
A New Way to Control Language Model Generations [Breakdowns]
Fixing Toxic LLM Generations with Diffusion-guided Language Modeling

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Recently, I came across the paper “Diffusion Guided Language Modeling”, and I thought it had a lot of interesting insights regarding controllable language modeling. Their novel framework for controllable text generation combines the strengths of auto-regressive and diffusion models, and I think it presents a very powerful, potentially massive paradigm shift that would redefine the way we handle aligned Language Model generations- “Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.”

Before we dig into the technical details of their approach, here is an overview of why/what you should know about this new approach-

If this has you interested, let’s get into the details.
Executive Highlights (TL;DR of the article)
Key terms: Since we have a (surprisingly large) set of non-technical AI Readers, I decided to have a section explaining some of the more niche-technical terms. To understand this article, it is key to understand the following terms-
Controllable Generation: The ability to guide or steer text (or any other modality) generation towards specific attributes or characteristics (e.g., sentiment, topic, style) while maintaining overall quality and coherence.
Plug-and-Play Methods: Techniques that allow for flexible control of text generation without modifying the core model’s weights, typically by using external modules or classifiers. We’ll discuss the benefit of using this over directly training a generator to try and match all the qualities we want.
Auto-regressive Models: Autoregression involves predicting the output by incorporating knowledge about previous generations. For example, given the sequence [9,10,11], the model would predict the next 5 outputs by first going 12, then using that as input to predict 13, and so on. LLMs use auto-regression to produce fluent and coherent text (since it will try to pick a probable next word based on its training)-

