
Understanding the best practices and ideas for LLM-enabled RAG systems[RAG]
RAG Part1: An overview of how to Do Retrieval Augmented Generation

Hey, it’s Devansh 👋👋
This article is part of a series on Retrieval Augmented Generation. RAG is one of the most important use-cases for LLMs, and in this series, we will study the various components of RAG in more detail. The goal is to build the best RAG systems possible. If you have anything to share, please do reach out.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Two announcements before we begin. Firstly, I’ve heard some interesting things about the Church of Scientology, so I’m interested in learning more. If any of you are Scientologists (especially in NYC), shoot me a message to say hi. Secondly, I’m looking for people who are interested in working with me on breaking surveillance systems and adversarial perturbation of deep learning models (especially multi-modal models). This is key to preventing the utilization of AI in unsafe use cases. I’ll post more about some research we’re doing soon and I would love to involve members of our little cult. If that interests you, message me.
Executive Highlights (TL;DR of the article)
A very special shoutout to Jean David Ruvini and Cameron Wolfe for sharing constantly sharing great insight on NLP and LLMs.
Retrieval Augmented Generation involves using AI to search a pre-defined knowledge base to answer user queries.

RAG stores and indexes data to make it searchable. When you ask a question, RAG searches its indexed data, retrieves the most relevant information (using the retriever), and feeds it into an LLM (called a generator) along with your query. This allows the model to generate more accurate and informed responses grounded in factual evidence. If you wanted to get real fancy, you could also use Reader models which specialize in understanding and extracting key information from retrieved documents, potentially leading to even more precise and relevant answers and/or better ranking of the contexts fed to the generator.
RAG aims to solve the issues with the two dominant paradigms of information extraction-
Traditional Search often does not give you exactly what information you want, in the exact way you want it. We might have to read through multiple sources to find our needles in the haystack, do some work to put the pieces together ourselves, and end up having to do some thinking for ourselves (ew). This is slow, expensive, and not fun. RAG speeds this up by having the AI find relevant contexts and aggregate them.
LLMs can speed up processes, but their outputs can be unreliable, outdated, or refer to sources that you don’t like. By constraining an LLM to contexts that you approve, you can handle all of these issues. It also allows you to avoid expensive retraining costs since you no longer have to spend millions embedding new knowledge directly into the LLM. Instead that cost is replaced by the cost of having to index/reindex data into your data store, which is generally cheaper. The cost delta between LLM-native search and ‘traditional’ Transformer-enabled search (which is the V0 of RAG) goes up when we consider the inference costs, which are significantly higher with LLMs than traditional search-
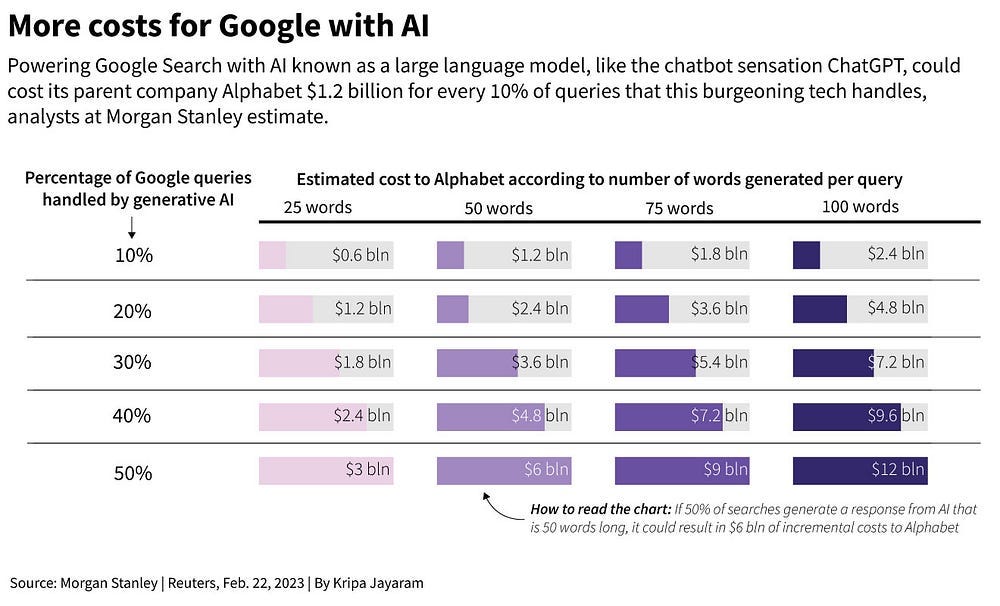
While modern RAG (especially generator-heavy setups) are more expensive than V0, the general principle is still useful to keep in mind. While we are on the discussion of costs for RAG, one thing to keep in mind is that your costs will depend very heavily on your design, and the variance between a well-designed system and a poorly designed one is night and day.
Despite this, RAG has a lot of potential, especially in inaccessible professional domains (legal, biotech, law etc) where the high cost of professionals makes any reduction in work hours extremely valuable. The complete impacts of RAG are summarized below-

