
Why ChatGPT lies[Breakdowns]
The problem with Generative AI that causes it to spew misinformation.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
A lot of people talk about ChatGPT making things up. It is among the biggest problems with Large Language Problems that I covered here. Recently, I wrote an article called How Amazon makes Machine Learning More Trustworthy. In it, I broke down multiple publications by Amazon where they answered how they created AI models that were more immune to bias, and more robust while also protecting user privacy. I was curious how ChatGPT would summarize the article. Take a look-

It did a pretty solid job. However, the last sentence of the summary is pretty interesting, because I never wrote anything about human evaluations. This was something ChatGPT came up with, on its own. In our case, this was pretty harmless. But apply this tendency towards delusion and making things up in fields like Law or Medicine, and you will have a very problematic
The tendency for Deep Learning Agents to ‘hallucinate’ is not a new one. However, billions of dollars are still being poured into LLMs and other complex Generative Deep Learning systems (GPT-4 is apparently on the horizon). Microsoft spent billions to integrate Open AI, startups are raising millions, and now Google has joined the party with their language model Bard. In this article, I will be going over some of the design flaws with these models that cause hallucinations. Understanding this will help you integrate/use these models in a safer and more effective way.

Note: While there are problems like biased datasets and just poisonous data in training, those are issues that can be fixed. I will be focusing on the architectural issue that is causing the hallucinations
A Quick Refresher on ChatGPT
To understand the reason it lies, let’s first do a very quick refresher on how it works. Specifically, I will be focusing on the latent space embedding, the pretraining with large data corpora, and the generative word-by-word output format since they are the biggest culprits to ChatGPT/other Deep Learning modules and their tendency to lie. These 3 components work as follows-
The datasets are encoded into a latent space.
The latent space is used to train the data.
ChatGPT then uses this encoded space to process your query. The query is fed into the latent space. The AI traverses the latent space to find the best outputs.
To those of you that want a high-level overview of how ChatGPT works, this video does a solid job of going over the big parts of the model. I also like this post by Sebastian Raschka that explains RLHF, the key behind the chat capabilities of ChatGPT.
Latent Space Embedding
A latent space, also known as a latent feature space or embedding space, is an embedding of a set of items within a manifold in which items resembling each other are positioned closer to one another in the latent space. Now some of you are probably scratching your head at these terms so let’s go with an example. Imagine we were dealing with a large dataset, containing the names of fruits, animals, cities, and cars names. We realize that storing and training with text data is too expensive, so we decide to map every string to a number. However, we don’t do this randomly. Instead, we map our elements in a way that lemons are closer to oranges than grapes and Lamborginis. We have just created a latent space embedding.

If you’re looking to get into AI, especially into Large Models, then you should understand this idea very well. While Latent Spaces can be hard to work with and interpret, they are really useful when working with data at scale. They can turn higher dimensional data into lower dimensions, which can help with storage, visualization, and analysis.
ChatGPT uses Latent Spaces to encode the large amounts of text used to pre-train the model. Latent Spaces allow ChatGPT to produce coherent pieces of text since it allows it to stick to relevant details. If I ask ChatGPT to help me write a love letter, I don’t want it to give me an essay on Karl Marx. Latent Space Embedding accomplishes this by staying in neighborhoods that are close to love and relationships and far from the economics of labor (although since divorce should be close to love, there is a chance my model might end up going the wrong way).
So what issues does this cause? Let’s think back to the Amazon breakdown I mentioned earlier. Most likely, the embedding was something near bias in AI and what Amazon does to address it. Human audits and evaluations are a very common idea that is thrown around to combat bias, so it’s not unlikely that this slipped into the generative word-word output. Since LLMs like ChatGPT rely on first encoding the query into a latent space, this issue will continue to show up since we can’t really control how the AI traverses that space.
In the case of reliability, latent space embeddings end up being a double-edged sword. They allow the model to efficiently encode and use a large amount of data, but they also cause possible problems where the AI will spit out related but wrong information
To drill this point home, I’m going to cite the experiences of a friend of mine, who works in SEO for cars. He told me about his experiences with ChatGPT and told me that it was almost more effort than it was worth. ChatGPT would keep creating specs/deals that were wrong. Most likely, the car details that my friend was feeding in conflicting with some online records, causing ChatGPT to spit out misinformation. Had he gone ahead without looking into this, he would have been fired for doing a terrible job.
Latent Spaces are not the only issue with the issue of LLMs that causes them to lie. The next problem is so integral to these models that it’s in the name. And it forms a double whammy with the flaws of latent space embedding.
‘Large’ Datasets
As should come as a surprise to no one, large language models like ChatGPT need a lot of Data. This is what allows it to talk about quantum physics, sales processes, and everything in between.

