
How Amazon Improved K-Nearest Neighbor Search on Graphs by 60% with FINGER [Breakdowns]
Improving the inference cost of graph search by using approximations

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
Executive Highlights
A rise in knowledge-intensive natural language processing (KI-NLP), information-retrieval (IR), and LLM-based RAG applications has seen an increased interest in similarity search mechanisms. Based on what I’ve seen, the similarity search/context retrieval protocol is the second most important factor(behind the Data Restructuring/Embeddings and ahead of the LLM you decide to use (although Gemini might make me eat my words)). A good similarity search algo can significantly improve text generation quality, reduce hallucinations, and might even lower inference costs.
A common improvement to improve similarity search is to integrate it with Graphs. Being a relational data structure, graphs can be especially good for forcing your search to prioritize certain sources and integrating domain-expert knowledge over naked LLMs. They also come with added benefits in explainability, can be used to model complex processes, and make you seem very smart for using them (bonus tip- to supercharge your math street cred, use Bayesian Graphs. Never met someone who isn’t impressed by those).
However, utilizing graphs for IR can be a challenging process due to various reasons. Some of the usual suspects are highlighted below-
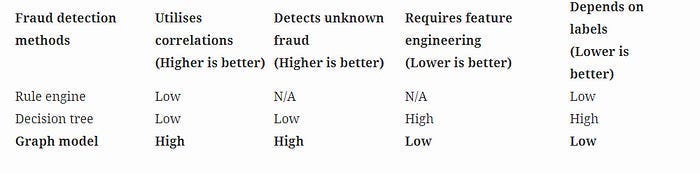
There has been a lot of research into addressing many of these issues. Amongst them, the publication, “FINGER: Fast inference for graph-based approximate nearest neighbor search”, by Amazon is worth highlighting for two reasons. Firstly, their approach is universal and can be applied to any graph constructed (since the optimization is done on the search side, not on the graph construction). Secondly, it hits some amazing numbers, “FINGER significantly outperforms existing acceleration approaches and conventional libraries by 20% to 60% across different benchmark datasets”
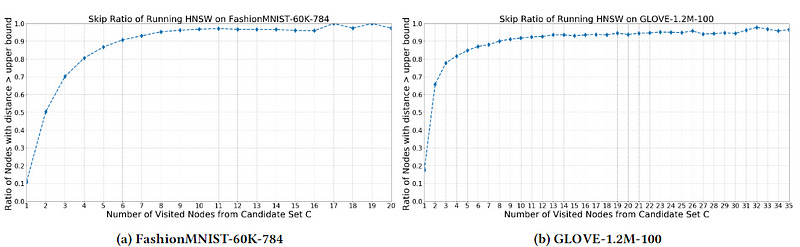
The secret to this performance lies in a fairly simple, but important insight- “when calculating the distance between the query and points that are farther away than any of the candidates currently on the list, an approximate distance measure will usually suffice.” Essentially, if I only want to consider top-5 similarity scores, then the exact distance of no. 6 and below is irrelevant to me. I can skip the heavy-duty distance computations in that case. I also don’t want to consider points that are further than my upper-bound distance. And as it turns out that after a while, “over 80 % of distance calculations are larger than the upper-bound. Using greedy graph search will inevitably waste a significant amount of computing time on non-influential operations.”
This leads Amazon to explore approximations for the distance measurement for the points further away. They finally settle on an approximation based on geometry + some vector algebra. Take a query vector, q, our current node whose neighbors are being explored, c, and one of c’s neighbors, d, whose distance from q we’ll compute next. “Both q and d can be represented as the sums of projections along c and “residual vectors” perpendicular to c. This is, essentially, to treat c as a basis vector of the space.”
