generate revenue through enterprise support contracts.
Create an MCP-Powered Real-Time Data Marketplace
Example: A marketplace aggregating live data (weather, logistics, social media) standardized via MCP.
Revenue Model: Premium data subscriptions or revenue-sharing agreements with data providers.
Develop Security & Compliance Tools for MCP
Need: Enterprises require robust governance tools (audit trails, access controls, data anonymization).
Action: Build an MCP governance layer offering granular permissions (e.g., agent access limited by specific conditions).
For Investors Backing MCP Startups
Bet on Startups Abstracting MCP Complexity
Target: Solutions simplifying MCP adoption for sectors unfamiliar with AI integrations (healthcare, manufacturing).
Example: When I was traveling in Tampa, I had a conversation with an almost retired factory engineer who told me about the potential of AI in manufacturing (completely unprompted, he didn’t know I work in AI), so MCP and IoT for manufacturing seem like a winning play.
Invest in MCP’s "Agentic Orchestration" Layer
Opportunity: As agent-driven workflows grow, startups managing inter-agent collaboration become vital.
Example: Platforms routing tasks between specialized agents (billing, customer support) via MCP-based unified data access.
Back MCP-Aware Infrastructure Startups
Example: Monitoring tools dedicated to MCP-enabled AI systems, tracking key metrics like latency, data freshness, and integration errors.
Edge: Position as the specialized "Datadog for Agentic Systems."
Based on early, very hacky calculations, MCP could significantly reduce agent integration costs (by up to 70%), benefiting infrastructure-focused startups. Founders should target vertical solutions and adoption tools, while investors prioritize teams embedded in AI engineering networks, positioning for early infrastructure wins rather than consumer-focused apps.
This isn’t the only Agent Related development that Founders should pay attention to-
How to Beat o1-mini with GPT-3.5-turbo
Most of you probably aren’t old enough to remember GPT-3.5-turbo, the oldest model that can call functions (tools). The folks over at Arcade.dev went on to show that there was still some life in Old Yeller and had the OG deliver a 50’s style spanking to the young one. The secret - tool calling.

Here’s the passage that matters- “Even when we expanded the experiment to include 20 different math tools, the model still got every answer right…
This result doesn’t mean that 3.5 Turbo is “smarter” than newer models like OpenAI o1 or Claude 3.7 Sonnet. But it does show that giving LLMs a set appropriate tools can greatly increase their real-world usefulness… Just like people, LLMs can perform much better when equipped with good tools. On their own, powerful reasoning models like o1-mini and o1-preview struggle to do big math. But when given a calculator tool, GPT 3.5 Turbo solves the problem cheaper, faster, and with zero mistakes. For context, using o1-mini is expensive ($1.10/$4.40 per million input/output tokens), while 3.5 Turbo is significantly cheaper ($0.50/$1.50 per million input/output tokens) – about 40% of the price of o1-mini and only 3% of the price of o1!
Not too bad for a model released 3 years ago, huh? If you're deploying AI products at scale, this is a critical consideration to make when designing your systems.”
The before and after of the GPT 3.5 using tools to tackle the tasks looks like it’s straight out of a Fair n Lovely ad-
Without Tools-

With Tools-

All in all, this leads to an important point that people are overlooking- so much of AI Engineering isn’t an intelligence play; it’s an architecture play. Even many of the older models have a lot of untapped intelligence that can be unlocked by good design. Conversely, even very powerful models can be hard-nerfed if you design your architecture with the creativity of women (or guys I hear, but I can only speak on one end of the spectrum) that start every fucking conversation with a “hey”, “sup”, or “wyd” (lower caps intentional).
This FYI is one of the biggest mistakes made in most prompt engineering pipelines I’ve reviewed- it throws too much junk at the LLM, nuking the performance.

