
A look into RWKV: A more efficient answer to Transformers? [Breakdowns]
How an RNN Style Architecture is challenging the dominance of Transformers in NLP

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights
Market Impact: From my assessment of this architecture, this would be better than Transformers for more generic chatbot/assistant/Q&A implementations, since it can be implemented efficiently. However, I would be careful using RWKV networks as a base when deeper relationships between data-points is crucial. Additionally, the prompt sensitivity would require additional testing and is a disadvantage when we compare RWKV to transformers. Lastly, the inherent multi-linguality, open-source nature, and efficiency of RWKV make it the best LLM for accessibility and bringing AI to more people. Governments and socially oriented businesses should take special note of RWKV. It requires more effort to get going, but I am sure that RWKV will be an extremely important architecture for NLP going forward.
The Open-Source Project RWKV is an “RNN with GPT-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable)”. It tackles a major bottleneck in Transformers: their high costs. The attention mechanism, one of the driving forces behind Transformer supremacy, causes Transformers to “suffer from memory and computational complexity that scales quadratically with sequence length”. This limits their scalability. On the other hand, RNNs, which are efficient for inference, tend to suffer a lot of performance degradation and can’t be parallelized for training. RWKV (Receptance Weighted Key Value) is a new architecture that aims to hit both the performance/scale of Transformers and the efficiency of RNNs.

According to a DM I received from one of their leaders, RWKV is going to release their new model, trained on 7 Trillion Tokens, in about a week. So now would be a good time to discuss the architecture, its pros and cons, and more. If you’re looking for a project to get involved in, would highly recommend looking into these guys (you can join their super fun discord here or check out their Wiki over here for the other links (Github, HuggingFace, etc)). For this breakdown, we will mainly be focusing on their publication, “RWKV: Reinventing RNNs for the Transformer Era”, their Wiki, and my conversations with the team, with occasional citations from other sources.
Comparing RWKV with Transformers head-to-head, we see the following:
The Good:
Lower resource usage (VRAM, CPU, GPU, etc) when running and training.
10x to a 100x lower compute requirements compared to transformers with large context sizes.
Scales to any context length linearly (transformers scales quadratically)
Perform just as well, in terms of answer quality and capability
RWKV models are generally better trained in other languages (e.g. Chinese, Japanese, etc), then most existing OSS models. This stuck out to me, so I spoke to the team about it. Turns out that RWKV has always had very diverse contributors, many of whom came from lower resourced languages. They noticed very early that Open AI’s tokenizations didn’t work as well, so they decided to build their own tokenizers. This is a giant leg up.

No architecture is without its flaws. See if you can put on your detective hats and spot the theme in RWKV’s weaknesses:
Is sensitive to prompt formatting.
Is weaker at task that require lookback, so reorder your prompt accordingly (e.g. Instead of saying “For the document above do X”, which will require a lookback. Say “For the document below do X” instead).
Both of the weaknesses are related to the input structure. My guess here is that Transformers are naturally less sensitive to inputs due to their permutational invariance (transformers don’t consider token order, since they are looks at the relationship between pairs of tokens). On top of this, the ordered nature of RNNs would make them more sensitive to order. Depending on your needs, this might end up being a huge problem. Teams already struggle to implement LLMs securely, and this sensitivity can be another headache. This might push you towards the safer pick in transformers.
On top of this, you have to keep in mind that any RNN will not encode the full depth of relationships that MHA would contain. This would hurt the IR/needle-in-a-haystack abilities.
First, the linear attention of RWKV leads to significant efficiency gains but still, it may also limit the model’s performance on tasks that require recalling minutiae information over very long contexts. This is due to the funneling of information through a single vector representation over many time steps, compared with the full information maintained by the quadratic attention of standard Transformers. In other words, the model’s recurrent architecture inherently limits its ability to “look back” at previous tokens, as opposed to traditional self-attention mechanisms. While learned time decay helps prevent the loss of information, it is mechanistically limited compared to full self-attention.
On the other hand, if you can do a lot of input preprocessing/verification -which is 101 for good design, but many teams overlook it b/c of a lack of competence, knowledge, and a rush to push products to market- this drawback might be mitigated. That’s where the efficiency can become a big plus. The OS nature of this model also shields you from the capricious whims of Big Tech companies sneakily switching up system prompts, breaking something crucial in their attempt to pander to certain crowds, or axing support to crucial services (or even moving things around internally) to please shareholders. If control and stability are important to you, then you must consider this as well (keep in mind there are good OS Transformers as well).