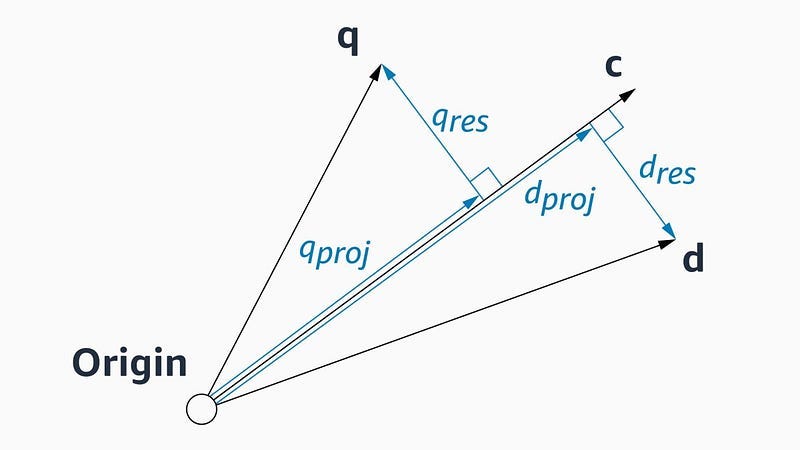
This approach works swimmingly-
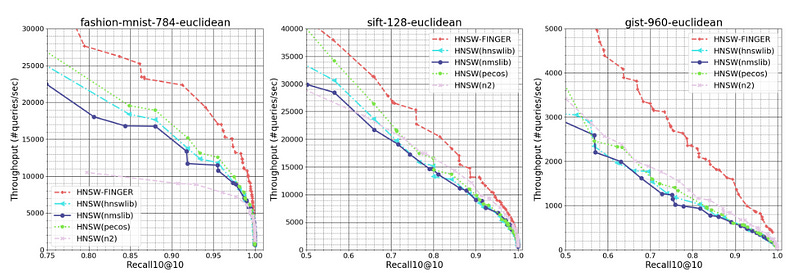
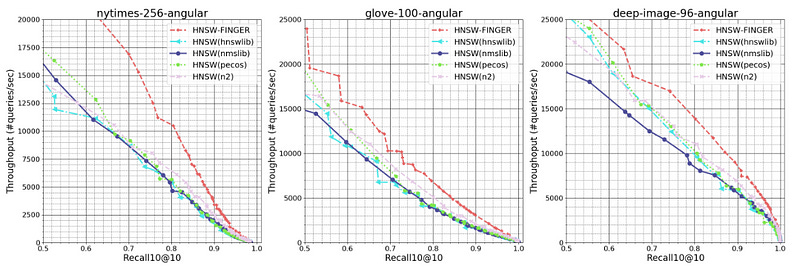
To evaluate our approach, we compared FINGER’s performance to that of three prior graph-based approximation methods on three different datasets. Across a range of different recall10@10 rates — or the rate at which the model found the query’s true nearest neighbor among its 10 top candidates — FINGER searched more efficiently than all of its predecessors. Sometimes the difference was quite dramatic — 50%, on one dataset, at the high recall rate of 98%, and almost 88% on another dataset, at the recall rate of 86%.
We will spend the rest of this piece elaborating on the ideas discussed above.
Why Graphs are Good for IR and Nearest Neighbors-
The first (and most important) question to ask with any technology/algorithm is why it exists and what kinds of problems it solves. Me preaching about the benefits Graphs in general would be a waste of everyone’s time, so let’s get a bit more specific to this paper- What Good do Graphs provide us for NN search (except for the street-cred one gains from using them)?
Let’s try to imagine lives w/o them. Here is how a naked nearest-neighbor search would look: data would be represented as points in a high-dimensional space; a query would be embedded in that space; and the data points closest to the query would then be retrieved as candidate solutions (or we might feed these points into a generator as a set of contexts).
So far, so good. But take a second to expensive how expensive computing the distance between the query and every point in the dataset will be. Unless you got a prime Kante or Merab running through every point, your system will probably give out at some point. That is why we use approximate methods for similarity search (ANN or Approximate Nearest Neighbors search).
Okay, but why Graphs? Imagine our search space was represented as a graph. Right off the bat, instead of looking through every point, we would only really be looking through a subset of points (those close to the query). That reduces your search space dramatically. This is helped even further when you consider that you can explicitly code relationships derived from domain expert insights (this was super useful in my work with supply chain analysis). When it comes to RAG, this can be super useful with very self-referential documents (docs where one section refers to another), as is the case with Legal/Compliance Docs, which often lose context in standard chunkings.

Not only does this reduce the time required for construction, but it also enables you to nudge your AI models to prioritize certain sources, ignore adversarial input, and acts as an added layer of security.
It is evident that the current state of Large Language Models (LLMs) necessitates the incorporation of external tools. The lack of straightforward algebraic and logical reasoning is well documented and prompted researchers to develop frameworks which allow LLMs to operate via external tools. The ontological nature of tool utilization for a specific task can be well formulated with a Directed Acyclic Graph (DAG). The central aim of the paper is to highlight the importance of graph based approaches to LLM-tool interaction in near future. We propose an exemplary framework to guide the orchestration of exponentially increasing numbers of external tools with LLMs,where objectives and functionalities of tools are graph encoded hierarchically.
Graphs are also very flexible. An underappreciated ability of graph-based systems is their ability to work with multiple kinds of entities (social media platforms are a great example of this since they have multiple different kinds of users/profiles). can be dynamically updated to incorporate new data points and evolving relationships. This makes them suitable for NNS tasks in real-time scenarios or with constantly changing datasets.
