
How Amazon tackles a multi-billion dollar bot problem[Breakdowns]
How to detect Robotic Ad Clicks.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a discount.
p.s. you can learn more about the paid plan here. If your company is looking to build AI Products or Platforms and is looking for consultancy for the same, my company is open to helping more clients. Message me using LinkedIn, by replying to this email, or on the social media links at the end of the article to discuss your needs and see if you’d be a good match.
As we covered in our earlier post on scaling Tensorflow to 300 Million Predictions per second, the online ad industry is expected to grow to 786.2 Billion USD by 2026. A large share of this online ad-market is driven to major platforms like Amazon, Facebook, Google, etc. However, this creates a challenge- given all the money that is channeled into advertising on these platforms, what if a scammer came along and used robots to click on these ads? This would cost the advertisers a lot of money, and reduce the ROI from these campaigns- ultimately causing them to move their business elsewhere. That is why platforms like Amazon and Facebook spend a lot of resources to monitor robotic activity and stop robotic ad clicks.
Amazon put out 3 phenomenal publications on this topic: Invalidating robotic ad clicks in real-time, Self Supervised Pre-training for Large Scale Tabular Data, and Real-Time Detection of Robotic Traffic in Online Advertising with details on how they tackle these challenges. In this article, we will be covering some important highlights from these publications (and a few others)- answering questions like the major challenges they faced, what metrics were used, the model used to solve the issue, and other important takeaways.

We demonstrate its efficacy by evaluating on the problem of click fraud detection on ads to obtain a 9% relative improvement on robot detection metrics over a supervised learning baseline and 4% over a contrastive learning experiment.
The Challenges
To first understand their solution, let’s first understand some of the challenges that we might come across in such a problem. When it comes to building ML Systems for robotic click detection, Amazon grappled with the following major challenges-
Lack of ground truth- Despite a large volume of ad clicks there is no way to confidently label a click as robotic or human. This means that Amazon has to rely on proxy metrics to differentiate. Proxy measurements are very common in AI, and it is important to know when a team is relying on them instead of direct measurements- since that is crucial to evaluating the results.
Balance revenue and recall- Amazon has to walk a fine line- incorrectly labeling a robotic click as human causes advertisers to lose money, and incorrectly labeling a human as a robot eats into Amazon’s profits. “We address this tension by calibrating ML models for a chosen false positive rate.”
Equal protection across traffic slices- Online ads are displayed on many traffic slices across a variety of devices and ad placements on the e-commerce site. The model should ensure fairness and offer similar protection across all slices of traffic. We formulate this as an offline convex optimization problem to determine the operating points of the model for each traffic slice.
Evolving bots need fast reaction- Bots are rapidly evolving with an increase in their sophistication and the model needs to continuously adapt along with traffic patterns. The model should also quickly react to egregious robotic attacks that have the potential to deplete the budgets of small or medium-sized ad campaigns. Behavior drift is one of the biggest challenges in ML systems (especially those handling behavioral predictions). Studying how different groups handle it is a must.
So how do tackle these challenges? The first step is to have some system for differentiating between humans and bots (which is tricky because of the lack of ground truth labels). Amazon’s scientists accomplish this by using some fairly common-sense proxies-
we generate data labels by identifying two high-hurdle activities that are very unlikely to be performed by a bot: (1) ad clicks that lead to purchases and (2) ad clicks from customer accounts with high RFM scores. RFM scores represent the recency (R), frequency (F), and monetary (M) value of customers’ purchasing patterns on Amazon. Clicks of either sort are labeled as human; all remaining clicks are marked as non-human.
This is great because it turns this into a business problem- if an ad-click leads to purchases or comes from a high RFM account then it’s a click that helps business. Even if it is a bot, it’s important to keep it. Now we have a dataset for binary classification. If it were me, I would supplement that with valuable clicks and non-valuable clicks (using a range from 0-1) to enable more nuanced analysis for the future- but for all we know that has already been implemented by another team.
Before we proceed to look at the model, let’s take a looksie at the metrics used to calibrate the models.
The Metrics Used to Train Robotic Click Detection
Once again, the lack of ground truth labels makes traditional analysis and metrics impossible. The Amazon team works around this issue by using custom metrics picked for their business impacts.
Firstly, we have the Invalidation rate (IVR) is defined as the fraction of total clicks marked as robotic by the algorithm. IVR is indicative of the recall of our model since a model with a higher IVR is more likely to invalidate robotic clicks. However, this has an obvious issue- a bad model would just invalidate everything (including human clicks). That is why we have the second metric- The FPR.

