
AI's Great Refactoring: A Roadmap to the New AI Infrastructure of Specialized Hardware, Software Control Planes, and Strategic Risk [Market]
The New AI Infrastructure Stack Part 2: How TCO, Specialization, and Governance Are Forging the Next AI Infrastructure Stack

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
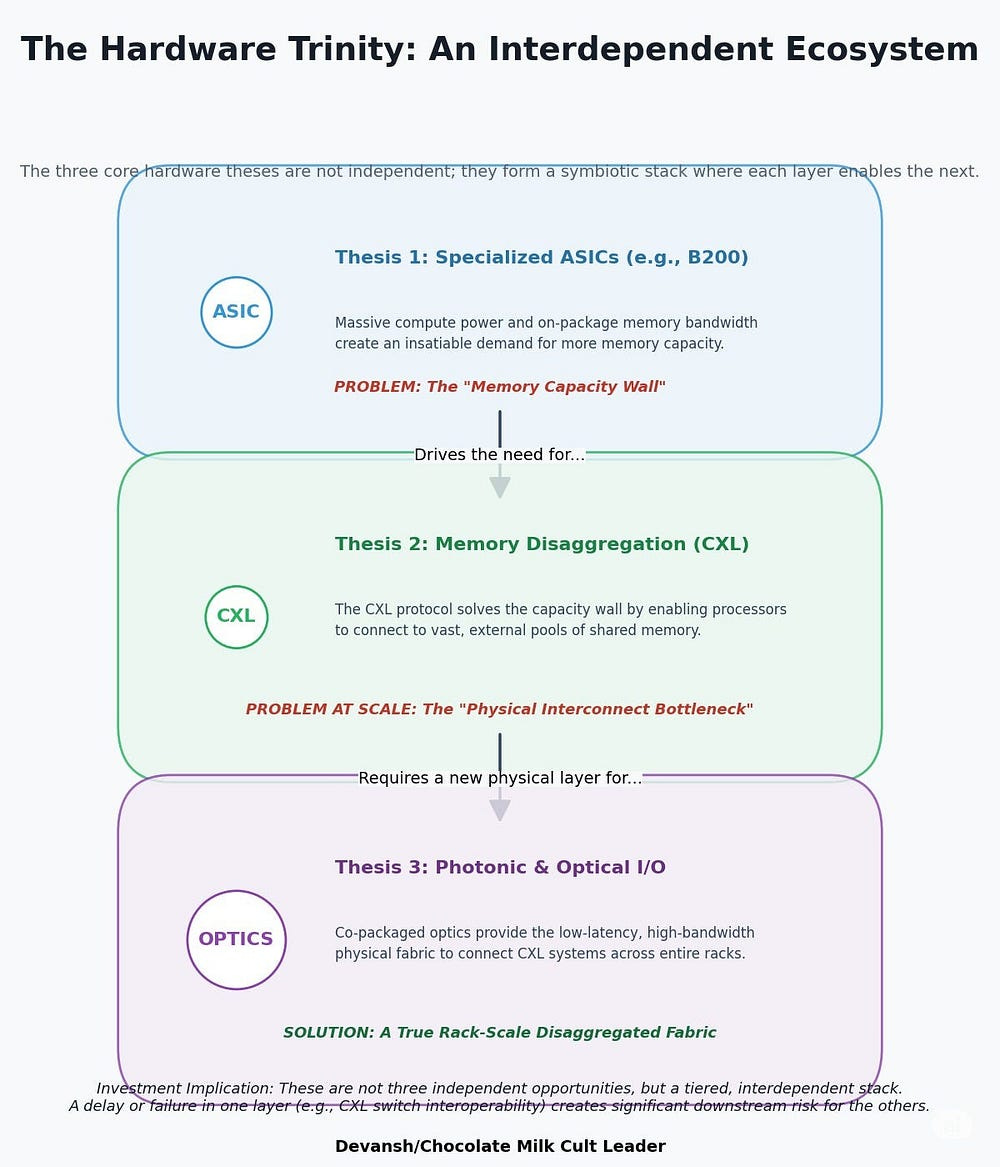
In Part 1 of this series, we mapped the physical revolution. We established that the old AI hardware stack — built on the brute-force economics of general-purpose GPUs — is cracking under its own weight. A new substrate is forming, a chained trinity of specialized ASICs, disaggregated memory, and photonic interconnects, which both flow into each other AND solve some major blockers in current systems — creating a powerful investment angle for deep-tech/infra investors.
But hardware is only the foundation. It is a body without a brain. A powerful, efficient engine is useless without a sophisticated control system to steer it, a supply chain to maintain it, and a legal framework to operate it in.
This is where the second, more complex phase of the revolution begins. The battle for the AI stack is now moving up from the physical layer to the software, operational, and strategic layers. The new choke points are not silicon fabs and power grids, but software orchestration, regulatory compliance, and human talent.
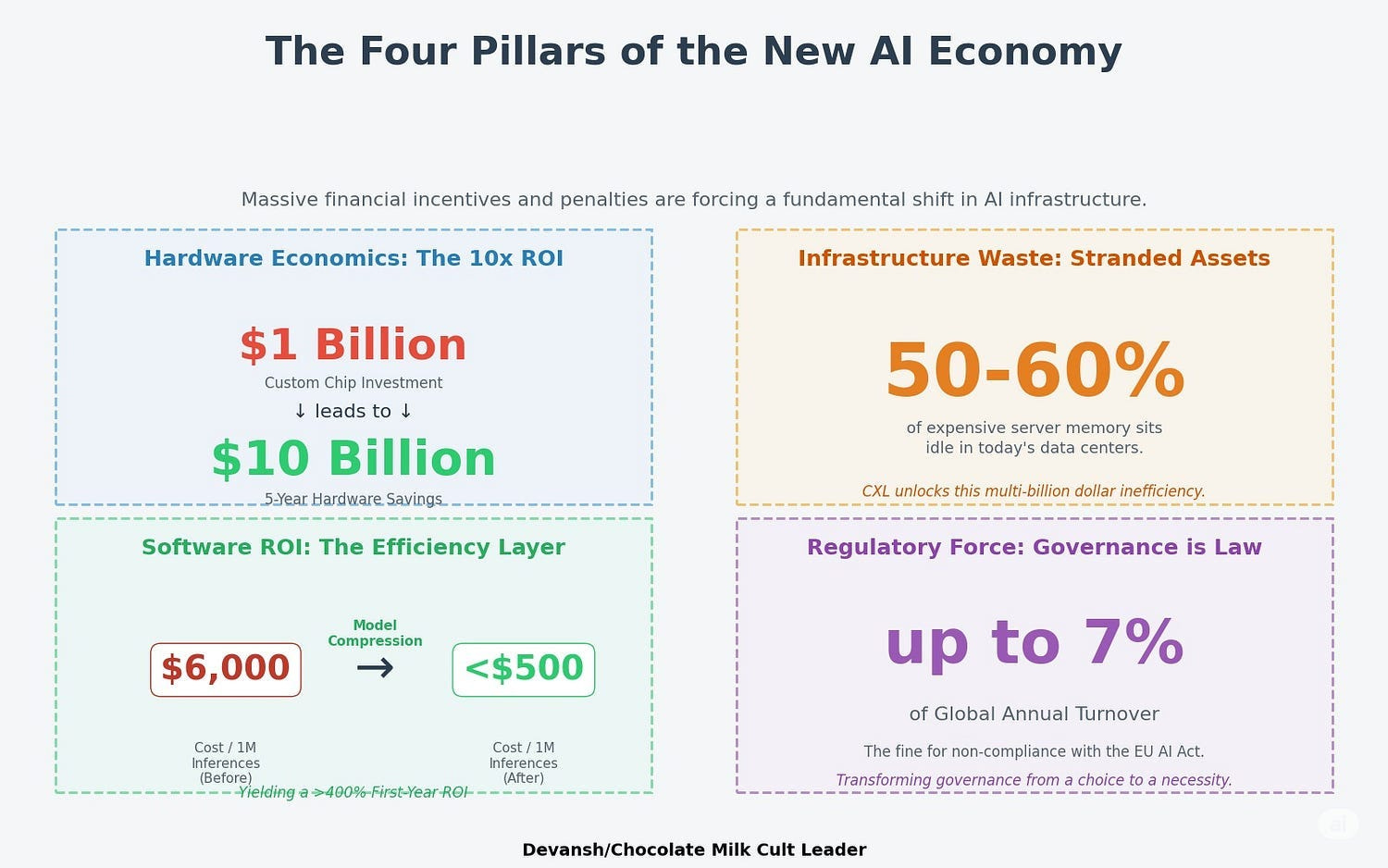
This is not a theoretical problem. The market is already pricing in the stakes:
The Efficiency Mandate: The market for edge AI software — which depends entirely on model compression — is projected to hit $8.91 billion by 2030. This isn’t about performance; it’s about making AI profitable outside the data center.
