


Dear Sam Altman- There was never an era of making models bigger [Thoughts]
LLMs have never been revolutionary or as game-changing as gurus online would have pushed you to believe

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Recently, the internet caught fire with a particular admission from Sam Altman- The Era of Large Language Models is over. According to this report by Wired-
But the company’s CEO, Sam Altman, says further progress will not come from making models bigger. “I think we’re at the end of the era where it’s going to be these, like, giant, giant models,” he told an audience at an event held at MIT late last week. “We’ll make them better in other ways.”
Article- OpenAI’s CEO Says the Age of Giant AI Models Is Already Over
This has caused a notable stir in the online space. We have seen a notable increase in the number of AI Experts (specifically GPT Experts) since November 2022. These GPT/LLM warriors have been promising AGI and 100x productivity-based AI based on how adding trillions of parameters and more data might be coming to an end sooner than people realize. Looks like Alex Hormozi can live a peaceful existence now-
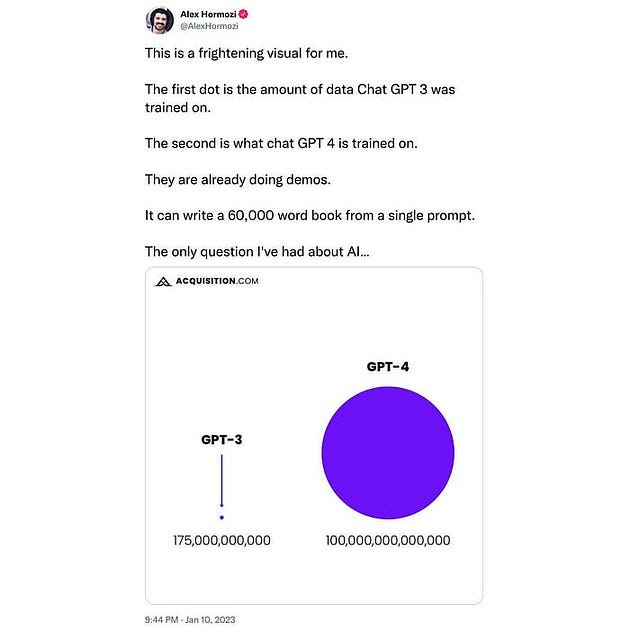
In this article, I’m here to argue something that would be considered blasphemy to many people in the AI Space- the age of mindlessly scaling models has never been here. When we look at the data and actually compare the results- it has always been clear that throwing more and more data and increasing parameter size was always doomed to fail- long before we started hitting the scaling limits that GPT-4 is starting to hit. By understanding how we could have foreseen this problem, we can avoid making these mistakes in the future- saving everyone a lot of time, money, and attention.
OpenAI, the AI research company behind popular language models like ChatGPT and Dall-E 2, has reportedly doubled its losses to $540 million in 2022 due to soaring development expenses for its chatbot. The company is now looking to raise as much as $100 billion in the coming years to fund its goal of developing artificial general intelligence (AGI), an AI advanced enough to improve its own capabilities.
-Source. The hype around these models is causing a major bubble. Make sure you don’t get caught up
Sound like a good time? Let’s get right into it.