This is combined with a third metric- We define a heuristic rule to identify traffic that has a high likelihood to be robotic. If a session makes more than K ad clicks in a hour, then it is likely to be robotic. We choose K to be a large number so that humans are less likely to click on ads at that rate. We define Robotic coverage as the percentage of such clicks that were marked as robotic by the model. This metric can also be considered as an indicator of recall for a model.
All 3 of these metrics are relatively straightforward, which is great because it makes it easy to understand them and the results.
With all this out of the way, let’s now get into the model and the data used to differentiate b/w humans and bots.
The Features of Data Input into the Models.
The data relies on the following dimensions-
User-level frequency and velocity counters compute volumes and rates of clicks from users over various time periods. These enable identification of emergent robotic attacks that involve sudden bursts of clicks.
User entity counters keep track of statistics such as number of distinct sessions or users from an IP. These features help to identify IP addresses that may be gateways with many users behind them.
Time of click tracks hour of day and day of week, which are mapped to a unit circle. Although human activity follows diurnal and weekly activity patterns, robotic activity often does not.
Logged-in status differentiates between customers and non-logged-in sessions as we expect a lot more robotic traffic in the latter.
The data is supplemented by using a policy called Manifold Mixup. The team relies on this technique for a simple reason- the data is not very high-dimension. Carelessly mixing data up would thus lead to high mismatch and information loss. Instead, they “leverage ideas from Manifold Mixup[17] for creating noisy representations from the latent representations of hidden states.”

This data is fed into a binary classifier consisting of three fully connected layers with ReLU activations and L2 regularization in the intermediate layers.

“While training our model, we use sample weights that weigh clicks equivalently across hour of day, day of the week, logged-in status, and the label value.” The team found that sample weights to be crucial in improving the model’s performance and stability, especially with respect to sparse data slices such as night hours. “We find the model trained with sample weights to have a superior performance than the model without sample weights. For a similar IVR level, the model trained without sample weights incurs almost double the FPR as shown in Figure 4a. Sample weights allow the model to proportionally weigh data points across various traffc slices in the training data. In particular, early morning hours, weekdays, and non-logged-in slices are examples of sparse traffc slices that need to be compensated for by sample weighing. For instance, we see that the model trained without sample weights has a high variance in FPR across hours, see Figure 4b.”
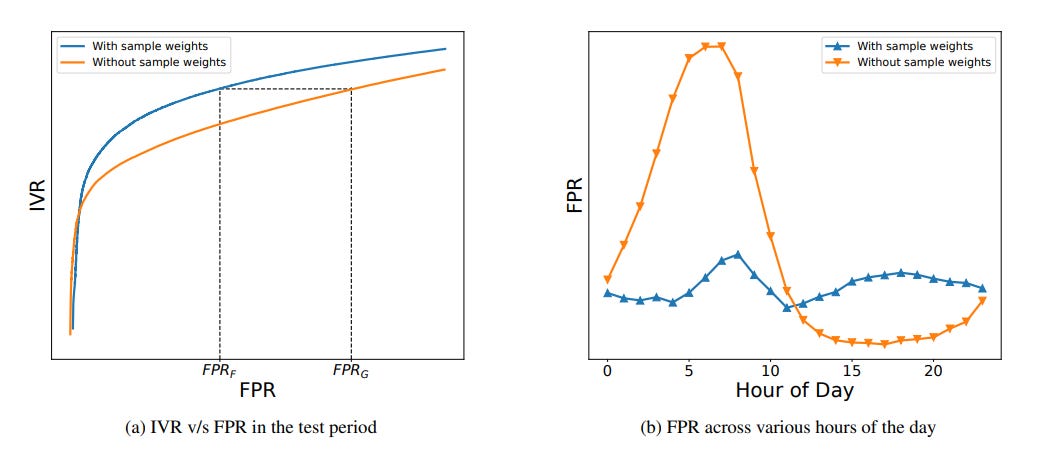
This model is stacked against 2 different baselines- logistic regression and a heuristic rule that computes velocity scores of clicks (higher velocity would imply robotics). The model shows a higher ability to model complex data than the other 2.

