


How to Pick between Traditional AI, Supervised Machine Learning, and Deep Learning [Thoughts]
The framework I use to determine what tool to use for your problems

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights
Thanks to the explosion in AI, we have seen an outbreak of new techniques to solve various problems. While a net positive, this leads to a lot of confusion within AI teams on how to best tackle problems. This is very pertinent since the growing scale of software means that backing the wrong horse can lead to 6–7 figure losses, even in relatively small operations.
This article has been inspired by the many discussions I’ve had with clients. One of the most common questions I get is how I pick the right tools to do the job. Today, I will talk about my framework for picking between traditional AI, Supervised Machine Learning, and Deep Learning when it comes to delivering solutions. While this is not an exact science, some general heuristics work well as guidelines. This is my evaluation of the various techniques-
Traditional AI- The most secure, understandable, and performant. However, Good implementations of traditional AI require that we define the rules behind the system, which makes it unfeasible for many of the use cases that the other 2 techniques thrive on.
Supervised Machine Learning- Middle of the road b/w AI and Deep Learning. Good when we have some insight into the workings of the system, but are unable to create concrete, well-defined rules for it.
Deep Learning- Opaque and costly, far too many teams rush to use Deep Learning when other solutions would suffice. However, with very unstructured data, where identifying rules and relationships is very difficult (even impossible), Deep Learning can be the only way forward.
One of these is not better than the other. Nor are they mutually exclusive. Even in modern AI pipelines, traditional AI techniques like Regexs, Probability Distributions, and Clustering are used in data extraction, feature engineering, and pipeline monitoring. This enables effective deployment of Machine Learning and Deep Learning.
PS- AI Made Simple is about to hit its 1st anniversary. We will be hosting an AMA (ask me anything) to celebrate this. You can ask your questions in the comments, message me on any of the social media links, reply to this email, or drop any questions you have in this anonymous Google Form- https://docs.google.com/forms/d/1RkIJ6CIO1w7K77tt0krCGMjxrVp1tAqFy5_O2FSv80E/.
PPS- Based on the last poll, it seems like most people (94%) like the highlights section. To those that feel like this section makes your experience worse, what can I do to improve it. Please lmk.
What is the difference in AI, Machine Learning, and Deep Learning
In reality, DL is a subclass of ML, which is a subfield in AI. AI is itself a massive field, containing everything from a collection of if statements to complex evolutionary algorithms and self-organizing systems. But for this article, here is how we are differentiating between these techniques.
Traditional AI systems are developed by analyzing the system and creating rules around it. These rules are explicitly programmed, significantly boosting the transparency of the system. These systems are also computationally efficient since there is no expensive training process, However, since these rules must be defined before running the system, traditional AI is often hampered in the scope of adaptation. In very complex (or high-dimensional systems) inferring rules/relationships between variables can be either impractical or impossible. This is where ML comes in. ML Engineers feed the machines lots of data, and let the machine approximate the rules for itself.
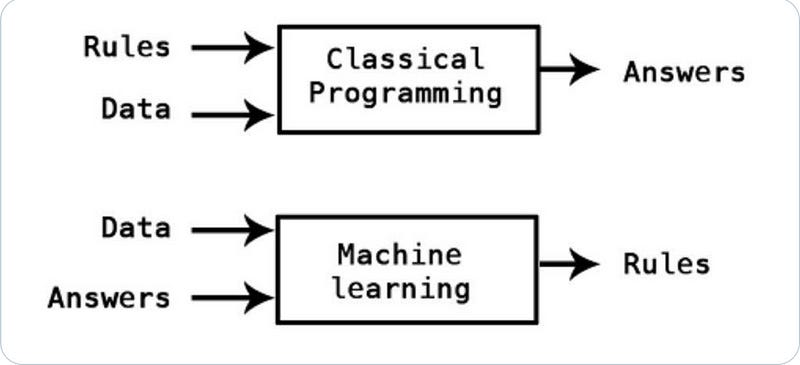
Machine Learning came to prominence because it matches many requirements of the information era-
Cheap computation, large volumes of data make training ML Systems feasible.
Human expert time is expensive, so paying them to try and identify very complex rules doesn’t always make sense.
