


This technology will create the next Nvidia
Interconnects and Hardware Orchestration are the most underpriced field in AI

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
“God is dead. God remains dead. And we have killed him. How shall we comfort ourselves, the murderers of all murderers? What was holiest and mightiest of all that the world has yet owned has bled to death under our knives: who will wipe this blood off us? What water is there for us to clean ourselves? What festivals of atonement, what sacred games shall we have to invent? Is not the greatness of this deed too great for us? Must we ourselves not become gods simply to appear worthy of it?”
-Friedrich Nietzsche, “Thus Spoke Zarathustra”
For the past decade, AI has been scaled on one idea: more compute = more capability. FLOPS became the metric, GPUs the weapon, and acceleration the only game that mattered. It worked… if your definition of worked involved spending tens of billions in CapEx only to have Dario still scrubbing his knees for government protections against his competitors and promising that ASI (coming in 2 more years, pinky promise) will make everything okay.
Now that we’ve hit the end of the Chinchilla curves, we’re forced to confront that our performance bottleneck has moved. The limiting factor in AI today is no longer arithmetic. It’s something deeper, more primordial.
This report outlines the most important — and most underpriced — shift in modern AI infrastructure today: the rise of interconnects orchestration as the strategic high ground.
Speaking more concretely, here is what we will cover-
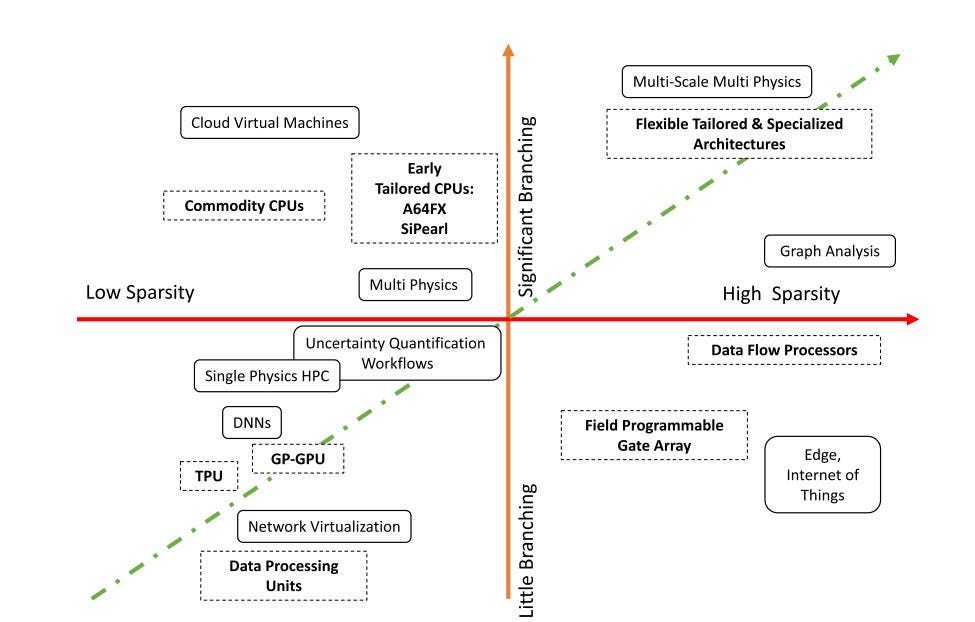
The hidden cost of brute force: The core assumptions that held up GPUs and made them successful so far are also blockers going forward to build “structurally aware AI” that can natively handle more complex structures like Sparsity, Branching, enforced constraints, and more. The answer isn’t better GPUs but other systems that can better handle these “structures”.
The rise of fragmentation: The above leads to heterogeneous compute, multi-stage pipelines, and nonstandard data representations; all will splinter the old stack.
The birth of the orchestration layer: To coordinate this splintering, we need more refined interconnects that can coordinate data across multiple kinds of chips and representations. While this may seem lofty, we’re already seeing a power struggle b/w several big players to draw first blood on this emerging stack.
The battle for the stack: We’ll cover NVIDIA’s vertical moat vs the “Open Alliance’s” rebellion, including a review of competitors like Arm and Intel. And why the orchestration OS becomes the next CUDA.
The financial signal: how capex trends in interconnects, scheduling software, and memory disaggregation are already starting to price in the shift.
The geopolitical accelerant: geopolitical concerns about the robustness of GPU supply chains and interest in bringing compute manufacturing locally both create strong upward pressures on the entire ecosystem.
In other words, several players have identified the massive gaps in our current computational paradigm for AI, and have started to move to integrate other solutions to augment them. However, most of the resources have gone towards foundational layers (better chips, representations etc), while the orchestration layer has been largely untouched. Since the former can’t scale bigly w/o the latter, the orchestration layer represents a blue ocean investment.
“Running on our third generation Wafer Scale Engine, OpenAI gpt-oss-120B runs at up to 3,000 tokens/s — the fastest speed achieved by an OpenAI model in production. Reasoning that take minutes on NVIDIA GPUs take a single second on Cerebras Systems.”
—From the CEO of Cerebras Systems. The release of gpt-oss, OpenAIs newest Open Weight LLMs have been accompanied with the (not so) subtle attempts from various hardware for AI players to assert their dominance on this.

Let’s break the new frontier that most of the industry hasn’t noticed yet.
FYI- we’d flagged this phenomenon as a signal yesterday in our premium updates, a few hours before Sama validated this for us. Email devansh@svam.com for access to our premium AI investment research.
Executive Highlights (TL;DR of the Article)
GPUs and raw compute — once the cornerstone of the paradigm — have reached structural limits. Modern AI demands flexible handling of sparsity, irregular memory access, and conditional logic — areas where traditional GPUs fall short. Specialized architectures like Cerebras and Graphcore, with massive on-chip memory, have emerged to bypass data movement entirely.
But this hardware diversity creates a new problem: orchestration.
As AI stacks fragment into specialized chips and heterogeneous workflows, system-level bottlenecks emerge — pipeline fatigue (slow handoffs between tasks) and data-marshalling taxes (translation costs across different hardware architectures).
This fragmentation has ignited a strategic power struggle.
NVIDIA’s vertically integrated, proprietary stack (CUDA + NVLink) currently dominates, but faces a growing rebellion of open standards (CXL, UCIe, oneAPI) backed by AMD, Intel, Arm, and major cloud providers. This shift is already reflected in market signals:
AI orchestration software market growing at 38% annually.
Interconnect hardware spend nearly doubling by 2030.
Industrial policy (U.S. & E.U. CHIPS Acts) funding open standards, aiming to reduce strategic reliance on NVIDIA.
The new control point is clear: the orchestration OS layer. Whoever builds the “operating system” for intelligent coordination across fragmented AI hardware will control developer experience and define economic structure for the next decade
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 1. The Limits of the GPU-Centric Monoculture
FYI- We broke this down in excruciating detail here. Check it for more details.
The SIMT design — Single Instruction, Many Threads — was perfect for the early deep learning era: dense tensors, regular math, predictable memory access. Multiply, accumulate, repeat. And if you want more, add more GPUs.

