


Why your AI fails in Production [Guest]
Beyond Benchmarks: Why your perfect lab model fails when real users, messy data, and infrastructure constraints show up

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Since 2019, Louis-François and Towards AI have shared thousands of articles through their publication and hundreds of videos via the What’s AI channel. Their education platform has been used by over 100,000 learners to help bridge the gap between academic research and real-world industry needs.
Today’s guest post goes back to the basics, exploring one of the core phenomena experienced by Machine Learning teams everywhere— the production model collapsing despite stellar benchmark scores. It’s a great look at some of the practical realities of AI engineering, especially as our industry struggles w/ increasing divergence b/w benchmarks and utility (the Llama 4 debacle of gaming benchmarks being a high-profile example of the same).
As you read this, here are some angles worth considering:
Shaping the User: Any production system will inevitably collide with users doing stupid shit and misusing the platform. Trying to patch everything is expensive and opens you to a lot of user churn. How can we design a system's feedback loop (e.g., its error messages, its latency, its failure modes) not just to tolerate unpredictable user behavior, but to actively train users over time to interact with the system in a more predictable, efficient, or profitable way? Any good examples of the UX we can study?
Ecosystems and Intelligence: Given that so much failure happens outside the “intelligence” layer, we see that AI needs a powerful ecosystem to truly benefit. What aspects of the ecosystem is the industry currently undervaluing as it overfunds AGI?
What does "monitoring" even mean in the age of stochastic outputs?: So far the answer has been largely the use of LLM as a judge or LLMs as a jury. What do we do to move beyond that?
Monitoring Pressures: Adding metrics in monitoring creates implicit pressures to maximize performance on the monitors, guiding future development of the system. What do we make sure that our metrics stay updated as things change?
What does monitoring look like for Agents, MCPs, etc where you have multiple tools chained together.
Have fun and make sure you drink lots of water.
TL;DR:
Lab models succeed in controlled environments—but fail under production pressures like latency, cost, and unpredictable users.
Common reasons include integration issues, lack of monitoring, and unrealistic assumptions about hardware.
This post outlines production-ready ML strategies—from system design to stress-testing LLMs in the wild.
Machine learning in the lab runs on ideal conditions—clean datasets, generous GPUs, and tightly controlled benchmarks. But the moment that model hits production? Everything changes.
Suddenly, you're juggling:
Limited hardware and compute quotas
Messy, unpredictable real-world inputs
Tight latency and uptime budgets
Privacy and compliance requirements
And actual users are doing weird, unexpected things
A model that scored 95% on paper might stall under real traffic, frustrate users, or rack up an unexpected GPU bill that blows your budget. When your model breaks in production, the stakes are higher: latency turns into user drop-off, instability eats into customer trust, and rising infrastructure costs cut directly into profit margins. You’re not just debugging a model—you’re patching holes in the product experience.
In this post, we explore the messy, practical side of machine learning deployment. First, we’ll map the most common pitfalls (with real-world examples). Then we’ll break down how production teams navigate them using smarter infrastructure, monitoring, and optimization. Finally, we’ll apply those lessons to the ultimate stress test: deploying LLMs at scale, safely and responsibly.
Why Your Model Breaks After the Paper is Published
Training in the lab is one thing. Running models in production is a different game.
Research-Grade Doesn’t Mean Production-Ready
Models that ace academic benchmarks often struggle when real traffic hits. Under actual loads, tiny inefficiencies compound rapidly—latency balloons, memory spikes, and what once felt fast becomes sluggish. A recommendation model performing smoothly in internal tests might crumble during a Black Friday rush when every millisecond counts.
Even slight increases in latency significantly reduce user engagement and conversion rates, directly impacting revenue and customer retention. Users today expect instantaneous responses; any noticeable delay can damage trust and brand perception. (Large-scale studies at Amazon and Google found that just 100 ms of added latency can shave 1% off conversions—millions in lost upside.)
Smart teams plan for scale early. They bake in batch inference, caching, and throughput-aware architecture before launch.
The Hardware Reality Check
Research typically assumes access to powerful GPUs (like A100s) or TPUs. In production, you're often limited to shared GPUs, CPUs, or even edge devices.
Why it matters: If inference costs more to run than the feature earns, finance will pull the plug—no matter how elegant your model is.
This reality means rewriting inference code, using techniques like distillation, quantization, and pruning to meet real-world constraints. These trade-offs aren’t glamorous, but they're essential. Failing to optimize models for production hardware can result in prohibitively high costs, degraded performance, or operational infeasibility—potentially killing a project's profitability.
