


Rethinking Generative AI and LLMs with Fruit Flies & Complex Math [Breakdowns]
A Deep Dive into Comply: The Efficient, Bio-Inspired NLP Challenging the Scaling Laws.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
The trajectory of modern Natural Language Processing/Generative AI has been intimately linked with scale. Modern Language Models + massive datasets + unprecedented computational budgets have pushed the boundaries of language understanding and generation. However this has led to models with hundreds of billions or even trillions of parameters, which carry significant burdens: prohibitive training costs, lower transparency, demanding inference requirements, and consequent accessibility issues.
This naturally leads to the very important question- is continuing to feed our Language Models increasing doses of Trenbologna sandwiches really the best idea? Maybe giving away increasing amounts of money to Daddy Jensen and/or the hyperscalers isn’t the best idea long term?
“Comply: Learning Sentences with Complex Weights inspired by Fruit Fly Olfaction” is a very interesting attempt to look for alternatives. This research caught my eye for a few reasons-
It applies various ideas like Sparsity, Complex Numbers, Bio-mimicry. Already I’m a big fan.
Involves bugs that instantly 10xs my interest.
It’s written by one of my favorite members of the Chocolate Milk Cult- Justus Westerhoff- who has had many insightful comments over the years. His presence in our cult has made me a better writer and a much better AI researcher, so to be able to cover his work is very cool.
The results are worth paying attention to- “By incorporating positional information through complex weights, we enable a single-layer neural network to learn sequence representations. Our experiments show that Comply not only supersedes FlyVec but also performs on par with significantly larger state-of-the-art models. We achieve this without additional parameters. Comply yields sparse contextual representations of sentences that can be interpreted explicitly from the neuron weights.”
Between this, increasing shifts on post training, reports of data center buildouts being delayed/possibly cancelled, and the DeepSeek releases, I can’t imagine people who were betting on pure scaling being the status quo are too happy right now-

Here is a more detailed overview of potential impacts, looking at the various angles-

Since you’re on this side of the table, I’m guessing you agree that this research is worth studying. So grab a piece of fruit and some milk, and let’s get nerdy.
Executive Highlights (TL;DR of the article)
Comply achieves something remarkable: capturing word order sensitivity with a fraction of the resources of massive models like BERT, opening up new possibilities for accessible and sustainable AI.
1. Bridging the Gap: Order Sensitivity Without Massive Compute
The Efficiency Bottleneck: Efficient NLP models (like FlyVec) traditionally sacrifice word order, limiting their understanding. Order-sensitive models (BERT, Transformers) demand immense computational power.
Comply’s Bio-Inspired Breakthrough: Comply draws inspiration from the fruit fly’s olfactory system — known for its efficient processing of temporal scent information — to achieve order sensitivity in a resource-light way. The system is visualized below-

Complex Numbers for Positional Encoding: Comply’s core innovation is using complex numbers to encode word position. Imagine each word’s representation getting a “positional spin” in the complex plane, allowing the model to inherently understand sequence. This is fundamentally different from bag-of-words methods.
2. How Comply Achieves Order Sensitivity (Technical Glimpse)
Phase as Position: Word order is encoded by the phase (angle) of complex numbers. Earlier words have different phases than later words, creating a sequential “fingerprint.”
Complex Weights & Phase Preferences: The model learns complex weights, allowing neurons to develop preferences for specific word phases (positions). This is analogous to neurons learning to recognize specific temporal patterns.
Magnitude & Phase-Aware Learning: Comply’s adapted energy function rewards neurons that not only recognize words (magnitude component) but also their correct sequential positions (phase component). This drives the learning of order-sensitive representations.

3. Why Comply Is a Game Changer — Key Advantages
BERT-Level Performance, Pocket-Sized Model: Comply rivals, and sometimes outperforms, BERT on semantic tasks (like sentence similarity and RL), but with only ~14% of BERT’s parameters and vastly reduced computational needs.
Ultra-Efficient Inference: Inference is significantly faster, especially on CPUs and larger datasets (e.g., up to 10x faster than BERT in evaluations), making it practical for real-world deployment in resource-constrained scenarios.
Order Sensitivity Demonstrated: Unlike FlyVec, Comply is inherently order-sensitive. It can distinguish “the cat chased the dog” from “the dog chased the cat,” a crucial ability for nuanced language understanding.
Democratizing Advanced NLP: Comply paves the way for bringing sophisticated NLP capabilities to edge devices, mobile applications, and decentralized systems, moving beyond the reliance on massive cloud compute.