It worked beautifully — until we asked AI to do something intelligent.
Below, we break down three critical bottlenecks in the GPU-centric paradigm. None are about raw compute. All are about structure — how AI workloads actually behave when the math gets messy.
1.1. The Memory Wall: Starved at the Buffet
Here’s the dirty secret. Your multi-thousand-dollar GPU spends most of its time sitting idle, waiting for data.
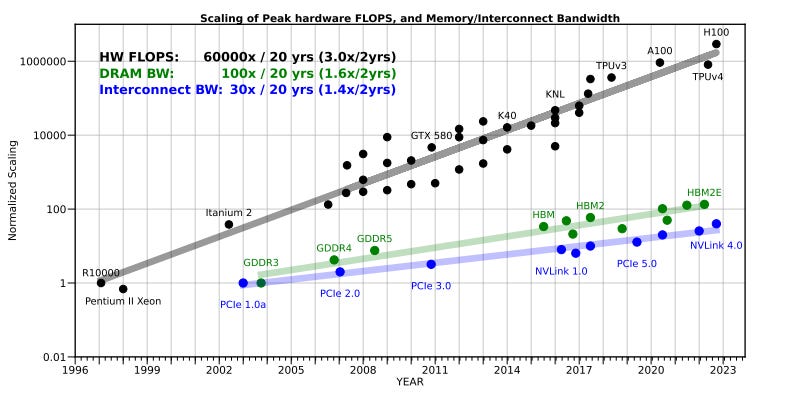
The math is simple. For years, compute power (FLOPS) has been compounding at 3x every two years. The memory bandwidth needed to feed it has grown at half that rate. The gap means that you’re (*checks notes for the right terms*) royally fucked.
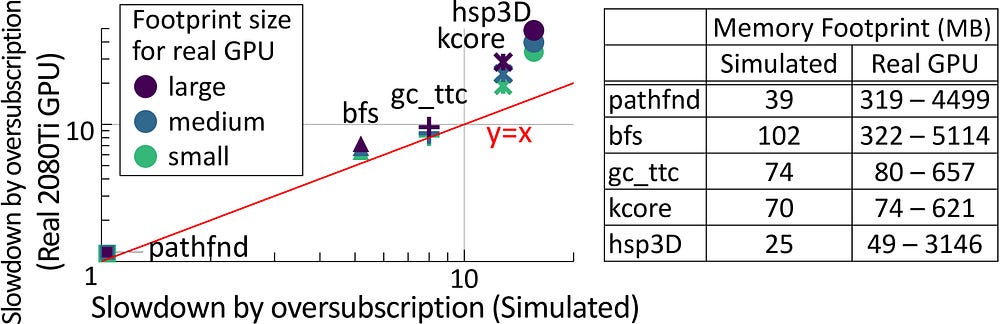
The moment your model’s data spills over the tiny pool of super-fast on-chip memory, the system punishes you. Hard. “When data size exceeds GPU memory capacity, the data must be migrated repeatedly between the CPU and GPU, either manually or automatically. However, manual migration can be laborious for programmers, and it is infeasible for irregular workloads because the data access pattern is unpredictable. On the other hand, demand paging approaches (e.g., NVIDIA Unified Memory [120]) can automatically manage data movement, but it can significantly degrade performance due to high page fault-handling latency and limited PCIe BW [46, 121, 52]. This overhead can be particularly severe for irregular workloads since prefetch/eviction policies become ineffective [14]. For example, the runtime of bfs can increase by ∼4.5× with only 125% oversubscription (i.e., exceeding memory capacity by 25%) compared to when the GPU is not oversubscribed.”
The “compute bottleneck” is largely an oversimplification used to avoid confronting this data starvation problem. I guess even the folk building the (Holy) Ghost in the Shell rely on the all too human tendency of ignoring their actual problems in favor of made-up ones to make themselves feel better.
1.2. The Curse of Sparsity: Don’t bring a Grocery Run to a Scavenger Hunt
A GPU is a drill sergeant. It’s brilliant at making thousands of threads march in perfect, predictable lockstep.
Real-world data isn’t a parade ground. It’s a bar fight. It’s an irregularly structured mess where the important bits are scattered all over the place. We don’t know how to get to them; data flow depends on conditionals that we don’t know until runtime; and the flow is too irregular for us to model preemptively. This is the world of true sparsity. While AI Sparsity (lots of zeroes in networks) is hard enough for our systems, it is this system that brings the true terror.
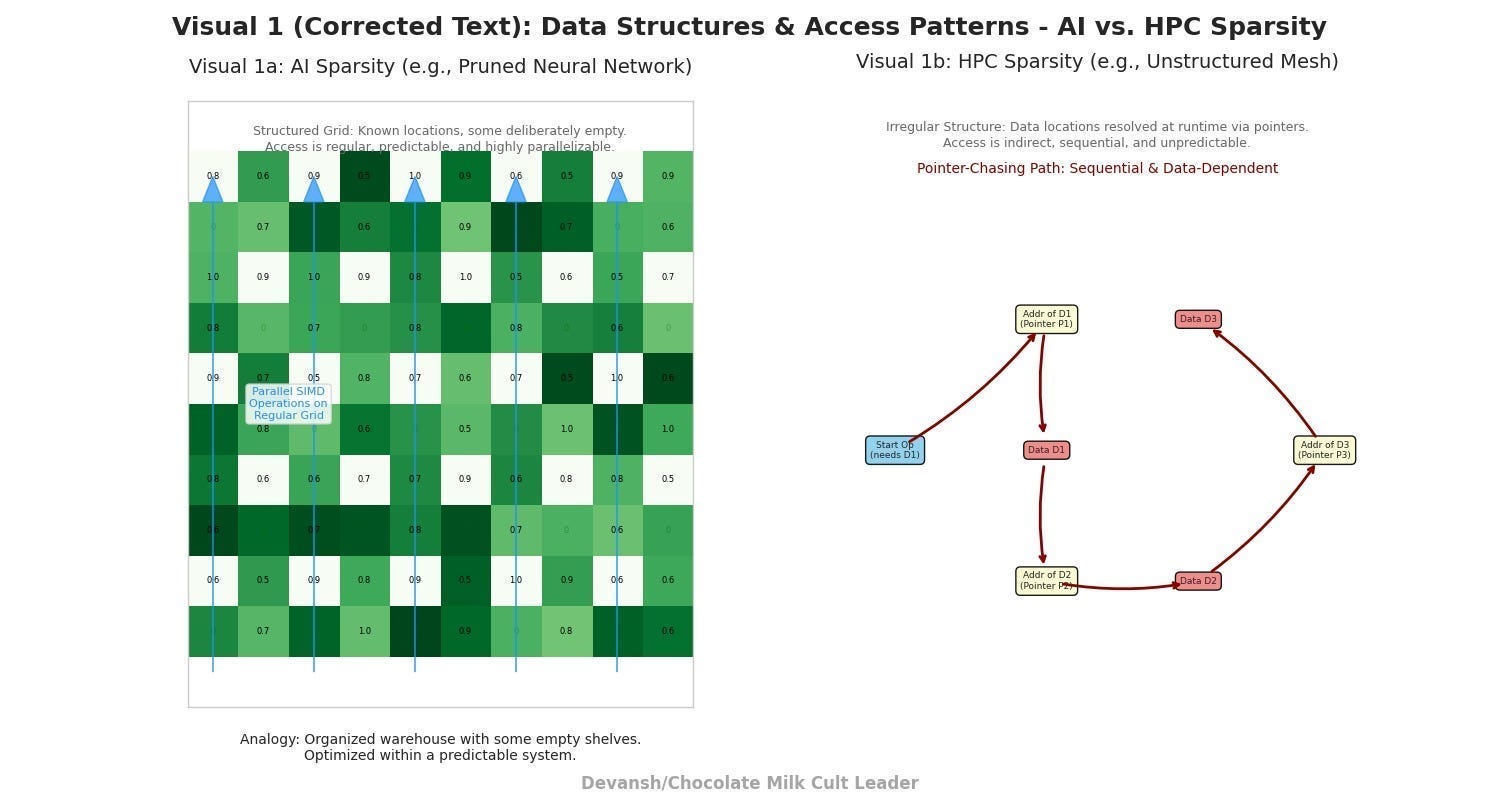
GPUs are built for neat, sequential grocery runs. Sparsity forces them into messy scavenger hunts, chasing pointers from one random memory address to the next. Here, the caches are useless. As Sparsity and branching kick in, the performance gap between GPUs and CPUs starts to vanish-
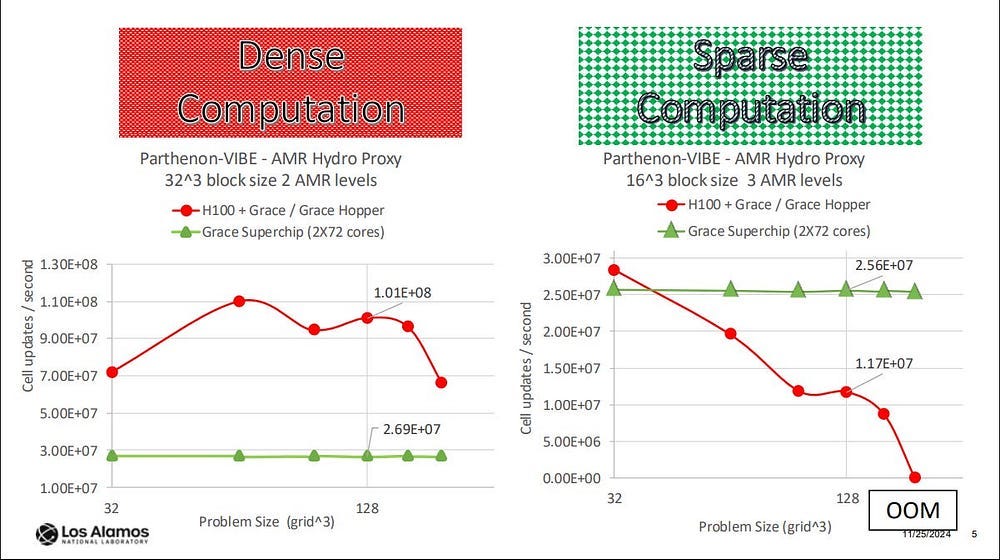
