
DeepMind's AlphaGeometry is the Mona-Lisa of LLMs[Breakdowns]
If you want to build your system around LLMs, take careful notes

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 250K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights-
Deepmind’s “Solving olympiad geometry without human demonstrations” gained a lot of attention for developing AlphaGeometry, an LLM-based system that matches human expert performance in solving Olympiad Geometry questions. This has long been a benchmark for AI systems, and its significant improvement over previous systems (2.5x improvement over SOTA) warrants all the attention it gets.

Naturally, such a performance led to a lot of hype, with Deepmind’s leader even calling it a step towards AGI (in a now-retracted statement). All of the noise around AGI however detracts from something much more important- AlphaGeometry is a beautiful piece of engineering and system design. Anyone looking to build products or services around LLMs/Multimodal AI should study AlphaGeometry and take notes on how to design their products.
On a test set of 30 latest olympiad-level problems, AlphaGeometry solves 25, outperforming the previous best method that only solves ten problems and approaching the performance of an average International Mathematical Olympiad (IMO) gold medallist. Notably, AlphaGeometry produces human-readable proofs, solves all geometry problems in the IMO 2000 and 2015 under human expert evaluation and discovers a generalized version of a translated IMO theorem in 2004
The power of AlphaGeometry lies in its design. It splits algorithmic problem-solving into two distinct sub-routines-
The Inspiration: Where you need to identify the one step that will unlock the solution/get you closer to the final proof. This stage requires some creativity as your AI would have to identify steps that aren’t obvious.
The Deductions: Once you have the magic step, you need to progress with a series of steps to get to the final solution/reach the next stage. This routine requires precision (missing a few little details will completely skew your proofs), efficiency (lots of little steps), and accuracy (things have to be correct, always).
The way I see it, this is like 40m Toni Kross through ball to Vini, who takes it down perfectly, beats the last man, and scores. Subroutine 1 produces aesthetic assists, while the little mechanical steps to finish things are done by subroutine 2. If you read the recent, “How to Pick between Traditional AI, Supervised Machine Learning, and Deep Learning”, it will not surprise you that we use an LLM for subroutine 1 and a symbolic engine for subroutine 2. These 2 work in loop. “Given the problem diagram and its theorem premises, AlphaGeometry first uses its symbolic engine to deduce new statements about the diagram until the solution is found or new statements are exhausted. If no solution is found, AlphaGeometry’s language model adds one potentially useful construct , opening new paths of deduction for the symbolic engine. This loop continues until a solution is found.” The process is visualized below:
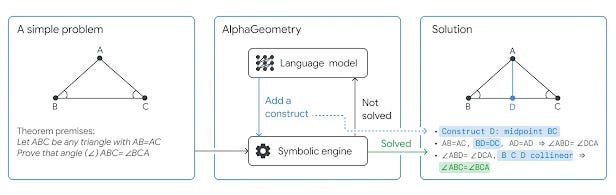
This seemingly simple design is amazing for a simple reason, it leverages the strength of each kind of system while minimizing the weaknesses. As we’ve discussed many times, LLMs are expensive, unreliable, and unexplainable. This is not the death sentence that many doomers pretend it is, but it does mean that we should use them only when none of these three are critical requirements. This meets all the boxes (even hallucinations, which are the topic of much angst, aren’t a problem over here). GOFAI on the other hand struggles with rigidity, stopping when there isn’t a clearly defined protocol for proceeding. This part is outsourced to the Language Model. They complement each other perfectly.
AlphaGeometry’s output is impressive because it’s both verifiable and clean…It uses classical geometry rules with angles and similar triangles just as students do.
-Evan Chen, math coach and former Olympiad gold-medalist, who verified some of the proofs
In this breakdown, I want to focus on the data preparation that enables AlphaGeometry. While the specifics of this might not be relevant to you, the design principles are worth noting. We will end on a note about the impacts of pertaining and fine-tuning on performance, to highlight the importance of developing congruent parts in your systems.