Saturation of Benchmarks
One of the most important cornerstones of the hype behind AI was the performance increases that LLMs hit with multiple benchmarks. Every week, we found that GPT/a new Language Model was able to match/beat SOTA performance on a new benchmark or task. Who can forget the hype that we hit when we learned that GPT can pass the Bar Exam and even act as a doctor?
This led to a lot of speculation on AGI and how these models were developing so-called emergent abilities. However, peering behind the hood tells you a very different story.
In earlier years, people were improving significantly on the past year’s state of the art or best performance. This year across the majority of the benchmarks, we saw minimal progress to the point we decided not to include some in the report. For example, the best image classification system on ImageNet in 2021 had an accuracy rate of 91%; 2022 saw only a 0.1 percentage point improvement.
People involved in deep learning for a while will know an uncomfortable truth- AI performance has been increasingly saturated for a few years, way before we had investors and social media influencers blindly pushing the hype behind large language models. Machine Learning Researchers have burned more and more computation for increasingly smaller gains (sometimes under a percentage point).
AI continued to post state-of-the-art results, but year-over-year improvement on many benchmarks continues to be marginal. Moreover, the speed at which benchmark saturation is being reached is increasing.
Seen from this perspective, you should be less excited about these so-called amazing architectures. When it comes to performance- sure they can hit benchmarks- but at what cost? Deploying these models at any kind of scale would have you running out of computing budgets quicker than Haaland breaking goal-scoring records. Don’t forget, the scale that makes these models powerful also makes them extremely expensive to deploy in contexts where you have to make a lot of inferences ( Amazon Web Services estimates that “In deep learning applications, inference accounts for up to 90% of total operational costs”.).
According to researchers who wrote, Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model[3], it took roughly 50.5 tons of CO2 equivalent to train the large-language model BLOOM. GPT-3 released over 500 tons of CO2 equivalent.
- Once you’re done with article, check out my article on the ethics of Copilot
However, that is far from the only issue that made GenAI far less promising than the internet would have led you to believe. Let’s now cover something that would come as a surprise to a lot of people who have graduated from ChatGPT University.
Performance
Here’s something that would surprise you if you only read about GPT from online influencers telling you how to get ahead of 99% of people- these models are just not very good. When it comes to practically implementing Large Language Models into systems that are useful, efficient, and safe- these structures fall apart.
When it comes to business use cases, these models are often lose to very simple models. The authors of “A Comparison of SVM against Pre-trained Language Models (PLMs) for Text Classification Tasks” compared the performance of LLMs with a puny SVM for text classification in various specialized business contexts. They fine-tuned and used the following models-

These models were stacked against an SVM and some old-fashioned feature engineering. The results are in the following table-

This extends beyond just text classification. Fast AI has an exceptional write-up investigating Github Copilot. One of their stand-out insights was- “According to OpenAI’s paper, Codex only gives the correct answer 29% of the time. And, as we’ve seen, the code it writes is generally poorly refactored and fails to take full advantage of existing solutions (even when they’re in Python’s standard library).” Just to drill home how overrated these models can be for coding, here are some of the problems with these models that the amazing Luca Rossi explored in his insightful AI & The Future of Coding 🤖. In it, he attempted to create the following with in Node-
Write a Telegram bot that answers my questions like ChatGPT, using OpenAI API
-a relatively simple task, for any competen t developer
The code generated in Node didn’t work. Below is Luca’s analysis of the situation- It turns out, the AI used methods that do not exist in the Node library, probably inspired by the Python ones.

Below is Luca’s experience with Debugging-
I replaced them and things worked fine. Two considerations:
Debugging the code required me to study the openai and telegraf libraries, undoing 90% of the benefit of using the AI in the first place.
Debugging was surprisingly hard, because these were not the kind of mistakes a normal person makes. When we debug, our brain is wired for looking at things we are more likely to get wrong. When you debug AI code, instead, literally anything can be wrong (maybe over time we will figure out the most common AI mistakes), which makes the work harder. In this case, AI completely made a method up — which is not something people usually do.
Along with this, Luca has some great insights into how using AI Coders would cause a lot of duplication of work in bug fixing and system design, would destroy innovation, use outdated methods, and a few other concerns. Would highly recommend checking out his work here-

Let’s beyond ChatGPT and onto the allegedly early signs of AGI that were discovered in Microsoft’s 155 Page report- Sparks of Artificial General Intelligence: Early experiments with GPT-4. In it, we GPT-4 failing at some relatively simple tasks when it comes to a very simple task-