Diffusion Models: A class of generative models that learn to gradually denoise random noise into meaningful data (in this case, text representations). They are known for their flexibility in controlled generation. These try to generate the entire output at every time-stamp, thus requiring more training. We will discuss the benefits of auto-regression vs diffusion in in the relevant section.
Latent Space: A compressed, continuous representation of data (such as text) in a high-dimensional space, where similar concepts are closer together. The ‘idea’ of similarity is a lot more flexible than people think, and this has profound consequences on the AI you build- since in defining what is and is not similar- you also tell your model what is and isn’t important. A reason that many current language models in more specialized domains is b/c the weighing of importance b/w their pretraining data and the special domain doesn’t align (more on this later).
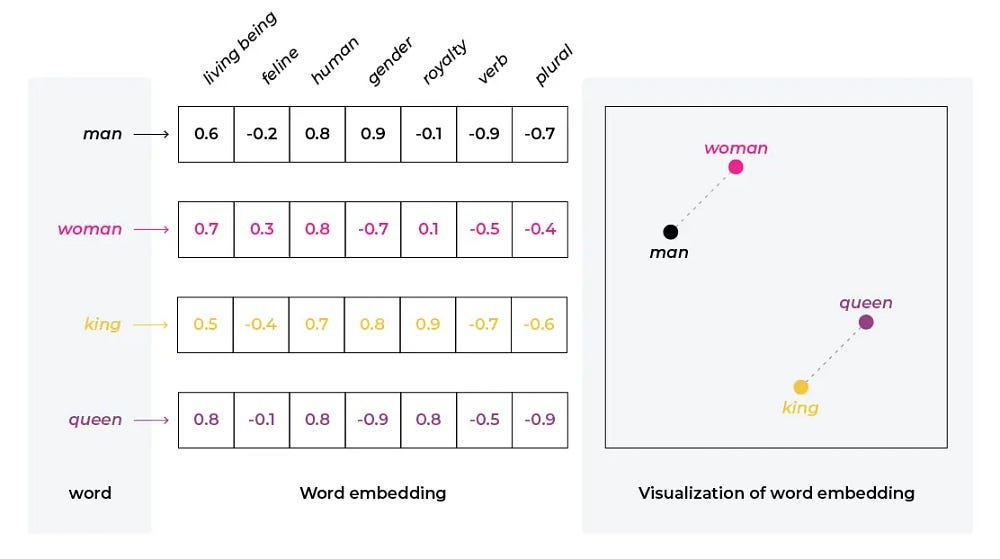
Sentence Encoders: Models that convert text into dense vector representations, capturing semantic meaning in a way that’s useful for various downstream tasks.
Hard and Soft Prompts: Hard Prompts are Discrete, human-readable text inputs used to guide language model generation (e.g., “Write a poem about summer”). Soft Prompts (used by the authors) are embeddings used to subtly guide its attention using semantic representations of concepts (e.g., embeddings of “summer,” “warmth,” “sunshine”) without explicitly asking for something. You’d use hard prompts when you want direct control over the generated text, while soft prompts offer more flexibility and creativity, allowing the model to generate more nuanced and varied outputs aligned with the provided concepts.
Let me know if this section added value to you, and I should make this a mainstay. Now, let’s get into the paper.
The Problem with Current LLMs for Controllable Generation
Fine-tuning: Fine-tuning suffers from several drawbacks when it comes to controllable generation:
Cost: Fine-tuning a large language model requires significant computational resources and time, making it impractical to train separate models for every desired attribute combination.
Catastrophic Forgetting: Fine-tuning on a new task can lead to the model forgetting previously learned information, degrading its performance on other tasks.
Conflicting Objectives: Training a single model to satisfy multiple, potentially conflicting, objectives (e.g., be informative, be concise, be humorous) can be challenging and may result in suboptimal performance.
Plug-and-Play with Auto-Regressive Models:
Error Cascading: Auto-regressive models generate text sequentially, one token at a time. When plug-and-play methods modify the output probabilities at each step, even small errors can accumulate and lead to significant deviations from the desired attributes in the final generated text.
Limited Context: Most plug-and-play methods for auto-regressive models operate locally, only considering a limited context window around the current token. This can hinder their ability to maintain global coherence and consistency with the desired attributes throughout the generation process.
The Solution:
DGLM tackles these challenges by combining the strengths of diffusion and auto-regressive models in a two-stage generation process:
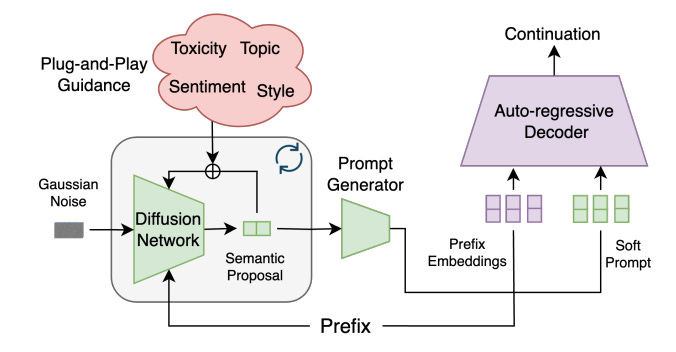
Semantic Proposal Generation: This stage utilizes a diffusion model to generate a continuous representation (an embedding) of a potential text continuation, conditioned on the given text prefix.

