


Fine Tune or Scale Up? OpenAI's Overlooked Experiments Say a Lot[Guest]
What we learned when specialized AI faced off against general models for software engineering- and why it matters.

Hey, it’s Devansh 👋👋
Our chocolate milk cult has a lot of experts and prominent figures doing cool things. In the series Guests, I will invite these experts to come in and share their insights on various topics that they have studied/worked on. If you or someone you know has interesting ideas in Tech, AI, or any other fields, I would love to have you come on here and share your knowledge.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Mradul Kanugo leads the AI division at Softude. He has 8+ years of experience, and is passionate about applying AI to solve real-world problems. Beyond work, he enjoys playing the Bansuri. Reach out to him on LinkedIn over here or follow his Twitter @MradulKanugo. Some of you may remember his earlier guest posts on Prompt Testing for LLMs and on How to solve complex software engineering tasks with AI-Agents.
I’ve come to genuinely love Mradul’s work- it’s insightful in a researchy way, but always firmly grounded in practical realities. His approach offers a refreshing alternative to typical AI + Engineering discussions, which often get lost in abstract hypotheticals and endless “what ifs.” This article continues that trend. Today, he'll be exploring:
OpenAI’s Experiment: AI vs. Competitive Programming
The Models: GPT-4O, O1, O1-IOI, and O3
The Testing Ground: CodeForces
Round 1: Language Models vs. Reasoning Models
How Reinforcement Learning Improved Results
GPT-4O vs. O1: Which Performed Better?
Round 2: General vs. Specialized AI
How O1-IOI Was Fine-Tuned for Competitive Programming
Inside O1-IOI’s Winning Strategy
Did Specialization Pay Off?
Round 3: Fine-Tuned Model vs. More Powerful General Model
Meet O3: Simpler, but Stronger?
Why O3 Outperformed Specialized Models
Key Takeaways
Reasoning Models Beat Language Models
More Training Means Better Performance
Fine-Tuning vs. General AI: What’s Smarter?
Bigger Models Usually Win—But Not Always
Conclusion: What This Means for You
Should You Specialize Now or Wait for Better Models?
Preparing for the Future of AI in Programming
I’m about to release an article on Vibe Coding soon, so this is a great way to introduce the theme. I’m sure you’ll love this article as much as I did (if you do, please message Mradul and tell him how good he is; I’ve been pushing him to start sharing his insights more regularly for a while, and hopefully, your message is the encouragement that gets him going). On with the article-
There are enough speculations about what AI will do to the programming business. Do programmers still have a chance? Would AI ever be able to do algorithmic questions, understand the real-life constraints like memory, time complexities? These are questions that have been floating around for a while. Today, let's dive deep into one fascinating experiment that OpenAI conducted to find some answers.

What's In It For You?
This isn't just another AI vs Human story. We're going to unpack:
How AI performs in competitive programming
The eternal debate: Is it better to perfect your pipeline or wait for a bigger model?
What happens when you pit a fine-tuned model against a more generally trained one?
The Premise
Here's an interesting experiment that OpenAI carried out. They wanted to make their models fight the competitive programming battle and understand where the leverages are. They took four different models:
Traditional GPT-4O (Large Language Model)
O1 (Large Reasoning Model)
O1-IOI (Fine-tuned specifically for competitive programming)
O3 (More advanced reasoning model)
The battleground?
CodeForces - a platform that hosts live programming contests where participants solve complex algorithmic problems under time constraints. Each problem typically has multiple subtasks, and the scoring is based on how many of these subtasks you can solve.
But here's the crucial part - how did they ensure the experiment was fair?
OpenAI implemented multiple safeguards:
All test contests occurred after the training data cut-off
They used embedding search to verify the model hadn't seen these problems
They simulated real contest conditions, including time and memory constraints
The First Battle - LLM vs LRM:
Now, this is where things get really interesting. The first showdown was between GPT-4O (a traditional language model) and O1-preview (a reasoning model). But before we dive into the results, let's understand what makes these models fundamentally different.
What exactly is a Large Reasoning Model (LRM)?