Assuming we can handle the possible negative outcomes from RAG (I’m optimistic), RAG will be a massive benefit. That’s why it is time for our chocolate milk cult to do a deep dive into it. I will be combining multiple research papers, experiences from different people (including my own from the last 2.5 years) building successful RAG systems, and my insight into the workings of Machine Learning to give you a guide on how to build RAG systems that actually generate business value.
Given how comprehensive this topic can be, I will split it into a series (similar to the one we just did on Deepfakes). Today’s piece will cover the overview of the general principles, which will then form the basis of our other explorations into more advanced/specific topics (Knowledge Intensive RAG, Multi-Modal RAG, GraphRAG, AgenticRAG, and much more). To do so, we will look at the excellent “Searching for Best Practices in Retrieval-Augmented Generation” and other good publications in the space.
Given the nature of the source, we will revert from the usual tl;dr and then elaborate format, to instead discuss everything together. The rest of this article will be a discussion of the engineering of RAG systems, so if you’re not interested in the technical details, you can click off here. Otherwise let’s dig into the various stages that go into a Retrieval Augmented Generation System, and how we can design them to meet our needs.
PS: While this will refer to mostly text, the principles can be extended to MultiModal Data fairly easily.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
The RAG Workflow
A typical RAG system into various steps. Let’s look at the steps, why they matter, and what might be the best solution.
Query Classification: Decides if retrieval is needed for a given query. This helps keep the costs down, by minimizing the hits to the database and handling easier queries with the generator itself.

They find that a BERT-based classifier and achieve high accuracy (over 95%) in determining retrieval needs.

This is cool, but I think this approach can be extended a lot more, and will be very dependent on your design. For example, if you decided to use a very wimpy generator- which is fine if you have strong retrievers and readers and want to prioritize something that sticks to the chunks they pull out- classifying whether you need to retrieve something is irrelevant. On the other hand, when building our Sales Agents at Clientell, our clients often had questions that relied on processing the data (“add up sales performances for this quarter”). Instead of trying to use a heavy generator you might use a more specialized agent. Here, you’d use a query classifier as an orchestrator, routing queries to the relevant specialized agent (if you go this route, you might also need to learn how to chain commands together, which is a nightmare)-
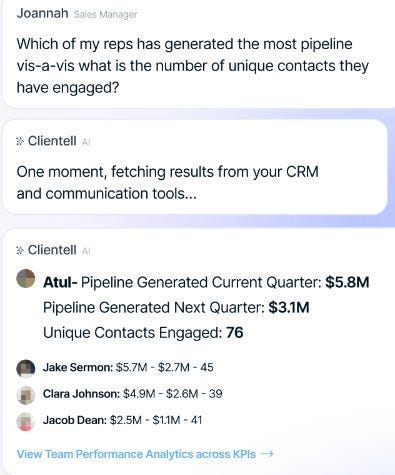
This is why knowing your customer is the most important thing. It will help you stick to the high-value additions and avoid anything that adds complexity without business value.
In general, BERT or other encoder-heavy models will do a lot of good for you when it comes to query classification. Because they tend to be stacked with auto-encoders and are often trained with bi-directional masking (you mask a token, look at both contexts in front and behind the masked token, and then try to predict what the masked token is), you tend to get a more robust understanding of the language-