Lab Metrics Miss the Real Picture
F1, BLEU, or ROUGE scores might look great in research papers but rarely matter in production. What truly counts are metrics directly connected to the user and business outcomes:
Uptime: Is the system reliably available?
Latency: How quickly does the model respond?
Cost per inference: Is the model economically sustainable at scale?
User satisfaction: Do users find the system helpful, responsive, and trustworthy?
A chatbot with outstanding BLEU scores but slow replies won't succeed in the real world. What gets lost in academic metrics is opportunity cost—a quarter spent tuning BLEU is a quarter not spent improving latency, throughput, or explainability. These aren’t just trade-offs—they’re bets on where value lives. Optimizing for production metrics early keeps your ML work aligned with what actually matters: outcomes.
Effective teams start with business metrics and optimize models to achieve those goals. Ignoring these business-centric signals risks deploying academically impressive models that disappoint users, reduce retention, and quietly undercut impact.
Notebooks Are for Prototypes, Not Production
Interactive tools like Jupyter Notebooks are great for exploring ideas, tweaking parameters, and visualizing results. But in production, you need:
Versioned code, data, and models
Reproducible pipelines
Fast debugging paths when things break
Building with traceability and rigorous version control from the outset prevents minor issues from cascading into prolonged outages, difficult debugging processes, and costly downtime.
Integration is Where Models Die
Even a perfect model fails if it doesn’t fit into the broader system. You’ll run into:
Legacy APIs
Weird upstream data formats
Missing or malformed inputs
Integration isn’t a final step—it’s a foundational constraint. Successful teams prototype with real-world data and design specifically for live conditions. Integration issues, if addressed too late, lead to last-minute delays, increased development costs, and potentially catastrophic downtime.
And when integration fails late in the pipeline, it doesn’t just blow up timelines—it breeds cross-team blame. Model teams point to API issues. Product teams point to model inconsistency. Infra flags resource abuse. The result? Everyone slows down, and machine learning starts to look like a liability instead of a lever.
If You’re Not Monitoring, You’re Flying Blind
Models decay. Inputs shift. Infrastructure evolves. Users surprise you.
Without proactive monitoring, performance degradation remains hidden until users complain. Dashboards, alerts, and comprehensive logging are your early warning systems. Unchecked degradation severely impacts user experience, causing customer churn, revenue loss, and damaged reputation. Robust monitoring proactively identifies and mitigates these risks, maintaining reliability.
The Model Isn’t the System
Production failures typically aren't due to the model itself but the surrounding system—the "glue": missing documentation, broken APIs, inadequate logging, or absent fallback mechanisms.
Bridging the gap between research and production isn't a one-time task. It’s an ongoing process that requires thoughtful infrastructure design, observability, and cross-team collaboration. Neglecting comprehensive system reliability undermines even advanced models, causing failures that directly impact end users.
The danger isn’t just downtime—it’s fragility. Systems that aren’t observable or testable can’t be trusted. That means more manual reviews, slower releases, and constant firefighting. And when that fragility becomes systemic, it doesn’t matter how accurate your model is—because no one’s willing to rely on it.
If you’d like a hands‑on walkthrough of everything from proof‑of‑concept to production, plus advanced LLM topics, the Beginner to Advanced LLM Developer course is a solid next step. It starts with the basics and builds to full production workflows, reinforcing the principles we’ve explored here.
Below are some strategies that top teams use to bridge that gap—and ship machine learning systems that work under real-world conditions.