LRMs are language models trained via reinforcement learning to "reason" and "think through" extended chains of thought. DeepSeek recently illustrated how learning chain-of-thought boosts performance on both mathematical and programming challenges.
Here's what makes O1 special:
Chain-of-Thought Processing: O1 is a large language model trained with reinforcement learning to tackle complex reasoning tasks. By generating an extended internal chain of thought before answering, it resembles a human who methodically works through a challenging problem step by step.
Reinforcement Learning Benefits: The RL process helps the model:
Identify and correct errors
Break down complex tasks into manageable parts
Explore alternate solution paths when an approach fails
The Results:
The difference in approach showed in the results:
GPT-4O: 11th percentile (Rating: 808)
O1-preview: 62nd percentile (Rating: 1258)
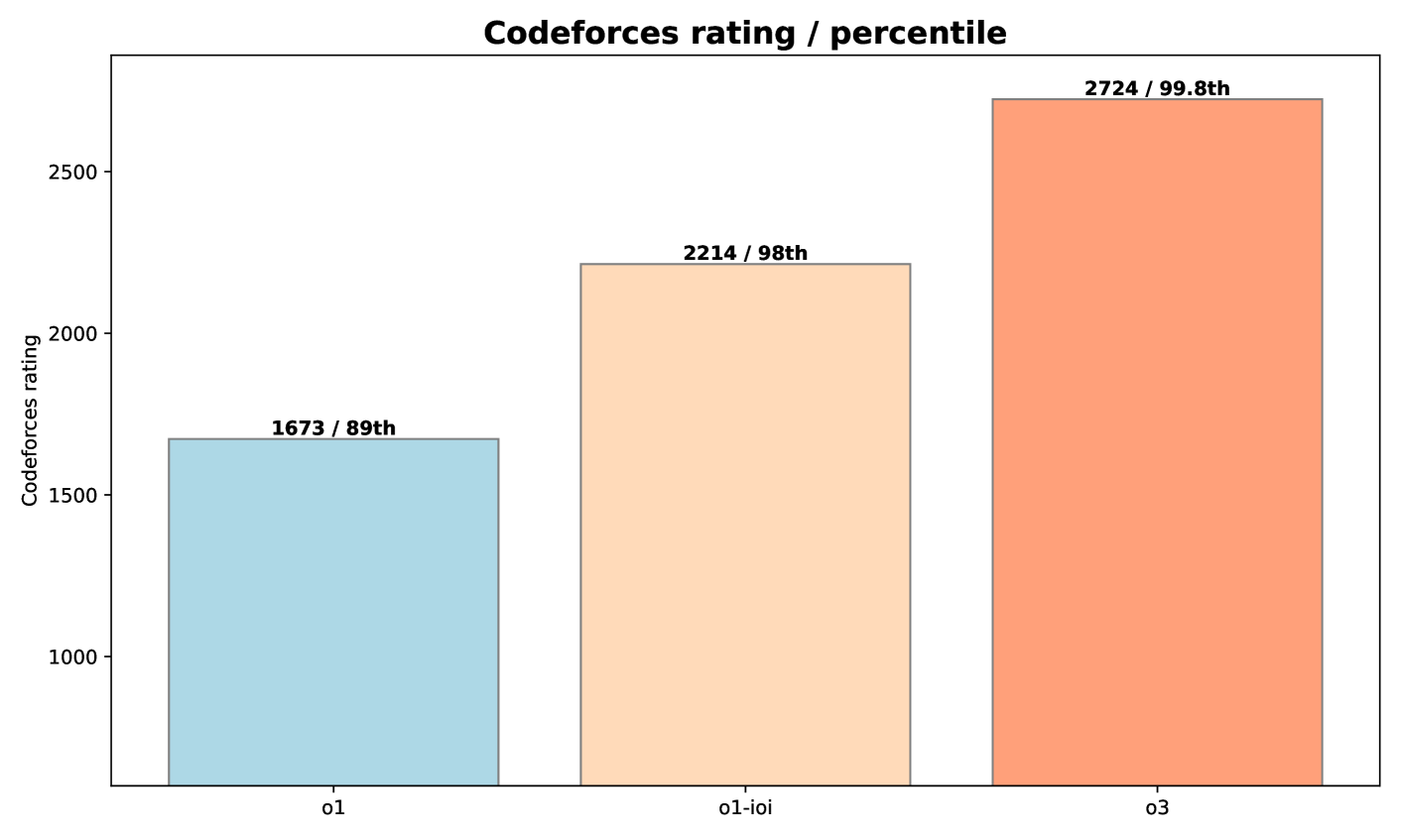
O1 (after more training): 89th percentile (Rating: 1673)

This dramatic improvement demonstrates how reinforcement learning significantly boosts performance on complex coding and reasoning tasks.