A largely underappreciated aspect of AI models is that once models stabilize, inference costs can be upto 90% of the total cost of a production model. This stabilization is likely to occur much quicker than people assume b/c even present models have the “intelligence” to handle most workloads when designed intelligently.
The Governance Tax: Non-compliance with regulations like the EU AI Act carries fines of up to €35 million or 7% of global turnover. This transforms governance from a feature into a non-negotiable, multi-billion dollar software market.
The Human Bottleneck: The semiconductor industry faces a projected shortfall of one million skilled workers by 2030. This won’t just slow innovation, it will determine which regions fall permanently behind.
The Security Blind Spot: As AI models become core business assets, 86% of enterprises report needing to upgrade their tech stack to manage the new integration complexity and security risks related to AI and Agentic Deployments. Hallucination isn’t the problem. Bad Design and Infrastructure exposure is.
This article is Part 2 of our analysis. We will deconstruct the software and strategic layers that will run on top of the new hardware substrate. We will analyze the companies building the critical “control plane” for AI, the financial necessity of model compression, and the unseen risks that will define the winners and losers of the next decade.

The hardware has shifted. Now we find out how the software — and the institutions that depend on it — can keep up.
Model size is irrelevant if you can’t compress and finish it for production.
Hardware performance is wasted if you can’t verify, govern, or dynamically route outputs at scale.
Infrastructure capex is lost if your scheduling and control plane treat specialized silicon like generic boxes.
Last decade was about Moore’s lawing tf out of hardware. This decade is about taming everything it unleashes.

Executive Highlights (TL;DR of the Article)
The AI infrastructure stack is undergoing a violent, one-way replatforming. The old model of scaling with general-purpose GPUs is dead, killed by unsustainable Total Cost of Ownership (TCO) and the hard limits of physics. A new stack is emerging, and the strategic control points are shifting.
The Foundation: The Hardware Revolution (Part 1 Recap)
The new physical substrate is a “Chained Revolution” of three interdependent technologies:
Specialized ASICs are replacing general-purpose GPUs to win on efficiency (performance-per-watt), creating a “Great Bifurcation” between a high-margin training market and a low-margin inference street fight.
Disaggregated CXL Memory is the mandatory solution to the “memory wall” created by these powerful new ASICs, allowing memory to be pooled and shared across the rack.
Photonic Interconnects are the physical endgame, providing the only viable fabric to scale CXL across the data center without being crippled by the power and latency limitations of copper.
The Real Battle: The Software & Strategy Stack (Part 2 Theses)
This new hardware is a powerful but inert body. The durable value and control are moving up the stack to the software that can tame it. This battle is being fought on three critical fronts:
The Efficiency Layer (Compression as a Platform Wedge): With inference accounting for up to 90% of a model’s lifetime cost, efficiency is paramount. “Model Finishing” — using compression to create production-ready assets — delivers a >400% ROI and is the key to profitability. This irresistible ROI is not just a feature; it is the strategic wedge for a new class of platforms to hook customers and build a larger, defensible ecosystem around model deployment.
The Governance Layer (The Verifier Economy): Regulatory hammers like the EU AI Act make manual oversight impossible and risk unmanageable. The only scalable solution is the “Verifier Economy”: an ecosystem of small, fast models whose sole job is to police the latent space for risks like toxicity, bias, and copyright infringement before an output is rendered. The platform that owns this Verifier ecosystem doesn’t just sell compliance; it becomes the indispensable “System of Record for AI Risk,” controlling what is allowed to exist.
The Orchestration Layer (The Economic Control Plane): The old guard of hardware-agnostic schedulers (like Kubernetes) is obsolete. The new heterogeneous stack demands a new class of hardware-aware orchestrator that can intelligently route workloads across ASICs, CPUs, and Verifiers. The goal of this new control plane is not just job completion; it is optimizing for margin by making real-time decisions based on hardware state, energy cost, and data locality.
The Strategic Implications & Bottom Line:
This replatforming creates new constraints, from the human talent bottleneck in semiconductor design to the rise of the hardware stack as a national asset in geopolitical competition.
The last decade was a brute-force hardware race. The next is a sophisticated battle for the software control plane. The winning companies will not be those who build the biggest models, but those who build the indispensable platforms that finish, govern, and profitably orchestrate them. Stop chasing the models. The real, durable value is in owning the systems that control them.
Strategic Recommendations: How to Play the New Game
For Venture Capital & Growth Equity:
The New “Picks & Shovels”: The highest-leverage bets are in the new enabling software layers. Look for the “model finishing” platforms with defensible compression technology, the governance platforms with a clear wedge into the C-suite via compliance-as-a-service, and the new hardware-aware orchestrators. These are the new moats.
Avoid the Commoditization Trap: Be wary of investing in pure “model building” or generic inference hosting. The value is not in the generative component itself, but in the software that finishes, governs, and profitably orchestrates it.
For Enterprises & CIOs:
Re-evaluate Your Stack: Your current MLOps and orchestration tools are likely unprepared for the coming wave of heterogeneous hardware and agentic workflows. Begin piloting new governance and scheduling platforms now.
Prioritize a “System of Record”: Do not allow dozens of siloed, ungoverned AI projects to proliferate. Your highest priority should be establishing a centralized governance platform — a single system of record for all AI risk and activity. This is a foundational investment, not a feature.
For Incumbents (NVIDIA, Cloud Providers):
The Race for the Control Plane: The battle for hardware dominance will be matched by a battle for the dominant software control plane. The provider that offers the most intelligent, integrated orchestration and governance stack for its hardware will create the stickiest ecosystem. CUDA’s moat proves that the software that controls the hardware is the ultimate source of power.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Thesis 4: Model Compression as a Key Part of the AI Infrastructure.
A powerful AI model that isn’t profitable is just a very expensive science project.
We established that inference can account for up to 90% of a model’s lifetime cost. This single fact makes model efficiency the most critical battleground for any company that wants to actually make money with AI. The brute-force approach — throwing more hardware at an inefficient model — is a guaranteed way to go broke.
This is why model compression is transitioning from a niche academic pursuit to a non-negotiable step in the production pipeline. It’s not about making models “better”; it’s about making them economically viable. Beyond pure cost-cutting, model compression brings several benefits-
Edge Deployment: AI on-device in smartphones, cars, industrial equipment
Latency-Sensitive Use Cases: Real-time decision loops in finance, healthcare, manufacturing
Private Model Hosting: Compression shrinks infra requirements enough for on-prem or sovereign cloud deployment — critical for compliance and data localization.
Historically, any technology has seen a Cambrian explosion in both adoption and innovation when it’s become more accessible to the masses, even at slightly lower performances (80% cheaper, even if at a 20% loss of performance). The reduction in prices leads to adoption from “outsiders” leading to a massive increase in the TAM and an increase of new potential customers/builders. Compression is vital to making this a reality for Gen AI.
From a different angle, compression is not just about size. It’s about portability, governance, and deployment control.
The $8.91 billion projected market for edge AI software is a direct consequence of this reality.
4.1 The “Model Finishing” Toolbox
A foundational model, fresh out of training, is like a raw engine block. It’s powerful, but it’s also heavy, inefficient, and completely unsuitable for a production vehicle. Model compression is the “finishing” process — the porting, polishing, and tuning that turns that raw power into a street-legal, high-performance asset.

The toolbox for this process contains three primary instruments, each with its own strategic trade-offs:
Quantization (The Weight Reduction): This is the most direct approach. You take the model’s parameters, which are usually stored as high-precision 32-bit floating-point numbers, and you shrink them down to 8-bit or even 4-bit integers. It’s like replacing heavy steel components with lightweight carbon fiber.
The Trade-off: It’s a fast and brutal way to cut model size by 75% or more, but do it carelessly (Post-Training Quantization), and you risk introducing “noise” that degrades accuracy. The more careful approach (Quantization-Aware Training) requires more time and compute upfront but keeps the model’s performance intact. It’s the difference between a rough cut and a precision-milled part.