Evaluating such tradeoffs is the element of AI Security and Performance that is often completely overlooked in loud discussions on AI Safety, Performance, and the state of the art. Looking at the performance, my experiments comparing RWKV to various Transformers show mostly comparable results. But that was before I had access to the Gemini Pro (I got approved on Wednesday night). I will play around with it and let y’allz know if it matches up to the hype.
All in all, any practitioner of NLP (or general ML) should be familiar with developments like RWKV. Even if they never become completely paradigm-shifting, such developments push our knowledge further and teach us about the limitations of the current status-quo.
For the rest of this article, we will cover the following ideas in more depth:
Why RNNs became the kings of NLP.
How Transformers overthrew RNNs for NLP.
What makes RWKV so good?
A neat tip I learned about RWKV to improve performance on long-context windows.
and more.

RNNs, Transformers, and NLP
To fully appreciate RWKV, let’s take a stroll down memory lane to contextualize it within the broader history of NLP. More advanced readers may skip this section, since I don’t think you’d gain too much from it(unless you’re looking to admire the pretty diagrams).
How RNNs became the Kings of NLP
Recurrent Neural Networks (RNNs) were created to handle temporal data, where the past follows the future. Let’s take a simple example. Imagine the sentence, “Don’t eat my _”. To fill in the _, we need to take context from the previous words in the sentence. Filling out random words wouldn’t do us any good. Unlike Traditional Networks, RNNs take information from Prior Inputs, making them better suited for these tasks. Pay particular attention to this ability to look at words within the context of a sentence, b/c it will come back around in this piece.
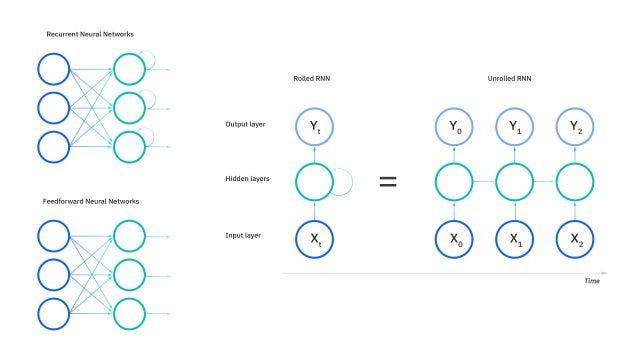
RNNs mimic this by employing a concept called a “hidden state.” This hidden state gets updated as the network processes each word sequentially. In a way, it captures the network’s understanding of the sentence so far.
Here’s a simplified view:
The network receives the first word.
It combines the word with the initial hidden state.
Based on this combination, the network updates the hidden state and generates an output (like predicting the next word in a translation task).
In the next step, the updated hidden state is used along with the second word to create a new hidden state and output.
This sequential processing allows RNNs to handle variable-length sequences and learn long-term dependencies within the data. The recursive nature of the process is also what lends RNNs their names.
So far, so good. But where do issues start cropping up? RNNs typically face challenges with long sequences. The information from the beginning of a sequence could fade away as the network processes later elements. This is known as the vanishing gradient problem. Additionally, RNNs are inherently sequential, limiting their processing speed. That is where Transformers become our messiahs.
Let’s do that next.
Why Transformers Took Over
Somewhere in the mid-2010s, a shadowy cabal of AI researchers decided that they needed more free time on their hands. They couldn’t just ask their bosses, so they created an ingenious scheme- start training larger and larger AI Models. This way, they had a handy excuse anytime they got caught slacking. This caught on, and the rest is history.

The limitations of RNNs meant that there was a major limitation on how much you reasonably scale them up. Vaswani decided that he could not let this limit his vacation days, so he and his crew published “Attention is all you need”. The transformer architecture they introduced came with several scaling benefits:
Parallelization: Faster training and computation.
Long-Range Dependencies: Better handling of complex relationships within sequences.
Interpretability: Attention mechanisms offer some insight into how the model makes decisions.
The cornerstone to enabling this lies in the self-attention mechanism. Here, each element in the sequence attends to (focuses on) other elements to understand their relationships. This enables Transformers to capture long-range dependencies more effectively than RNNs. Fluff words in the middle stop being as much of an issue, when your model looks at all the words at once.

Also, since Transformers analyze all words in a sentence at once we can parallelize their training process. All of these combine to give us more params, larger datasets, and wayy more vacation days.
Unfortunately, all things have their limits. The self-attention mechanism creates a massive computational overhead, owing to its high complexity. With increasing competition, a strong interest in deploying AI Models into edge systems, and no ROI for deployments: it has become clear that “the throw money and GG” strat is not as OP as we thought.
In earlier years, people were improving significantly on the past year’s state of the art or best performance. This year across the majority of the benchmarks, we saw minimal progress to the point we decided not to include some in the report. For example, the best image classification system on ImageNet in 2021 had an accuracy rate of 91%; 2022 saw only a 0.1 percentage point improvement.
Enter the RWKV model. By implementing some very clever modifications, it gets very close to the “best of both worlds”: the efficient inference of RNNs with the scale of a transformer. Let’s talk about how that becomes possible.