In some cases, the performance collapses completely — for certain kinds of high-memory sparse compute tasks, GPUs collapse while CPUs eventually get something-
1.3. The Penalty of Divergence: A Tax on Thinking
The GPU’s core rule is simple: everyone in a “warp” of 32 threads does the same thing. No exceptions.
But what is intelligence, if not making choices? An if-then-else statement is the most basic building block of logic. On a GPU, it’s a performance disaster.
When threads in a warp need to follow different paths, the GPU doesn’t handle it gracefully. It just runs them one after the other. Half the threads take a nap while the first path executes. Then they wake up, and the other half goes to sleep. A simple choice instantly cuts your efficiency in half. This is called branch divergence. And it’s why reinforcement learning, agentic systems, and dynamic tool use all quietly underperform on GPU clusters. The “thinking” stalls your entire system.

Even with software tricks (thread remapping, predication, speculative execution), real-world speedups max out around 12–16%. And that’s with hand-optimized kernels. For many modern workloads, you’re better off rewriting your model than waiting for your warp.
This creates a powerful incentive to avoid clever, logic-driven algorithms and instead flatten everything into dumb, brute-force matrix math or rely on simplifications like pre-compiled graphs. The more we build for this ecosystem, the more we get locked in. This was a huge reason that people kept scaling despite expecting the diminishing returns. It was only after the performance saturation became undeniable did the labs start making big switches away from the paradigm.
All of this sets the stage. As you’ve seen so far, the GPU monoculture has limitations that we can’t brute force our way through. Solving them requires a rebuild. And that is what leads us to our new age.
Section 2: The Hardware Cambrian Explosion
What do we do when GPUs can’t fix these specific, but important problems?
We go to tech that does. You’re welcome. I’ll send in my invoice soon.
So we get a Cambrian explosion of new architectures, each built to attack the specific weaknesses the GPU couldn’t solve: memory, sparsity, and divergence. From wafer-scale behemoths to chips that compute with light, the data center is being re-architected from the silicon up.
Here’s the twist: this hardware diversity, the very solution to the old problem, creates a new, more formidable bottleneck.
In an almost poetic reflection of our broader society, extreme niche-ization leads to a breakdown in communication …
2.1. On-Chip Memory as the Moat: Cerebras and Graphcore
Some companies didn’t try to fix the memory wall. They are a bit more… original.
Instead of building faster compute to chase data across bus lines, companies like Cerebras (yes same guys from earlier) and Graphcore, shoved all the memory on-chip — the fastest memory possible — and scattered the compute cores throughout it. The result? No traffic. No trips. No waiting. Just compute and data, face to face.