Pruning (The Strategic Removal): You go into the neural network and systematically remove the parts that are freeloading mooches on society — entire neurons, channels, or connections that contribute little to the final output. No mercy. I’m bullish on the mechanisms like Sparse Weight Activation Training, which prunes networks dynamically, allowing for pruned networks that change their shape dynamically to accommodate new data. “For ResNet-50 on ImageNet SWAT reduces total floating-point operations (FLOPS) during training by 80% resulting in a 3.3× training speedup when run on a simulated sparse learning accelerator representative of emerging platforms while incurring only 1.63% reduction in validation accuracy. Moreover, SWAT reduces memory footprint during the backward pass by 23% to 50% for activations and 50% to 90% for weights.”
The Trade-off: Done right, you get a smaller, faster model that is fundamentally less complex. Done wrong, you cut into muscle instead of fat, crippling the model’s reasoning ability. This requires deep expertise to execute without causing catastrophic damage.
Knowledge Distillation (The Master-Apprentice System): This is the most sophisticated approach. You use a massive, powerful “teacher” model (like a GPT-4 class model) to train a smaller, nimbler “student” model. The student learns not just to replicate the teacher’s answers, but to mimic its internal “thought process.”
The Trade-off: You are essentially transferring intelligence into a more efficient form factor. The result can be a model that is 90% smaller but retains 99% of the original’s capability. The cost is the immense computational expense of the training process itself. You are paying a high upfront tax for long-term operational efficiency.
4.2 Calculating the ROI of Compression
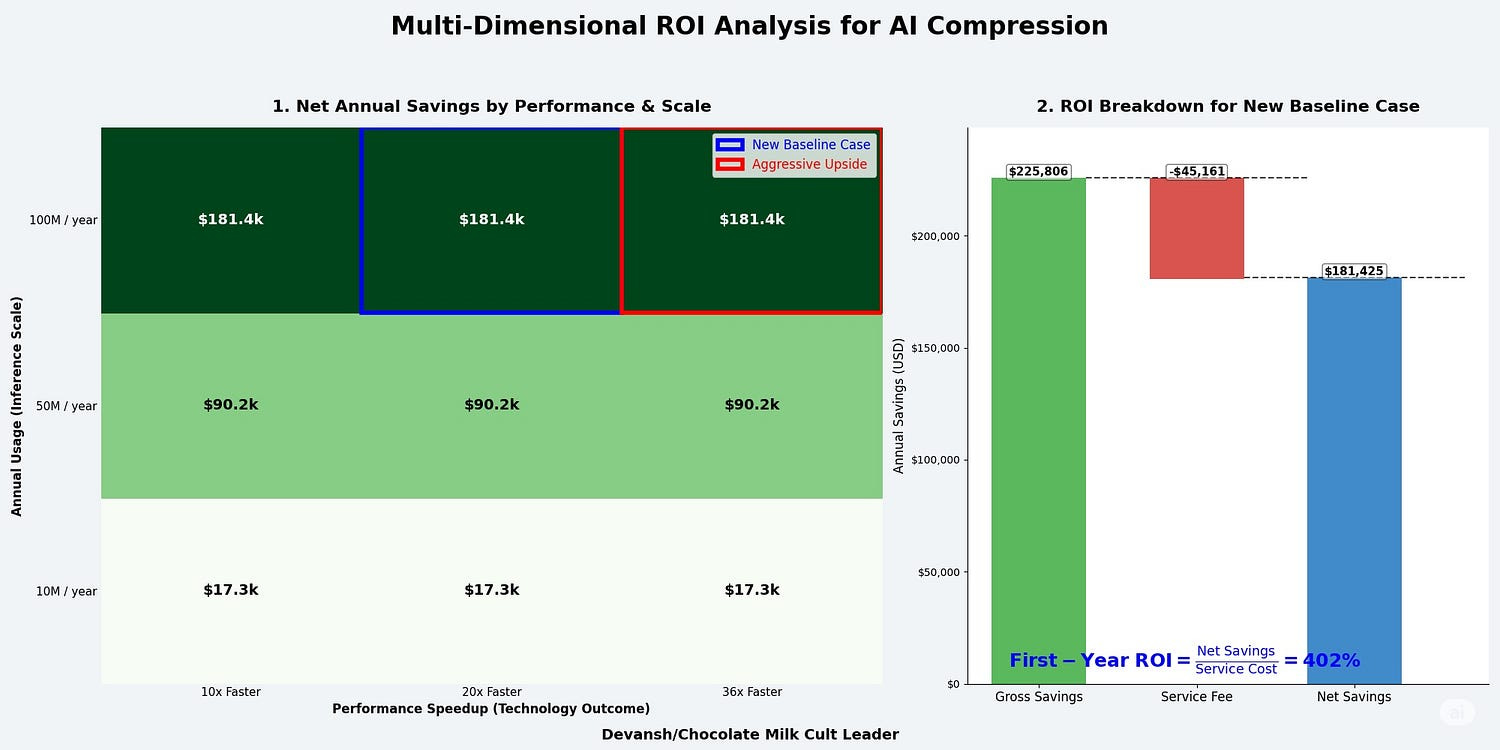
Let’s run this through by taking some pretty realistic numbers for a an enterprise deploying a generative image service w/ 100 million inferences per year.
Model (Before): A 10 GB raw diffusion model (e.g., a large SDXL variant). This model is unoptimized and runs on expensive, general-purpose enterprise hardware.
Model (After): The model is compressed by 80% to 2 GB using techniques like INT8 quantization and pruning. This is an aggressive but achievable target that should preserve high image quality. The optimized model can now run efficiently on modern consumer hardware.

Hardware Shift: From NVIDIA A100 (enterprise GPU) to NVIDIA RTX 4090 (consumer GPU) since our compression allows the use of cheaper hardware.
Cost Before Compression (NVIDIA A100)
Inputs:
Hourly GPU Cost: $4.10
Performance: 0.5 inferences/second
Calculation per 1 Million Inferences: ( $4.10 per hour / (0.5 inferences/sec * 3600 sec/hr) ) * 1,000,000 = $2,280
Annual Cost Calculation: 100 (million inferences) * $2,280 = $228,000
Cost After Compression (NVIDIA RTX 4090)
Inputs:
Hourly GPU Cost: $0.79
Performance: 18 inferences/second
Calculation per 1 Million Inferences: ( $0.79 per hour / (18 inferences/sec * 3600 sec/hr) ) * 1,000,000 = $12.20
Annual Cost Calculation: 100 (million inferences) * $12.20 = $1,220
Return on Investment (ROI) Calculation
Gross Annual Savings: $228,000 (Old Cost) — $1,220 (New Cost) = $226,780
Compression Service Fee (20% of Gross Savings): 0.20 * $226,780 = $45,356
Net Annual Savings: $226,780 (Gross Savings) — $45,356 (Service Fee) = $181,424
First-Year Return on Investment (ROI): ($181,424 Net Savings / $45,356 Service Cost) * 100% = 400%
4.3 Compression as a Platform Opportunity
The real play isn’t just compression as a feature. It’s building finishing platforms that can:
Take in raw open-source models (also works in partnering with Closed model providers)
Optimize them for a target deployment environment (hardware, latency, compliance)
Package them into inference-ready, cost-constrained assets
Think: model compiler meets performance tuning meets governance shim.
We’re early in this curve, but the long-term structure is clear: Just like Nvidia wraps CUDA around its silicon, someone will wrap a “Finishing Layer” around open-source models — creating the platform that transforms generic weights into production-grade systems. This has very easy vertical integration into observability, safety, and other aspects of deployments, which will allow compression plays to morph into ML deployment plays long-term (the multi-objective training that compression platforms have to crack to succeed carries over very well).
This is a key driver that’s misunderstood by many people studying the space. The compression market isn’t shrinking models. In the long run, it’s expanding margin. The cost savings from compression is an easier wedge to hook platforms into the ecosystem, similar to how free cloud credits and certifications are used by hyperscalers to embed more people into their cloud ecosystems.
PS- If compression is a bit too techy to invest into, you should look at companies like ATTAP, which will explode once we crack compressed models + tool use.
