


How to handle 300 million predictions per second [Breakdowns]
How an Advertising team scaled Tensorflow to 300 Million predictions per second

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Machine Learning is changing a lot of fields. One of the big ones is advertising. While companies like Google and Facebook are infamous for their use of big data to target personalized ads, there are many other players in this field. This should not be a surprise since online advertising is much bigger than you realize. According to market estimates, total media advertising spending the United States in 2020 would amount to 225.8 billion U.S. dollars. By 2024, the figure is expected to grow to 322 billion dollars.

However, applying AI to advertising is a lot more challenging than you’d think. From a technical standpoint, this industry is an interesting blend of two fields, networking and machine learning. This presents an interesting set of challenges that have to be handled. We need high accuracy, constantly updating models, and very low latency. Data Drift is a huge challenge, as data collection policies, user preferences and other protocols can change quickly. This makes it hard to implement the traditional approach/models. The authors of the paper, “Scaling TensorFlow to 300 million predictions per second” detail their challenges and approach to tackling the issues. They do this by sharing their learnings from working with Zemanta.

Above is a passage from the authors. It explains what Zemanta is, how the service operates, and how the ad space is sold. The last bit detailing the use of machine learning in maximizing their KPIs is pretty interesting. Maybe a reader of this article will go on to work in this field (make sure to remember me lol).

In this article, I will share the learnings that allowed the authors/team at Zemanta to 300 Million Predictions every second using the TensorFlow framework. Which of these learnings did you find most interesting? Let me know in the comments.
Learning 1: Simple Models are (still) King
This is something that people working in Machine Learning know very well. Going over AI news you would think that Machine Learning equates to training large models with complex steps. It’s no surprise that most beginners conflate Machine Learning with Deep Learning. They see the news about GPT-4 or other giant models. And they assume that to build great models, you need to know how to build these giant networks that take months to train or to just fine-tune/prompt engineer on any of these architectures.
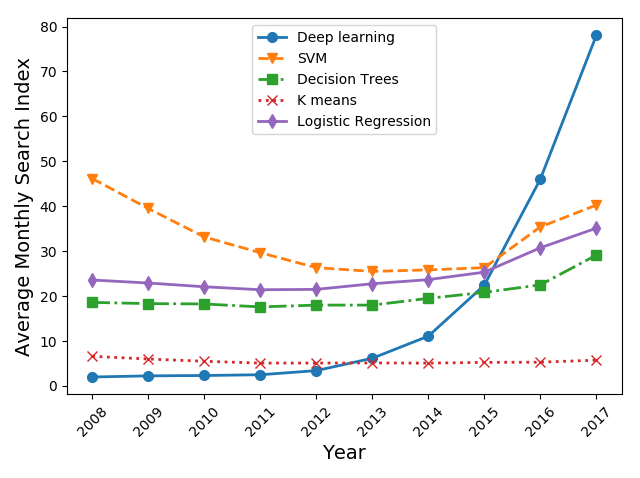
This paper presents the reality. Keep in mind that a lot of ML models are deployed in contexts where they have to make a lot of inferences (including the models from this team). Amazon Web Services estimates that “In deep learning applications, inference accounts for up to 90% of total operational costs”. Having huge models can really eat into your margins (and even turn the profits into losses).