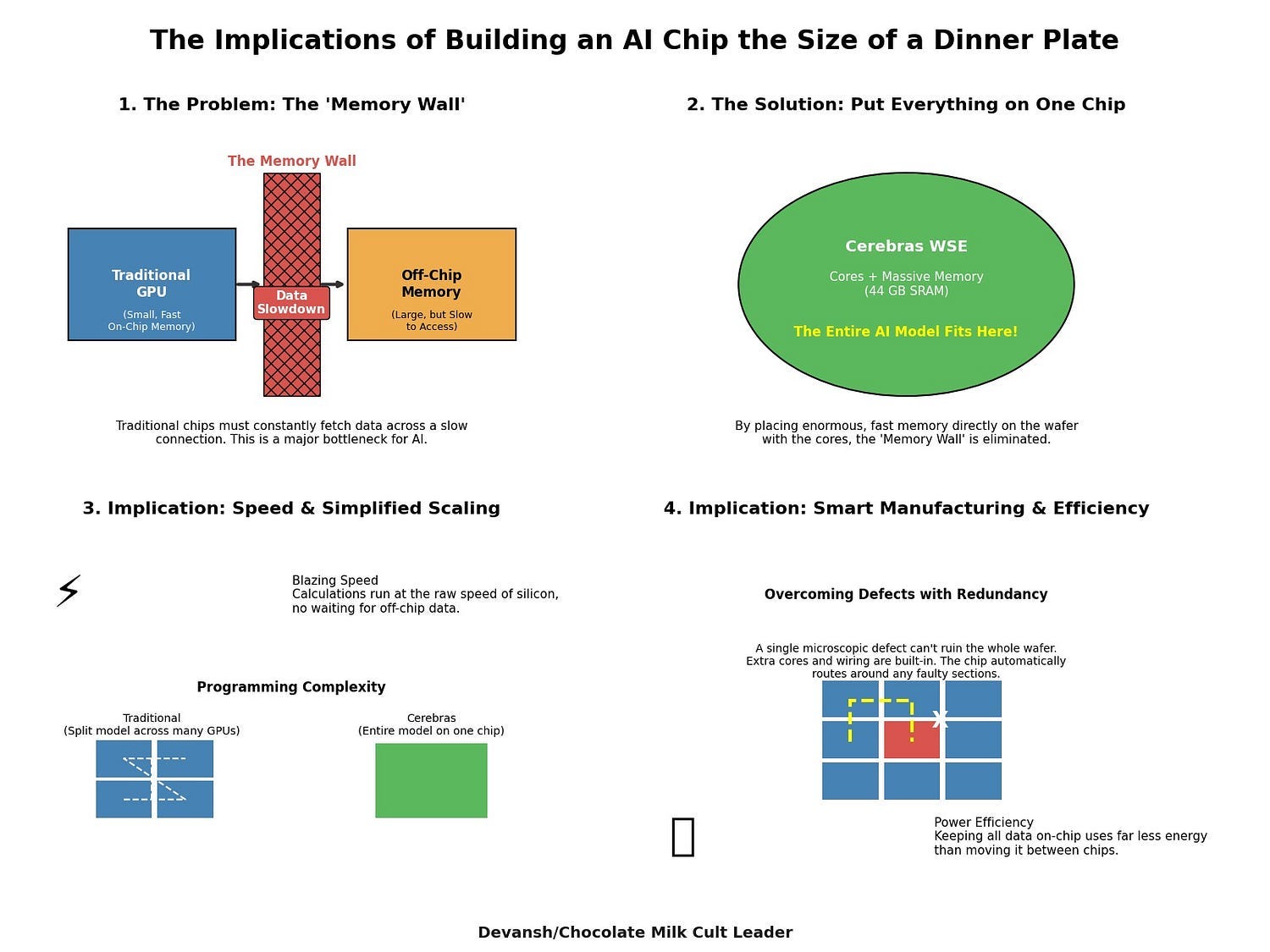
Cerebras took this to its logical — and slightly unhinged — conclusion with its Wafer-Scale Engine (WSE). They don’t cut wafers into chips.
The wafer is the chip. This gets them 44GB of SRAM, letting them handle a 70B param model on a single chip. This setup is allegedly 57x better than the H200 by Nvidia.
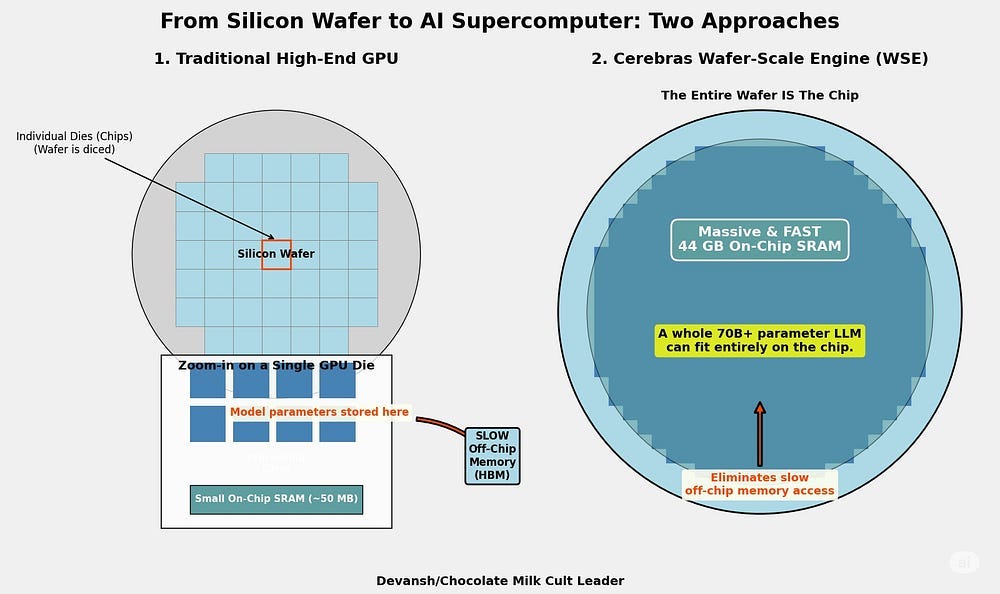
Meanwhile, Graphcore’s IPU pursues the same religion, just less Yuno Gasai-esque. High SRAM, distributed cores, and no patience for data movement overhead.
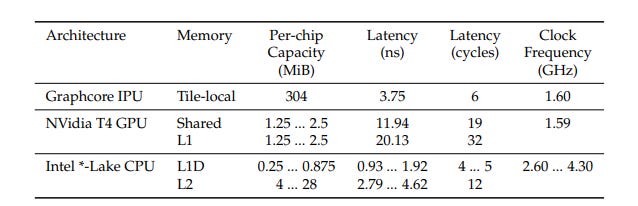
What both bets share is this core belief: You don’t need more compute. You need less distance.
“Cerebras’ wafer-scale engine (WSE) technology merges multiple dies on a single wafer. It addresses the challenges of memory bandwidth, latency, and scalability, making it suitable for artificial intelligence. This work evaluates the WSE-3 architecture and compares it with leading GPU-based AI accelerators, notably Nvidia’s H100 and B200. The work highlights the advantages of WSE-3 in performance per watt and memory scalability and provides insights into the challenges in manufacturing, thermal management, and reliability. The results suggest that wafer-scale integration can surpass conventional architectures in several metrics, though work is required to address cost-effectiveness and long-term viability.”
— From, “A Comparison of the Cerebras Wafer-Scale Integration Technology with Nvidia GPU-based Systems for Artificial Intelligence”. WSE is still early stages and many promising ideas have been Yamcha’d when deployed at scale.
2.2. The Interconnect as the System: Fabrics for a Disaggregated World
State-of-the-art models are too big for any single chip anyway. Training them is now a distributed systems problem. This means the network isn’t just a component anymore. The network is the computer.
This has ignited a war to build the nervous system of the AI data center.