Modularity: Modularity is the practice of dividing a system into smaller, self-contained components or modules that can function independently. We want modular systems because they reduce complexity and allow teams to focus on individual components without interference. Agentic AI naturally supports modularity by using specialized agents for tasks like data querying or response generation. This isolates errors and allows for easy reuse of components across projects.
Scalability: Scalability is the ability of a system to handle increasing workloads or larger data volumes without sacrificing performance. Given that Tech is most profitable when leveraging economies of scale, the importance of this should be clear.
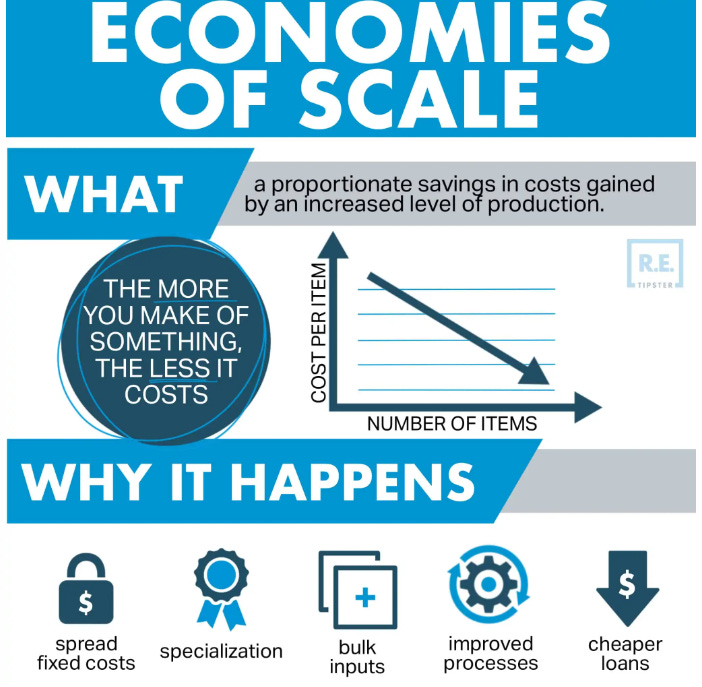
Agents are great here for two reasons. Firstly, Agents enable the development and maintenance of more complex systems- which increases the amount of things you can do. Secondly, Agents can reduce your computing costs per task by reducing the number of more expensive LLM calls for certain tasks by replacing them with cheaper processes.
Separation of Concerns: Separation of Concerns involves organizing a software system into distinct sections, each focusing on a specific functionality. This simplifies development, reduces complexity, and minimizes the risk of unintended side effects when making changes. Agentic AI (I’m getting tired of typing this, so will just use AAI) embodies this principle by assigning specific roles to individual agents.
Loose Coupling: Loose coupling is the practice of minimizing dependencies between components in a system. This principle ensures that changes or failures in one part of the system do not propagate to others, making updating, maintaining, or replacing components easier. Similar to above, specialized Agents allow us to build and change functionalities without impacting the larger setup much better than with traditional LLMs.

Robustness: Robustness is the ability of a system to maintain functionality and performance even when faced with errors, unexpected inputs, or partial failures. This principle is especially crucial for critical domains like healthcare or legal applications, where the vulnerability of LLMs to minor changes to inputs can be very problematic. AAI boosts this in two ways- the scalability adds robustness toward one of the biggest problems in tech (overload causing weird behavior) and the separation of concerns + Loose Coupling is very helpful in helping us isolate and track errors.
Consistency: Consistency ensures that a system behaves predictably and uniformly across its operations, something traditional LLM Systems lack at the moment. Consistent systems reduce confusion for users and make debugging + development more straightforward by providing reliable outputs. Consistency is one of the biggest improvements that Agentic Systems can provide for LLM based systems in several ways byincreasing the usage of more deterministic/stable components and reducing the amount of “entaglement” by limiting the uneccesary context that LLMs have to interact with (this is a bigger problem than you’d think). I’m not going to elaborate too much on this because even though this is an extremely important benefit- I don’t have that much to say about this specifically.