How Production Teams Bridge the Gap
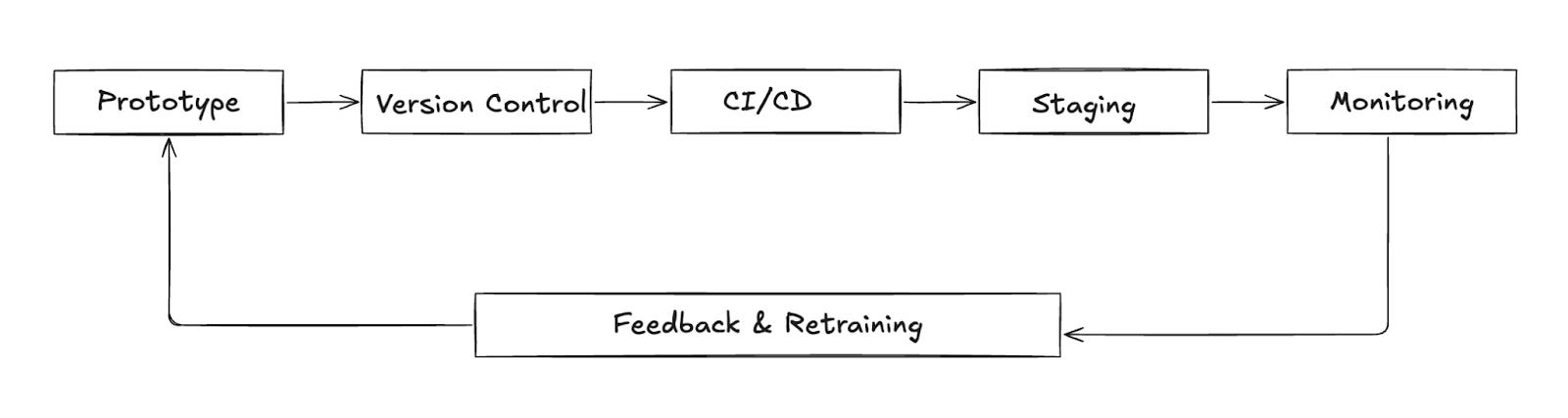
Continuous loop from prototype to production, with live feedback driving retraining
Turning a research prototype into a stable, scalable ML service takes more than a trained model. The teams that succeed consistently follow a different playbook—one grounded in real constraints, collaboration, and operational discipline.
Here’s what that looks like in practice.
Start With the Application, Not the Algorithm
Don’t build a model and then figure out how to use it.
Define the problem, success metrics, and constraints (latency, budget, device) first.
Make accuracy serve the product, not the other way around.
A crop-disease detection model should optimize for robustness and speed on mobile devices, not marginal accuracy gains on academic datasets.
If your model doesn’t align closely with real user needs and constraints, it will fail in practice—regardless of how sophisticated the algorithm is.
Pull in Product and Infra Early
Model decisions—architecture, format, deployment targets—have downstream consequences.
Involve engineers, infra, and product early in the pipeline.
Align on how data is stored, which platforms the model will run on, and what trade-offs are acceptable.
Skip this, and you’ll be retrofitting a GPU-trained transformer into a mobile app the week before launch.
Late-stage architectural changes due to poor early alignment can derail project timelines, inflate costs, and compromise product quality.
Borrow From Software Engineering
Good ML products behave like good software: versioned, testable, and reproducible.
Track every dataset, training config, and model checkpoint.
Use containers to eliminate “works on my machine” bugs.
Wire up CI/CD pipelines so updates are safe, small, and fast.
This isn’t overhead—it’s insurance against silent breakage.
Without rigorous engineering practices, seemingly minor changes can result in production failures, downtime, and significant maintenance costs.
Optimize for Deployment, Not Just Accuracy
Once the model works, make it production-worthy.
Use distillation to create smaller, faster student models.
Quantize and prune to fit compute budgets.
Rewrite the inference code to match your actual deployment stack.
Cutting 2× latency or 50% cloud spend often matters more to the business than nudging accuracy another decimal.
Monitor Everything Post-Launch
Shipping is just the beginning. Drift, bugs, and slow regressions are constant.
Set up dashboards to monitor model inputs, outputs, latency, and usage.
Log predictions and user interactions for feedback loops.
Unmonitored models silently degrade, leading to dissatisfied users, revenue loss, and damaged trust.
Build for Change
Data changes. Infrastructure changes. Teams change. Build systems that survive all of it.
Containerize services so they can move across platforms.
Use retraining pipelines to adapt to shifting data.
Architect for modularity: swap models, retrievers, or endpoints without breaking the stack.
Rigid systems fail under inevitable changes, causing downtime and increased maintenance costs. Flexible systems enable seamless updates, keeping your product robust and reliable.
Large language models push every challenge to its limit—scaling, monitoring, privacy, safety, and cost. They’re not a special case; they’re a stress test. The same principles apply—but they need to be tighter, faster, and more intentional. We’ll unpack that next.
Deploying LLMs: The Ultimate Stress Test
LLMs unlock powerful capabilities—but they come with demanding infrastructure and reliability challenges. They amplify every deployment concern: cost, latency, safety, monitoring, and compliance. Here’s what to watch for—and how top teams are keeping these models stable in production.