While there is a lot of work to be done to establish this paper as generational, this is a great start with lots of promise. I for one am positively buzzing with the excitement about this paper

We will begin by flying into a small history-biology lesson about the background of this technology.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 2, Overview: Blueprints from Biology — Efficient Coding in the Fruit Fly Brain
To understand the design choices behind models like FlyVec and Comply, we first need to look at their source of inspiration: the fruit fly’s olfactory system. Given that I’m a panchvi-fail in biology, we’ll focus more on computational principles that nature uses effectively over the biological details.
The overarching goal is simple- to see how a biological system achieves complex information processing (identifying smells) with relatively simple components and high efficiency.

The Basic Pathway: From Nose to Decision
Input Layer (ORNs — Olfactory Receptor Neurons): These are the sensors in the fly’s antenna. Different ORNs respond to different chemical molecules. When a smell (a mix of molecules) arrives, a specific combination of ORNs activates.
First Processing Hub (AL — Antennal Lobe): Signals from ORNs go here. Think of it as a pre-processing stage where related ORN signals converge onto Projection Neurons (PNs). A specific smell results in a characteristic pattern of activity across the population of PNs.
The Key Transformation (MB — Mushroom Body): This is the structure most relevant to FlyVec/Comply. The PNs send their signals into the Mushroom Body, connecting to a large number of neurons called Kenyon Cells (KCs).
Output & Learning (MBONs — Mushroom Body Output Neurons): KCs connect to MBONs, which are involved in learning associations (e.g., “this smell means food” or “this smell means danger”).
The connection between the PNs (~50 types) and the KCs (~2000) is where a crucial computational transformation happens:
Dimensionality Expansion: The input signal (PN activity pattern, relatively low-dimensional) is projected onto a much larger population of KCs (high-dimensional). In AI terms, this is like projecting data into a higher-dimensional feature space. Why do this? Often, data that is hard to separate or classify in a low-dimensional space becomes easier to handle in a higher-dimensional one.