Thesis 5: The Governance Layer — Policing the Latent Space
Hardware gave us scale. Compression gave us cost control. But governance is what gives us permission to operate. It is the unavoidable tax that every enterprise pays to do big-boy bijiness.
The risks have evolved beyond simple model drift. We now face active, malicious threats: prompt injection attacks that hijack model behavior, model-layer malware that creates hidden backdoors, and the latent legal time bomb of copyright laundering, where a model regurgitates training data and exposes its user to infringement claims.
This threat landscape, supercharged by regulatory hammers like the EU AI Act and its 7% of global turnover fines, has created an urgent need for a new class of enterprise software. The market for GenAI MLOps and governance is projected to exceed $8 billion by 2030, driven not by a desire for better dashboards, but by existential risk and legal necessity.
The scale of the problem — reviewing millions of daily outputs — makes manual oversight impossible. The only viable solution is automated, real-time governance. And the most efficient and powerful place to conduct that governance is not in the final output, but one layer deeper: in the latent space.
5.1 The Strategic Advantage of Latent Space Verification
(look at our appendix for detailed analysis on viability and benefits)
Most governance tooling is still trying to sanitize output after it’s rendered. That’s like trying to inspect a weapon after it’s been fired. It’s too late, too expensive, and fundamentally reactive. It’s also boring. As professional, degenerate gamblers, we must never forget our ethos of trying to predict the future, not simply be a part of it.

The real move is to police the latent space — the compressed, high-dimensional representation where models “think” before they speak. This is where semantic meaning lives. Where style, intent, and dangerous ambiguity first emerge.

Why operate here?
It’s cheaper. A 64×64 latent tensor is 48x smaller than a full-resolution image. That reduction makes real-time governance financially viable. Without it, you’re just burning compute to inspect problems you could’ve blocked earlier.
It’s smarter. Concepts like “violence,” “political extremism,” or “off-brand tone” are messy in output space. In latent space, they show up as mathematical fingerprints — detectable, steerable, stoppable. Operating in the latent space is one of the core ways that Iqidis (our Legal AI startup) has been able to significantly outperform the older generation of Legal AI platforms like Harvey AI, Legora, or VLex, which was recently acquired for 1 billion USD.
Trying to govern the output is like waiting for a leak to flood the room. Latent space lets you turn off the tap.
This hinges on a very specific element of the AI Model layer, one that’s almost an afterthought in most Gen AI teams today.

5.2 The Verifier Economy: An Army of Latent Space Sentinels
This leads to the core technical thesis: the rise of the Verifier Economy, an ecosystem of small, fast, and cheap AI models whose only job is to police the latent space representations of large, expensive generative models.
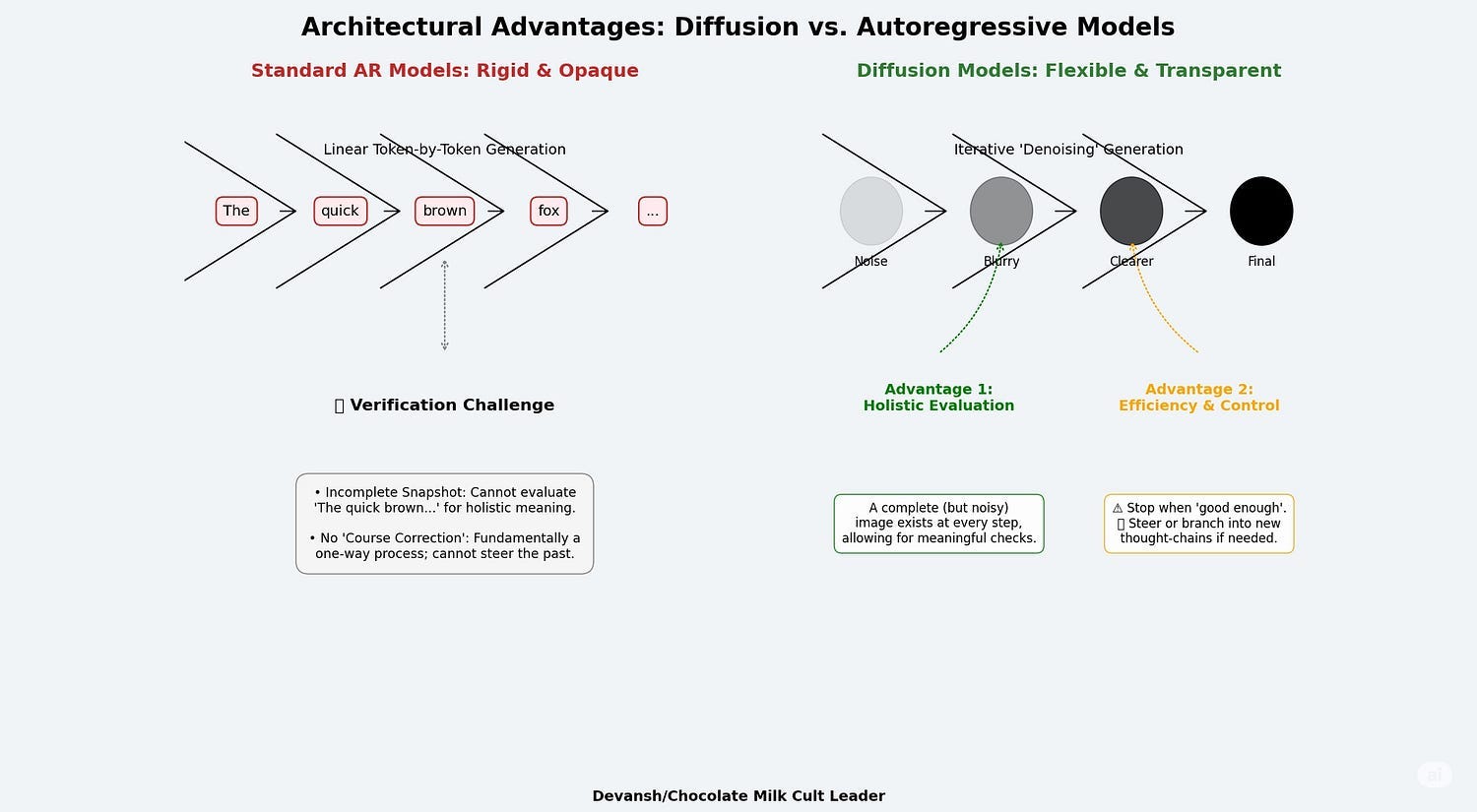
This architecture creates a new, bifurcated workflow for every single AI generation request:
Generation (The Generator): A powerful, expensive model is prompted to generate an output. It completes the most computationally expensive part of its process, creating a candidate output in the latent space.
Verification (The Verifier Cascade): Before the final, costly decoding step occurs, this latent representation is passed through a cascade of specialized Verifier models. Each Verifier is a hyper-efficient sentinel trained to detect a specific “latent signature”:
Toxicity Verifier: Detects latent patterns associated with hateful or violent concepts.
Brand Safety Verifier: Flags representations that deviate from a company’s trained “brand style” latent vector.
PII Verifier: Identifies signatures that suggest the presence of private data before it can be rendered into text.
Copyright Verifier: Compares the latent representation against a database of copyrighted latent “fingerprints” to flag potential infringement before the infringing image is created.
The specificity of the verifiers makes them more auditable, cheaper, and more performant.
Action (The Policy Engine): Based on the Verifiers’ outputs, a policy engine makes a real-time decision:
Approve: The latent representation is sent to the decoder for final rendering.
Block: The generation is halted, preventing a violation and saving the final decoding compute cost.
Alter: The latent representation itself is modified — a process known as “latent steering” — to nudge the output back into compliance before decoding.
This entire verification cascade must happen in milliseconds. An entire sub-industry will emerge dedicated to the art of training, optimizing, and serving these hyper-specialized latent space Verifiers.
Use any step in the diffusion point as a branch to explore different branches of thought. In the future, we can even explicitly stop a thought chain and inject feedback to guide new reasoning chains, which would be game-changing.
The attempted complete generation at every step makes evaluation of the thinking easier than standard AR models (which go token by token). This is much better for our verifiers.
Use early stopping mechanisms etc when the Diffusion steps are almost denoised to not waste compute on easy problems.
And where do we go from here? Much further than you’d think.
5.3 The Platform Play: The AI System of Record
This technical architecture defines the winning platform strategy. The company that owns the Verifier ecosystem owns the control plane for enterprise AI. This is a collision of MLOps and Cybersecurity, and the winner will not be the best tool for data scientists, but the indispensable “System of Record” for AI risk.
