


Understanding Google's GPT-Killer- The Revolutionary Pathways Architecture
The reason why their model Bard will be much more than a language model

In one of my recent articles, I wrote about why Bard will be much more powerful than ChatGPT. One of the reasons I gave was their unique system for training models, Pathways. A lot of you reached out and asked me to cover the Pathways architecture in more detail. So that is what I will be doing. In this article/post, I will be covering the key design decisions that differentiate the Pathways architecture from competitors.
To highlight how powerful these design ideas are, we will also be looking at the results of an amazing model that was created using Pathways last year Google’s Pathways Language Model (PaLM). PaLM is “a 540-billion parameter, dense decoder-only Transformer model trained with the Pathways system”. It gained a lot of notoriety in the AI space for its ability to explain jokes-

However, people mostly overlooked the Pathways architecture. We will not. Some of the innovations covered it implemented are very unique and might be huge in AI in the coming decades. To understand this, let’s go over the amazing Pathways system, which debuted in the writeup, Introducing Pathways: A next-generation AI architecture.
Why Pathways is a revolution.
The inspiration for the infrastructure is our brain. I know every Neural Network says that, but this is much closer than others. How? Think back to how our brains work. We have a ton of neurons with hundreds of trillions of potential wiring. As we learn certain skills, neurons fire together and build certain pathways. These pathways solidify as we practice. The next time we use that skill, our pathways will fire up, allowing us to remember that skill.
Researchers at Google did something similar. They built a giant model with tons of neurons and connections. They trained that one model on multiple tasks. And they implemented Sparse Activation so to save resources. It’s hard to argue with the results.
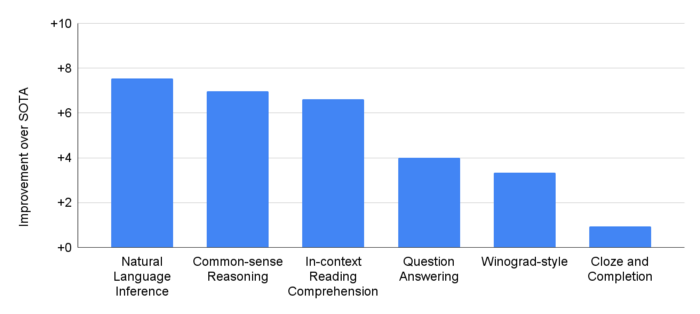
These implementation decisions are uncommon when compared to the way Machine Learning is conducted now. The researchers at Google raise a lot of points about why their approach is better than what is being done right now. Let’s cover these, and talk about how they add another dimension to the current discourse around Deep Learning. To do that, let’s first list out what makes Pathways closer to our own way of learning.
How Pathways takes inspiration from NeuroScience
There are several design choices that make the Pathways infrastructure much closer to our own minds. The big ones include
Multi-Task Training- Instead of training 1 Model for one Task, Pathways trains one model to do multiple things. Not transfer to multiple tasks. Directly do them. Like how we can learn to do multiple things over the same time frame.
Use of Multiple Senses- What will your input be? Video, Text, Sounds, Binary…? Why not all of the above. Think about how our minds combine multiple senses every day.
Sparse Activation- Training large models is expensive because you have to propagate through all those parameters. What if for a specific task, you only used a small portion of the network to train and run. We don’t use all our minds for all the tasks. Writing and dancing use different neurons.
Let’s explore this in more detail.
Multi-Task Training
In normal Machine Learning, we take a model architecture and train it from Scratch to teach it our specific task. But Google researchers are like edgy teens and are terrified of being seen as normal. They strive to express their individuality.
Pathways will enable us to train a single model to do thousands or millions of things
-From the Pathways introduction article.
Instead, they train the same model on many different tasks. The same model. Not the same architecture. The exact same model. Imagine a translation app also helping you solve some math problems.

What is the logic behind this? Let’s take a simple example. We know Cristiano Ronaldo plays Football. To be the freak of nature he is, he takes his physical conditioning very seriously. Thus, when it comes to activities like Running and Jumping, he is going to be much better than your average Joe, even though this is not his focus. Similarly, for a model becomes excellent at one task, it will probably develop some tertiary skills that will carry over to other tasks. In my more advanced readers, this might be ringing a few bells. You have one question-
How is Pathways Training Different from Transfer Learning
Transfer Learning is the practice of taking Large Models trained on generic tasks, and then using the insights gained from that to train a related model on a related example. The idea is that the knowledge from the related tasks will “carry over” to our new task. In our earlier example, Ronaldo’s training in Football allows him to also be a good Runner.
Pathways is different because they take this to the next level. When they say millions of things, they mean it. Pathways is trained on tasks that are almost completely unrelated to each other (look at the visualization above). This would be like teaching Ronaldo Differential Equations, while also training him to be an archeologist, as he was prepping to play Football. This is much closer to the idea behind AGI, and what has allowed the PaLM model to develop its much deeper understanding of meaning and language. It is also much closer to how we learn.
Multiple Senses
Senses are how we perceive the world. This is often overlooked in Machine Learning (especially if you’re primarily a statistical analyst like me) but senses literally determine your input. One of the biggest challenges in converting Machine Learning research into working solutions is in translating the input data into valuable information that can be analyzed. Preprocessing is a big deal. This is why people say that ML is mostly data cleaning and preprocessing.
For AI purposes, each Data Source can be treated as a sense. Most ML applications use limited sources and typically work on only one kind of data (NLP, Computer Vision, Behavior, etc). As you can see in the following passage, Pathways will not be doing this.