Sparse Activation: Despite the large number of KCs, only a very small percentage (less than 5%) become active for any given smell. This isn’t accidental; it’s enforced by inhibitory neurons (like the APL neuron) that effectively raise the activation threshold for KCs. Only the KCs receiving the strongest, most coherent input signals from the active PNs manage to fire. This is not dissimilar to the idea of activation energy in certain kinds of neural networks (and physics too, iirc) where the neurons only get activated if the value crosses a certain threshold. This is also the grounding for ReLU and it’s derivations.
The resulting pattern of activity across the KCs — mostly silent, with just a few active neurons — forms a sparse, high-dimensional code for the specific input smell. This has several benefits from an AI perspective.
Firstly, you can represent many different input patterns (smells or, by analogy, word contexts) using combinations of a few active units out of many, with less chance of different inputs generating the same code (reduced collisions). Essentially, this sparse, high-dimensional code acts like a form of learned hashing. The PN-to-KC network learns to map complex inputs (smell signatures) to sparse “fingerprints” (KC codes). FlyVec directly adapted this idea to map word+context inputs to sparse binary vectors.
This is actually a cool concept that I picked up through my reading- if you’re struggling with separating b/w samples w/ your feature set, sometimes the problem is the dimensionality. Higher-dimensional, sparse feature maps can be good when dense, low-dimensional representations fail. This is why sparse indexes are often used as a first-pass in knowledge retrieval tasks.
Another huge advantage of sparsity (and the one that’s more obvious) — Efficiency. This has 2 dimensions:
Metabolic/Computational: Fewer active neurons require less energy (in biology) or fewer active computations (in AI).
Learning: Learning associations with sparse codes can be simpler and faster, as downstream units only need to pay attention to the few active inputs.
This sets up the first pillar for our information. However, there’s another component, one that’s arguably just as important. Let’s talk about that next.
Beyond “Who Fires”: The Importance of “When”
The story doesn’t end with which KCs fire. The fly’s olfactory system also leverages temporal information — the timing of neural signals:
Input Timing Signatures (ORNs): The initial sensor neurons (ORNs) don’t just switch on or off. They fire with specific time courses — delays (latencies), burst durations, and firing rates — that vary depending on the smell. This means the temporal pattern of the input signal itself carries identifying information, beyond just the set of activated ORNs.
Sequence Sensitivity (Asynchronous Input): Flies can tell the difference between smells arriving simultaneously (like from one source) versus smells arriving with slight delays relative to each other (like from multiple sources). This demonstrates sensitivity to the relative timing or sequence in which components of the input signal arrive. Our system should be sensitive to the order of elements in an input sequence, not just the presence or absence of those elements.
This lays the base of our fly-inspired AI. Since we threw out a lot of terms, I’m going to take a second to summarize our discussion, specifically in content of AI, down below-
Efficient Encoding via Sparse, High-Dimensional Representations: Projecting input into a higher dimension and then enforcing sparsity is an effective way to create distinct, efficient codes for complex inputs. (This is the core principle behind FlyVec).
Temporal / Sequential Information Coding: The timing and order of input signals, and the temporal patterns of neural responses, contain crucial information that goes beyond static activation patterns. Representing and processing this sequential dimension is vital for a richer understanding. (This is the gap FlyVec left and the principle Comply aims to incorporate).
Understanding these two principles sets the stage for analyzing how FlyVec implemented the first, and how Comply attempts to integrate the second using complex numbers.
We’ll take this one step at a time, starting from the OG.
Section 3: Understanding FlyVec for Natural Language
FlyVec aimed to replicate the PN-to-KC sparse coding transformation computationally, applying it to the domain of contextual word embeddings.
Its design choices directly reflect the biological analogy:
1. Input Representation (v in R^(2*Nvoc)): Simulating PN Input
The input vector v represents the information analogous to the pattern of active PNs reaching the Mushroom Body. It concatenates two pieces of information:
Context Vector (First Nvoc dimensions): This represents the surrounding words of a target word. It’s constructed typically by summing the one-hot vectors of words within a fixed-size window (e.g., +/- 3 words) around the target. Critically, this summation creates a bag-of-words representation. The order of context words is lost; only their presence within the window matters.
Target Word Vector (Second Nvoc dimensions): This is a standard one-hot vector identifying the specific word whose contextual embedding we want to generate.

Dimensionality: Nvoc is the size of the vocabulary. The total input dimension is 2 * Nvoc, combining context and target information into a single input signal for the next layer.
2. Architecture: A Single Layer Emulating KCs
FlyVec employs a simple, single-layer feed-forward network.
Weight Matrix (W in R^(K x 2*Nvoc)): This matrix represents the synaptic connections from the “PN-like” input layer to the “KC-like” hidden layer. K is the number of hidden neurons (analogous to Kenyon Cells), typically chosen to be significantly larger than the input feature dimension derived from a single word (Nvoc) but representing the high-dimensional KC space. Each row Wμ corresponds to the weight vector of a single KC neuron μ. These weights are real-valued (ew).

Activation Calculation: For a given input v, the activation aμ of each neuron μ is calculated simply by the dot product: aμ = <Wμ, v> = Wμ ⋅ v.

