


Meta AI's open source version Google [Breakdown]
With Sphere, an Open Source Large Language Model, Meta steps into Google’s Turf. And improves Wikipedia along the way.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Last year, Machine Learning researchers at Meta released a new Large Language Model (LLM) called Sphere. With its amazing performance on search-related tasks, and ability to parse through billions of documents, combined with Meta’s other work in NLP, Meta has positioned itself well to disrupt the search market. In this article, I will cover the technology behind this architecture itself. To those of you interested in the implications of Meta Open Sourcing everything- read this article where I go into the implications in greater detail.
To do so, I will be referring to 3 primary sources. Meta’s announcement post, Introducing Sphere: Meta AI’s web-scale corpus for better knowledge-intensive NLP, their Github, and their paper- The Web Is Your Oyster — Knowledge-Intensive NLP against a Very Large Web Corpus. Other relevant sources will be linked as and when used.

Understanding the Background
Let’s take a second to understand what exactly Meta did, that has me so excited. To do that, we’ll have to take a slight detour. Trust me, this is crucial to understanding why this paper is important.
The Internet has been awesome for open access to education. It’s an amazing source of knowledge and information. But how can you find the most relevant source for your particular query and topic? For any particular query/search, the best source might not be ranked the highest. Esp. when you consider practices like keyword stuffing and SEO optimization. What ranks highest might not be the best source.
Most people resort to relying on trusted sources of information. Take the fantastic Math YouTube channel, Wrath of Math. Even if I see a video with more views on the same topic, I am likely to with Wrath just because he has consistently put out the highest quality information when it comes to more advanced Math topics. This is one of the biggest reasons that creators have such a high-earning potential today. A good creator has access to his audience's attention in a way that traditional media does not.
One of the go-to sources of information is Wikipedia. The team at Wikipedia works hard to ensure that the quality of articles and citations is well maintained. However, it has grown to a scale where purely human moderation is impossible. Just from the start of 2022, 128,741 new English articles have been added to Wikipedia. How can the moderation team go through and check every article and make sure every citation is appropriate?

Meta seeks to solve both these issues with their model Sphere. Sphere has been trained on multiple sources of the internet, beyond just Wikipedia/other traditional sources. This makes its corpus a lot more wide-reaching (as shown in the example earlier). Incase you don’t know, KI-NLP= Knowledge Intensive NLP.
We investigate a slate of NLP tasks which rely on knowledge — either factual or common sense, and ask systems to use a subset of CCNet — the Sphere corpus — as a knowledge source. In contrast to Wikipedia, otherwise a common background corpus in KI-NLP, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the web.

This allows it to retrieve answers from a much bigger pool of information, significantly improving the capabilities of the model. The capabilities of Sphere can also be used to verify citations and even suggest alternatives. Take a look at the passage below.

Obviously, to achieve such performance and scale, Meta would need to go ham on the engineering. Let’s take a look at the design of the Sphere model, that makes these amazing developments possible.
The Sphere Architecture
Sphere has a few interesting design decisions that need to be evaluated. For a quick overview of the architecture-

Firstly is the setup of their retriever models. Retrievers models are used to filter through the entire corpus, to find relevant documents. The documents are stored using an index, which is “a data structure which stores representations of corpus documents, built with the objective of optimizing the retrieval efficiency”.
They use both a Sparse Index + Model (BM25) and a Dense Index+Model (DPR). In BM25, the documents/queries, “are represented as high-dimensional, sparse vectors, with dimensions corresponding to vocabulary terms and weights indicating their importance”. Meanwhile, DPR “is a dense model which embeds queries and documents into a latent, real-valued vector space of a much lower dimensionality”.
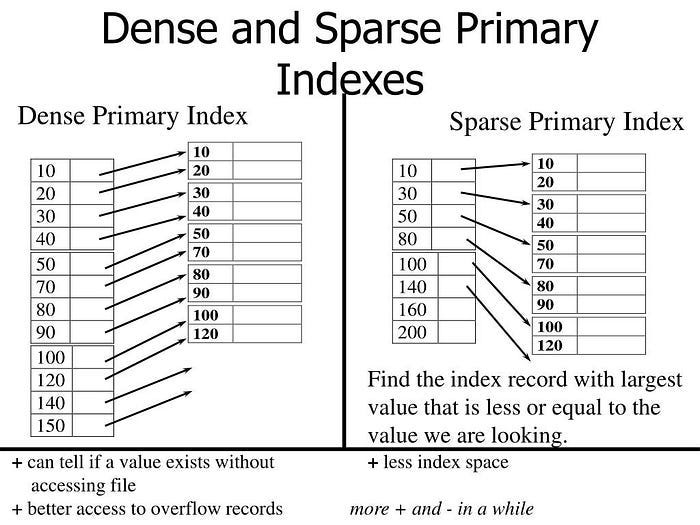
This is really interesting for a couple of reasons. Regular followers of my content will know that I’m a huge fan of Sparsity. In this YouTube video, I covered Sparse Weight Activation Training, a way to slash neural network training costs. To me, sparse activation as one of the biggest developments to look out for in this coming decade. When it comes to operating at Scale, Sparsity is an amazing solution. Indexing is no exception.