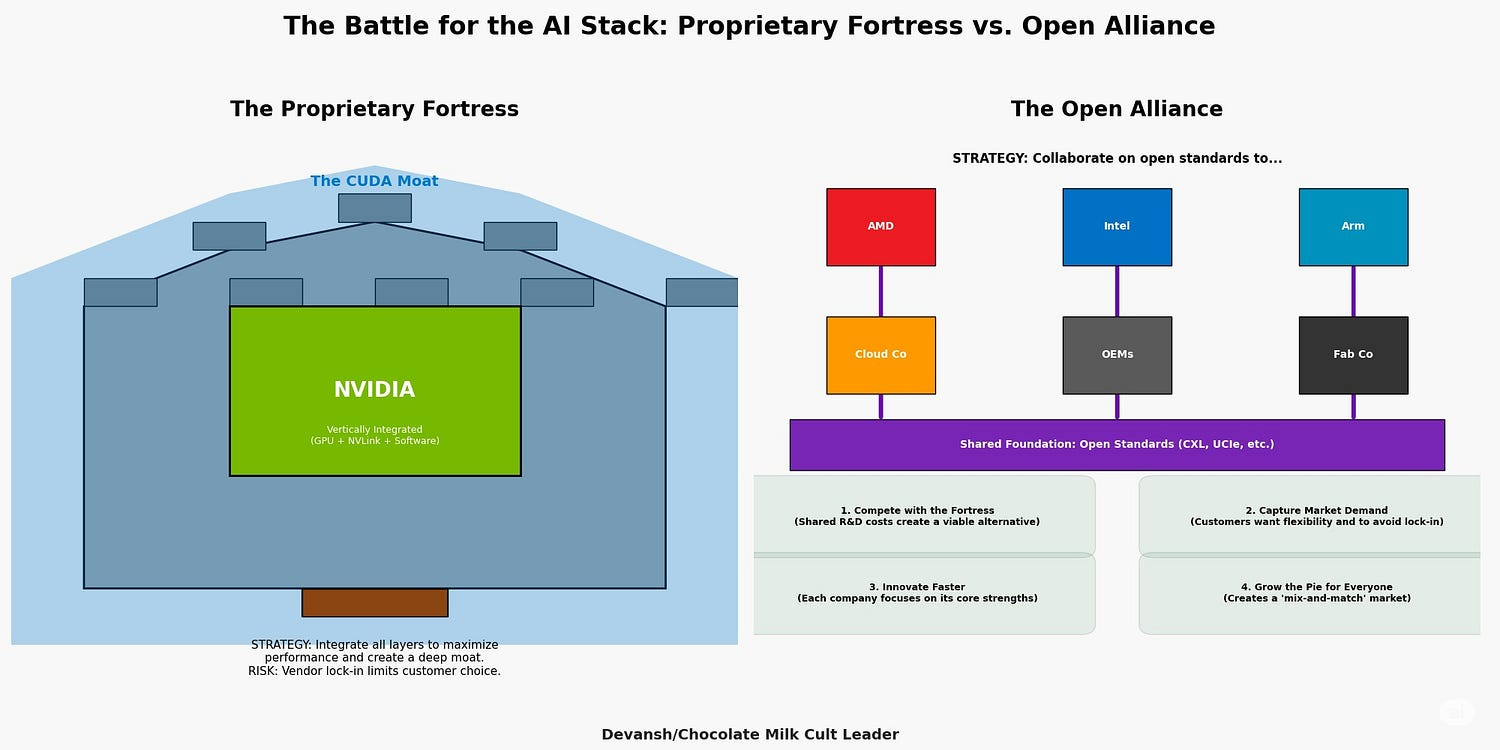
On one side, you have NVIDIA’s proprietary fortress. NVLink is their high-speed, GPU-to-GPU private highway, bypassing the slow public roads of PCIe. It’s the foundation of their moat, a beautiful, high-performance prison that locks you into their ecosystem and lets them retain their insane operating margins.
On the other side, you have the rebellion: a loose alliance rallying around open standards.
CXL (Compute Express Link): This is the big one. It lets you create shared pools of memory that any processor can access. It’s the end of “stranded memory” and the beginning of a truly disaggregated data center.
UCIe (Universal Chiplet Interconnect Express): This is the “plug-and-play” standard for chiplets. It lets you build a system-on-a-package using best-of-breed components from different vendors, like LEGO bricks for silicon.
And then you have the potential leapfrog: photonics. Companies like Lightmatter are building interconnects that use light instead of electricity. They promise to increase bandwidth by orders of magnitude, effectively turning an entire rack of processors into a single, cohesive supercomputer.

The strategic battle is clear. NVIDIA wants the interconnect to be an extension of its software. The Open Alliance wants to turn it into a commodity utility, like plumbing to open up market segments for themselves. Whoever wins this fight defines the hardware API for the next decade.
2.3. The Heterogeneous Imperative: The Right Tool for the Right Job
Building on all of these, we see that the one-size-fits-all GPU cluster is dying. It’s too inefficient, too expensive. No single architecture is optimal for every part of an AI pipeline.
This gives rise to the heterogeneous imperative. The future is a system composed of a diverse mix of specialists: CPUs for serial control logic, GPUs for parallel grunt work, and custom ASICs (like Google’s TPU) for their own jam.
Major players are all-in on this. Arm’s “Total Compute” and Intel’s “oneAPI” are explicit strategies to build and manage these mixed-signal systems.
And here we are. The solution to the compute bottleneck creates the orchestration bottleneck.
Homogeneous GPU clusters were hard enough, but at least they were predictable. Now? Every task has multiple potential landing zones. Every component speaks a different memory format. Every data packet needs to be translated, serialized, and routed.
The overhead becomes a tax. Every attempt to go faster — by splitting work across more chips, more formats, more domains — creates friction.
This moves your bottleneck from compute to orchestration. Progress (I think??)!!!