We see GPT-4 adding new information to the note, even though the prompt explicitly states- using exclusively the information above (and keep in mind this is Microsoft’s hype piece on GPT-4, so we don’t see the real disasters). Show this to the people that want to use GPT for doctors. If these systems are implemented recklessly, people will suffer. Regular readers know that I prefer not making sensational statements, but this is not me click-baiting you about AI’s existential threat. This is me telling you about a very real issue with these systems. If you’d like to read more about my investigation into GPT-4 and understand how the writers of the GPT-4 report ignored very real problems with their claims of AGI- read Observations on Microsoft’s Experiments with GPT-4.
Data-Centric AI
Prior to this ‘bombshell’ admission and GenAI capturing the attention of everyone, there was another trendy buzzword that was moving through the Data Field- ‘Data-Centric AI’. The premise was relatively- we had spent a lot of time building better models and not enough time on improving our data transformation processes. Take a look at this quote from Andrew Ng at an event by MIT-
AI systems need both code and data, and “all that progress in algorithms means it’s actually time to spend more time on the data,” Ng said at the recent EmTech Digital conference hosted by MIT Technology Review.
Once you’re done being wowed by the big names in the statement, tell me what part of that is truly surprising. It’s been well-known that data processing and curation is the most important part of the pipeline since the beginning. The reason that we saw this giant emphasis on models in research was two-fold-
We have big benchmarks/datasets (ImageNet for eg) for many of the standard tasks. In this case, the problem was in the architectures themselves. By standardizing datasets, we could test the effectiveness of various changes to the training pipelines.
Streetlight Effect- The streetlight effect, or the drunkard’s search principle, is a type of observational bias that occurs when people only search for something where it is easiest to look. Combining this with the confirmation bias we see the mess of mindless scaling model size without attention given to other factors- people simply funding/copying whatever is already being done (in our case tweaking architectures). If all you see is working focused on changing architectures, then people will likely create work along a similar vein.
But the unsustainable nature of simply scaling up architectures has been well known to anyone who even remotely understands the field. Once you step outside the bubble of ML Academia and Big Tech AI- you will see that organizations lack the expertise/budgets/inclination to invest into implementing large models because the ROIs are not worth it.
We additionally do not utilize GPUs for inference in production. At our scale, outfitting each machine with one or more top-class GPUs would be prohibitively expensive, … that our models are relatively small compared to state-of-the-art models in other areas of deep learning (such as computer vision or natural language processing), we consider our approach much more economical.
-This is from a writeup by the engineers at Zemanta, a leading advertising firm. Even at their level, SOTA DL isn’t really worth it. To learn more read- How to handle 300 million predictions per second over here
This is why we have seen the move away from bigger models and obscenely big data sets and instead focus on more intelligent design. Intelligent design was explicitly mentioned as one of the reasons Open Source was beating big companies like Google and Open in the infamous ‘Google has no Moat’ document-
Open-Source companies are doing things in weeks with $100 and 13B params that we struggle with at $10M and 540B.
Closing
Combining this together, here is a question I want to ask you- when exactly did we have an era of scaling up? At what point was it ever a good idea to implement more and more scaling- as opposed to focusing on better data selection, using ensembles/mixture of experts to reduce errors, or constraining the system to handle certain kinds of problems to avoid errors? People have been calling this unsustainable for a long time, way before general-purpose LLMs were a mainstay in ML.
Rather than an insightful statement about the future of AI, Sam Altman’s statement is a face-saving maneuver. As is becoming clear- the market is becoming increasingly saturated and OpenAI has no clear direction for making money. Even if they did corner the market, they can’t raise prices because customers can always switch to open-source models (and this assumes that the OpenAI models are meaningfully better- which is debatable). The bubble is bursting, the chickens have come home to roost, and this statement is Sam Altman is now scrambling to maintain the facade that these problems are under control.
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here.
To help me understand you fill out this survey (anonymous)
Small Snippets about Tech, AI and Machine Learning over here
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
When it comes to AI, and humans, there's a quote that always comes back to my mind, from Judea Pearl which basically says that faking intelligence is enough (i.e. you don't really need to be). This world is about appearances, half truths, and sometimes fanatics defending totally bogus ideas. You're a breeze of fresh air.
This is like people chasing the hardware specifications of a new smartphone/pc, who are only proud of the number of parameters but without considering what exactly the tools will help improve their productivity.