What You Should Know DeepSeek's Open Source Week
Chinese AI startup DeepSeek just dropped five open-source tools in a single week, tackling some of AI's biggest scaling challenges. This isn't just a PR move; it's a strategic play that could reshape the AI landscape, particularly for startups and investors. Here's a breakdown of what was announced and why it matters.
The Big Picture: Open Infrastructure for the Agentic AI Era
DeepSeek's "Open Source Week" signals a shift towards open, collaborative development of AI infrastructure. As the industry moves towards agentic AI (where AI agents proactively perform tasks), DeepSeek is betting that this future will be built on shared, high-performance foundations, not proprietary tech. If the bet pays off, this will give Deep Seek a lot of visibility into tech stacks, which should help its parent company (a hedge fund) in making better trades by providing a very strong source of alpha.
Let's dive into the specifics of the tech
Day 1: FlashMLA - A Faster Attention
What it is: FlashMLA is a highly optimized kernel for Multi-head Latent Attention (MLA) decoding, specifically for NVIDIA Hopper GPUs. It supercharges the transformer decoding process, especially for long sequences.
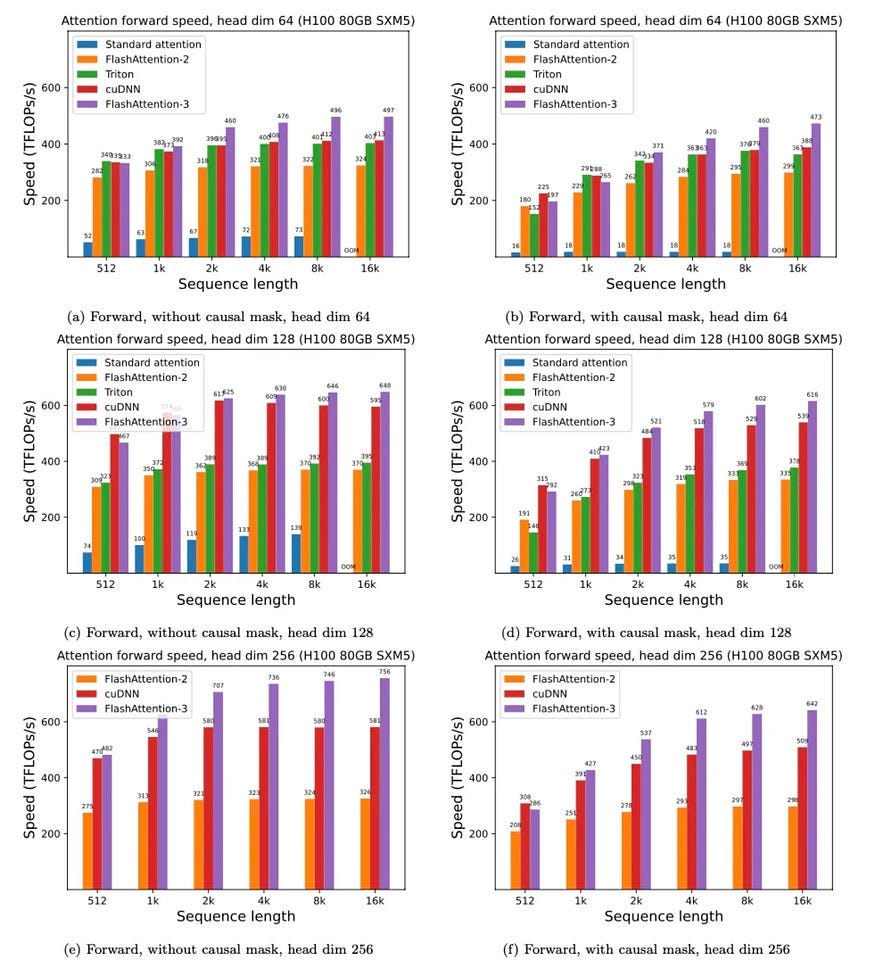
Technical Highlights:
Extreme Performance: Achieves up to 3000 GB/s memory bandwidth and 580 TFLOPS on an H800 GPU.
Memory Optimizations: Uses BF16 precision and a paged key-value cache to reduce memory usage and speed up lookups for long sequences.
Production-Ready: Designed for easy integration into PyTorch workflows.
Based on FlashAttention and NVIDIA's CUTLASS.
Why it Matters:
Startup Superpower: Enables small teams to achieve high-end model performance without massive infrastructure.
Latency-Sensitive Applications: Ideal for finance, healthcare, and other areas requiring real-time AI responses.
Infrastructure Disruption: Erodes the performance advantage of incumbents, favoring those who iterate quickly on open tools.
5,000+ GitHub stars in 6 hours
Day 2: DeepEP - MoE Made Simple
What it is: DeepEP is an open-source communication library for Mixture-of-Experts (MoE) models. MoE allows for massive models by distributing them across many "expert" modules. DeepEP tackles the communication bottleneck in MoE training.