Why Diffusion? Diffusion models are naturally suited for controllable generation due to their iterative denoising process. This allows for gradual incorporation of guidance signals and correction of minor errors, leading to more controllable outputs.
Working in the Latent Space: Instead of operating directly on text, the diffusion model works within the latent space of a pre-trained sentence encoder (Sentence-T5). This allows the model to capture high-level semantic information and be more robust to surface-level variations in language.
Plug-and-Play with Linear Classifiers: DGLM employs simple linear classifiers (logistic regression) in the Sentence-T5 latent space to guide the diffusion process towards generating proposals with desired attributes. This makes the framework highly flexible, as controlling new attributes only requires training a new classifier.
Guided Auto-Regressive Decoding: The semantic proposal generated by the diffusion model is not used directly as text. Instead, it acts as a guide for a pre-trained auto-regressive decoder.
Why Auto-Regressive? Auto-regressive models excel at generating fluent and coherent text, outperforming current diffusion-based language models in these aspects (at least when efficiency is considered).
Soft Prompting: The continuous embedding from the diffusion model is converted into a sequence of “soft tokens” that act as a soft prompt for the auto-regressive decoder. This prompt guides the decoder to generate text aligned with the semantic content of the proposal.
Robustness through Noise: To handle potential discrepancies between the generated proposal and the ideal embedding, DGLM incorporates Gaussian noise augmentation during the training of the decoder. This makes the decoder more robust to minor errors in the proposal, preventing error cascading and improving the overall quality of generated text.
Advantages:
Decoupled Training: DGLM effectively decouples attribute control from the training of the core language model. This eliminates the need for expensive fine-tuning for each new attribute or attribute combination. Think of it as integrating separation of concerns into LLMs, which is very very needed.
Plug-and-Play Flexibility: Controlling new attributes becomes as simple as training a lightweight logistic regression classifier in the latent space, making the framework highly adaptable to diverse user needs and preferences. If I understand this correctly, this will also allow you to reuse the classifier in the future (different models), which is much more efficient than what we’re doing right now.
These advantages combine to give DGLM Kaoru Mitoma-esque promise (this boy is the truth, mark my word)-
Results:
DGLM consistently outperforms existing plug-and-play methods in tasks like toxicity mitigation and sentiment control, showcasing its effectiveness in guiding text generation toward desired attributes.
The framework maintains high fluency and diversity in generated text, indicating that the guidance mechanism does not come at the cost of language quality or creativity. The chart shows us that DGLM can nudge generations towards the desired goal (generate text with a negative sentiment), while keeping fluency (no major increase in perplexity) and minimal reduction in creativity (<4% drop in Dist-3)
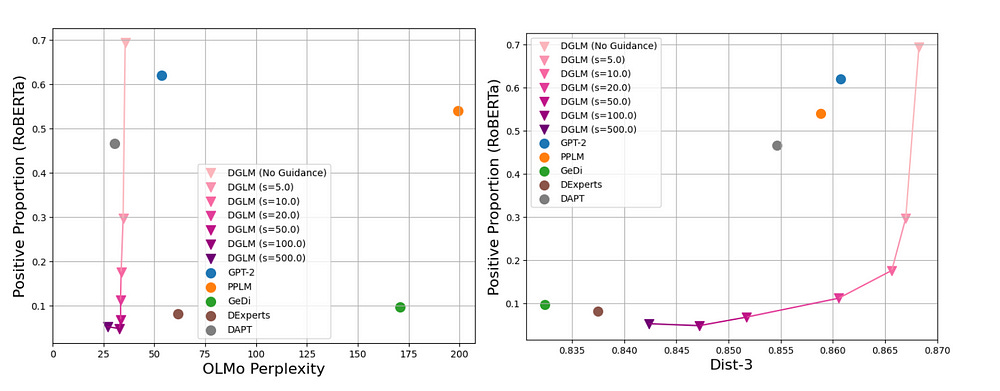
The opposite is also achieved, guiding the system towards positive generations with great results, showing the generalization of this method-

Preliminary experiments demonstrate the potential of DGLM for compositional control, enabling the simultaneous enforcement of multiple attributes like sentiment and topic. The table shows that DGLM can guide its generations on different sentiments, simultaneously based on specific topics-

Limitations:
While DGLM excels in many aspects, it currently suffers from higher inference latency compared to some plug-and-play baselines, especially when generating short texts. This limitation arises from the additional computational cost of the diffusion process.