Sound too good to be true? Well it is. Let’s move onto the next section about why Graphs have been a menace to (the Data Science) society.
Challenges with utilizing graphs-
To elaborate on the ideas discussed in our very academic visualization in the highlights, let’s do a more in-depth review of some ways you can struggle with Graphs for NNS. This is based mostly on my subjective experiences, so if you have different experiences (or have insights on how to fix this), make sure you share.
1. Graph construction:
Choice of neighbors: Selecting appropriate neighbors for each data point significantly impacts search performance. Inappropriate choices can lead to local minima, where the search gets trapped in a suboptimal region of the graph, failing to reach true nearest neighbors.
Balancing efficiency and accuracy: Balancing the number of neighbors per node with the overall graph size is crucial. Too few neighbors limit search space exploration, while too many increase storage requirements and potentially slow down search.
High dimensionality: Constructing effective graphs in high-dimensional spaces can be challenging. The “curse of dimensionality” can lead to sparse graphs, hindering efficient search due to the lack of meaningful connections between points. Not using enough dimensions can lead to undifferentiated nodes, which is probably even more useless.
Expensive Domain Expert Insights: In many cases, it is very expensive to leverage Domain Experts in graph construction. However, without their help, you can end up missing crucial details and creating substandard structures. Related to point 1, but I wanted to bring this out explicitly.
2. Search algorithms:
Greedy vs. optimal search: Most graph-based NNS algorithms are greedy, meaning they explore the graph based on local heuristics, not guaranteeing to find the absolute nearest neighbor. While efficient, this can lead to suboptimal results.
Dynamic data: Updating graphs efficiently to incorporate new data points and maintain search performance can be challenging, especially for large-scale datasets. Data Drift can hit these Graph Based Systems particularly hard, given the explicit modeling of relationships. Don’t skimp out on the monitoring and observability tools.
Distance metrics: Implementing various distance metrics beyond Euclidean distance within the graph structure can require specialized algorithms and potentially increase computational complexity.
3. Practical considerations:
Memory usage: Storing and managing large graphs can be memory-intensive, especially for dense graphs with many connections per node. This can limit the applicability of graph-based NNS to resource-constrained environments if you care about that kind of stuff. Personally, I find that throwing more money at the problem and constantly shifting goalposts for performance goals works very well.
Parallelization: Efficiently parallelizing graph-based NNS algorithms can be challenging due to the inherent dependencies between graph traversals and the potential for race conditions. This limits their scalability on multi-core or distributed computing systems.
As you can see, there are clearly lots of opportunities in this space, if you’re willing to try your shot at it. Let’s end this by looking at what Amazon did to improve its NNS.
How Amazon Improved Graph-based Similarity Search
As mentioned earlier, Amazon’s algorithm FINGER relies on Geometry and Linear Algebra. Let’s look into the idea in more detail here-
Firstly we know that if the algorithm is exploring neighbors of c, we have already calculated the distance between c and q. By combining that with some precomputations (a list of which can be found in Section B of the appendix), “estimating the distance between q and d is simply a matter of estimating the angle between their residual vectors.”
So how do we get that angle? For that we use the angles between the residual vectors of c’s immediate neighbors. “The idea is that, if q is close enough to c that c is worth exploring, then if q were part of the graph, it would probably be one of c’s nearest neighbors. Consequently, the relationships between the residual vectors of c’s other neighbors tell us something about the relationships between the residual vector of one of those neighbors — d — and q’s residual vector.”
There are some derivations, but I’m not going to touch upon them here b/c I really have nothing to add to them. Going over it here would be the newsletter equivalent of reading off the slides. If you want to check the math, check out Section 3.2 of the paper. For the rest of us let’s look at the FINGER algorithm.

Nothing too crazy, assuming you accept the math for the approximation. Aside from that, the big things to note would be line 14, where we switch to approximate distance computations to account for the observation that “starting from the 5th step of greedy graph search both experiments show more than 80% of data points will be larger than the current upper-bound.”
As mentioned earlier, this relatively simple approach leads to some very solid performance gains, “We can see that on the three selected datasets, HNSW-FINGER all performs 10%-15% better than HNSW-FINGER-RP. This results directly validates the proposed basis generation scheme is better than random Gaussian vectors. Also notice that HNSW-FINGER-RP actually performs better than HNSW(pecos) on all datasets. This further validates that the proposed approximation scheme is useful, and we could use different angle estimations methods to achieve good acceleration”
All in all, really exciting work. Between this and my investigation into Natural Gradients, I’m now curious to learn more about other approximations in AI. It’s really cool how much there is to learn in this space.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819