Let's dive into the next fascinating part of this experiment
Second Battle: Reasoning model v/s fine-tuned reasoning model specifically for competitive programming
The Rise of O1-IOI
During the development and evaluation of O1, the OpenAI team discovered something interesting - increasing both the amount of reinforcement learning compute and test-time inference compute consistently improved model performance. This insight led to the creation of O1-IOI, specifically designed for competing in the 2024 International Olympiad in Informatics (IOI).
What made O1-IOI special was its two-phased approach:
Additional RL training targeted at coding tasks (Coding RL)
Specialized test-time inference strategies engineered for competitive programming (Test time strategy)
Let's break down how they built this specialized system:
1. Coding RL Fine-tuning
The team didn't just stop at O1's capabilities. They:
Resumed RL training from the O1 checkpoint
Specifically emphasized challenging programming problems
Improved C++ generation and runtime checks
Guided the model to produce outputs in IOI submission format
But here's where it gets really interesting.
2. The Test-time Strategy.
This majorly has 4 components:
Problem formulation
Clustering
Reranking
Submission
Problem formulation:
Since scoring for IOI is done on subtask to subtask basis, what the team did was to break each subtask as a new problem.

Clustering:
For each subtask, the model generated 10000 solutions.
Now the next step was to get the model to create a test input generator. The objective of the test input generator is to create test inputs that are close to the real inputs that will be used to score the solutions. 256 of these test inputs were created for each subtask.
In order to validate whether the test inputs generated are valid or not, Model was also used to generate a test input validator.
The process is as follows:
1. For each subtask, 256 test inputs were generated.
2. Each test input will have to go through all the validators.
3. If the test input passes at least 75% of the validators, it is regarded as a valid test input.
Now each of the solutions that was generated, output against the test inputs were recorded.
To simplify this, let's take an example (we have 3 solutions and 3 test cases):

Now for each solution that matches output with the other solutions in all cases, they are grouped together.
Solution 1 outputs: [1, 2, 3]
Solution 2 outputs: [1, 5, 2]
Solution 3 outputs: [1, 2, 3]
So,
Cluster 1: [Solution 1, Solution 3]
Cluster 2: [Solution 2]
Now, the next step is to rerank the solutions.
Reranking:
Each of the solution is scored based on:
Quality of the solution according to learned scoring function
Errors on Model generated test cases
Failures on public test cases
And each custer is scored as:
Average score of the solutions in the cluster
And penalty for each time a solution is submitted from the cluster. One reason for this is to encourage diversity.
Submission:
Since 50 is the maximum number of submissions allowed to humans, the same constraint was applied to the model. Submissions were done in round robin fashion starting with the hardest subtask first.
The approach used was: select the highest scoring solution from the highest scoring cluster. If the subtask is solved, cease the sampling.
Another clever hack was used to narrow down the search for candidate solutions.
If the current subtask is a strict superset of a previous solved subtask, then filter our solutions that do not match outputs on test inputs of the previous solved subtask.
To take a simple example:
Current subtask: Solve for all numbers less than 1000
Previous solved subtask: Solve for all numbers less than 100
Since the current subtask is a strict superset of the previous solved subtask, we can filter out all the solutions that do not match outputs on test inputs of the previous solved subtask.