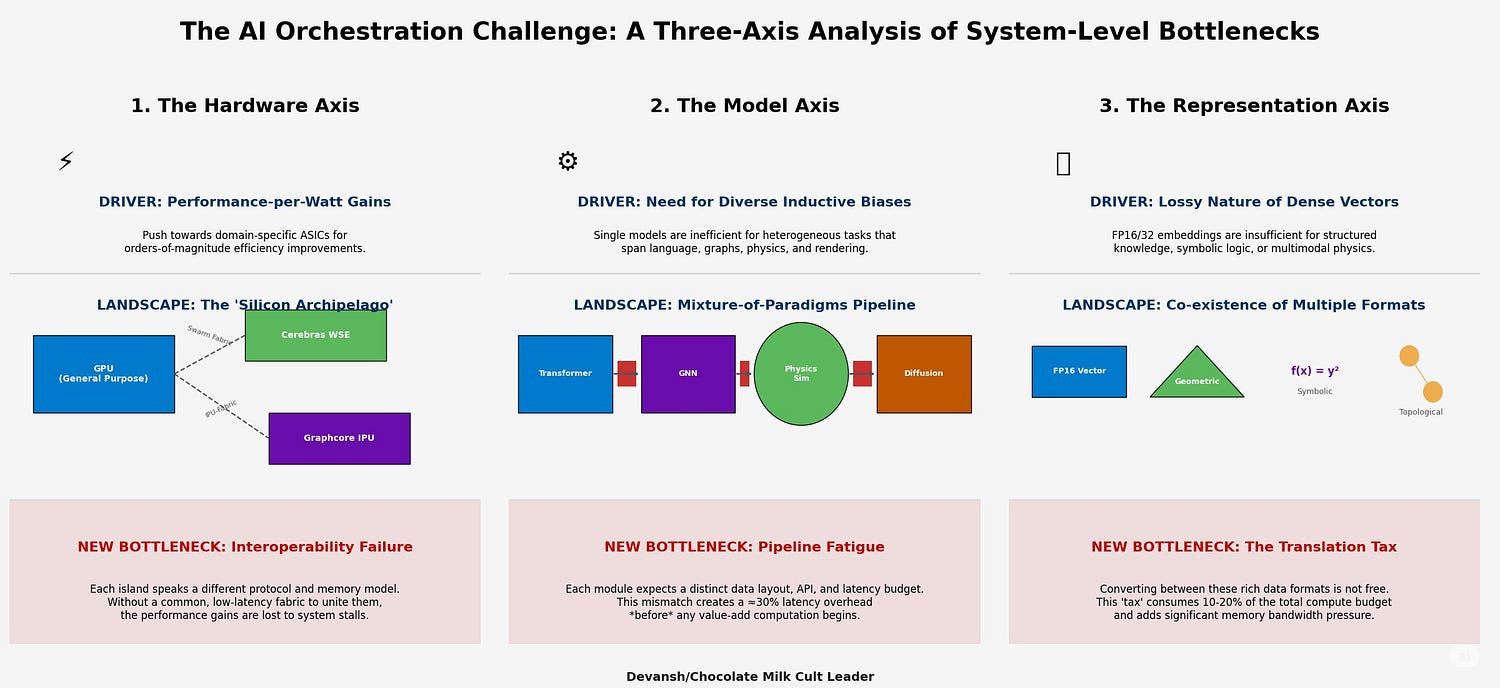
Section 3. The New Frontier of Failure: System-Level Bottlenecks
The game is no longer about optimizing a single CUDA kernel. The new frontier of failure lies in the seams. In the handoffs between chips, in the invisible glue in multi-model pipelines, in the vacuum between the chips. As AI systems become more distributed and heterogeneous, they’re running headfirst into a different kind of limit.
Artifacts of a fractured world where every improvement creates a new coordination cost.
3.1. Pipeline Fatigue in Multi-Stage AI
The most valuable AI systems today are long, interdependent chains. Retrieval-Augmented Generation, agentic reasoning, and tool use — each is a pipeline with multiple specialized stages. A user query might start on a CPU, touch a vector database, format intermediate data, then move to a GPU for inference, possibly hitting another module for post-processing.
This creates a new kind of bottleneck: pipeline fatigue.
Your fastest chip doesn’t matter. What matters is the sum of all latencies, plus the cost of context switching between stages. Accelerating one component is irrelevant if the handoff kills you.
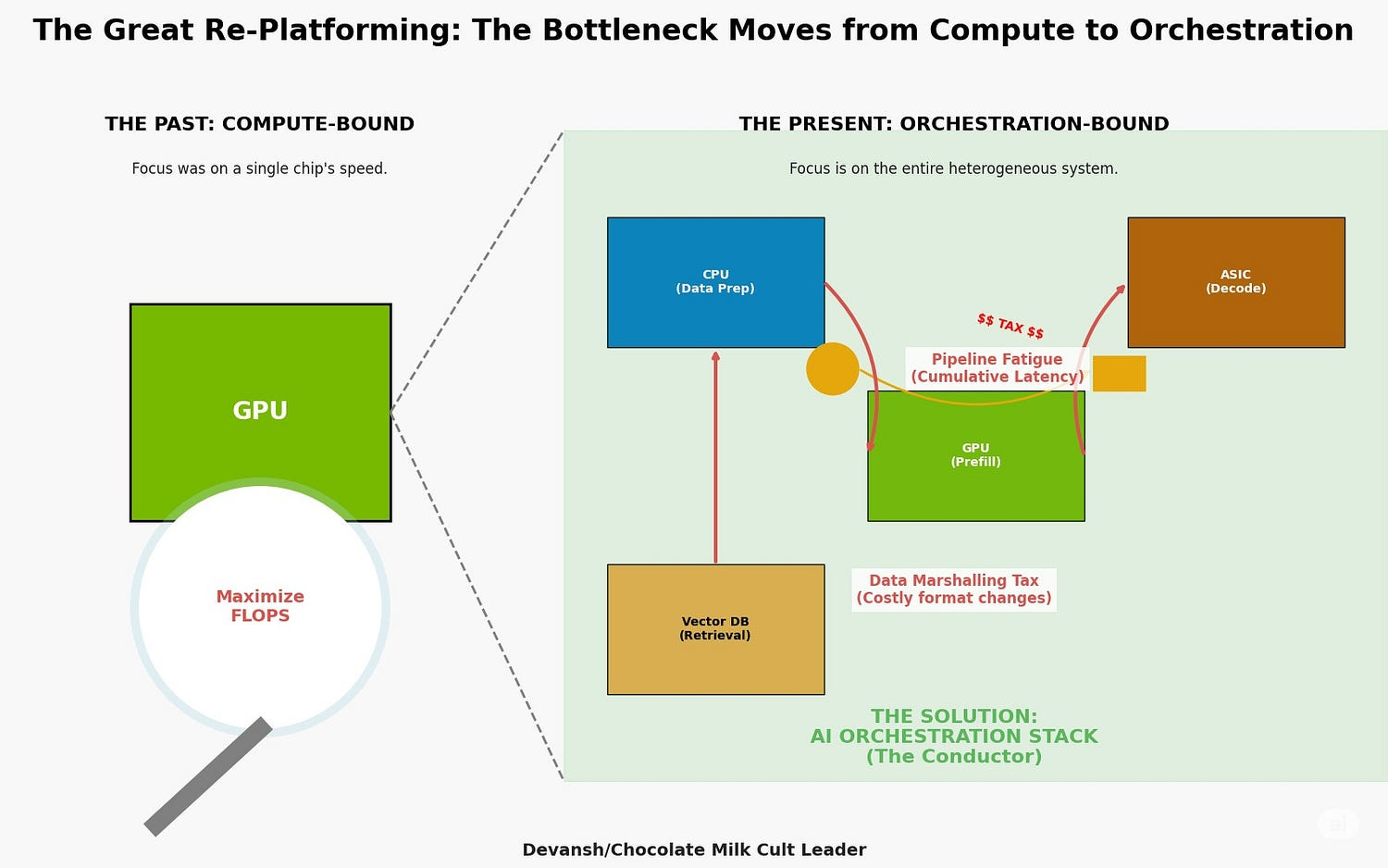
This mirrors the shift from monoliths to microservices in traditional software. The AI industry is now grappling with the classic distributed systems headaches: service discovery, load balancing, and inter-service latency. “Pipeline fatigue” is just the AI-specific name for this old pain,a new skin on an old foe, only now Frieza has become Mecha Frieza since it has to also account for specialized AI-Hardware.