This is why BERT-based language models often beat up SOTA LLMs in many domain-specific information retrieval and language understanding challenges, even when they are smaller-
When considering the standard 12 layer of BERT, our experiments show that (Chat)GPT achieves comparable performance to BERT (although slightly lower) in regard to detecting longterm changes, but performs significantly worse in regard to recognizing short-term changes. We find that BERT’s contextualized embeddings consistently provide a more effective and robust solution for capturing both short- and long-term changes in word meanings.
-Source.
There is one situation where BERT as a base will not work as well. If you find yourself regularly dealing with very complex user queries that need to be decomposed into several agent commands, then you might find yourself drawn to either a powerful AR model or an encoder-decoder model if you’re an AI hippie. I’d suggest trying the latter first because of their success in language translation and because their errors are more predictable- which will reduce the things you have to worry about.
Once we have our query classified, we must sort through our data to find the relevant information. This is where step 2 comes in-
Chunking: Splits retrieved documents into manageable chunks for the LLM to process effectively. The authors experiment with different chunking sizes and techniques, finding that sentence-level chunking with a size of 512 tokens, using techniques like “small-to-big” and “sliding window,” provides a good balance between information preservation and processing efficiency. Enrichment through the addition of meta-data also helped-

A fun story about the unreasonable effectiveness of Enrichment: this is actually the first RAG improvement I “discovered” for myself (some of you who have spoken to me know this one). To give you context- I was working with an international supply chain company that handled data for their clients (in Jan 2022). The end users- non-technical business folk- always wanted to check various performance-related metrics (“How many chairs did we sell in China last week”). Currently, this meant calling my client, who would ask a developer to write SQL queries and return answers. As you might imagine, this takes a lot of time and effort.
So, I was asked to figure out how to build a system that took End-user queries in English and converted them into an SQL query that ran in their Data and returned the desired results. This task had several challenges-
The data was laid out in several tables. Each client got a non-standardized layout, custom to the data we were storing for them. Keep in mind, even ChatGPT couldn’t do multi-source queries for a long time, even after release.
The end users were expected to know nothing about the data layout (what tables they had, column names etc) that would make their commands more explicit.
This was before powerful LLM that now do this were mainstream and accessible.
For roughly 2 weeks, I threw the kitchen sink at it with very minimal results. I had to present to my supervisor in 2 days, and I was desperate, so I started changing column and file names to make them very explicit (I noticed how a lot of errors were caused by similar names, so this was my last ditch effort to salvage something). That ended up taking the performance several times over (we hit 60% improvements on enriched data). Unfortunately, the effort and computational resources required at that stage weren’t enough, so this project was dropped. But this experience was foundational in my LLM journey (and is why I emphasize changing your system to be more AI-Friendly so strongly).
Hopefully that gives you something to think about. Now let’s move on.
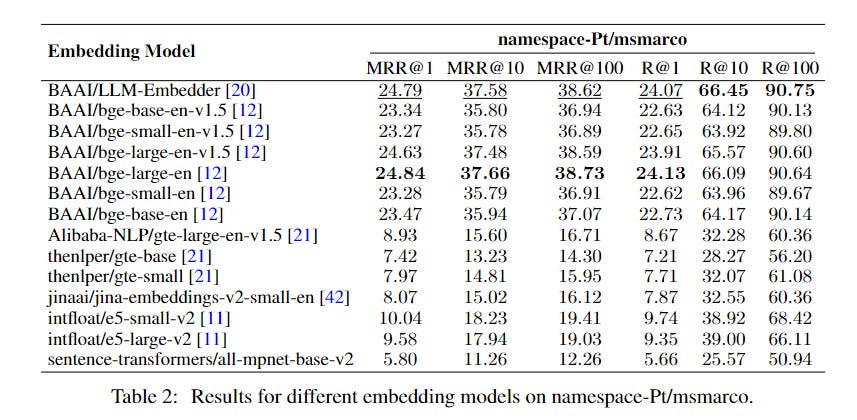
Our chunks are then turned into vectors for similarity search through embeddings. The research compares various embedding models and finds that LLM-Embedder offers a good balance of performance and efficiency compared to larger models.
Our chunks are stored in Databases. The authors tested a special kind of DB, called Vector Databases, that are sold as Databases with binding vows that make them good for AI (and RAGs specific). Let’s talk about them next.
Vector Databases
“Vector databases store embedding vectors with their metadata, enabling efficient retrieval of documents relevant to queries through various indexing and approximate nearest neighbor (ANN) methods.” The authors like Milvus the most, based on the following assessment-