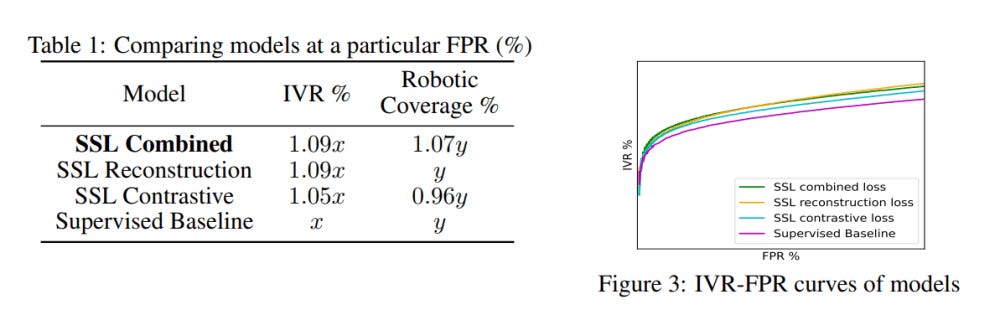
According to the PreTraining on Tabular Data publication, seems like Self Supervised learning has some great potential to take the results even further- Figure 3 shows the IVR-FPR curves of the models. A model with a higher IVR at a particular FPR means that the model is able to invalidate more traffic at that FPR and is hence likely to catch more bots than a model with a lower IVR at the same FPR... Self-supervised pre-training of embeddings improves performance when compared to the supervised baseline model
Different slices (desktop, mobile etc) come with different behaviors. Thus it is important to have slice level optimization. To ensure fairness across all traffic slices, we formulate calibration as a convex optimization problem. We perform joint optimization across all slices by fixing an overall FPR budget (an upper limit to the FPR of all slices combined) and solve to maximize the combined IVR on all slices together. The optimization must meet two conditions: (1) each slice has a minimum robotic coverage, which establishes a lower found for its FPR, and (2) the combined FPR of all slices should not exceed the FPR budget.
Next, let’s now cover this system is deployed in production.
Deploying the Ad Detection System
It’s important to build a system that is real-time, efficient, and adapts to new robotic behavior quickly. As stated by the authors- To quickly adapt to changing bot patterns, we built an offline system that retrains and recalibrates the model on a daily basis. For incoming traffic requests, the real-time component computes the feature values using a combination of Redis and read-only DB caches and runs the neural-network inference on a horizontally scalable fleet of GPU instances. To meet the real-time constraint, the entire inference service, which runs on AWS, has a p99.9 latency below five milliseconds.

This is combined with certain guardrails. Firstly, it is important to protect against architectural failure, which can make the model mistakenly assume that there was no human traffic (increasing the IVR). To protect against this, we “check that every hour x day across the training period of a week contains a minimum number of clicks with a certain human label density. We ignore any training samples that have null values for a feature and have a guardrail on the total number of such samples. If any of these guardrails fails, then model training will not proceed for that instance.”
This is combined with a comprehensive review of newly trained models and their performance against the model currently in production. We look at 3 criteria-
The new model’s metrics like AUROC and log-loss at the end of training should lie within specifc bands.
The new model should have a higher IVR in validation data than the production model though both are calibrated at the same FPR, which indicates that the new model has higher recall of robots.
The new model’s IVR on most recent hours should be within a certain percentage of the IVR of the production model, to ensure that the update does not cause any drastic changes in production metrics.
If the model doesn’t pass all these checks, it’s not used. To ensure extra safety of the system, this is integrated with safety mechanisms-
We have also developed disaster recovery mechanisms such as quick rollbacks to a previously stable model when a sharp metric deviation is observed and a replay tool that can replay traffic through a previously stable model or recompute real-time features and publish delayed decisions, which help prevent high-impact events.
All of these combine to give us a strong system capable of detecting robotic ad clicks, adapting to new behaviors, and not mistaking humans for robots. This idea is fairly compact, which makes it easy to change and tweak in the future. In fact, in their concluding remarks, the authors talked about how they will extend this system forward- In the future, we plan to make the model more feature-rich with endto-end learned representations for users, IPs, UserAgents, search queries, etc. With the increased number and types of features, we plan to experiment with advanced neural architectures like cross-networks that can effectively capture feature interactions in tabular data. I’ve never heard the term cross networks before, so if any of you know about these, I’d appreciate a few pointers. The more you share, the better I know the field, the higher the quality of my writing.
If any of you would like to work on this topic, feel free to reach out to me. If you’re looking for AI Consultancy, Software Engineering implementation, or more- my company, SVAM, helps clients in many ways: application development, strategy consulting, and staffing. Feel free to reach out and share your needs, and we can work something out.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819

Great breakdown of how Amazon tackles the bot problem in online advertising. Your jargon-free analysis really helps us understand the complexities of AI research.
As a bot programmer, these security measures and analysis that you mention in the article seem pretty basic and well known to me.
On the other hand, publishing a guide that talks in detail about the security measures to stop bots, usually makes it easier to evade those security measures.
The AI is going to greatly improve anti-spam measures, but at the same time it is going to give the bots superpowers. It is going to be a very difficult fight where the means of physical identification (phones, IDs, iris analysis, credit cards or real purchases) will continue to be the only way to guarantee that a user is real.