The comms tax, especially b/c different architectures have different languages, is the core driver of the pipeline fatigue. But that’s not the only factor we have to worry about.
3.2. The Data Marshalling Tax: The Hidden Cost of Heterogeneity
Every time data crosses a hardware boundary (b/w GPU-CPU; or any other combination), you pay. You’re serializing structure, translating memory layout, rehydrating formats, and realigning for a new execution model. Structure-of-Arrays, Array-of-Structures — whatever the format, there’s always a mismatch.
And mismatches cost cycles.
They introduce latency.
They inflate your memory footprint.
In high-throughput systems, they break scaling entirely.
This tax doesn’t show up in your model card. But it eats into every inference, every second of training, every pipeline step. The runtime system must serialize the data, translate its layout, and rebuild it on the other side. That translation introduces latency and eats cycles. In some cases, it can double the memory footprint just to hold both versions in flight.
Put two and two together, and it becomes clear why orchestration becomes key. Especially when we account for the rise of novel data structures/AI paradigms: complex-valued neural networks, sheafs, Bayesian inference-based world models, diffusion, evolution-based reasoning etc. There is too much promise in research that rethinks the core (see what I did there?) assumptions of our current paradigm for us not to explore it further:
“By incorporating positional information through complex weights, we enable a single-layer neural network to learn sequence representations. Our experiments show that Comply not only supersedes FlyVec but also performs on par with significantly larger state-of-the-art models. We achieve this without additional parameters. Comply yields sparse contextual representations of sentences that can be interpreted explicitly from the neuron weights.” — Source
Taking that axiomatically, we are forced to confront that all of these techniques and architectures have unique priors and setups, and the performance lies in figuring out ways to coordinate their unique advantages into a cohesive whole.
Section 4. The Rise of the Conductor: AI Orchestration Platforms
The chaos of the new hardware stack creates a vacuum of control. The system-level bottlenecks — pipeline fatigue and the data marshalling tax — are too complex for any single developer to solve from scratch.
Nature abhors a vacuum. And so, a new software layer is rising to fill it: the AI orchestration platform.
These platforms are the conductors for the new AI orchestration. They coordinate the complex interplay between models, data, and a diverse array of hardware instruments. They are, in effect, building a new “operating system” for AI, giving developers high-level APIs to build sophisticated applications without needing a Ph.D. in distributed systems.
Think it over. An OS for the interplay in HPC and Performant AI. You’re being together two wildly valuable streams in Tech, which together can solve some of the greatest problems around. Think about the value unlock —
^^ Credit to the GOAT Mojahed.
4.1. Defining the AI Orchestration Stack
“Orchestration” is a big word. Let’s make it precise. The emerging stack has three distinct layers, each with a clear job.
The Strategic Scheduler (The Brain): Given a high-level goal, it decides what to do next. It decomposes the problem, determines which model or tool to call, manages the workflow’s state, and handles the complex logic of reasoning, reflection, and error recovery. This is where the “thinking” happens.
The Data-Logistics Engine (The Brawn): Handles the “how” and “where” of data. It’s responsible for paying the “data marshalling tax” — handling the serialization, format translation, and data movement between the different parts of the system. It manages caching, data placement, and ensures the right data is in the right format, in the right memory, at the right time.
The Hardware-Abstraction & Compilation Backend (The Last Mile): This is the layer that talks to the metal. It takes a concrete task from the upper layers and translates it into optimized code for the target hardware — be it a GPU (via CUDA), a CPU, or a custom ASIC. It manages the fine-grained details of launching kernels, managing memory on a specific device, and abstracting the ugly implementation details away from the rest of the stack.
I like this framework b/c it gives us a clear picture of who is fighting for what piece of the new value chain. Let’s look at some of the players right now.
4.2. Landscape Analysis: From Open-Source Frameworks to Enterprise Platforms
The market is already populating with players, each tackling different parts of this stack. None of these are good enough for our next generation, but studying their limitations and failures will give us important information for what’s coming next.
Open-Source Agentic Frameworks (Strategic Scheduler Focus):
LangChain: The popular choice for chaining together LLM components. Its extension, LangGraph, is a pure play for the Strategic Scheduler layer, allowing developers to build complex, stateful agentic workflows as graphs.
AutoGen: Microsoft’s framework for orchestrating conversations between multiple, specialized AI agents. It excels at managing the high-level interaction logic, placing it firmly in the Strategic Scheduler layer.
Enterprise AI Orchestration Platforms (Full Stack Focus):
SuperAGI: Positions itself as a platform for automating complex business workflows. It aims to provide a unified platform that handles not just the scheduling of AI tasks but also their integration into enterprise IT systems.
Microsoft Azure AI: A comprehensive, deeply integrated suite that covers all three layers. Azure AI Foundry is the Strategic Scheduler, Azure Machine Learning is the Data-Logistics Engine, and the underlying Azure AI Infrastructure is the abstracted hardware backend.
The dynamic is clear. The raw hardware is becoming a layer of immense but undifferentiated power. It’s too complex to program directly. The orchestration platforms are building a new, simpler, more powerful API on top of it.
History has shown that the company that controls the dominant abstraction layer — the OS in PCs, the cloud API in enterprise IT — captures enormous and durable value. The race to build the most widely adopted AI orchestration platform is a battle to define the primary interface through which the next generation of AI will be built.
5. Market Analysis: Sizing the Next Wave of AI Infrastructure
The issues discussed are creating and reshaping markets worth tens of billions of dollars. The system-level bottlenecks are forcing massive investment in two key areas: the software to manage the complexity and the hardware to solve the data logistics.
5.1 The Multi-Billion Dollar Orchestration and Interconnect Opportunity
The software layer is exploding (see more). The AI orchestration market is projected to grow from $2.8 billion in 2022 to $14.4 billion by 2027, a compound annual growth rate of 38%. Orchestration platforms are stepping in to solve a massive enterprise pain-point- 80% of organizations can’t reliably get models into production.
Meanwhile, the hardware layer is undergoing its own arms race. The Data Center Interconnect (DCI) market is forecast to nearly double — from around $16 billion in 2025 to $33 billion by 2030. This driven by immediate neccesity: Enterprises are buying faster networks because their current ones can’t keep up with the chips they’ve already paid for.