Deep Learning just takes this a step further. Traditional ML relies on feature extraction, which might not be possible in all use cases. For example, when I worked in Deepfake detection, it was really hard for me to manually pull out features that were relevant to deepfakes. This is where DL can be great. The following writeup from IBM puts it well-
Deep learning automates much of the feature extraction piece of the process, eliminating some of the manual human intervention required… A deep-learning model requires more data points to improve accuracy, whereas a machine-learning model relies on less data given its underlying data structure.
With this explanation out of the way, let’s now look at some variables that can be useful in identifying where each of these comes in. Starting first with the availability of data.
Availability of Data
Without access to high-quality and high volumes of Data, ML and DL are generally infeasible. When data is scarce, traditional AI systems are the only solutions that can work somewhat effectively- assuming that you have the domain expertise to create the rules.

{kind=link}
What about very complex systems where you can’t create explicit rules? My first instinct here would be to consider giving up and finding better ways to spend your resources. This might not be sexy to say- but not every problem can be solved with automated decision-making. Nor should it be. Sometimes it’s better to table ideas for a later date. Too many teams make the mistake of getting too gungho about the technology without fully thinking whether it’s really a good idea (we did the Under Armor case study here).
For the sake of argument, let’s say that you have a use case with low-quality data that you have to build on. Are you doomed to failure? Well… it depends.
Things can be quite interesting if you have high volumes of low-quality data. This was the case when I worked in state healthcare policy analysis. We had to quantify the impact of changes in health system policy on public health for a state government with 300 Million citizens. There was a lot wrong with data- unreliable information, high missingness, and high dimensionality- but we were able to use Machine Learning somewhat effectively. This worked b/c the project had 3 properties-
My supervisors were absolute studs in the public health space, so they were able to ground my ML work with context. Their input would allow me to refine my solution w/o wasting too much time.
I had enough data that I could test out my assumptions about data imputation, structural analysis, and more.
I wasn’t tied to a fast release schedule and was given a very wide berth to run all my experiments. This allowed me to spend a lot of time on exploration and research.
If your situation meets these requirements, then the middle-of-two-world nature of ML can be useful to build your base around. Fun tangent- my supervisor's comments and the applied research and open-ended nature of the assignment were key to my getting into writing.
However, this should be treated as a stopgap. If you must build some kind of decision engine for a system with low-quality data, then you should immediately ramp up your data-gathering and ingesting capabilities. Ultimately, that is the only way for you to proceed. Trying to brute force your way out of bad data will only lead to your venture intimately embracing failure.
Goes w/o saying, that having a lot of high-quality data makes ML and DL feasible, but that doesn’t always mean we need to use them. You might find that the ROI is not worth it. That’s where you need to have a strong alignment b/w the product and engineering team, to create meaningful baselines and cutoffs.
Understanding of domain
The next factor to consider is your understanding of the domain. To create effective rules, you need to understand your system deeply. If you have a good understanding of your system, then trad AI will give you amazing performance. Take this longish (but super insightful) quote from the NetHack Challenge, where we saw various automated agents face off to beat a game. Interestingly enough, the challenge was dominated by symbolic AI and not RL agents-
The margin of victory was significant, with the top symbolic agent beating the top neural agent by a factor of almost 3 in the median score. This was, in fact, increased when looking at the very best agents from each team, where frequently we might see almost an order of magnitude improvement in the median score between the best symbolic and neural agents.
While our best symbolic teams had moderate-to-expert NetHack domain understanding, we were surprised to find they often had extensive ML experience as well. In fact, both winning symbolic teams said they had intended to enter the neural track, but found their symbolic methods scaled much better…
NetHack benefits ‘strategic’ play … Symbolic bots found it easy to define ‘strategy’-like subroutines and to decide when to deploy them based on rich, human-legible representations of the game state. ... Neural agents struggle in this area, since hierarchical RL is an open problem in the research field, and it is hard for agents to discover ‘strategy’-type patterns of behaviour in environments featuring such a large action space and sparse reward…
Symbolic bots excelled in keeping the full game state in memory, and incorporating external knowledge into their strategies. They found it easy to transfer domain knowledge to the decision-making process. In contrast, neural agents find it harder to maintain information in memory, especially if there is no reward directly associated with it.
- If you can create good rules, traditional AI can work wonders.