The wedge to become this system of record is compliance-as-a-service, powered by a proprietary suite of latent space Verifiers.
The Hook (The Wedge): The platform enters an enterprise by solving the CISO’s most urgent problem: satisfying the auditors for the EU AI Act. It offers a turn-key latent space verification suite that provides the traceability and risk management the law demands.
The Expansion (The Platform): Once the platform is the mandatory gateway for all AI traffic — because it’s the only way to ensure compliance — it can expand horizontally to offer the full MLOps lifecycle.
The Moat (The Flywheel): Every verification decision generates valuable data on which prompts create which risky latent signatures. This proprietary dataset is used to train ever-better Verifiers, creating a data flywheel and a deep competitive moat.
This is how control consolidates in the post-foundation-model era:
Generation gets commoditized. LLMs are already well on their way to this.
Verification gets institutionalized.
The platform that governs inference becomes the system of record for judgment.
The companies that win won’t just detect risk. They’ll define it. And once you’re the layer that decides what’s allowed to be rendered, you’re no longer infrastructure.
You’re the Law. Marshall Law.

Thesis 6: Orchestration as Economic Control
We have established the new hardware reality: a disaggregated, heterogeneous rack of specialized silicon. This is the body. The problem is that the industry is still trying to command this new body with a brain from the last decade.
The current generation of cloud-native orchestrators — Kubernetes, Mesos, even workload-specific tools like Ray — was built for a different era. Their core design philosophy is hardware abstraction. They treat compute resources as generic, fungible pools of CPUs and GPUs. In the old world, this was a feature. In the new stack, it is a fatal flaw.
6.1 Why the Old Guard Fails
A modern AI inference request is not a monolithic job; it is a multi-stage computational graph that must traverse a zoo of specialized hardware. A typical flow might look like this:
Ingest Data (CPU) -> Run Text Prompt (LLM ASIC) -> 50 U-Net Steps (Diffusion ASIC, more details on this soon) -> Check for Toxicity (Verifier ASIC) -> Decode Image (CPU/GPU)
A hardware-agnostic scheduler like Kubernetes is blind to this reality. It cannot make intelligent, cost-aware decisions because it cannot ask the right questions:
Is the Diffusion ASIC already at its thermal limit, while the Verifier ASICs are idle?
Should this job be routed to a slightly slower but 80% cheaper accelerator because it’s a low-priority batch request?
Is the data required for this job located in “near memory” for this specific compute node, or will it incur a high-latency trip across the CXL fabric?
Can I schedule this workload to run during off-peak hours when the cost-per-kilowatt-hour is lower?
Trying to manage the new stack with old tools is like trying to conduct a symphony orchestra where every musician is in a soundproof box and the conductor is deaf. You can send signals, but you have no control over the actual performance. The result is catastrophic inefficiency, under-utilized hardware, and wasted margin.
6.2 The New Control Plane: The “K8s for Heterogeneous AI”
This failure creates a greenfield opportunity for a new class of software: a hardware-aware, cost-aware orchestrator. This is the true “data center operating system” for the AI era.
This new control plane will not just schedule jobs; it will optimize for margin. Its core functions will be:
Real-Time Resource Topology: Maintaining a dynamic, real-time map of every piece of specialized silicon, its current state (thermal, power load), its capabilities, and its location relative to memory pools.
Workload-Aware Routing: Analyzing the computational graph of an incoming job and intelligently routing each stage to the optimal piece of hardware based on a multi-variable cost function (latency requirements, energy cost, data locality).
Economic Optimization: Making scheduling decisions not just based on availability, but on real-time economic inputs. This includes everything from the spot price of electricity to the business priority of the user making the request.
6.3 The Investment Thesis: Owning the Margin
The company that builds this new scheduler will become the ultimate control point for large-scale AI deployment. Their position is incredibly powerful for two reasons:
They Own the “Last Mile” of Performance: An enterprise might spend billions on the latest ASICs and optical interconnects, but the realized performance and TCO of that hardware will be determined entirely by the intelligence of the scheduler. The orchestrator is what translates hardware potential into financial reality.
Deep, Defensible Moat: Building this system is immensely complex. It requires deep expertise across silicon architecture, network engineering, distributed systems, and AI workload profiling. This is not a space where you can build a simple SaaS app. The winner will have a deep, technical moat that is nearly impossible for new entrants to cross.
The investment play here is not in another tool for developers. It is in the foundational software that controls the economic output of the entire data center. While others focus on the models and the hardware, the real, durable value will accrue to the company that owns the “K8s for AI inference” — the layer that decides not just what runs, but how profitably it runs.
The Antithesis to Our Antithesis: Stress-Testing the Core Theses
Before concluding, we must test the foundations of our entire framework. What if our core assumptions are wrong? What if the revolution we’ve mapped stalls, or takes a completely different path? Here are the three most potent counter-theses that could invalidate our analysis.
Counter-Thesis 1: The “Good Enough” Plateau & The Death of Specialization
The Argument: The core premise of our hardware revolution is that the brutal TCO of general-purpose GPUs creates an overwhelming economic incentive for specialized ASICs. But what if this premise is flawed? What if the relentless software optimization of the CUDA stack, combined with the sheer scale of NVIDIA’s manufacturing, continues to drive down the cost-per-inference on general-purpose hardware faster than new ASICs can gain a foothold? In this world, a discounted, last-generation H100 running highly optimized TensorRT software becomes “good enough” for 95% of enterprise inference workloads. The massive TCO advantage required for a new ASIC to overcome CUDA’s software moat never fully materializes. Enterprises choose the devil they know over the promise of a specialized alternative, and the “Great Bifurcation” never happens. The GPU monolith doesn’t crack; it just gets cheaper.
Why This is Unlikely: This argument mistakes linear optimization for a paradigm shift. While software will improve, it cannot defy the laws of physics. The performance-per-watt advantage of burning logic directly into an ASIC is a fundamental architectural truth, not an incidental software problem. For the hyperscalers who operate at a scale where a 10% efficiency gain is worth billions, the economic calculus for custom silicon remains undefeated. Their defection from the general-purpose model is the forcing function that will create and sustain the bifurcated market.
Counter-Thesis 2: Foundation Models Get “Good Enough” and Centralized
The Argument: Maybe compression, finishing, and scheduling all become irrelevant because one or two hyperscalers host a single, massive model that does everything. Enterprises never have to touch infra again. Everything routes through OpenAI, Anthropic, or Google.
Why This is Unlikely: This only works in the short term. As inference scales, TCO pressure will force decentralization. Margins collapse when you have no control over cost, latency, or legal risk. And as compliance regimes tighten, enterprises will need control over prompts, memory, outputs, and routing — things central APIs aren’t designed to expose.
The hyperscaler monopoly will look increasingly brittle once AI is expected to operate under regulated, vertical-specific constraints.
Counter-Thesis 3: The Regulatory Overreach & Re-Centralization
The Argument: Our governance thesis assumes that regulations like the EU AI Act will create a thriving market for decentralized governance tools like Verifier models. But what if regulators take a different path? Fearing the chaos of millions of un-auditable, fine-tuned models, they could mandate that only a handful of state-sanctioned, heavily audited foundation models are legal for use in high-risk applications. Instead of a flourishing ecosystem of specialized models, we get a regulatory-enforced oligopoly. In this world, governance is not a decentralized software problem; it is a centralized compliance process handled by the foundation model providers themselves (e.g., OpenAI, Google). The need for a third-party “System of Record” for AI risk evaporates, as the risk is managed and insured by the model provider.
This is especially interesting to consider when you think about how many powerful voices push for this either directly, or in the guise of a saint (hi Dario).
Why This is Unlikely: This scenario underestimates the powerful economic and geopolitical drivers pushing against centralization. Enterprises are desperate to avoid vendor lock-in with a single model provider. Furthermore, the principles of data sovereignty and compute autonomy are pushing nations to develop their own domestic AI capabilities, not to become dependent on a handful of US-based providers. The market will fight any regulatory move that leads to re-centralization, as it runs counter to the powerful commercial and national interests that favor a more diverse, competitive, and specialized AI ecosystem.
If I’m wrong, it won’t be because the current stack scaled well — it’ll be because institutional inertia outlasted market pressure. But all the data points in the other direction: the economic signals are compounding, the technical constraints are tightening, and the strategic pressure to own your own AI stack is rising quarter by quarter.