3. Unsupervised Learning: Competitive Learning and Hebbian Principles
FlyVec doesn’t use standard backpropagation with labeled data. Instead, it employs an unsupervised learning rule inspired by biological principles [Krotov and Hopfield, 2019]:
Goal: Train the weights W such that different input contexts map to distinct sparse activation patterns in the KC layer.
Competitive Learning (Winner Selection): For each input sample v, the network identifies the single neuron μ* that exhibits the highest activation :
μ* = argmax_μ <Wμ, v>
This neuron μ* is the “winner” for that specific input. This implements competition among the KC neurons.
Hebbian Update Principle (“Neurons that fire together, wire together”): Only the weights Wμ* of the winning neuron are updated. The update rule effectively modifies Wμ* to make it slightly more similar to the current input vector v. This is achieved implicitly by minimizing an energy function (Eq. 1):
E = — Σ_samples [ <Wμ*, v’/p> / ||Wμ*|| ]
where v’ might be v or a related vector, and gradient descent on this E w.r.t Wμ* results in an update rule resembling: ΔWμ* ∝ v’/p.
It is worth noting the division by word frequency p and normalization ||Wμ*||, which are crucial practical additions. The former prevents overly common words from dominating the learning process, effectively amplifying the signal from rarer, more informative words. The latter, ensures stable learning by preventing weights from growing uncontrollably, maintaining fair competition among neurons and allowing diverse specializations to emerge. Together, these steps significantly improve the quality and stability of the learned sparse representations.
Effect: Over time, each KC neuron μ learns to respond strongly (i.e., become the winner) for a specific cluster or type of input context+target combinations. The weight vector Wμ essentially becomes a prototype for the inputs it represents.

4. Inference: Generating Sparse Embeddings via k-WTA
Once the weights W are learned, generating an embedding for a target word in context involves:
Construct the input vector v (context + target).
Calculate the activation aμ = <Wμ, v> for all K neurons (potentially after dividing v by p).
Apply k-Winner-Takes-All (k-WTA): Identify the indices I_topk corresponding to the k neurons with the highest activation values aμ. k is a hyperparameter controlling the sparsity of the output embedding (typically k << K).
Construct the final embedding h as a sparse binary vector of dimension K: h_μ = 1 if μ ∈ I_topk, and h_μ = 0 otherwise.
FlyVec’s Pros and Cons:
Strengths:
Efficiency: Extremely fast training and inference due to the simple single-layer architecture and lack of backpropagation through multiple layers.
Simplicity: Easy to understand and implement.
Sparsity: Produces sparse binary embeddings, which can be memory-efficient and potentially useful for downstream tasks or indexing.
Bio-plausibility: The learning mechanism has stronger ties to biological learning rules than standard deep learning, which has generally shown to be a good thing.
Weakness:
Order Agnostic: The most significant limitation, inherited directly from the bag-of-words context representation, is its inability to model word order. “The cat chased the dog” and “The dog chased the cat” might produce very similar context vectors if the window size captures the key nouns and verb, leading to similar embeddings for “chased” despite the reversed meaning.
Fixed Context Window: Relies on a predefined, fixed-size window, potentially missing longer-range dependencies.
Word Embeddings, Not Sentence Embeddings: Designed to produce embeddings for individual words within a context, not directly for entire sentences or sequences.
With this background firmly established, we can now look at how Comply comes in to shake things up.

Section 4: Comply Mechanics — Weaving Order with Complex Weights
Our extension revolvese around capturing the sequential nature of text data through added positional information. We leverage the semantics of complex numbers and keep the same biologically inspired mechanisms, namely sparsity through k-Winner-Takes-All (k-WTA) activations. We aim to preserve the properties of FlyVec regarding efficiency, simplicity, and interpretability. Thus, we constrain ourselves to a single-parameter matrix. Additionally, we focus on an extension that considers a complex-valued input, a single complex parameter matrix W, and a compatible energy function E.
Comply’s central challenge is to incorporate sensitivity to word order into the efficient, single-layer, competitive learning framework of FlyVec. Adding recurrent connections or attention mechanisms would break the architectural simplicity and efficiency goals. Instead, Comply takes a novel approach: modifying the nature of the inputs and weights themselves, moving from the real number domain (R) to the complex number domain C.
Why Complex? You’ll have to ask Brother J for the deets, but I can speculate here. To simplify very difficult math, complex analysis is built around the unit circle. This cyclical nature allows it to adapt very well to phasic data: images, signals, etc.