Simple models are easier to train, can be tested quicker, don’t require as many resources, and generally don’t fall behind too much. Applying large models at scale would increase server/running costs by a lot. The authors reflect a similar sentiment in the following quote from the paper:
We additionally do not utilize GPUs for inference in production. At our scale, outfitting each machine with one or more top-class GPUs would be prohibitively expensive, and on the other hand, having only a small cluster of GPU machines would force us to transition to a service-based architecture. Given that neither option is particularly preferable and that our models are relatively small compared to state-of-the-art models in other areas of deep learning (such as computer vision or natural language processing), we consider our approach much more economical. Our use case is also not a good fit for GPU workloads due to our models using sparse weights
Many companies don’t have large systems of GPUs lying around that they can just use to train and predict data. And they are mostly unnecessary. To quote the authors: the relatively small models are much more economical.
The best way to build and use huge models efficiently- don’t use them a lot. Instead, let simple models/filters do most of your tasks, and use your large AI model only when it is absolutely needed.
Learning 2: Don’t Overlook Lazy Optimizers
Sparse Matrices refer to matrices where the values are largely 0. They are used to represent systems where there is limited interaction between 2 pairs of components. For example, imagine a humanity matrix where we the row and columns correspond to people on the planet. The value of a particular index is 1 if the two people know each other and 0 if they don’t. This is a sparse matrix since most people don’t know most other people in the world.
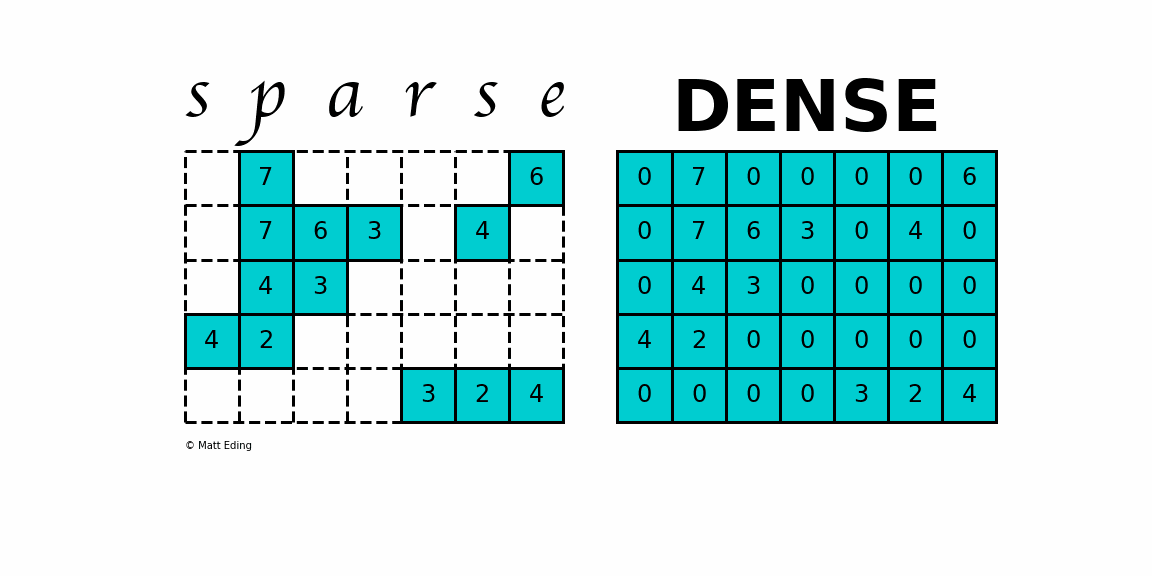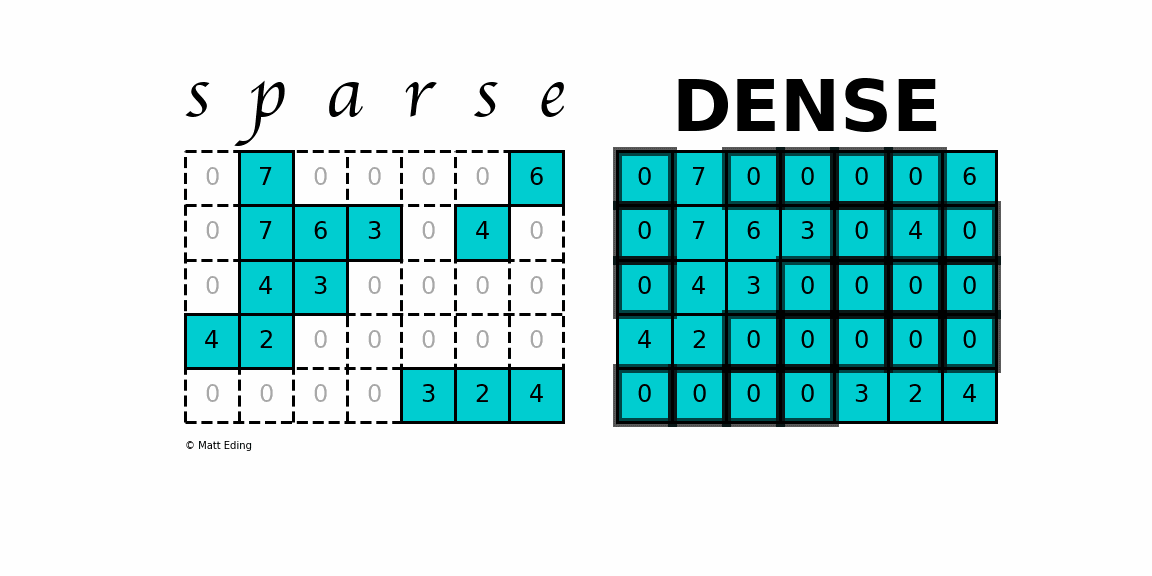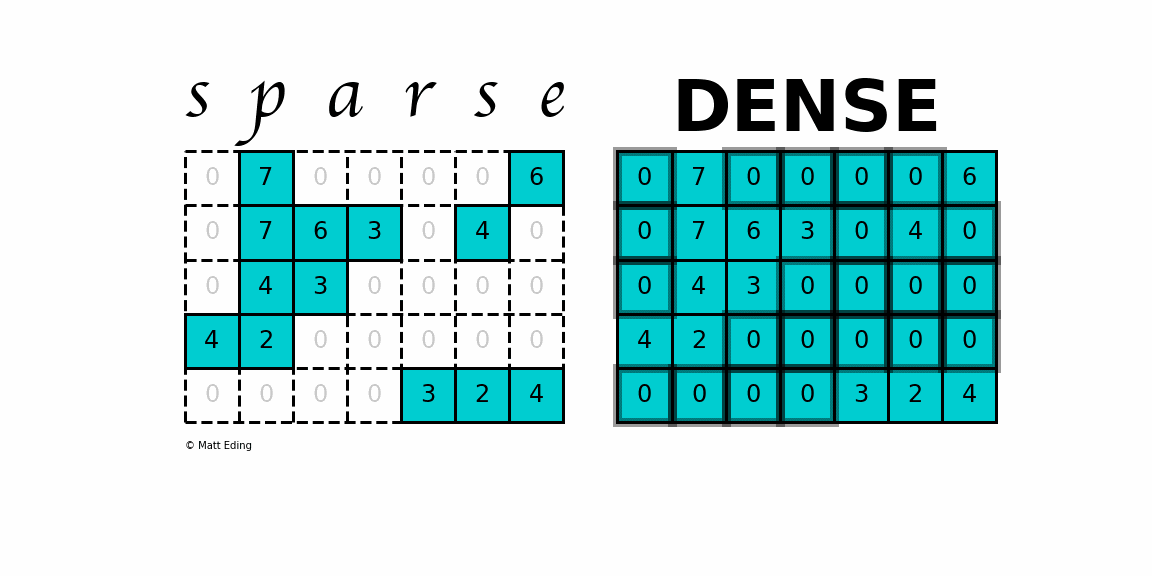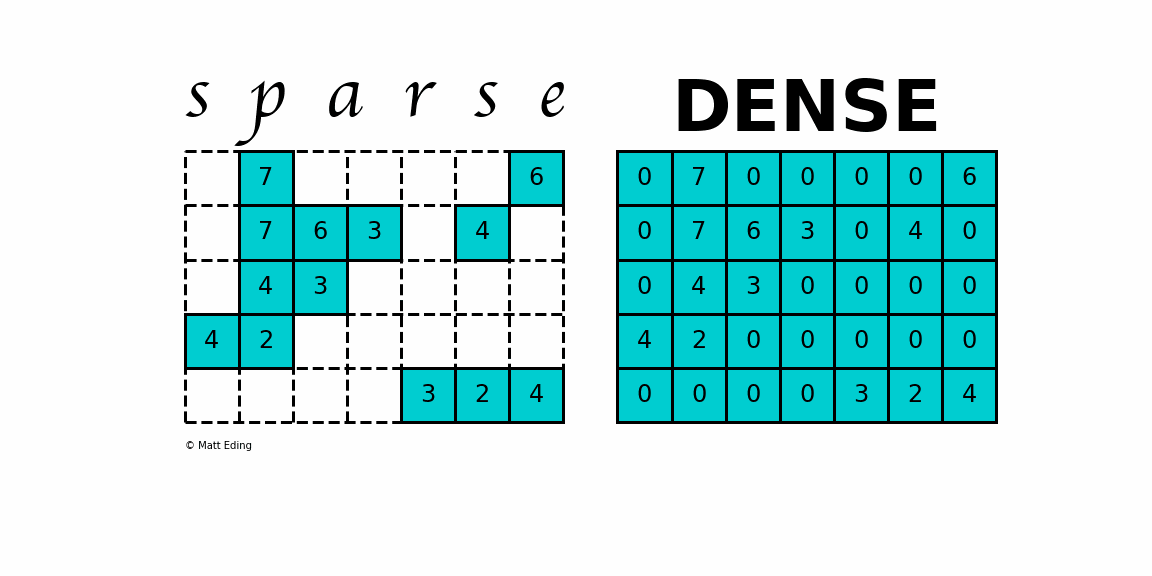
The matrix Zemanta was working with was sparse. They identified the cause of this being the fact that most of the features were categorical. Using an Adam Optimizer was increasing run costs by a lot (50% more than Adagrad). Adagrad on the other hand had a terrible performance. Fortunately, there was an alternative that gave a great performance without being very expensive: LazyAdam.