More senses lead to an exponential increase in capabilities. This is because each sense can be treated as its own space. More senses allow for more possible ways to encode the relations between objects, leading to far more possible embeddings. This will allow you to handle more kinds of inputs and generate more kinds of outputs.
This also mimics the way we interact with the world. We learn by interacting with objects using both our physical (touch, taste, smell, etc.) and mental (creating models, theories, abstractions) senses. Integrating more senses is much harder, but the pay-off is worth it. As the paper, “Accounting for Variance in Machine Learning Benchmarks” showed us, adding more sources of variance improves estimators. You can read my breakdown of the paper here, or watch the following YouTube video for a quick explanation. Either way, don’t miss out on this paper.
Sparse Activation
This is probably the most interesting idea to me in the entire paper. To understand why this is so cool, think back to how Neural Networks work. When we train them, input flows through all the neurons, both in the forward and backward passes. This is why adding more parameters to a Neural Network adds to the cost exponentially.
Adding more neurons to our network allows for our model to learn from more complex data (like data from multiple tasks and data from multiple senses). However, this adds a lot of computational overhead. I know that this will come as a complete shock to you, but make sure to breathe. It helps when dealing with such shocking information.

Sparse Activation allows for a best-of-both-worlds scenario. Adding a lot parameters allows for our computation power. Palm does have 540 Billion Parameters. However, for any given task, only a portion of the network is activated. This allows the network to learn and get good at multiple tasks, without being too costly.
We can build a single model that is “sparsely” activated, which means only small pathways through the network are called into action as needed. In fact, the model dynamically learns which parts of the network are good at which tasks -- it learns how to route tasks through the most relevant parts of the model. A big benefit to this kind of architecture is that it not only has a larger capacity to learn a variety of tasks, but it’s also faster and much more energy efficient, because we don’t activate the entire network for every task.
The concept kind of reminds me of a more modern twist on the Mixture of Experts learning protocol. Instead of deciphering which expert can handle the task best, we are instead routing the task to the part of the neural network that handles it best. This is similar to our brain, where different parts of our brain are good at different things.
Sparse Activation is such a cheat code that it provides much cheaper training while giving the same performance. Take a look at this quote from the Pathways writeup-
For example, GShard and Switch Transformer are two of the largest machine learning models we’ve ever created, but because both use sparse activation, they consume less than 1/10th the energy that you’d expect of similarly sized dense models — while being as accurate as dense models.
This shows itself with the PaLM model. Adding more parameters allows for a much greater ability when it comes to tackling challenges. Inferring the nature of the task given, training for it, and being handle to handle it are all expensive procedures. Sparse Activation allows the model to handle all this better.

I looked around for more details on the Sparsity Algorithm at Google, but couldn’t find too many details on it. If you have any insights/thoughts on it, please do let me know. However, this idea of Sparsity intrigued me a lot when I was researching it. So I looked into a few algorithms. My favorite was Sparse Weight Activation Training or SWAT. I have a video going into more details on it linked below. To those of you that need a reason to watch it- this algorithm can lead to an 8x reduction in FLOPs while keeping your performance drop within 5%.
Clearly, you can now see how Pathways will be a game-changer for AI research in the upcoming decade. It combines ideas from neuroscience, Machine Learning, and Software Engineering with the scale of Large Language Models to create something exceptional. The training protocols will be era-defining, even as people create other, better ML models. Before we finish, I’d appreciate if you answered the following poll
If you’d like to have more influence on my content, I run polls like this on LinkedIn. Make sure we’re connected over there.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people.
For those of you interested in taking your skills to the next level, keep reading. I have something that you will love.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!

Using this discount will drop the prices-
800 INR (10 USD) → 533 INR (8 USD) per Month
8000 INR (100 USD) → 6400INR (80 USD) per year
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
This is really well written. Pathways and the mixture of experts approach will enable a lot of interesting models in the near future for sure.