When operating at such a large scale, dense indexing of every document on one system is infeasible. Thus the engineers at Meta AI created distributed FAISS to distribute the indexing across several machines. Those interested in building distributed systems would do well to learn about it. You can find their GitHub here.
The documents retrieved by the retriever models are then passed on to the reader model. This is responsible for generating the answers. You typically see these falling into two broad categories-

For Sphere, the Meta researchers use the following setup-

The reader models are then trained for different individual tasks. These tasks are split into 5 categories: fact-checking, entity linking, slot-filling, ODQA, and dialog. Thus it is important to note that while the retriever models/indexing are task agnostic, the reader models do require specific training.

Combined, this allows Sphere to do an amazing job parsing through a large unstructured data corpus, to find the answers. Sphere’s performance is especially amazing because it is including all kinds of lower-quality sources. The fact that it can be competitive with Models trained on high-quality sources like Wikipedia, and find more information sources, gives it a lot of potential to be applied to web-related tasks.

This performance and scale are what make development so exciting. As I read through the appendix, what the authors gave examples of Sphere outperforming it’s competition. Take a look at the table below.

This ability to not only parse through documents, but also make contextually aware inferences is why I think we might see a Sphere based search platform soon. Think of how often human search is vague/imprecise. In such a case, more traditional search archiectures don’t perform as well. Sphere seems to adapt to such tasks much better, most probably because of it’s larger+more chaotic corpus.
There is one final thing that is very interesting about Sphere that has me very excited. Believe it or not, 10 years down the line, this might end up being Meta’s biggest contribution to Deep Learning Research.
Meta’s Open Source Push
One of the reasons that this development had a lot of Deep Learning insiders buzzing is the nature of its release. Big Tech companies have been under a lot of scrutiny because of how opaque the ML research published by them is. ‘Open’ AI is a perfect example. There is no information given about how they were created, what data/preprocessing was applied etc. This contributes to the AI replication crisis, which I covered here.

Why is that a problem? This turns these solutions into black boxes of sorts. It can be hard for outsiders to scrutinize and test the solutions, which can lead to the propagation of biases. Discussions around the topic can be limited since no one can go into the details. It also makes experimenting on these systems to test for security that much harder.
Meta acknowledges these problems. That is why they put a lot of effort into opening up everything. They even refuse to black-box search engines in building their corpus. Instead, they leverage the information available information online.
Our new knowledge source, Sphere, uses open web data rather than traditional, proprietary search engines. That means other AI researchers can see into and control the corpus, so they can experiment with scaling and optimizing different methods to push retrieval technology forward
Thanks to this, researchers gain a lot more control than would be possible otherwise. This also has a lot for fine-tuning retrieval for specific tasks by filtering the corpus to make it smaller. The fact that Meta has shared everything required to make this solution work is a huge win for the ML industry as a whole, and we will see a whole bunch of amazing solutions being created thanks to this. There’s another huge thing this will cause. In my article about Meta open-sourcing their version of GPT3 (Implications of Meta’s challenge to GPT-3 and Open AI), I made the following prediction-
There are two ways that this situation can play out-
Other tech companies join this trend and they start undercutting each other to gain an edge in the market. Economics tells us that this is amazing for consumers (us).
Business as usual in the industry. The other big companies don’t take the bait. For all the reasons mentioned earlier, this is already a huge win for consumers.
It seems like the first situation is becoming more likely. Amazon and Microsoft recently released their libraries for Bayesian Causal Inference. More and more big companies are trying to establish dominance against each other. This is an example of the big tech war, which I covered here.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!
Using this discount will drop the prices-
800 INR (10 USD) → 640 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819