The way I see it, the phasicness of Complex networks gives them a very different nature to real-valued networks. Their ‘perception of the data’ and subsequent decision boundaries are very different since they are built around the unit circle.
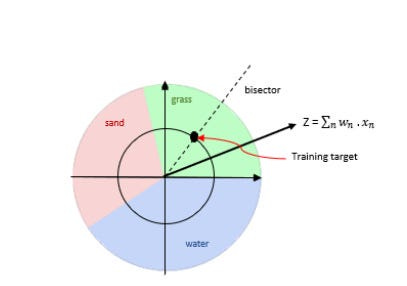
As demonstrated in the excellent, A Survey of Complex-Valued Neural Networks, we see CVNNs thrive w/ periodic, wave-like (phasic) data-

Ultimately, they’re able to encode more information than real-valued data (this is called their expressiveness).
This extra expressiveness is likely what comes in clutch here. Let’s break it down more.

1. Encoding Position with Complex Phases:
The key idea is to use the phase (angle) of a complex number to represent a word’s position within a sentence.
Input Transformation: Consider a sentence S = [word_0, word_1, …, word_{L-1}] of length L.
For each word word_l at position l (0-indexed), start with its standard one-hot vector representation, onehot(word_l) (a vector in {0, 1}^Nvoc).
Calculate a position-dependent complex scalar (a phase rotation):
p_l = e^(i * π * l / L) = cos(πl/L) + i * sin(πl/L)
This maps the position l to a specific point on the unit circle in the complex plane. Specifically, it maps positions to angles ranging from 0 (for l=0) to approximately π (for l = L-1), distributed across the upper half of the unit circle.Create the complex input vector for this word:
zl = p_l * onehot(word_l)
This vector zl is now in C^Nvoc. It’s still effectively a one-hot vector in terms of magnitude (only one non-zero element, with magnitude 1), but that non-zero element is now a complex number whose phase encodes the word’s position l relative to the sentence length L.
Complete Input (z): The input to the Comply model for the entire sentence is the sequence of these complex vectors: z = [z0, z1, …, zL-1]. Unlike FlyVec, which combined context and target into one vector, Comply processes the entire sentence sequence.


Why this specific encoding? This has a few properties hot enough to get the bois singing love songs-
Parameter-Free: It uses a fixed mathematical formula, adding no learnable parameters for encoding position.
Continuous Representation: Maps discrete positions to a continuous (though bounded) space (angles).
Integration with Complex Arithmetic: Phases naturally interact during complex multiplication, allowing the model’s weights to learn phase preferences.
Limitations Revisited:
Length Dependence: The phase p_l depends on both l and L. The same word at position 5 will have different phases in a sentence of length 10 vs. length 20. This implicitly encodes position relative to sentence boundaries.
Potential Phase Crowding: For very long L, π/L becomes small, reducing the angular separation between adjacent positions.
2. Complex Weights (W in C^(K x Nvoc)): Learning Phase Preferences
The model’s single weight matrix W now consists of complex numbers.
Each weight Wμ,j connects input vocabulary item j to KC neuron μ.
Wμ,j = |Wμ,j| * e^(i * Arg(Wμ,j)). It has both a magnitude and a phase.
Interpretation:
|Wμ,j|: Can be interpreted similarly to real weights — the strength of association between word j and neuron μ.
Arg(Wμ,j): This is the new component. It represents a learned phase preference for neuron μ concerning word j. The learning process will adjust this phase based on the typical positions (input phases) of word j in the sequences that maximally activate neuron μ.
Parameter Count: As previously noted, storing K * Nvoc complex numbers requires 2 * K * Nvoc real numbers, exactly matching the parameter count of FlyVec’s R^(K x 2*Nvoc) matrix.