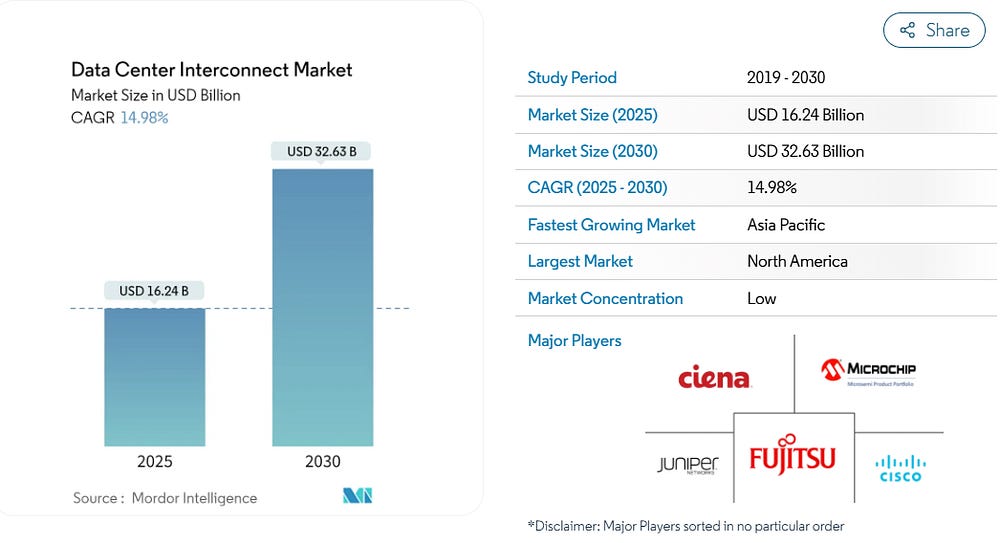
The growth curve in interconnect spend is a direct proxy for system-level dysfunction. The market isn’t confused. It’s signaling, clearly, that the bottleneck has shifted from compute to coordination.
5.2 The Battle for the Stack: Proprietary vs. Open Ecosystems
This brings us to the Dio vs. Joestars version of tech strategy: integrated control vs. modular scale.
NVIDIA’s Fortress: Full vertical integration. Proprietary GPUs, bound together by NVLink, all run through CUDA. It’s seamless. Fast. And completely closed. The performance is real. So is the lock-in.
The Open Alliance: Everyone else. AMD, Intel, Microsoft, Google, Meta. They can’t beat the fortress alone, so they’re aligning around shared standards. UCIe for chiplets. CXL for memory. UEC for high-performance networking. Intel’s oneAPI is the most explicit CUDA alternative in software — an attempt to open the gates at the developer level. Together, they’re hoping to create an alternative ecosystem to drive down their Nvidia reliance, especially as sophisticated inference time scaling jacks up volumes.

The increasing volumes on GenAI make the opening up imperative for survival. And the added complexity of our systems makes the orchestration non-negotiable.
This is a movie we’ve seen many times in the past.
Apple vs Android. IBM mainframe vs x86. Integrated platforms win early. Modular ones win scale. The tradeoff is always the same: short-term performance vs. long-term flexibility. What gets decided here will shape the economic structure of AI for the next decade.
PS- It can be easy to misunderstand this analysis as a bear case for Nvidia. While Nvidia is on the control side, it’s also taken significant steps to move across the ecosystem. Their culture + RnD, increasing Open Source presence, and internal memo to focus on inference are all strong indicators that position them well.
5.3 Financial Health and Strategic Positioning
You can tell a company’s strategy by reading its income statement.
NVIDIA is in a league of its own. Gross margins above 70%. Net profit margins exceeding 50%. And they’re reinvesting this wisely. They’re on a massive building spree. Datasets. Hardware. Software. Compiler layers. Interconnects. Cloud inference. Everything to lock them in.
AMD and Intel are in a different fight. Margins are thinner. Intel’s in the red. They can’t play the same game, so they don’t. Instead of controlling the stack, they’re trying to shape the playing field. That’s why they invest in UCIe, push CXL, and lead standards bodies. Their strategy is leverage by coordination.
Profitability doesn’t just follow strategy. Profits set constraints. Constraints set the boundaries. While Nvidia is the most unconstrained player in the space currently, its customers are quickly becoming powerful competitors. For their sake, it’s key that they never lose sight of their core strengths and avoid pointless distractions. Especially as the competitors consolidate into powerful blocs.
6. What Comes Next: The Post-Moore’s Law AI Data Center
The shift from compute to orchestration marks the beginning of a new, more complex era. As the industry solves for data logistics, a new set of even more fundamental constraints will come into focus.
6.1. Beyond the Bottleneck: A Holistic View
A myopic focus on interconnects is a strategic error. It will just move the bottleneck again. The real constraint is the Total Cost of Ownership (TCO) of the entire system, driven by a nexus of problems that must be solved together.
Power and Thermal Management: The energy consumption of AI is becoming a first-order economic crisis. A single accelerator chip is now pulling over 1,000 watts, forcing a costly transition to liquid cooling. The network, the power grid, and the cooling system are now a single, interconnected problem.
Software Complexity: The hardware Cambrian explosion creates a software crisis. A rack full of specialized chips is just an expensive pile of sand without a new generation of hardware-aware orchestration software to manage it. Today’s cloud platforms, like Kubernetes, are fundamentally unprepared for this world.
A faster network is necessary, but not sufficient. The entire stack, from silicon to software, must be co-designed. The ultimate challenge isn’t maximizing one component; it’s optimizing the TCO of the whole system.
6.2. The Impact of Industrial Policy: The CHIPS Act Catalyst
The game is no longer just about markets and tech. Industrial policy is now a key player.
The US, EU, and other major economies have all identified GPU dependence and the GPU supply chains as major geopolitical vulnerabilities. There are several pushes to bring the manufacturing of chips locally to reduce global dependence, AND to develop more kinds of chips as a form of economic leverage in diplomacy.
In this context, NVIDIA’s proprietary ecosystem looks like a single point of failure. The technologies being funded by the CHIPS Acts — open chiplet ecosystems, cross-vendor design platforms — are all in line with the interests of the “Open Alliance.” The obvious implication here is the explosion of diversity in chips and hardware. However, someone will need to make this chip-zoo get together, clearly demonstrating the need for the orchestration layer.
6.3. Intelligence Was Never About Compute
The orchestration bottleneck reveals something we’ve been avoiding: intelligence was never about raw computational power.
Your brain runs on 20 watts. A GPU cluster burns 20 megawatts. The difference isn’t in the math — it’s in the coordination.
You’re not “smarter” than an ant simply because you have more brain cells. Your neurons have many more specialized structures, which play together to create a richer map of thinking. The difference isn’t in the scale — it’s in the orchestration.
Qwen3 works at 0.6B parameters. Kimi K2 works at 1T. That’s a 1,666x difference. If intelligence needed a specific scale, this shouldn’t be possible. But here we are.
Problems in orchestration mirror the fundamental problems around intelligence and biological emergence. Consequently, tackling them extends into theology, as we try to unravel the face of God that manifests in our creation. In doing so, perhaps we too will develop the divine and solve many of the problems plaguing humanity today.
Isn’t that much more fun than what we’re doing right now?
Let me know if any of these ideas struck a chord. Or what an idiot I am if none of these did. Either way, hearing from you makes my heart skip a beat. Sometimes even two.
Thank you for being here, and I hope you have a wonderful day
Orchestration is my love language
Dev <3
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Superb article. 👏
Probably the wrong framing but I’m getting Cisco in the 90s vibe from the opportunity
Fantastic article. For interconnects, don't we have multiple categories like: on chip, chip to chip, (Astera labs come to mind), servers, across data centers by the same hyperscalar, across hyperscalars.. Aren't there multiple companies playing in that field.
For orchestration, you say kubernetes (i assume Kubeflow) ain't prepared for it, so what is? Are we talking Airflow/ML Flow etc?