Lazy Evaluation is a well-established practice in software engineering. Lazy Loading is often used in GUI/Interactive-based platforms like websites and games. It is only a matter of time before lazy optimizers become established in machine learning. Keep your eye out when it does happen. If you’re looking to find avenues to research in Machine Learning, this might be an interesting option.
Learning 3: Bigger Batches → Lower Computation Costs
By diving deeply into TF, we realized that the computation is far more efficient (per example) if we increase the number of examples in a compute batch. This low-linear growth is due to TF code being highly vectorized. TF also has some overhead for each compute call, which is then amortized over larger batches. Given this, we figured that in order to decrease the number of compute calls, we needed to join many requests into a single computation.
So why did big training batches lead to lower computational costs? There’s a cost associated with moving batches from RAM/disk to memory. Using larger batches = less moving around of your data = less training time. However, by using larger batches you miss out on the advantages of stochastic gradient descent, and as Intel Showed, large batch sizes can reduce generalization. However, keep in mind, you can work around this (article on this coming soon).
This halved their computational costs. The full results from optimizing like this were:
This implementation is highly optimized and is able to decrease the number of compute calls by a factor of 5, halving the CPU usage of TF compute. In rare cases that a batcher thread does not get CPU time, those requests will time out. However, this happens on fewer than 0.01% of requests. We observed a slight increase in the average latency — by around 5 ms on average, which can be higher in peak traffic. We put SLAs and appropriate monitoring into place to ensure stable latencies. As we did not increase the percentage of timeouts substantially, this was highly beneficial and is still the core of our TF serving mechanisms
The slightly increased latency makes sense. To read what exactly they did, check out section 3.2. It’s a whole of networking stuff, so I’m not an expert. But the results speak for themselves.
Closing
This paper is an interesting read. It combines engineering, networking, and machine learning. Furthermore, it provides insight into the use of Machine Learning in smaller companies where huge models and 0.001% improvements in performance are not crucial.
PS: If you didn't know, I'm doing a quick study on AI Safety. It has only 6 questions, and you'll be done in under 2 minutes. But it contains questions that need to be answered to build a stronger AI Safety Community. You can help in ensuring that the AI Developed is safe, ethical, and useful. 👷♂️👷♀️
Please fill out this Google Form here
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819