PS- I highly recommend checking out their Github over here. It’s a great demonstration of how any LLM-enabled application requires a lot of engineering to work (keep in mind, this is not even a system that’s deployed in a live app). Don’t underestimate the importance of traditional software engineering for your AI systems. Powerful AI systems require a LOT of infrastructure and maintenance work.
Data Preparation
The first thing of note is how Deepmind preps the data for the experiments. Especially when it comes to LLMs, Data Preparation can be one of the highest ROI investments you make. Well-prepared data will beat any Vector DB, SOTA Foundation Model, or any amount of fine-tuning.
Immediately what stands out to me is their use of synthetic data for training. I think their utilization of synthetic data might be a hint that they are exploring similar approaches in other domains and that AlphaGeometry is meant to be the preview to a new system of training at Google. In that case, it would make sense to experiment with a large amount of purely synthetic data, to see how this approach might be expanded. Speculation aside, here is the play-by-play of the training process-
“We focus on Euclidean plane geometry and exclude topics such as geometric inequalities and combinatorial geometry.”- Not to be petty, but so much for all the commentators claiming “general” intelligence. Also, by focusing on Euclidian Geometry, we don’t have to worry about LLMs and their tendency to get funky when numbers get involved.
“By using existing symbolic engines on a diverse set of random theorem premises, we extracted 100 million synthetic theorems and their proofs, many with more than 200 proof steps, four times longer than the average proof length of olympiad theorems.”- This is super-duper clever. Since this is all machine-generated, it will serve as higher quality input compared to human uses (which might have less structure, since our brains work very differently).
“We further define and use the concept of dependency difference in synthetic proof generation, allowing our method to produce nearly 10 million synthetic proof steps that construct auxiliary points, reaching beyond the scope of pure symbolic deduction.” — I like your funny words magic man:). The tricky phrase here is “dependency difference” which in simple words is just the set of terms that the premises don’t contain, that we need to reach the conclusion.
“Auxiliary construction is geometry’s instance of exogenous term generation, representing the infinite branching factor of theorem proving, and widely recognized in other mathematical domains as the key challenge to proving many hard theorems”- Auxillary Construction is the smarter way of saying our LLM makes shit up, and hope that what is created will help our engine reach the conclusions. This is the inspiration sub-routine we talked about earlier.
“We pretrain a language model on all generated synthetic data and fine-tune it to focus on auxiliary construction during proof search, delegating all deduction proof steps to specialized symbolic engines.”- A great demonstration of how we should aim to constrain the use of any AI to clear, narrow scopes.
Another important how they calculated the final scores. Olympiads are scored b/w 0–7 instead of a binary (yes/no). Human scores are rescaled appropriately, to allow for comparisons. “For example, a contestant’s score of 4 out of 7 will be scaled to 0.57 problems in this comparison.”
Some of you might be wondering how we create the synthetic proofs for the AI. Let’s discuss that part of the process.
When producing full natural-language proofs on IMO-AG-30, however, GPT-4 has a success rate of 0%, often making syntactic and semantic errors throughout its outputs, showing little understanding of geometry knowledge and of the problem statements itself. Note that the performance of GPT-4 performance on IMO problems can also be contaminated by public solutions in its training data. A better GPT-4 performance is therefore still not comparable with other solvers. In general, search methods have no theoretical guarantee in their proving performance and are known to be weaker than computer algebra methods
-Just because it seems like LLMs can do something, doesn’t mean they do them well. The illusion of competence is especially strong with LLMs, so be extra careful with your design and testing.
Creating Synthetic Proofs
The first step is to sample a random set of theorem premises, “serving as the input to the symbolic deduction engine to generate its derivations”. A full list of actions is given below-

“Next we use a symbolic deduction engine on the sampled premises. The engine quickly deduces new true statements by following forward inference rules as shown in Fig. 3b. This returns a directed acyclic graph of all reachable conclusions. Each node in the directed acyclic graph is a reachable conclusion, with edges connecting to its parent nodes thanks to the traceback algorithm described in Methods. This allows a traceback process to run recursively starting from any node N, at the end returning its dependency subgraph G(N), with its root being N and its leaves being a subset of the sampled premises. Denoting this subset as P, we obtained a synthetic training example (premises, conclusion, proof) = (P, N, G(N)).” This is visualized as