3. Interaction via Hermitian Inner Product:
To calculate the interaction between a neuron’s weights and an input word, Comply uses the Hermitian inner product. For neuron μ and input word zl (which is non-zero only at index j corresponding to word_l):
⟨Wμ, zl⟩H = Σ_k conj(Wμ,k) * zl,k = conj(Wμ,j) * zl,j
= conj(Wμ,j) * p_l * onehot(word_l)_j
= (|Wμ,j| * e^(-i*Arg(Wμ,j))) * (e^(i*πl/L)) * 1
= |Wμ,j| * e^(i * (πl/L — Arg(Wμ,j)))
The result is a complex number:
Its magnitude |⟨Wμ, zl⟩H| = |Wμ,j|, representing the strength of the weight connection.
Its phase Arg(⟨Wμ, zl⟩H) = (πl/L — Arg(Wμ,j)) mod 2π, representing the difference between the input position’s phase (πl/L) and the neuron’s learned phase preference (Arg(Wμ,j)) for that specific word j.
Pretty neat, huh?
4. The Comply Activation Score (Eq 5): Combining Magnitude and Phase Difference
This is the core calculation determining which KC neuron “wins” for a given sentence z. The score for neuron μ is summed over all words l in the sentence:
Score(μ, z) = Σ_l [ |⟨Wμ, zl⟩H| + |Arg(⟨Wμ, zl⟩H)| ]
Let’s break down the contribution of a single word zl (corresponding to word_j at position l):
|⟨Wμ, zl⟩H| = |Wμ,j|: The magnitude contribution depends only on the weight strength for the specific word j present at position l.
|Arg(⟨Wμ, zl⟩H)| = |(πl/L — Arg(Wμ,j)) mod 2π|: The phase contribution measures the absolute angular distance between the input phase πl/L and the learned weight phase Arg(Wμ,j). This value is between 0 and π.
Why + |Arg(…) | ? The Drive Towards Phase Opposition:
The learning objective aims to maximize this score for the winning neuron.
Maximizing |Wμ,j| encourages the neuron to associate strongly with specific words (like FlyVec).
Maximizing |(πl/L — Arg(Wμ,j))| encourages the neuron to learn phase preferences Arg(Wμ,j) that are maximally different (ideally, π radians apart) from the typical input phases πl/L of the words it responds to.
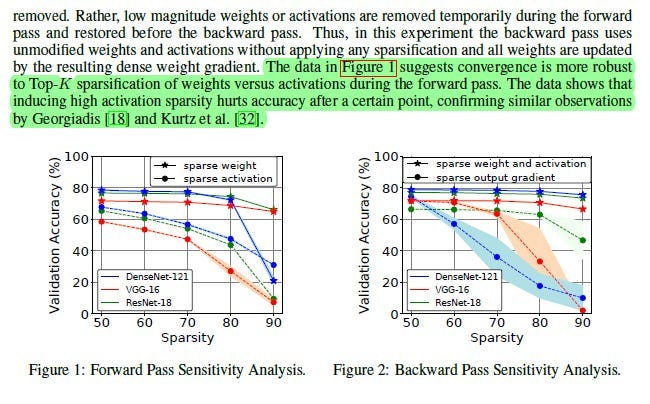
Since input phases πl/L are in [0, π), maximizing the absolute difference pushes the learned weight phases Arg(Wμ,j) towards the lower semi-circle [-π, 0). This creates a separation between input and weight phases, potentially simplifying the learning landscape or creating more discriminative representations. Figure 3 confirms this empirically — learned weights end up in the lower half-plane.
Combined Effect: The winning neuron μ will be one that not only recognizes the constituent words of a sequence (high |Wμ,j| sum) but also has learned internal phase preferences Arg(Wμ,j) that align coherently (in maximal opposition) with the specific positions l of those words in the input sequence (high |Arg(…)| sum). It learns to recognize sequence motifs.

5. Sentence Embedding via k-WTA (Eq 6):
The final step mirrors FlyVec but operates on the sentence-level scores:
Calculate Score(μ, z) for all K neurons.
Select the k neurons with the highest scores.
The output h is the K-dimensional sparse binary vector indicating these top-k winners.

This vector h represents the entire sentence z, implicitly encoding both its lexical content and word order through the selection of neurons sensitive to specific sequential patterns.