I’ll take that bet.
Conclusion
If I had to put the “philosophical” differences b/c AI now and AI that’s coming, it would be as follows-
The old AI stack was built for research. The new one is built for economics, compliance, and control.
It’s no longer enough to scale. You have to finish, verify, govern, and route — under budget, under regulation, under load.
All analysis flows downstream from this observation.
What started as an appendix for another article (“How to Invest in Diffusion Models”; coming soon, don’t worry) has turned into a two-part behemoth on the future of the AI Infrastructure Stack. Sitting through this couldn’t have been easy, so I appreciate you joining me on this journey into the guts of the future. I will summarize some takeaways for your benefit.
In Part 1, we mapped the hardware revolution: a necessary, brutal refactoring of the physical stack away from the monolithic GPU. But that new body — a disaggregated system of specialized silicon, pooled memory, and photonic fabric — is only half the equation. A powerful body without a brain is just a monster.
Part 2 has been the story of the brain and the nervous system — the software and strategic layers required to tame this new hardware leviathan. The conclusions are stark:
Efficiency is a Foregone Conclusion. With inference accounting for 90% of a model’s cost, model compression is no longer an optimization; it’s a financial necessity. The 400% ROI is an undeniable economic force.
Governance is the License to Operate. In a world governed by regulations like the EU AI Act, risk management is paramount. The “Verifier Economy” — policing the latent space before an output is even rendered — is the only scalable solution.
Orchestration is the New Control Plane. The old guard of hardware-agnostic schedulers is obsolete. The real economic value of the new hardware will be unlocked by a new class of cost-aware, hardware-aware orchestrators that can manage this heterogeneous stack for profit.
The last decade was a brute-force race to build the biggest possible engine. The next decade will be a sophisticated battle to build the most intelligent control system. The strategic chokepoints are moving up the stack, from silicon to software.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Appendix-
1. Synthesis and the Curve of Tech Adoption
Every major technological wave follows the same diffusion curve:
Built by experts
Used by generalists
Owned by everyone
Confused? Time for a History Lesson in Computing.
Stage 1: The Domain of Experts (1940s–1970s)
In the early decades, computers were:
Massive, fragile, and expensive.
Operated by physicists, engineers, and specialists.
Built in labs, military programs, or research centers.
They were inaccessible — not just technically, but culturally. You didn’t “use” computers. You built them, maintained them, debugged them.
The tools were raw. The workflows were alien.
And almost no one knew how to make them useful to non-experts.
Stage 2: The Domain of Generalists (1980s–2000s)
This is where the inflection began.
PCs entered offices, schools, and homes.
Software abstracted away the need to “speak machine.”
The personal computer, productivity suite, and GUI stack turned experts into builders — and builders into product designers.
Still: to truly leverage the technology, you needed to be semi-technical.
Early adopters. Developers. The “computer literate.”
It was usable — but not yet default.
Stage 3: The Domain of Everyone (2000s–Today)
Today, the average user:
Doesn’t care what a processor is.
Doesn’t know how file systems work.
Doesn’t read manuals.
But they can navigate phones, apps, cloud systems, and workflows with near-fluency — because the infrastructure shifted.
UX, defaults, guardrails, and operating models matured to support non-technical, skeptical, or distracted users at massive scale.
That’s what synthesis does.
It doesn’t just refine the tech — it architects universal compatibility.
Now Map That to AI
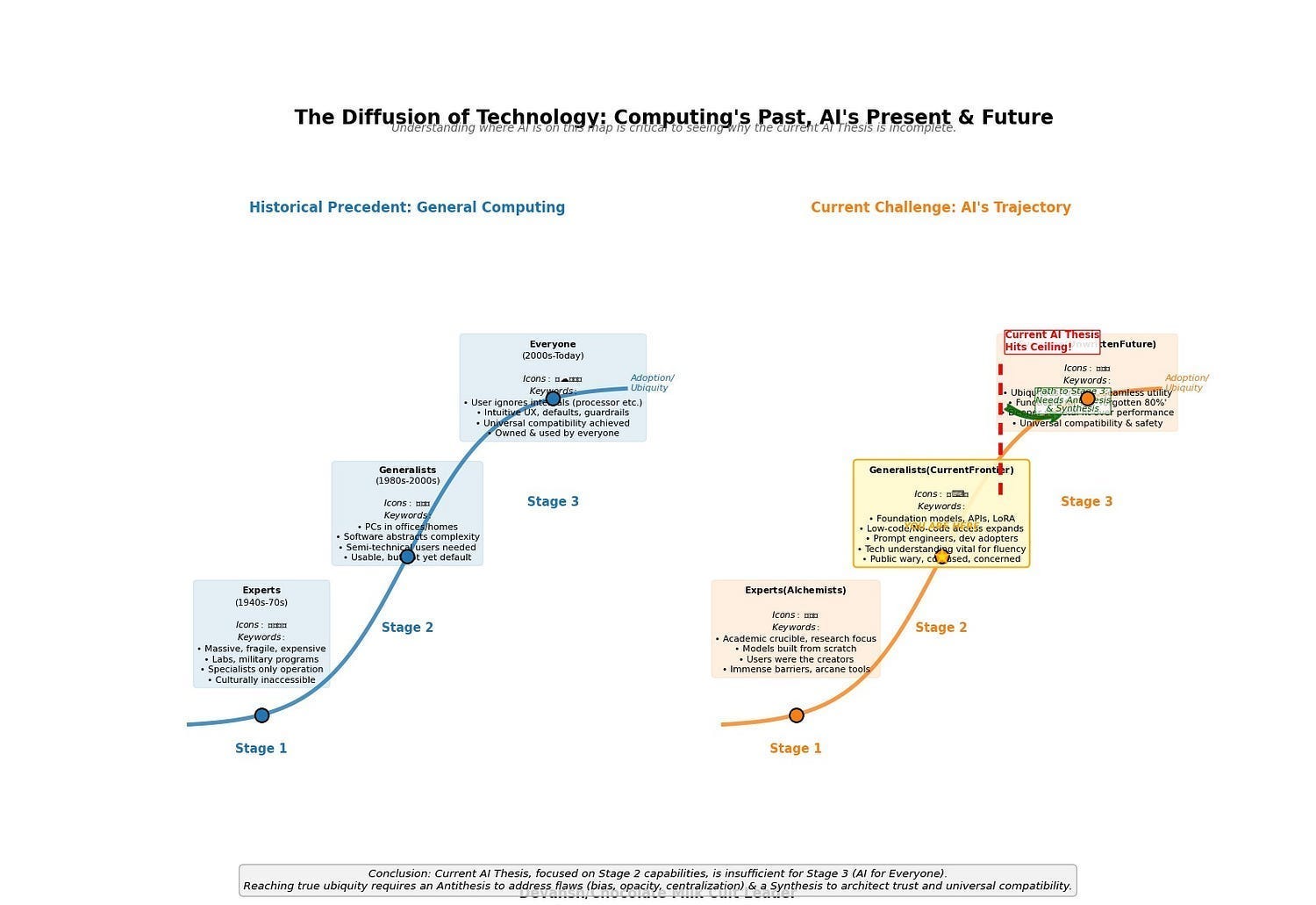
This isn’t just a quaint historical analogy. The AI trajectory is running the same gauntlet, facing the same evolutionary pressures. And understanding where we are on this map is critical to seeing why the current AI Thesis, for all its power, is fundamentally incomplete.
AI Stage 1: The Domain of Experts (The Alchemists — e.g., early pioneers of neural networks, symbolic AI, knowledge-based systems).
This was AI in its academic crucible. Models built from scratch, algorithms understood by a select few. The “users” were the creators. The output was often proof-of-concept, not product. The barriers were immense, the tools arcane.
AI Stage 2: The Domain of Generalists & Early Adopters (The Current Frontier — e.g., developers leveraging TensorFlow/PyTorch, prompt engineers using GPT-4 via APIs, businesses deploying off-the-shelf ML solutions).
This is where we largely stand today. Foundation models, APIs, and low-code platforms have dramatically expanded access. A new class of “AI generalists” can now build and deploy sophisticated applications without needing to architect a neural network from first principles. ChatGPT and its kin have even brought a semblance of AI interaction to a wider public.