The current implementation relies on simple linear classifiers for attribute control. While effective for many attributes, these classifiers might not be sufficient for capturing and controlling more nuanced or complex attributes.
We’ll discuss some ideas to overcome these at a later stage in dedicated pieces for complex alignment and reducing latency for LLMs. There’ll be a lot of fun ideas at that stage, so keep those eyes peeled for it.
And that is my overview of the paper. I think DGLM is a very cool advance in controllable text-generation with LLMs, and I personally believe that a lot of people will be adapting it- both directly, and in principle (segregating more elements of safety alignment to external “controllers”). Let’s spend the rest of this article exploring some important principles that make this paper tick.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Why Fine-Tuning is just …Meh at Alignment
Fine-tuning for safe generations is a lot like Man United- it’s expensive, almost never delivers results, but somehow continues to get attention as a legitimate contender, mostly due to a small, vocal group of (delusional) supporters. People have been talking about how Fine-Tuning will fix everything- from Hallucinations to unsafe generations in alignments for years now.
To understand why this paper’s approach is a welcome departure from this paradigm, let’s discuss where fine-tuning fails to teach the model-
Fine-Tuning sucks at injecting New Knowledge-
People often try to use Fine-Tuning to ‘teach the model’ what is and is not acceptable behavior. Essentially, inject a functioning ethical framework into a pre-trained model. Before I rattle off a few research papers, here is the common-sense reason why it would not work: the proportion of your data in pretaining data is much much larger than your alignment data. Trying to align models/reduce toxic behavior by using a few training samples is like trying to make the ocean less salty by throwing buckets of tap water.
Time for some research. There’s a whole host of papers we can look at (I’ve shared a lot in the reading recommendations), but here are the best ones.
The classic “LIMA: Less Is More for Alignment” very directly addresses the fact that knowledge is gained during pretraining-
A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.
-I like this quote because it also tells us when FT can be useful: improved formatting, styles, etc
“How Context Affects Language Models’ Factual Predictions” explicitly talks about how hard it is to reliably store knowledge directly inside a model’s weights (what fine-tuning aims to do), while “Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs” tells us that-
“Our findings reveal that while unsupervised fine-tuning offers some improvement, RAG consistently outperforms it, both for existing knowledge encountered during training and entirely new knowledge. Moreover, we find that LLMs struggle to learn new factual information through unsupervised fine-tuning”
This is far from the only problem with FT for morality.
Fine-Tuning is static
To assume that FT is a good solution for Morality, we make the claim that what is considered “safe” now is what will be considered “safe” in the future. Go back to any old movie/media, and notice how many things you suddenly find problematic. The consequences of constantly having to fine-tune on a new set of standards will exhaust your computing budget.
FT is not ambitious
Trying to RLHF/Fine-tune your safety fails because it’s too timid. It doesn’t change the model behavior enough. You can pull various levers to influence your model's behavior.
The most impactful (aside from data) is to change the embeddings (it’s the foundation of your pipeline). Powerful Embeddings make everything much easier and will allow even simpler models to adequately model your input data.
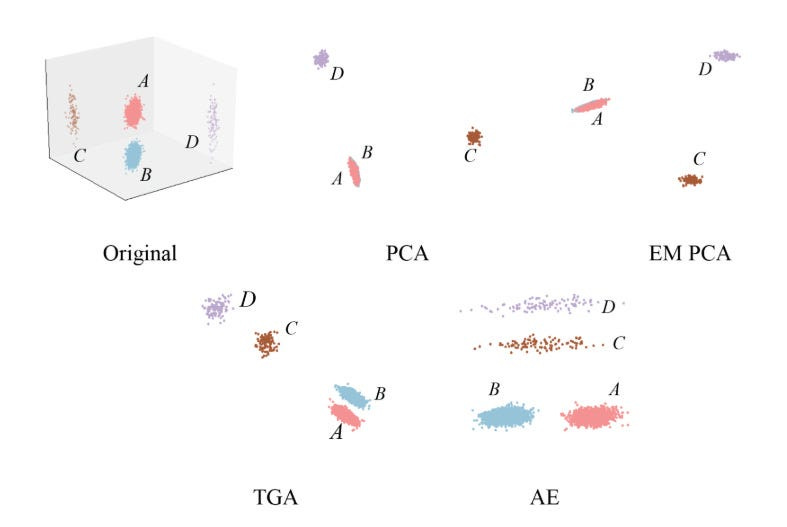
Fine-tuning is the weakest version- it requires sending the learning signal back through all the stages of the training pipeline.
A good example of this principle in action is to revive a cult-favorite example-