However, this comes with a downside. When it comes to generating text for a particular task, the other information that GPT has been trained with is mostly irrelevant. Going back to the Amazon Example, I only wanted a summary of my article. Any other practices were irrelevant. However, the large size of the ChatGPT training means that no matter what you feed as a query, chances are that there will be another irrelevant piece inside the neighborhood of your embedding. Thus, the model will slip those parts into your system, without thinking twice.
Take the example of prominent Subsatck Writer and Economics person,
. He asked ChatGPT to help with an article-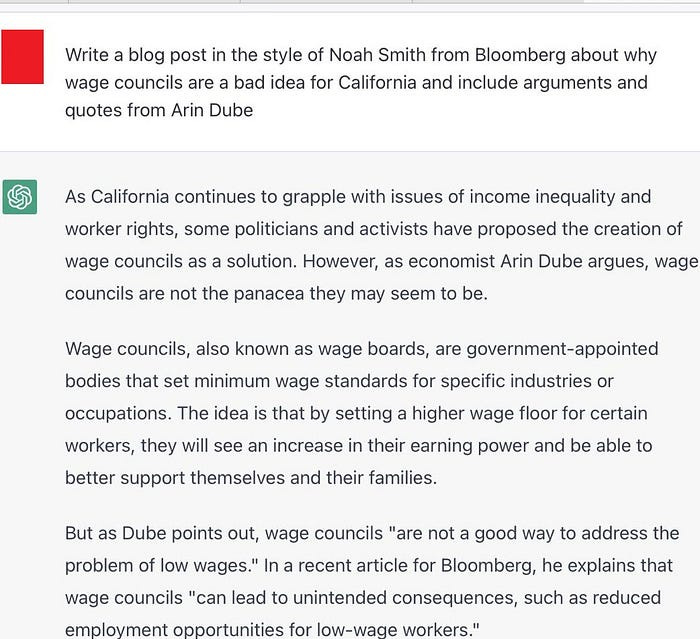
However, apparently, this has a few issues. To quote the man himself-
There are just a few problems with this output. First, the quote from Dube is completely fictitious. Second, though he has been interviewed for Bloomberg, Dube has never written an article for that publication. And third, and most importantly, Dube’s position on wage boards is completely opposite to what ChatGPT claims in the above passage.
ChatGPT definitely has arguments against Wage Boards, and it has the characters Arin Dube, Bloomberg, and California. So it’s not hard for it to come up with this fictional position. The extensive scale of its training database creates the lies.
As a relevant tangent, the large training sets used in Large Models can also negatively hurt performance. The authors of “A Comparison of SVM against Pre-trained Language Models (PLMs) for Text Classification Tasks” compared the performance of LLMs with a puny SVM for text classification in various specialized business contexts. They fine-tuned and used the following models-

These models were stacked against an SVM and some old-fashioned feature engineering. The results are in the following table-
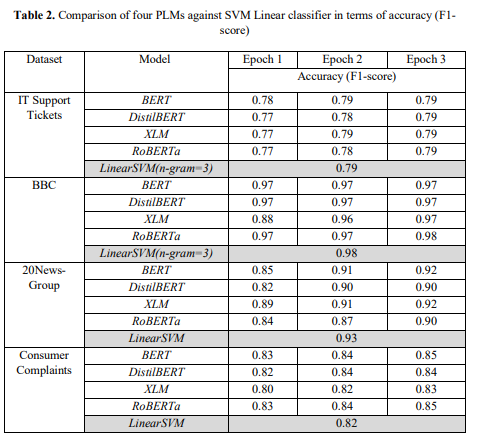
As you can see, SVMs match the performance of these large models. Keep in mind, text classification is one of the core functions of these bigger models. My guess here is that conflicting sentiments from different domains might have overloaded the fine-tuned models, preventing them from hitting peak performance in a specific business case.
Once again, we see a pattern. Large datasets are one of the core features of LLMs. However, they also cause an issue of trust and reliability, since they lead to the model going over irrelevant areas/mixing in false information.
Moving on to the final reason that causes these models to lie- the way output is generated.
ChatGPT is Fancy Autocomplete
Here is how ChatGPT produces its output- it uses the embedding and the datasets, to predict the most likely next word. This process is stochastic, which is why the same query can create different outputs. But at its core, ChatGPT functions very similarly to the autocomplete on your phone.
Why is this relevant? Try producing essays on Autocomplete. Eventually, it will take a weird direction. LLMs are no different. As you go token by token, the error will continue to propagate. The deviation will be slight at first, but it will continue to shoot up as the output becomes more complex. Lies/misinformation are inevitable in this case.

Unlike the other two reasons discussed, this could possibly be changed. By increasing the lookback/window that the probability generation considers, we might be able to reduce the error increase after every generation to a manageable level. However, this would also likely require much more training and validation, making it infeasible to develop. I’m basing this bit of my own experiences and conversations with others. However, keep in mind I’m not a text expert, and could be off here. If you have any insights into how we can accomplish better generations, I’d love to hear them. As always, you can either leave your thoughts in the comments, reply to this email, or simply use one of my social media links to reach out.
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Upgrade your tech career with my newsletter ‘Tech Made Simple’! Stay ahead of the curve in AI, software engineering, and tech industry with expert insights, tips, and resources. 20% off for new subscribers by clicking this link. Subscribe now and simplify your tech journey!

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819