This is one of my hot-takes, but I personally think you don’t really need Vector DBs for a lot of RAG problems. A simple DB available on your provider is probably enough for storing vectors (people often misunderstand this, but you can store vector embeddings without a Vector DB). To quote this excellent Xethub article that mirrors my sentiment, “You do not need document embeddings for RAG. Consider simpler information retrieval methods. Vector embeddings are still useful, and are a great way to add a higher precision filter. But to use vector embeddings as a later stage filter, all you really need is a vector retrieval service (any KV store) to be able to do efficient and exact k-NN reranking on a small set of vectors. No vector database necessary.”

Some of you are excellent software engineers who can handle complex architectures without any problems. I’m not, so I like to keep my solutions as simple as possible. Adding Vector DBs is another source of overhead and possible failure, and I’d prefer to stick to simple DBs whenever I can.
Within this research setting, we found that differences in architectural complexity could account for 50% drops in productivity, three-fold increases in defect density, and order-of-magnitude increases in staff turnover.
- “How bad is Architectural Complexity”. Complexity is costly.
This is where I will end our discussion of Vector DBs. Let’s move on to the next stage of RAG that the authors tested.
Retrieval Methods
We need to find the relevant chunks based on query similarity. The authors tested various methods, including rewriting queries, decomposing them, etc. They find that hybrid search, combining sparse and dense retrieval with HyDE (a pseudo-document generation method), achieves the best retrieval performance.

We’ll explore retrieval combining dense and sparse indexes in our exploration of KI-NLP (knowledge-intensive NLP). That’s where splitting the database into sparse and dense indexes really shines since it lets you parse through large document sets very quickly.
Reranking:
Refines the order of retrieved chunks to ensure the most relevant ones are presented to the LLM. They experiment with DLM-based reranking methods (monoT5, monoBERT, RankLLaMA) and TILDE, finding that DLM-based methods, particularly monoT5, significantly improve retrieval accuracy. “We recommend monoT5 as a comprehensive method balancing performance and efficiency. RankLLaMA is suitable for achieving the best performance, while TILDEv2 is ideal for the quickest experience on a fixed collection”

If I’m not mistaken, monoT5 is based on T5, which is an encoder-decoder model, not a decoder-only model like GPT, Claude, etc (Google confirms this, but please correct me if I’m wrong, I have a hard time keeping track of all these models). Hopefully, this is a reminder to check out other kinds of transformers and not just get into the habit of sticking to the currently trendy decoder-only models everywhere. As LLM research constantly demonstrates, higher levels of performance are unlocked with techniques like filtering, preprocessing, and other more traditional techniques (the recent craze for Neurosymbolic AI is another such example)-

If you will allow a tangent, I’m personally interested in a combination of Neural Network and Computational-Biologicaly inspired ideas like Cellular Automata and Self-Organizing Networks. It does some very cool things like this-
Or this (play around yourself here)-
Or this, from “Google’s AutoML-Zero: Evolving Code that Learns” which combines Evolutionary Algorithms with ML-

There is so much to learn, and the myopic obsession with a very narrow field of Deep Learning is not good. Study these techniques, because one of these will form the crux of the next generation of AI. I have barely scratched the surface of Machine Learning and AI, so if you have any interesting work/field of research to share, please do reach out. Even if this newsletter never amounts to anything meaningful, I’d at least like it to be a celebration of some of the cool things that humanity has discovered.
Before you get too angry at me for constantly getting distracted, let’s get back on track. So, we now have a set of contexts ranked by importance. What do we next? Something overlooked but deceptively important.
Repacking: Organizes chunks for optimal LLM processing, considering that the order of information can influence the generation process. They experiment with different repacking strategies and find that placing relevant documents at the beginning and end (“sides” method) yields the best results. Nothing much for me to say there, so let’s move on.
Summarization: Condenses retrieved information to fit LLM input limits while preserving key information. They compare different summarization methods, including:
Extractive Summarization: Select the most important sentences from the original text to create a summary. Think of it like highlighting the key sentences in a long document, and using them to summarize it.
Abstractive Summarization: Generates a concise summary by paraphrasing and synthesizing information from the original text. Think of it like rewriting a long paragraph into a shorter, more concise version.
They find that Recomp, with both extractive and abstractive capabilities, excels in condensing information effectively, but with an interesting caveat-