Without good domain understanding, you’re wasting time on trad AI. This is a drawback of AI systems since both the domain expert time to give inputs and the developer time to turn those inputs into rules is very expensive. And trying to come up with rules for very complex (or chaotic) systems is a nightmare. This is where ML can come in.
Machine Learning can significantly cut down on the expert time required to develop a system. Domain expert insights can quickly be converted into features, which will then be fed to the model. These features act as guides to the model, telling it what is important without the need for us to explicitly model relationships. The Machine will do this for us.
In this paper, we compare the performance of four different PLMs on three public domain-free datasets and a real-world dataset containing domain-specific words, against a simple SVM linear classifier with TFIDF vectorized text. The experimental results on the four datasets show that using PLMs, even fine-tuned, do not provide significant gain over the linear SVM classifier. Hence, we recommend that for text classification tasks, traditional SVM along with careful feature engineering can pro-vide a cheaper and superior performance than PLMs.
-Source. Just the addition of a few well selected features can add soo much to your performance.
If you have no domain understanding, then Deep Learning becomes a good friend. Vision and Language are perfect examples of this. Coming up with good features for these tasks is a nightmare (and we have heaps of data). So DL can go brrr and solve problems. Another example of this was seen in our investigation- How to take back control of the internet- where LSTMs were able to superior to feature engineering + neural networks in beating signal jamming. With very unstructured/complicated data, DL can do wonders.
In such cases, my opinion is that the team should look to move away from Pure Deep Learning towards more boring methods. These boring methods can add efficiency, stability, and transparency to your system. This might involve building filters to limit the use of the DL model, integrating some features into your decision engine, or investing in saliency visualization to get a better understanding of what your models are considering important.
Note that this doesn’t mean removing what works, but using additional time to understand the system in ways that can then augment the deep learner. One misconception people often make is to assume that Deep Learning is always superior (or its counter-cultural equivalent of “Deep Learning doesn’t work”). The truth is that these techniques often complement each other. Pretty much every system I’ve worked with has used all 3 in different ways. One example can be seen here. All the discussions online claiming one is better than the other are just pointless culture wars. Try not to engage in such meaningless tribalism, and dedicate your time to better things (such as helping me find the best brand of chocolate milk).

Budget
This one will be fairly straightforward, but I’m including it for the sake of completeness. Your budgets will often tell you what kind of solution you want to build. If you have a lot of time and expertise, but lower amounts of computation- trad AI is your best friend. Invert this, and DL is the one you go home with. ML exists in the middle.
Ler’s end of a note about security.
Security
Given my recent articles, this should not come as a shock to you that deep learning and security don’t exactly see eye to eye. Since we use DL in areas where we don’t have much domain knowledge, it’s only natural that we can’t exactly control it. Deep Learning is like that gnarly piece of logic that you and the boys would throw together after many chicken nugget-fueled hours of working together on your assembly project. None of you know how or why it works, and you’re too scared to try reconstructing it from scratch. You throw data at DL, rediscover your faith in God, and pray vigorously that it works.
This also means that it’s for you to prove that your system works or predict how the system will change in the future. And you don’t know what kinds of biases/information it’s picking up without you realizing it. You can invest in better training or transparency protocols, but you can only do so much.
Traditional AI is the opposite in this regard. By its very nature, you have quite a bit of transparency into its working and its safety is theoretically provable. The word theoretically does some Brian Shaw levels of heavy lifting there, but even still you do have a lot of insight into the workings of your trad AI systems. When it comes to security, that’s worth its weight in gold.
Once again, ML lies in the middle. The usage of features (+ feature importance calculations) means that you can have a decent idea of where your model is looking to make its decisions. That’s something, but once again you can’t prove anything. And that’s a wee bit icky. This is one of the causes for my bias towards simple models. Yeeting the computation into data engineering, model evaluation, and pipeline monitoring makes up for the lower transparency of an ML/DL based system.
Hopefully, this article was useful to you. Good judgment and design is more of an art than a science (or maybe I need more experience to fully systematize my thinking), but I’ve found that good frameworks and rules of thumb can be very useful. What do you think of this framework? How would you improve it? I’d love to hear from you.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Can we have a traditional AI that makes the decision of what to use. Since it’s rule based (almost). 😃
Loved the article! Very well written.👏