Scale Breaks Everything
LLMs with tens or hundreds of billions of parameters mean inference isn’t just slow—it’s costly and resource‑hungry. Here’s what production teams actually do:
Knowledge Distillation: Train a smaller “student” model to replicate a larger “teacher” model’s outputs. For example, TinyLlama offers a lighter-weight option for cost-efficient inference.
Tip: Continuous or iterative distillation is gaining traction—teams retrain student models as teacher models evolve, keeping performance fresh.Quantization: Compress model weights from higher to lower precision (e.g., 32-bit to 8-bit) to reduce memory and compute without major accuracy loss.
Batching and Caching: Group multiple incoming requests and cache frequent outputs to maximize GPU utilization.
Serverless Scaling: Platforms like Modal or RunPod spin up GPU workers on demand—no idle capacity, instant scale under load, and pay‑as‑you‑go billing. Hybrid cloud/on-prem deployments are also common for balancing cost, compliance, and latency.
Taming Latency
Even with a lean model, network hops and cold starts can bite. To shave off precious milliseconds:
Asynchronous Pipelines: Instead of making the client wait for the model’s response, use a message queue (Kafka, Redis Streams) to process requests in the background. The client gets an immediate “accepted” reply, then polls or subscribes to the result. This absorbs traffic spikes and keeps GPUs running at full capacity by enabling batch processing and better job scheduling.
Warm‑Up Probes: Send lightweight dummy requests every few minutes (e.g., a 1‑token prompt) to keep model artifacts loaded in GPU memory. This avoids “cold” initialization delays when real traffic surges.
Speculative Decoding: Run a tiny, fast model to predict the next few tokens and then confirm them with the main LLM—trading a bit of extra compute for lower tail latency.
Treat Monitoring Like a First-Class Concern
LLM performance drifts as user inputs shift. A robust observability stack should:
Log input distributions (token lengths, special‑token ratios) and output patterns (entropy, repetition rates).
Track latency percentiles (P50, P95, P99) with Grafana dashboards and Prometheus metrics.
Alert on anomalies—for example, sudden spikes in generation time or unexpected token distribution shifts.
Drift Detection: Use tools to monitor for data and concept drift—subtle shifts in input data or user behavior that can degrade performance.
Collect user feedback—ratings, corrections, complaints—to catch what metrics miss. Always implement fallback logic for failure cases (e.g., rule-based responses).
Compliance & Safety Aren’t Afterthoughts
If your LLM handles sensitive data, you need guardrails by design:
Data Controls: Encrypt inputs at rest and in transit; anonymize personally identifiable information before inference.
Access Policies: Enforce fine‑grained roles in your data pipelines (e.g., via IAM).
Output Moderation: Filter every generation through an API (e.g., OpenAI’s Moderation API) to catch toxicity, then loop in human reviewers for high‑risk domains.
LLMs Are a System, Not Just a Model
Treat your deployment like a distributed application:
Version Everything: Model, data, config—tag every artifact for full reproducibility.
Explainability: Use tools like Captum or LangSmith to trace outputs back to inputs.
Modularity: Break retrievers, safety filters, caches, and the core model into independent services for easy swap‑in/swap‑out.
CI/CD & Canary Deployments: Automate end‑to‑end testing and roll out new models to a small percentage of traffic before full launch.
These production-ready techniques—distillation, quantization, dynamic batching, proactive monitoring, and built-in safety—help bridge the gap between prototypes and reliable, scalable LLM deployments.
Wrapping It All Up
Getting a machine learning model to work in the lab is the easy part. The hard part? Making it reliable, affordable, and safe in production—under real traffic, on real hardware, with real consequences.
That shift requires more than good modeling. It takes:
Thinking in systems, not scripts
Designing for latency, cost, and scale from day one
Collaborating across teams—infra, product, legal, and beyond
Building pipelines for reproducibility, monitoring, and maintenance
And treating LLMs like the complex, high-stakes systems they are
None of this shows up on academic leaderboards. But it’s the difference between a clever prototype and a machine learning product that works.
If you're navigating the shift from research to production and want to go deeper into the engineering practices, tooling, and deployment strategies that make LLMs production-ready, the Beginner to Advanced LLM Developer Course is designed for you. With over 60 hours of practical, in-depth content, it covers everything from foundational concepts to advanced techniques like quantization, scaling, and monitoring. Whether you're building your first LLM system or refining an existing pipeline, this course gives you the tools to move beyond prototypes and build systems that perform reliably in real-world.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Excellent breakdown!
I'm really happy we made this post happen! Love the final results and hope everyone will enjoy the read!