Next, we will discuss one of the favs, a true hometown hero for the LLM community-
Generator Fine-tuning:
Trains the LLM to effectively use retrieved context for generating accurate and relevant responses. They experiment with different fine-tuning strategies, varying the composition of relevant and irrelevant contexts, and find that fine-tuning on a mix of relevant and random documents improves the generator’s robustness and ability to handle noisy or irrelevant information (go randomness!!).

Since we are talking about Fine-Tuning and RAG, it’s worth bringing up “Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs”. Here the authors explicitly compare Fine-tuning an LLM to RAG to see how well each gets an LLM to learn something new. The results- RAG outperforms finetuning with respect to injecting new sources of information into an LLM’s responses.

I bring this up because I think people often misunderstand the power of Fine-Tuning. They try to use it to force the model to learn new things, which isn’t optimal because trying to counter the information captured in the pretraining with fine-tuning is like trying to put out a Forest Fire by peeing on it. Instead, I think it’s best to use the fine-tuning to teach your model how to navigate the complexities of your specific use-case (generating data in a certain format, navigate inputs etc).
A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.
The authors of our main best-practices paper adhere to this by keeping their fine-tuning focused on teaching the generator to do better with parsing through and recognizing irrelevant contexts (not brute-forcing the learning of the material itself). It’s best to keep the learning/information mainly to the data indexing.
This is important because we have many RAG datasets with conflicting information. A retriever would pull up both contexts, and it’s up to the generator to identify how to reconcile both. A fine-tuned generator that looks to prioritize certain style cues, tone etc might be be key. Otherwise, your generation might get dominated by sources that are engineered to rank highly in AI evaluations as opposed to sources with informational value. This is shown well by the researchers of “What Evidence Do Language Models Find Convincing?”-

To summarize, the best use of Fine-Tuning/Alignment is to use train LLMs to adopt your specs/style and not to teach it something new. Leave the new info updates to RAG, which is much more reliable with this.
That is a summary of the individual points of improvement for RAG. But what about putting them together. Let’s talk about that next.
How to Integrate RAG steps for the Best Results
We learn the following-
“Query Classification Module: This module is referenced and contributes to both effectiveness and efficiency, leading to an average improvement in the overall score from 0.428 to 0.443 and a reduction in latency time from 16.41 to 11.58 seconds per query.
Retrieval Module: While the “Hybrid with HyDE” method attained the highest RAG score of 0.58, it does so at a considerable computational cost with 11.71 seconds per query. Consequently, the “Hybrid” or “Original” methods are recommended, as they reduce latency while maintaining comparable performance.
• Reranking Module: The absence of a reranking module led to a noticeable drop in performance, highlighting its necessity. MonoT5 achieved the highest average score, affirming its efficacy in augmenting the relevance of retrieved documents. This indicates the critical role of reranking in enhancing the quality of generated responses.
• Repacking Module: The Reverse configuration exhibited superior performance, achieving an RAG score of 0.560. This indicates that positioning more relevant context closer to the query leads to optimal outcomes.
• Summarization Module: Recomp demonstrated superior performance, although achieving comparable results with lower latency was possible by removing the summarization module. Nevertheless, Recomp remains the preferred choice due to its capability to address the generator’s maximum length constraints. In time-sensitive applications, removing summarization could effectively reduce response time.”
Based on their findings, the authors propose two distinct recipes for implementing RAG systems:

Of course, a lot of the specific details might change with changed models, data modalities, and query optimizations. However, such research can be a good place to start architecting RAG systems. We’ll do more specific deepdives into specific kinds of RAG in upcoming installations of this series. Let me know if there’s a specific kind of RAG, you want me to cover first.
I’ll catch you later. Peace <3.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819