Technical Highlights:
Efficient All-to-All Communication: Custom GPU kernels minimize latency in data transfers between experts.
Multi-Node Scaling: Works across GPUs within a server (NVLink) and across servers (RDMA).
Dual Modes: Optimized for both high-throughput training and low-latency inference.
FP8 Support: Enables efficient communication with reduced precision.
I’m very excited about this, given that DS (and many other leading) LLMs use MoE, but it can be intimidating to a lot of smaller developers since handling MoE is a nightmare. Of all the shares, either this, the next share, or the 3FS file system will likely become the most important contributions in the long run.
Day 3: DeepGEMM - Using 8-bits for Efficiency
Technical Highlights:
FP8 Acceleration: Achieves over 1,350 TFLOPS on Hopper GPUs using 8-bit floating-point arithmetic.
Minimalist Codebase: ~300 lines of core code with no heavy dependencies, using just-in-time (JIT) compilation.
Versatile: Supports dense and MoE-specific sparse matrix layouts.
Outperforms Expert-Tuned Kernels: Beats or matches vendor-optimized libraries in many benchmarks.
This reminds me of the MatMul Free LLMs, which I’m still hoping will get more of a comeback-
Day 4: DualPipe & EPLB - Training at Scale, also made simple
What it is: DeepSeek released two tools for optimizing large model training:
DualPipe: A bidirectional pipeline parallelism algorithm that minimizes GPU idle time.
EPLB (Expert-Parallel Load Balancer): Dynamically redistributes workloads in MoE models to improve GPU utilization.
Technical Highlights:
DualPipe:
Overlaps forward and backward passes in pipeline training.

Aims for near 100% GPU utilization.
Eliminates pipeline stalls.
EPLB:
Balances workloads across experts in MoE models.
Minimizes idle time and improves throughput.
Adjusts expert assignments to physical devices.


Day 5: 3FS - The File System for High Performance AI
What it is: 3FS (Fire-Flyer File System) is a distributed file system designed for the extreme I/O demands of AI training and inference.
SmallPond: Lightweight data processing framework.

Technical Highlights:
Parallel, Distributed Design: Spreads data across nodes for high throughput and low latency.
Optimized for SSDs and RDMA: Leverages modern hardware for maximum performance.
Scalability and Synchronization: Handles massive datasets and concurrent access efficiently.
Benchmark Read Speeds up to 6.6 TiB/s:
Open and Extensible: Allows for customization and integration with existing infrastructure.
I wouldn’t be surprised to see startups built around this file system and/or smallpond.
If I were a founder or investor, these are the spaces I would monitor most closely for possible startup ideas or investments.
Which of these would you get into? Is there anything that I missed? Let me know by reaching out.
Once again, if you think such work is valuable and would like to support more of my writing, please consider a paid subscription here-
And share this with people who might benefit here-
Thank you for being here and I hope you have a wonderful day.
God’s Favorite
Dev <3
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast (over here)-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Where can one find the Arcade.dev blog post or paper??
I am struggling to find it. Thanks!
👏👏