How RWKV Modernizes the RNNs
RWKV splits the full RNN network into multiple smaller layers, “where each layer’s hidden state can be used independently to compute the next token hidden state for the same layer. This allows for the next token states to be computed partially in parallel, while awaiting the complete calculation of the first hidden state, in a cascading-like pattern…Effectively, this allows the RNN network to operate like a transformer network when rolled out side by side, where it can be trained “like a transformer” and “executed like an RNN” (the best of both worlds).”

Before we look into the architectural innovations, it would be good to understand the 4 letters that make up the RWKV name-
“R: The Receptance vector acts as the receiver of past information.
W : The Weight signifies the positional weight decay vector, a trainable parameter within the model.
K: The Key vector performs a role analogous to K in traditional attention mechanisms.
V : The Value vector functions similarly to V in conventional attention processes.”
The architecture looks like this-


Here is what I think is important:
Token Shifting: Instead of just considering the current input and hidden state, we also factor in the last input. More information is retained that way, and is a good mitigation of the loss of context that we experience when we compress long sentences into one hidden state with traditional RNNs.
Channel mixing: Acts kinda like a feed-forward layer in Transformers. It takes a weighted sum of the previous and current value and applies the following non-linearity to it:

Time mixing is a similar (but more complicated) process. It enables longer-term memory by accounting for both the previous state and learned weights to determine how to combine previous computations and new computations. In the equation below, the yellow highlights give you a weighted sum of all the previous values while the part in red tells you how much to consider the current value.

The time mixing is a very powerful idea, b/c has an interesting advantage over Transformers: unlike Transformers, which have fixed windows, this theoretically can be extended to infinity. Also, notice that none of the time-mixing equations are non-linear (the non-linearity is added after the block). This means that we can parallelize this computation, enabling a much larger scale.
Recurrent networks commonly utilize the output at state t as input at state t+1. This usage is also observed in the autoregressive decoding inference of language models, where each token must be computed before being passed to the next step. RWKV takes advantage of this RNN-like structure, known as time-sequential mode. In this context, RWKV can be conveniently formulated recursively for decoding during inference…
-This is a good observation that allows RWKV to act as a bridge of sorts
One interesting thing that stood out to me was the following quote, “These design elements not only enhance the training dynamics of deep neural networks but also facilitate the stacking of multiple layers, leading to superior performance over conventional RNN models by capturing complex patterns across different levels of abstraction”. This sounds very convolutional. Don’t have anything profound to add here, but I found it worth noting.
All of this results in an RNN that can hold its own against Transformers on various tasks.

Closing: Prompt Engineering for RWKV, limitations of the setup, and Scale is all you need
RWKV’s innovative ‘linear-attention’/mixing, just like the self-attention mechanism it seeks to replace, is a double-edged sword. One on hand, it doesn’t use pairwise relationships like transformers, which makes it far more efficient. However, this also means that the relationships it does build between the tokens is not as rich, leading to issues with look back and retrieving information. With Google’s Gemini allegedly coming in Hot, this might end up as a major drawback (although apparently telling the model to explicitly memorize the chunks improves performance).
RWKV’s sensitivity to Prompts and its lack of permutation invariance (which IMO is a pretty significant advantage of Transformers) also highlight problems that have plagued LLMs and significantly limit their ROI: their fragility and how little we understand about them. In these dimensions, RWKV might be arguably worse.
That being said, we’re also seeing more confirmation for the trend that our cult noticed a while back: the exact architecture/details end up mattering a lot less than data. The creators of Eagle, an LLM based on RWKV, had the following observation:
A notable observation was that our checkpoints near the 300 Billion token point, show similar performance to pythia-6.9b
This is consistent with previous pile-based experiments on our RWKV-v4 architecture, that linear transformers like RWKV scale similarly in performance levels to transformers, with the same token count training.
If so, it does repeat the question. If the exact architecture, matter less than the data for the model eval performance?
-Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages (RWKV-v5)
The cost-effectiveness and multi-linguality of RWKV would make it uniquely suited to scale up to more kinds of data and information, opening up and access that we would not have considered before.
All in all, it might require more work/massaging, but I see RWKV being a huge contribution to LLMs and would recommend that y’all keep your eyes on it/play around with it.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
This could work for enterprise solutions in companies if the prompt and order of data would not change much for operations. Suppose the language model is orchestrating something in the middle.
Tokenisation part is interesting. The choice of tokenisation can make or break a model especially for languages other than English.
Permutation invariance is the biggest drawback though.
Looking forward to what they come up with.😃