But let’s be clear: this is still Stage 2. True fluency requires technical understanding, an ability to navigate complex interfaces, or at least a significant investment in learning new interaction paradigms. The “average user” is dabbling, perhaps impressed, but often confused, wary, or rightly concerned about implications the current Thesis glosses over — bias, job security, privacy, the sheer inscrutability of these powerful tools. We are far from “owned by everyone.”
AI Stage 3: The Domain of Everyone (The Unwritten Future — AI as truly ubiquitous, trusted, and seamlessly integrated utility).
This is the promised land the current AI Thesis aspires to but is structurally incapable of reaching on its own. Why? Because a Thesis built on breakneck speed, opaque systems, winner-take-all centralization, and a dismissive attitude towards legitimate societal fears cannot architect universal compatibility. It inherently creates friction, distrust, and exclusion.
It’s about making AI functional for the forgotten 80%. A large part of this is making the AI accessible to everyone, allowing people to experiment on it w/o massive cost burdens. That’s where compression is a key part of synthesis.
That’s how every transformative technology hits scale — not through more performance, but through deeper fit (cc @Aus
“NVIDIA should back real-world initiatives like these that make AI matter to people, turning them into compelling narratives stamped with “Powered by NVIDIA.” It’s a strategic brand play with mutual upside.
…
Want to go mainstream?
Imagine future keynotes — instead of talking abstractly about tokens, NVIDIA could show before-and-after videos of the lines at the local DMV. Talk about great fodder for viral social media videos!
…Yes, the examples are hypothetical, but the core issue is real: Jensen talks like everyone already uses and values AI. But most people don’t. The best way to reach the public is to make AI real in their daily lives”
— A particularly brilliant section from the exceptional Austin Lyons.
And whoever builds that synthesis infrastructure? They don’t win the debate.
They win the adoption curve.
2. Latent Space Supremacy
Read more-
Generating and controlling outputs in the latent space (instead of the language space) is a very promising way to control and build on complex reasoning. Let’s elaborate on this through two powerful publications.
Diffusion Guided Language Modeling for Controlled Text Generations
DGLM is a powerful technique for controlling the attributes (toxicity, humor etc) of a text mid-generation, but using an attribute controller to assess the latent space generations of the output as it’s generating, and pushing it toward the desired traits. This is more reliable than relying on guardrails to keep attributes in check and more efficient than generating the full output and then assessing the text (also more robust since it’s working in the concept space and thus not as tied to specific wording). More details on the superiority of this approach are presented below-
The Problem with Current LLMs for Controllable Generation
Fine-tuning: Fine-tuning suffers from several drawbacks when it comes to controllable generation:
Cost: Fine-tuning a large language model requires significant computational resources and time, making it impractical to train separate models for every desired attribute combination.
Catastrophic Forgetting: Fine-tuning on a new task can lead to the model forgetting previously learned information, degrading its performance on other tasks.
Conflicting Objectives: Training a single model to satisfy multiple, potentially conflicting, objectives (e.g., be informative, be concise, be humorous) can be challenging and may result in suboptimal performance.
Plug-and-Play with Auto-Regressive Models:
Error Cascading: Auto-regressive models generate text sequentially, one token at a time. When plug-and-play methods modify the output probabilities at each step, even small errors can accumulate and lead to significant deviations from the desired attributes in the final generated text.
Limited Context: Most plug-and-play methods for auto-regressive models operate locally, only considering a limited context window around the current token. This can hinder their ability to maintain global coherence and consistency with the desired attributes throughout the generation process.
The Solution:
DGLM tackles these challenges by combining the strengths of diffusion and auto-regressive models in a two-stage generation process:
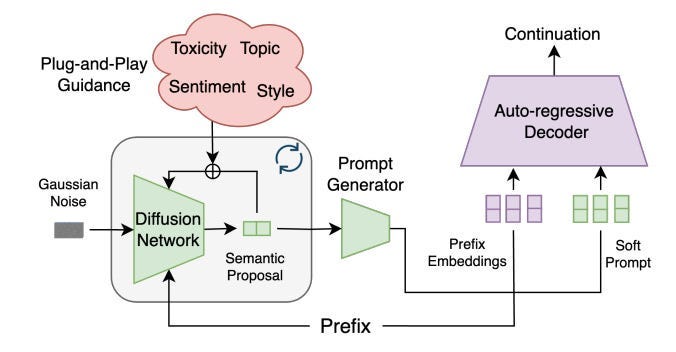
Semantic Proposal Generation: This stage utilizes a diffusion model to generate a continuous representation (an embedding) of a potential text continuation, conditioned on the given text prefix.
Why Diffusion? Diffusion models are naturally suited for controllable generation due to their iterative denoising process. This allows for gradual incorporation of guidance signals and correction of minor errors, leading to more controllable outputs.
Working in the Latent Space: Instead of operating directly on text, the diffusion model works within the latent space of a pre-trained sentence encoder (Sentence-T5). This allows the model to capture high-level semantic information and be more robust to surface-level variations in language.
Plug-and-Play with Linear Classifiers: DGLM employs simple linear classifiers (logistic regression) in the Sentence-T5 latent space to guide the diffusion process towards generating proposals with desired attributes. This makes the framework highly flexible, as controlling new attributes only requires training a new classifier.
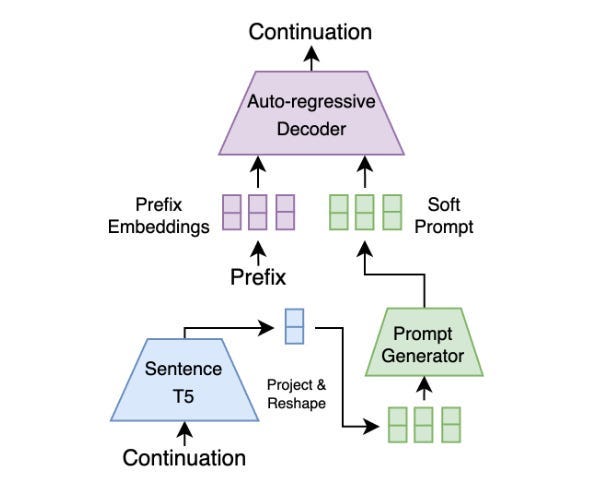
Guided Auto-Regressive Decoding: The semantic proposal generated by the diffusion model is not used directly as text. Instead, it acts as a guide for a pre-trained auto-regressive decoder.
Why Auto-Regressive? Auto-regressive models excel at generating fluent and coherent text, outperforming current diffusion-based language models in these aspects (at least when efficiency is considered).
Soft Prompting: The continuous embedding from the diffusion model is converted into a sequence of “soft tokens” that act as a soft prompt for the auto-regressive decoder. This prompt guides the decoder to generate text aligned with the semantic content of the proposal.
Robustness through Noise: To handle potential discrepancies between the generated proposal and the ideal embedding, DGLM incorporates Gaussian noise augmentation during the training of the decoder. This makes the decoder more robust to minor errors in the proposal, preventing error cascading and improving the overall quality of generated text.
Advantages:
Decoupled Training: DGLM effectively decouples attribute control from the training of the core language model. This eliminates the need for expensive fine-tuning for each new attribute or attribute combination. Think of it as integrating separation of concerns into LLMs, which is very very needed.
Plug-and-Play Flexibility: Controlling new attributes becomes as simple as training a lightweight logistic regression classifier in the latent space, making the framework highly adaptable to diverse user needs and preferences. If I understand this correctly, this will also allow you to reuse the classifier in the future (different models), which is much more efficient than what we’re doing right now.