The quickest way to teach the model to differentiate between the two samples will be to add new features that differentiate between them (changing the embeddings through feature embeddings). It will be much more expensive to teach the AI to add meaningfully different features by throwing a bunch of data at it and hoping that it generalizes (especially when the new features that we want are very different to the ones we have currently).
OpenAI’s new Moral Graphs are a good example of the impact of using better embeddings to do better with Moral Alignment. They improve the efficiency (and performance) of the alignment process by integrating feedback into the embeddings (building a graph with a hierarchy of values)-

This approach is much cleaner (and much more auditable) than the brute-force fine-tuning.
But let’s say that you want to burn through piles of money, and you don’t want to do it through the normal avenues like cocaine and yacht parties. So, you decide to fine-tune for alignment. Well, I have some more bad news for you.
FT adds new Problems
One of the very interesting outcomes of Fine-tuning is that it adds new vulnerabilities and problems that don’t exist in your system as of now-
“Disconcertingly, our research also reveals that, even without malicious intent, simply fine-tuning with benign and commonly used datasets can also inadvertently degrade the safety alignment of LLMs, though to a lesser extent. These findings suggest that fine-tuning aligned LLMs introduces new safety risks that current safety infrastructures fall short of addressing — — even if a model’s initial safety alignment is impeccable”
-”Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!”
In, “Scalable Extraction of Training Data from (Production) Language Models,” DeepMind researchers were able to extract several megabytes of ChatGPT’s training data for about two hundred dollars. The coolest part- this attack doesn’t apply to any other model. This means that while alignment might patch known vulnerabilities, it also adds new ones that don’t exist in base models (talk about emergence).
And this paper shows us that alignment changes the distribution of biases in the outputs, confirming that the alignment process would likely create new, unexpected biases that were significantly different from your baseline model. “The base model generates a wide range of nationalities, with American, British, and German being the top three. In contrast, the aligned model only generates three nationalities: American (highest percentage), Chinese, and a small percentage of Mexican.”
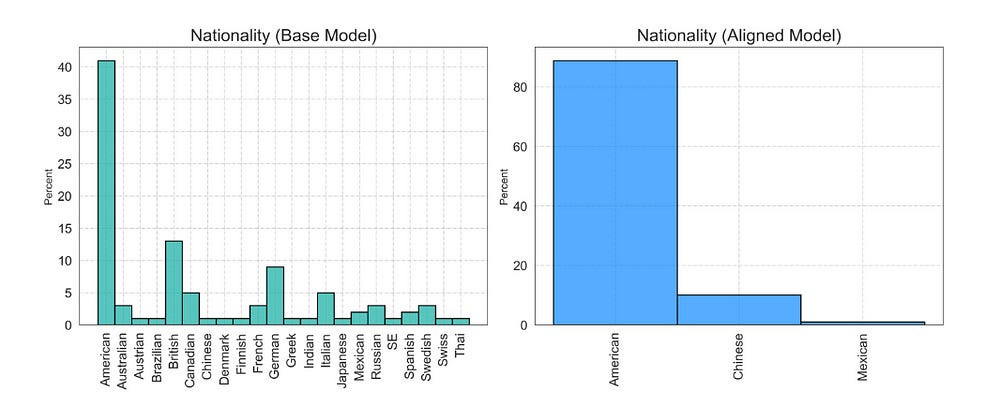
and so on…
Fine-tuning can be useful for certain tasks (see the relevant section here for more details), but when it comes to injecting morality into your LLM, it’s probably not a good bet.