The Results
O1-IOI reached a CodeForces rating of 1807 (93rd percentile)
With simple public test filtering: 2092 (96th percentile)
With complete test-time strategy: 2214 (98th percentile)
Real Competition Performance
The real test came at IOI 2024. Under competition conditions (50 submissions per problem), O1-IOI:
Generated 10,000 candidate solutions per problem
Selected 50 submissions using their test-time strategy
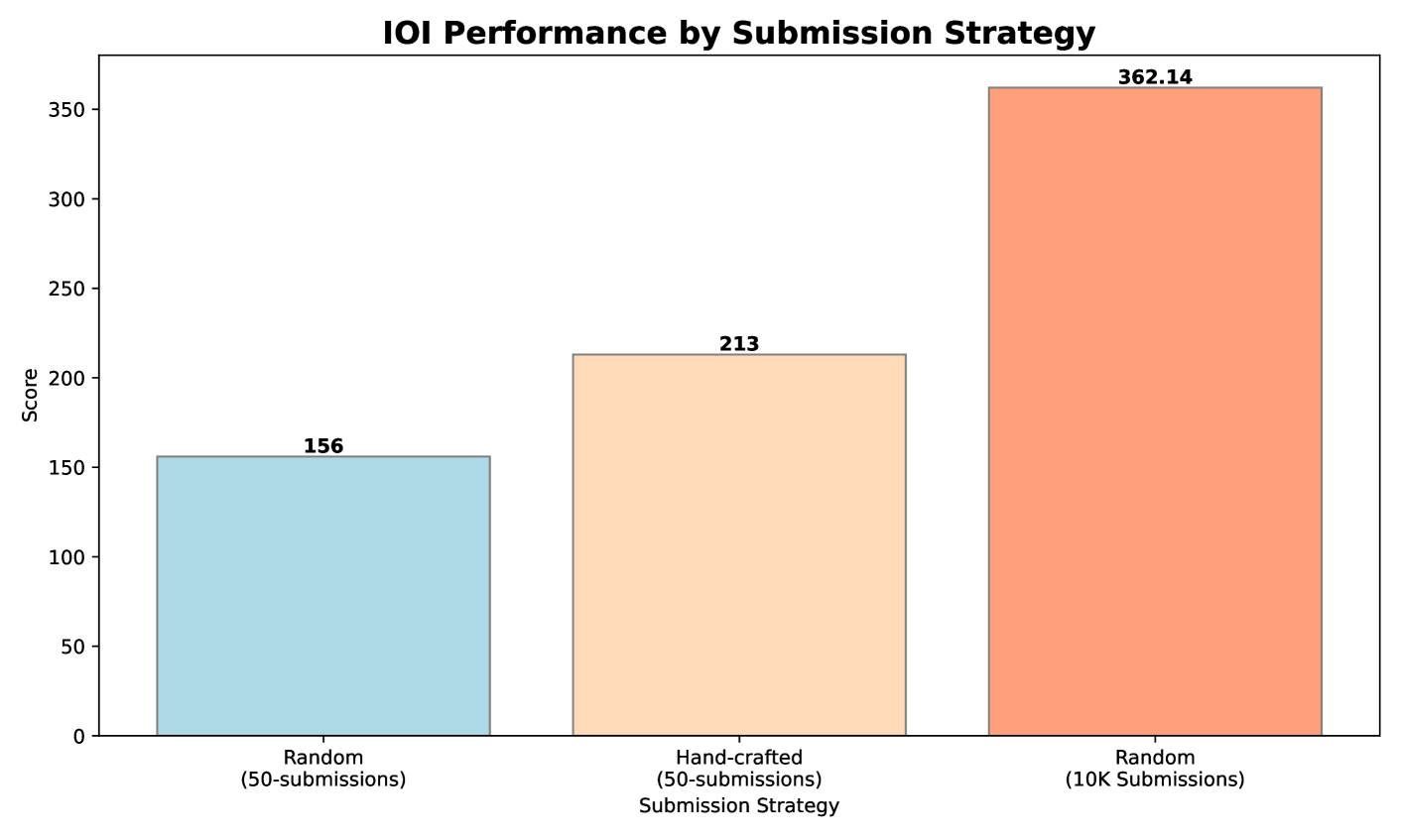
Scored 213 points (49th percentile)
For comparison, random selection would have scored only 156 points
Interestingly, when they relaxed the submission limit to 10,000, the model achieved 362.14 points - surpassing the gold medal threshold!