Comply thus achieves sequence modeling capability by fundamentally changing the mathematical domain (real to complex) and adapting the learning objective, all while preserving the efficient single-layer, competitive learning structure and parameter count of its predecessor. This elegant integration of positional information is its defining characteristic.
Absolute giga chad stuff here. So how do the results stack up? Very well (otherwise I wouldn’t be covering them). Let’s touch on them-

Section 5: Comply’s Performance — Key Experimental Highlights
The paper has a whole bunch of evals, but I really need to sleep b/c I’m travelling again tomorrow, so here are 3 that I really liked
Matching with BERT on Semantic Tasks: The most compelling result is Comply’s performance on standard Semantic Textual Similarity (STS) and Pair Classification (PC) benchmarks (Table shared earlier). Despite possessing only ~14.6% of the parameters (~16M vs. ~110M) and using a simple single-layer architecture trained unsupervised, Comply achieved scores competitive with, and in a majority of cases (7/13 tasks) exceeding, the bert-base-uncased Transformer baseline. This demonstrates that for judging sentence-level semantic relatedness, Comply’s method of encoding sequence via complex phases can be remarkably effective, challenging the notion that only massive, deep attention-based models can achieve high performance on such tasks.
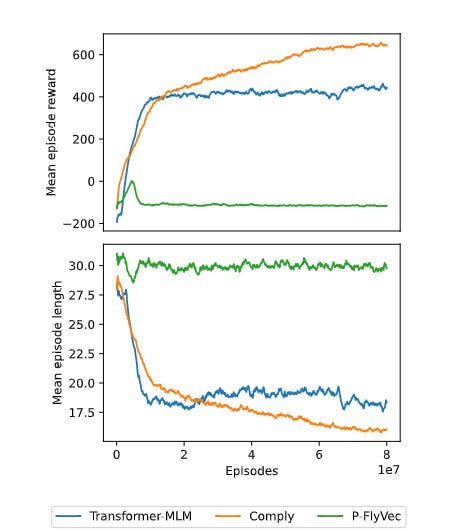
Demonstrated Value of Positional Encoding (vs. FlyVec & RL Success): Comply consistently and significantly outperformed its order-agnostic predecessor, FlyVec, on nearly all STS/PC tasks. This directly validates that the complex-phase mechanism successfully integrates crucial sequential information. The starkest evidence comes from the DDxGym Reinforcement Learning environment (Figure 6). Comply learned effectively and surpassed a Transformer baseline, while P-FlyVec completely failed. This dynamic task, requiring understanding of sequential textual descriptions, definitively shows that Comply captures temporal dependencies essential for complex interactions, a capability entirely absent in FlyVec.
Quantified Computational Efficiency: Underpinning the performance results is Comply’s resource frugality. Beyond the drastically lower parameter count compared to BERT, inference evaluations (Table 1) showed Comply to be significantly faster, particularly on CPUs and larger datasets (e.g., ~10x faster on TwitterURLCorpus than BERT on a V100 GPU). While training time per epoch might be slightly longer than highly optimized real-valued implementations due to complex arithmetic, the overall pretraining compute is vastly lower than for large Transformers. This efficiency makes Comply’s performance achievements particularly noteworthy.

All in all, this is worth getting excited about.
Final Thoughts and Closing
Comply offers a compelling alternative vision for efficient NLP, demonstrating that sequence information can be effectively captured without the immense computational cost of mainstream Transformer models. It achieves 2016 Leicester (or 2018 World Cup Croatia) performance levels, rivaling much larger models like BERT on semantic tasks while maintaining parameter and computational efficiency. This success, particularly its demonstrated ability to handle sequential dependencies in reinforcement learning where its predecessor failed, validates its novel approach and makes it worth further research.
While Comply represents a significant step, further research is essential. Its capabilities need validation across a broader range of tasks and modalities, and potential limitations regarding long sequences or scalability require investigation. Translating this research into practical, deployable tools- a hurdle that marks the grave of many promising ideas- is also a necessary next step.
Whether it passes or fails, I hope Comply encourages more researchers to explore novel directions in AI to spark some creativity in a field that’s desperately searching for its next breakthrough. I hope to see more such work that looks to actively rethink the foundations of our current AI systems to think about where to go next.
For whatever my opinion is worth, get yourself the best milk Justus. You deserve it.
Thank you for being here and I hope you have a wonderful day,
I make all my relationships complex for science,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Thank you so much for the feature, awesome read! Considering that I barely told you anything and almost simply sent you the arxiv link, I am very impressed by your understanding (which also proves that the paper can't be written too badly :D). Looking forward to.give Comply even more future!
Great one!