
Learning from the One Pixel Attack?
The paper that shook costly Deep Learning Image Classifiers

If you have been alive recently, you are likely aware of the Deep Learning Hype. People are convinced that with enough Computing Power and Data, DNNs will solve any problem. By this point, DNNs have established themselves as the go-to for Image Classifiers. This is why the paper “One Pixel Attack for Fooling Deep Neural Networks” by Jiawei Su et al should not be ignored. By changing only one pixel, they are able to reliably fool expensive DNNs across different architectures.

The image above shows the results using various metrics on the different metrics. As we can see, the results are exceptional. Moreover, the perturbation protocol used, Differential Evolution, is extremely inexpensive (we covered it in this post). To summarise: DE is cheap, can be applied to almost any problem, and can be customized easily to match any configuration.
In this article/post, I will be breaking down the major takeaways from this groundbreaking paper. We will discuss the implementation, possible extensions, and results. We will also go into interesting techniques used in the evaluation. I hope you’re excited for this, because this is going to be a fun one.
A quick note on this paper matters
Some of you might be wondering why this paper is significant. After all, what can we do by changing 1 Pixel? Aside from being used as a potential benchmark for future image classification models, the One Pixel attack has profound implications for our privacy and image security. This attack could be used as a way to stop facial recognition software from gathering information without our consent. Since the changes are imperceptible to human eyes, any images could still be used by humans in times of need, but mass automated surveillance could be prevented. However, that is not all. Papers such as this show us the importance of adding adversarial training to our protocols because the real world is filled with corrupted and messy data (both from malicious actors and unintended situations). Those familiar with my background will know that I have spent some time developing robust and scalable Deep Fake Detection Systems. These factors become huge considerations in that context (and others such as medical image processing).
Finally, by understanding the nuances of this attack, how it can be improved, and why it works a certain way, we can improve our results and gain a better understanding of the learning processes behind complex Neural Networks.
Experiment Setup
The experiment design was elegant and something we can learn from. The experiment used multiple datasets including Kaggle CIFAR 10, Original CIFAR 10, and the ImageNet dataset. All the datasets used are industry standard in Image Related works. Furthermore, the use of multiple datasets highlights the generality of the results.

The images were taken from multiple different classes (what the image represents). The model was trained to recognize and label an image into one of the classes. Once the image classification was trained, they attacked the model. The attacks were both targeted and non-targeted. Targeted attacks attempted to make the model misclassify the image as a specific different class, while non-targeted attacks just tried to fool the classifier.
To understand this take for example a fictional simple dataset containing 3 types of images cats, dogs, and rats. Take a model trained on our dataset. A targeted one-pixel attack on a cat pic might try to fool the model that the image is a rat. While a non-targeted attack will just try to fool the model that the image is not a cat.
How did they evaluate the results of changing a pixel?
With a lot of Machine Learning Research, it is important to look into the metrics used to evaluate the results. By understanding the metrics, we can evaluate a piece of research and its utility for potential solutions. We can look at the possible downsides of using the method, and the net scope. The research team used 4 different metrics for evaluating the results.
Success Rate: Simply put this was the percentage of images of one class that could be changed to another. This is the simplest one to understand and its use is fairly obvious.
Confidence: The average confidence given by the target system when misclassifying adversarial images. This is calculated as “Accumulates the values of probability label of the target class for each successful perturbation, then divided by the total number of successful perturbations.” The important thing is that this only looks at the successful cases.
Number of Target Classes: Counts the number of natural images that successfully perturb to a certain number of target classes. “In particular, by counting the number of images that can not be perturbed to any other classes, the effectiveness of non-targeted attack can be evaluated.”
Number of Original-Target Class Pairs: Counts the number of times each original-destination class pair was attacked. This puts the other metrics into perspective.
Interesting Results/Takeaways
This paper carries some interesting implications and learnings that one should not ignore. What I found interesting was:
Effective ML research can be conducted on lower resources
It feels like ML Research is becoming a game of computing power. Teams use thousands of computing hours and datasets of a colossal magnitude. New protocols are often extremely expensive. Which is why techniques like Differential Evolution and RandAugment always excite me. This paper costs peanuts. Take a look at the table below to understand.
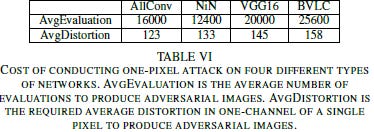
The costs of evaluation are super low. Most strong computers could run them without any problems. The fact that this paper was able to trick the costly DNN image classifiers with such low costs speaks volumes of the need for more diversity in terms of research directions and ideas.

We need to understand Neural Nets Better

This isn’t a new take. But this paper truly showcased the need to understand the black box learning process of DNNs. While most of the morphs were symmetric (if class A can be morphed to class B, then vice versa.), the paper revealed that there some classes that were easier to morph into others. For example with the AllConv Network, images of dogs could be misclassified as other things (including a truck?a frog?). This is obviously a curious result that warrants further investigation. By understanding the why behind this (or at least the how), we could potentially unlock the potential of ML.
Extensions
This paper has some interesting directions that might be explored. The paper does bring up several of them, but what struck me was the low quality of images. Using HD images would make the research more directly applicable to the real world. It would also validate the results for a world with an HD camera in every pocket.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.
For those of you interested in taking your skills to the next level, keep reading. I have something that you will love.
Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819