This sets up the data. But what about the symbolic engine that comes with the conclusions? That has two striking components. We have a deductive database (DD) and algebraic rules (AR). “The DD follows deduction rules in the form of definite Horn clauses, that is, Q(x) ← P1(x),…, Pk(x), in which x are points objects, whereas P1,…, Pk and Q are predicates such as ‘equal segments’ or ‘collinear’. ” DDs are solid contenders on their own, but ARs are needed to take our team through the playoffs. “AR is necessary to perform angle, ratio and distance chasing, as often required in many olympiad-level proofs. We included concrete examples of AR in Extended Data Table 2. The combination DD + AR, which includes both their forward deduction and traceback algorithms, is a new contribution in our work and represents a new state of the art in symbolic reasoning in geometry.”

Our all-star duo of DD+AR can run the plays well, but they lack the creativity to push things on their own. That is where the LLM comes in. “We first pretrained the language model on all 100 million synthetically generated proofs, including ones of pure symbolic deduction. We then fine-tuned the language model on the subset of proofs that requires auxiliary constructions, accounting for roughly 9% of the total pretraining data, that is, 9 million proofs, to better focus on its assigned task during proof search.”
We serialize (P, N, G(N)) into a text string with the structure ‘<premises><conclusion><proof>’. By training on such sequences of symbols, a language model effectively learns to generate the proof, conditioning on theorem premises and conclusion
-Adding structure to your text when training your LLMs can save you a lot of effort in training. Even if it’s not super impressive, just giving LLMs something to hold on to can be useful.
Some of you might be looking at the scale of the training and wondering if you can do this yourself. And if the associated costs will be worthwhile. Let’s end on that.
A note on the importance of pretraining, fine-tuning, and model selection
The importance of fine-tuning is one of the more pressing questions in AI, especially after multiple teams and startups have dedicated their existence to building some variant of talk-to-your-data chatbots. Let’s take a look what this research might teach us about this. For that let’s zoom in on the performance of the performance of DD+AR, and how various AI-Enablers add to them.

Firstly, the impact of the GPT-4 auxiliaries is almost negligible. This is a clear demonstration of why we need to pick tools that are best fits for the particular job, instead of blindly attempting a GPT-4 plug-n-play. Feel free to ignore all the noise around benchmarks and performance, and focus your attention on experimentation to see how different types of LLMs work for YOUR problems.
In principle, auxiliary construction strategies must depend on the details of the specific deduction engine they work with during proof search.
-A quote from the authors. Congruence with your system>> individual model performance
Most notable to me is the benefit of using a baseline customized transformer (described in the Methods section) of 151 Million Parameters. Even without pretraining, the performance of our system jumps up to 21 (and pretraining w/o fine-tuning takes you to 23). This clearly shows the importance of domain-specific foundation models (although I would be curious to see how something like Galactica or Phi, would perform).
This also clearly lays out the importance of preparing your data and making your system more congruent with your LLMs, instead of trying to use the biggest LLMs to power through badly structured data, identify inappropriate requests, perform high-quality multi-source IR, AND then present this information in the perfect format. My clients are consistently surprised by how much time I recommend for data-pipeline reengineering, better indexing, etc. over things like Prompt Engineering and Fine-tuning. This is a great demonstration of why.

Again, that is not to say that tuning, prompting strategy, etc are not important. They have their place, but they shouldn’t be the focus for early iterations of your products. Invest that time into your data and AI-enabling infrastructure, and you can pivot into whatever you want later down the line.
All in all, this is a great publication with a lot to teach us. Also between the two of us, part of the reason I really like it is because of how it seems to affirm much of what I’ve been saying about LLMs for the last ~1.5 years. So if you are to take nothing else away from this breakdown or from Deepmind work, just remember this: I am a genius and your company should be willing to go into debt to hire me for your AI Projects. That is the real recipe for success. A young, struggling Silicon Valley entrepreneur once did, and today you may know him as Bill Gates. In fact, he was so happy with my work that he made this (totally not photo-shopped) image of us-

No further comments needed.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
A tightly coupled system with a traditional rule based component and hallucinations of generative AI. I think this is huge and a path to way forward.