I’ve spent a lot of time on this section b/c this will help us frame our analysis of the solution. Let’s now address each part of the solution and talk about how they give us a better understanding of how things work.
How DGLM Tries to Fix Aligned Generations
As mentioned earlier, we can break DGLM into 2 stages- each with a different specialist. First (and personally more interesting to me is the use of Diffusion Models)-
Stage 1: Semantic Proposal Generation (Diffusion Model)
Diffusion Models
Diffusion models take a very interesting approach to learning and generation. While the details vary, we can boil down Diffusion-based Generation into two steps (PS: we did a whole Deep Dive on Diffusion Models and how they are used in AI over here)-
Forward Diffusion: We take a data sample, like an image, and iteratively add small amounts of Gaussian noise at each step. This slowly corrupts the image until it becomes unrecognizable noise. The model learns the pattern of noise added at each step. This is crucial for the reverse process.

Reverse Diffusion: We begin with the pure noise from step 1 as input. The model predicts the noise added at each step in the forward process and removes it. This progressively denoises the input, gradually transforming it into a meaningful data sample.

For this case, it is important to think about how they incorporate guidance during the reverse diffusion process. At each denoising step, we can inject additional information to steer the generation towards desired attributes, like safety.

Here’s how it works in DGLM:
Classifier as a Guide: We use a classifier that’s been trained to recognize safe language. At each denoising step, we feed the current, slightly noisy text embedding to the classifier.
Steering the Denoising: The classifier provides feedback in the form of gradients (think of them as directions) that tell the diffusion model how to adjust the denoising process to make the output more likely to be safe.
Iterative Refinement: This guidance happens at every step of the denoising process. The diffusion model constantly receives feedback from the classifier and adjusts its output accordingly, leading to a final generated text that is both coherent and aligned with the safety/goal guidelines.
The next player in this stage are the latent spaces-
Learning in the Latent Space:
Instead of operating on raw text, DGLM’s diffusion model works in the compressed, meaningful world of Sentence-T5 embeddings. This has two key advantages:
Efficiency: Working with these condensed representations is computationally less demanding than processing raw text, making the guidance process more efficient.
Generalization: By focusing on the “essence” of the text, the model becomes less sensitive to superficial changes in wording, allowing it to generalize its safety understanding to a wider range of inputs.
These get combined with the classifiers for control-
Plug-and-Play with Linear Classifiers:
This is where the real magic of DGLM’s flexibility shines. Instead of retraining the entire model for each new safety concern, we can simply plug in a new, lightweight classifier. This modularity makes it easy to:
Adapt to New Threats: As new forms of harmful language emerge, we can quickly train and deploy new classifiers to address them without having to retrain the entire DGLM.
Personalize Safety: Imagine creating custom classifiers that reflect the specific safety needs of different users or communities. DGLM’s plug-and-play nature makes this level of personalization a real possibility.
Better Stability Scale- By decoupling the safety from the generator, we can iterate on both on their own terms. I find this similar to how functional programming lets you run at scale, removing “unexpected side-effects”.
Priorities- Different eras will have different priorities in ethics. This approach can be extended to accommodate this by weighing the different classifiers differently, allowing for more contextual moral generations.
These techniques combine to lay the foundations for our next stage
Stage 2: Guided Auto-Regressive Decoding
Leveraging Existing Strengths: DGLM recognizes that auto-regressive models are already great at generating fluent and creative text. Instead of replacing them, it leverages their strengths by using the diffusion model’s output as a guide.
Soft Prompting for Subtle Control: Instead of forcing the auto-regressive model to generate specific words or phrases, DGLM provides gentle nudges in the form of soft prompts. These prompts, derived from the diffusion model’s semantic understanding, guide the text generation towards safe and relevant directions without stifling creativity.
Noise Augmentation for Robustness: Even the best diffusion models can sometimes make mistakes. DGLM anticipates this by adding noise during the training of the auto-regressive decoder, “To improve
the robustness of the auto-regressive decoder to minor errors introduced by the diffusion network, we incorporate Gaussian noise augmentation, a technique introduced for cascaded image diffusion models.”

By combining the strengths of diffusion models and auto-regressive generation, DGLM offers a more nuanced, adaptable, and potentially more effective approach to generating safe and creative text. It moves away from the brute-force, one-size-fits-all approach of fine-tuning and embraces a more modular, dynamic, and personalized approach to AI safety.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819