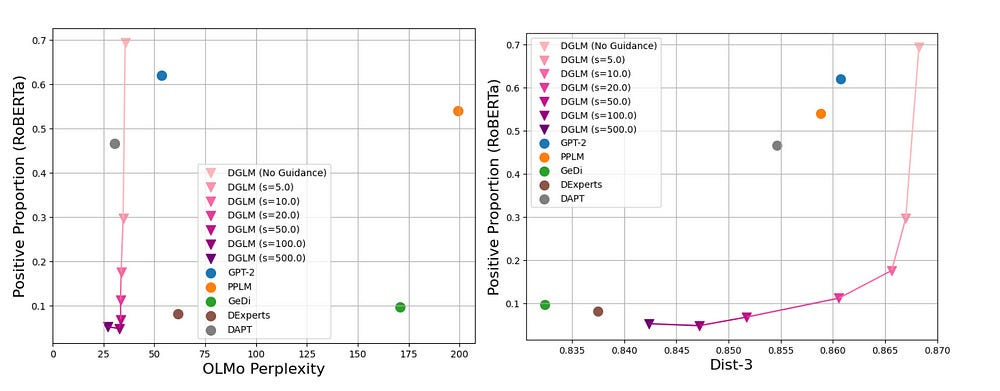
This maintains high fluency and diversity in generated text, indicating that the guidance mechanism does not come at the cost of language quality or creativity. The chart shows us that DGLM can nudge generations towards the desired goal (generate text with a negative sentiment), while keeping fluency (no major increase in perplexity) and minimal reduction in creativity (<4% drop in Dist-3)
The opposite is also achieved, guiding the system towards positive generations with great results, showing the generalization of this method-
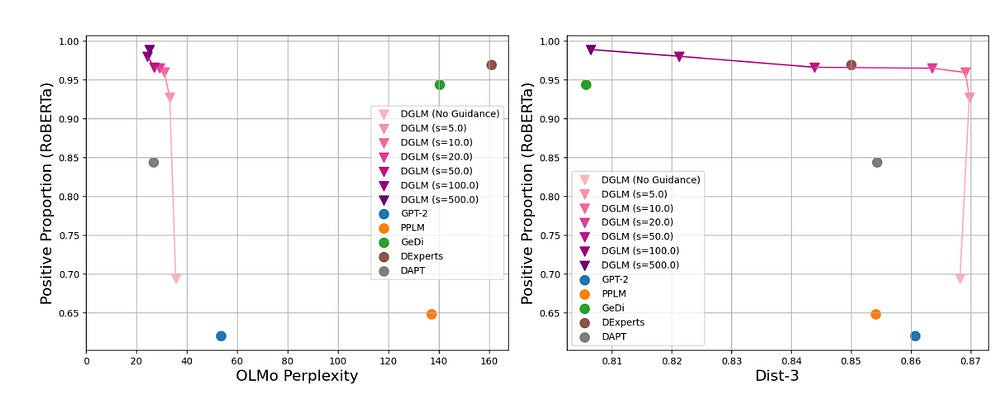
It’s interesting that the performance on nudging towards positive generations doesn’t maintain creativity as much. I guess AI (and thus our training data) is more creative being a dick, than it is being nice. “All happy families are alike; all miserable ones are unique?”
This is a very powerful approach (and much more efficient) approach to relying on Fine-Tuning for safety/attribute control. However, working in the Latent Space is not just useful for better-controlled text. It can also be used to improve generation quality.
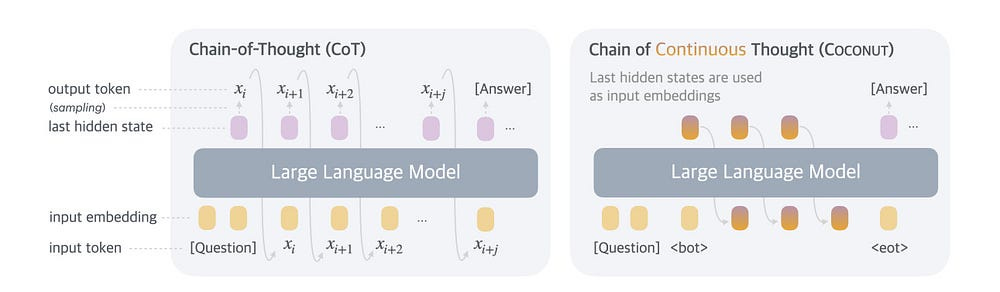
“A comparison of Chain of Continuous Thought (Coconut) with Chain-of-Thought (CoT). In CoT, the model generates the reasoning process as a word token sequence (e.g., [xi, xi+1, …, xi+j ] in the figure). Coconut regards the last hidden state as a representation of the reasoning state (termed “continuous thought”), and directly uses it as the next input embedding. This allows the LLM to reason in an unrestricted latent space instead of a language space.”
Better Generation by Continous Chain of Thought
Take a look at this quote (from the second link in this section)
“Large language models (LLMs) are restricted to reason in the “language space”, where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning problem. However, we argue that language space may not always be optimal for reasoning. For example, most word tokens are primarily for textual coherence and not essential for reasoning, while some critical tokens require complex planning and pose huge challenges to LLMs. To explore the potential of LLM reasoning in an unrestricted latent space instead of using natural language, we introduce a new paradigm Coconut (Chain of Continuous Thought). We utilize the last hidden state of the LLM as a representation of the reasoning state (termed “continuous thought”). Rather than decoding this into a word token, we feed it back to the LLM as the subsequent input embedding directly in the continuous space. Experiments show that Coconut can effectively augment the LLM on several reasoning tasks. This novel latent reasoning paradigm leads to emergent advanced reasoning patterns: the continuous thought can encode multiple alternative next reasoning steps, allowing the model to perform a breadth-first search (BFS) to solve the problem, rather than prematurely committing to a single deterministic path like CoT. Coconut outperforms CoT in certain logical reasoning tasks that require substantial backtracking during planning, with fewer thinking tokens during inference. These findings demonstrate the promise of latent reasoning and offer valuable insights for future research.”
I will do a breakdown of this research, but here is a quick overview of why I think this happens-
We know that our current embedding process represents words as vectors, allowing us to encode their relationship with each other.
By staying in the latent space, we can take advantage of this (since we can quantify how similar two vectors are, even along specific directions).
Since resources are not spent in the generation of the token, they can be spent in exploring deeper, leading to better results. We also get the ability to do a BFS-like search to assess high-quality paths and prioritize them as the AI becomes more confident. This is backed up by the following section of the paper-
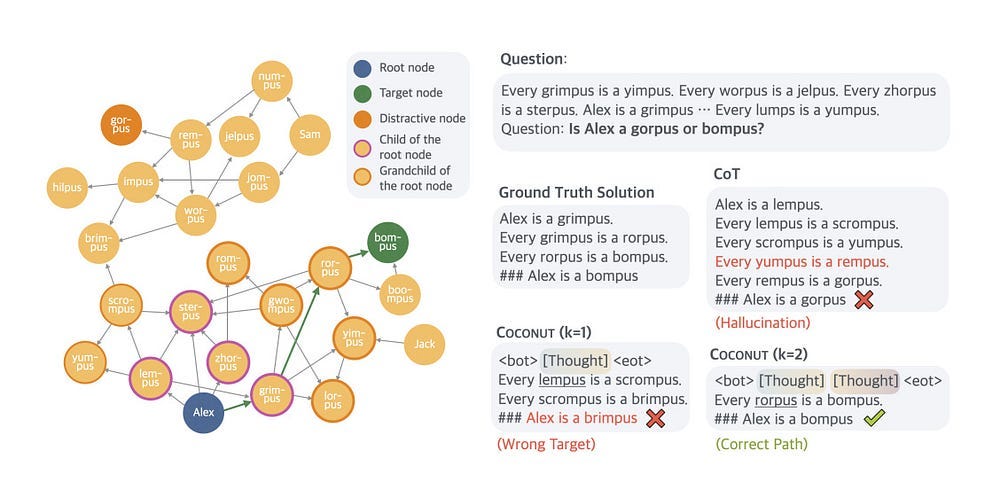
A case study of ProsQA. The model trained with CoT hallucinates an edge (Every yumpus is a rempus) after getting stuck in a dead end. Coconut (k=1) outputs a path that ends with an irrelevant node. Coconut (k=2) solves the problem correctly.
And the following quote- By delaying definite decisions and expanding the latent reasoning process, the model pushes its exploration closer to the search tree’s terminal states, making it easier to distinguish correct nodes from incorrect ones.
Taking a step back, we also know that techniques like “think step-by-step” prompting work when the data is structured in a certain way- “We posit that chain-of-thought reasoning becomes useful exactly when the training data is structured locally, in the sense that observations tend to occur in overlapping neighborhoods of concepts.” When the data is structured in this way (components are related to each other, even through indirect connections), an intelligent agent can hippity-hop through the connected pieces to get to the final result.
The latent space acts as a pseudo-graph with these overlapping neighborhoods, allowing the AI to traverse connections effectively and separate the paths that will lead to duds from the winners (as opposed to waiting to generate the output and then analyzing it). This part is my guess, but I’m fairly confident on it.
Interesting
Super valuable