“These results confirm that domain-specific RL fine-tuning paired with advanced selection heuristics can significantly boost competitive programming outcomes.”
This raises an intriguing question: What if instead of all this specialized fine-tuning and strategy, we just had a more powerful model?
Battle 3: Fine tuned model v/s More Powerful Model
Here's where the story takes a fascinating turn. What happens if we just focus on enhancing reinforcement learning training alone, without relying on human-engineered test-time strategies?
The O3 Experiment
Early checkpoints of O3 were used to evaluate competitive programming tasks. The difference in approach was striking:
O1-IOI: Used complex clustering, reranking, and specialized strategies
O3: Just pure model capability, no hand-crafted heuristics
The Results?
They were remarkable:
O1-IOI: 2214 rating (98th percentile)
O3: 2724 rating (99.8th percentile)
What's particularly interesting is how O3 approached problems. The paper highlights cases where sophisticated test-time strategies emerged naturally from its training. For instance, when verification was non-trivial, it would:
Write simple brute-force solutions
Trade efficiency for correctness
Cross-check outputs against more optimized algorithmic implementations
This self-imposed validation mechanism helped O3 catch potential errors and improve solution reliability - all without being explicitly programmed to do so!
The IOI Showdown The comparison became even more interesting when they tested O3 on IOI 2024 problems. The differences in approach were stark:
O1-IOI's Approach:
Generated 10K solutions per subtask
Used complex human-defined test-time strategy
Required subtask-specific prompts
Needed intricate submission strategies
O3's Approach:
Sampled only 1K solutions per problem
Used a simple selection method
Selected top 50 solutions with highest test-time compute
No need for subtask-specific prompts or complex strategies
The Results:
O1-IOI (50 submissions): 213 points
O1-IOI (10K submissions): 362.14 points
O3 (50 submissions): 395.64 points

O3 not only outperformed O1-IOI but surpassed the gold threshold even under the 50-submission limit, without any IOI-specific strategies!
This raises a crucial point about AI development: Sometimes, scaling up general-purpose reinforcement learning might be more effective than developing specialized domain-specific techniques. The sophisticated test-time techniques that emerged during O3's training served as a more than adequate replacement for the hand-engineered pipelines required by O1-IOI.
The Bigger Picture: What Does This Mean?
Let's step back and look at what these experiments really tell us. The team didn't stop at competitive programming - they also tested these models on real-world software engineering tasks using two datasets:
HackerRank Astra: 65 project-oriented coding challenges
SWE-bench Verified: 500 real-world software tasks
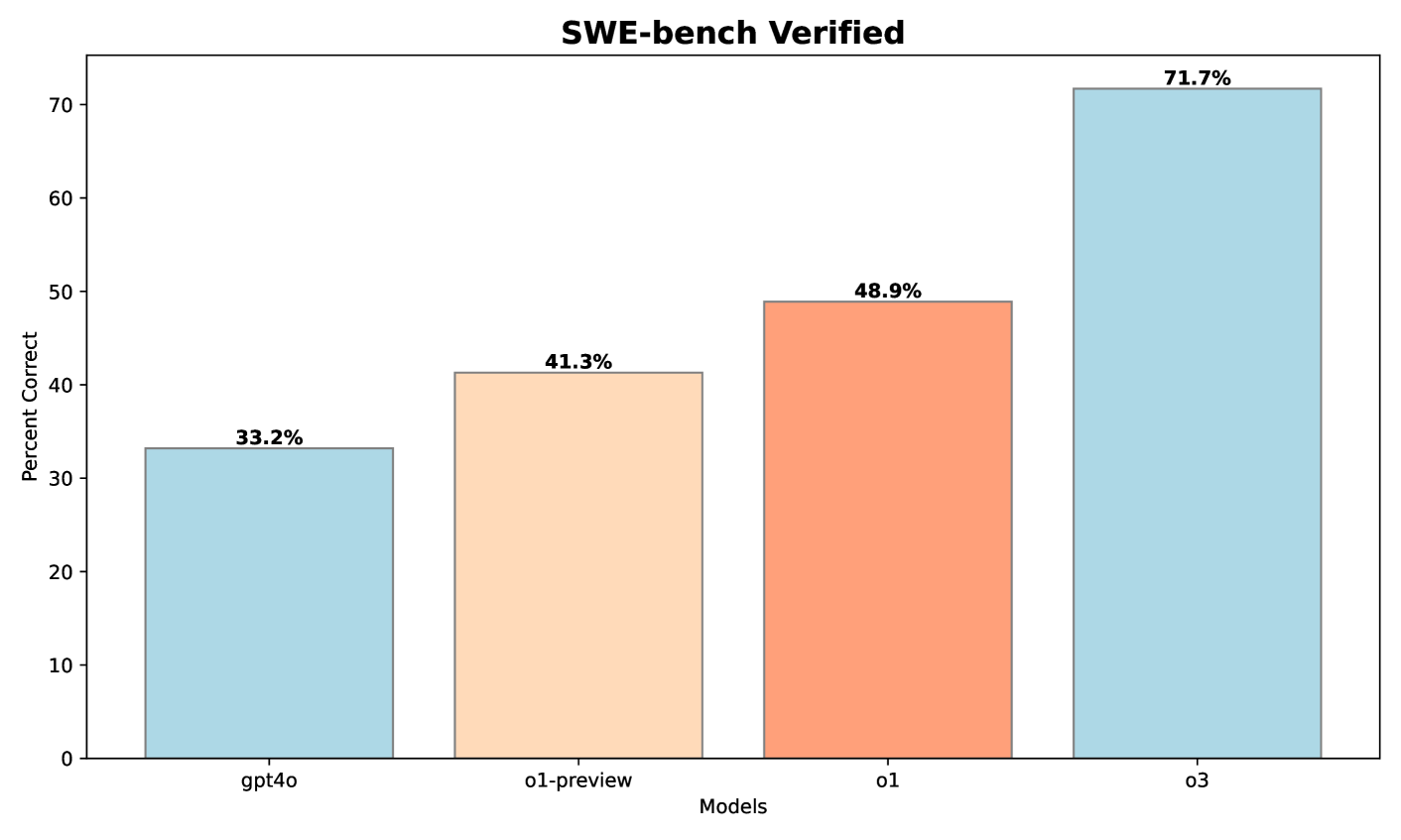
Below are result with SWE Bench (results were consistent with their earlier findings):
O1-preview showed an 8.1% improvement over GPT-4O
O1 achieved a further 8.6% improvement
O3 delivered an impressive 22.8% improvement over O1
This consistent pattern of improvement across different types of problems tells us something important about the future of AI in programming.
Key Takeaways
Reasoning Trumps Language:
If there's a complex problem where a lot of complex thinking is required, large reasoning models are significantly better than traditional language models. The jump from GPT-4O (11th percentile) to O1-preview (62nd percentile) makes this crystal clear.The Power of Training:
If your model isn't performing as expected, more reinforcement learning training can yield better results. We saw this with O1's improvement from 62nd to 89th percentile.The Fine-tuning Trade-off:
While domain-specific fine-tuning and test-time strategies (like in O1-IOI) can boost performance significantly, they might be a temporary solution. A more advanced, generally trained model (like O3) can potentially surpass these specialized approaches without the need for hand-crafted strategies.The Scale Advantage:
The success of O3 suggests that scaling up general-purpose reinforcement learning might be more effective than developing specialized domain-specific techniques. The sophisticated behaviours that emerged naturally in O3 replaced the need for hand-engineered solutions.
Looking Forward
This research gives us valuable insights into building AI systems:
When developing solutions, it's worth considering both immediate improvements through fine-tuning and the potential of future, more capable models
Keep your systems flexible enough to leverage newer models as they become available
Sometimes, waiting for a more advanced model might be more efficient than extensive fine-tuning of current ones
The competitive programming arena has shown us that while we can achieve impressive results through specialized training and clever strategies, the future might lie in more general, but more capable models. As these models continue to evolve, the balance between specialization and general capability will remain a crucial consideration in AI development.
This isn't just about competitive programming anymore - it's about understanding how to best approach AI development in any domain. Do we specialize and optimize, or do we wait for more capable general models? The answer, as this research suggests, might depend on your timeline and resources.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819