


What Investors and Product People Should Know about DeepSeek Part 1: Correcting Important Misunderstandings [Markets]
Is the DeepSeek-induced Stock Market Sell Off blind panic, or will it be the beginning of the end?

Hey, it’s Devansh 👋👋
In Markets, we analyze the business side of things, digging into the operations of various groups to contextualize developments. Expect analysis of business strategy, how developments impact the space, conversations about current practices, and predictions for the future.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
This article is the product of a lot of great conversations. I can’t name you all individually, but a special thank you to my friends Eric Flaningam and Andrew Gillies. Both of you always ask very challenging questions and have the sharpest insights, and it forces me to be better. I’m lucky to be friends with you. I owe both of your heads big slobbery smooches for all the ideas you’ve given me.
Ever since DeepSeek dropped their reasoning model R1, a lot of people have been trying to figure out how it will impact the AI markets. The immediate reaction within the USA Markets has been panic and bearish b/c-
DeepSeek’s Cheap training costs and use of older GPUs raise an important question- have we been overestimating the value of GPUs in training AI?
If anyone can replicate models, what builds loyalty? Especially given the performance of distillation- which lets smaller models copy more powerful ones for a fraction of the costs; leading to nasty price wars in the LLM space- it seems like LLMs are bound to become commodities with low margins.
What does it say about the USA’s geopolitical position if people can replicate their research for peanuts?
As you might imagine, this hasn’t led to a very positive outlook on the market-

Executive Highlights (TL;DR)
In this article, I’m going to cut through the noise to help you understand the following important questions-
Is this reaction justified? : That’s a nuanced question. GPUs are overpriced and overrated in the short-medium term, but in the long time, they will be justified by an increase in cloud computing usage (which GPUs can also help with). So, I don’t think they’re a terrible bet in the long run. Whether the value capture goes more to pure hardware players (Nvidia and Co.) or to Hyperscalers (AWS, Google Cloud etc) depends on a few factors. I believe it will go toward the former, based on a more ruthless and aggressive culture.
Why people would pay for model APIs when OS Models are free: There’s a huge cost to hosting and deploying LLMs yourself. Paying for Model APIs, especially when they’re as cheap as they are, is often a better deal.
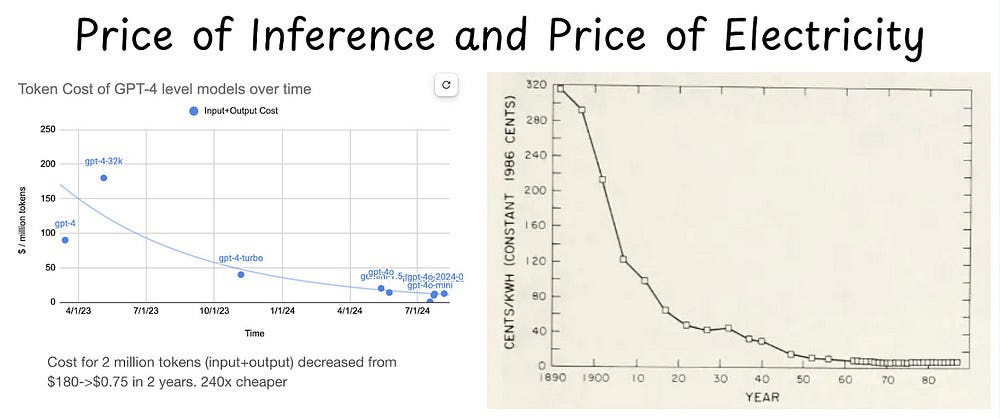
Does DeepSeek show us that there is no moat in Models and Algorithms?: Yes, but that’s irrelevant. Moats don’t matter for LLMs (or any disruptive startups).
Does Distillation Spell the End of Research?: Even assuming distillation perfectly transfers abilities and robustness (very dubious claims, especially the latter), I don’t think Distillation removes competitive advantages. The very act of pushing boundaries and exploring ideas is deeply meaningful (even from a results perspective) and the failures can give you deep insight into what will work in the future. Distilling models does nothing for that, and investing heavily into distillation assumes that model architectures will continue to be the same as they are right now (that is a bold thought, given research trends). Due to that, I don’t think that Distillation challenges power-structures as much as people are claiming.
This is a special article, so it will be structured in a special way. We will first elaborate on all the answers to the above questions by exploring the various misunderstandings people have around DeepSeek and its implications on the AI Model Markets. I will also have an appendix, which will further explain some important ideas related, but not strictly necessary to answer the above questions.
We will also do part 2 of this article, focusing on How LLM Providers will make money if techniques like Distillation can wipe out most performance deltas b/w leading and smaller models. Make sure you keep your eyes out for that.
If all of that interests you, keep reading. First, let’s answer question 1 in more detail.
Are GPUs and Cloud Providers Cooked?
Is the reaction justified? ehhh. By and large, I think Nvidia is a very overrated company. As I’ve reiterated a few times, you really don’t need stacks of the newest GPUs (or often any GPUs) to build useful AI for people. The number of people spinning up racks and buying servers was definitely unnecessary. From that perspective, it feels like a correction, and it could even drop further. For up to the next 5–7 years, I think they’re overpriced.
Using the dataset described herein, the AI model takes a few hours to train on a single NVIDIA-V100 graphics processing unit. The exact wall time depends on how often validation is done during training. We use 50 validation steps (every 1,000 batches), resulting in a 10-hour train time for the full global model.
-Google’s Floodforecasting System was trained with almost nothing, and it’s saving lives
The longer-medium term is where things get very interesting. The hyperscalers choosing to buy GPUs now are making a bet that overall cloud consumption (not just AI) will increase, which I believe is a pretty reasonable bet-
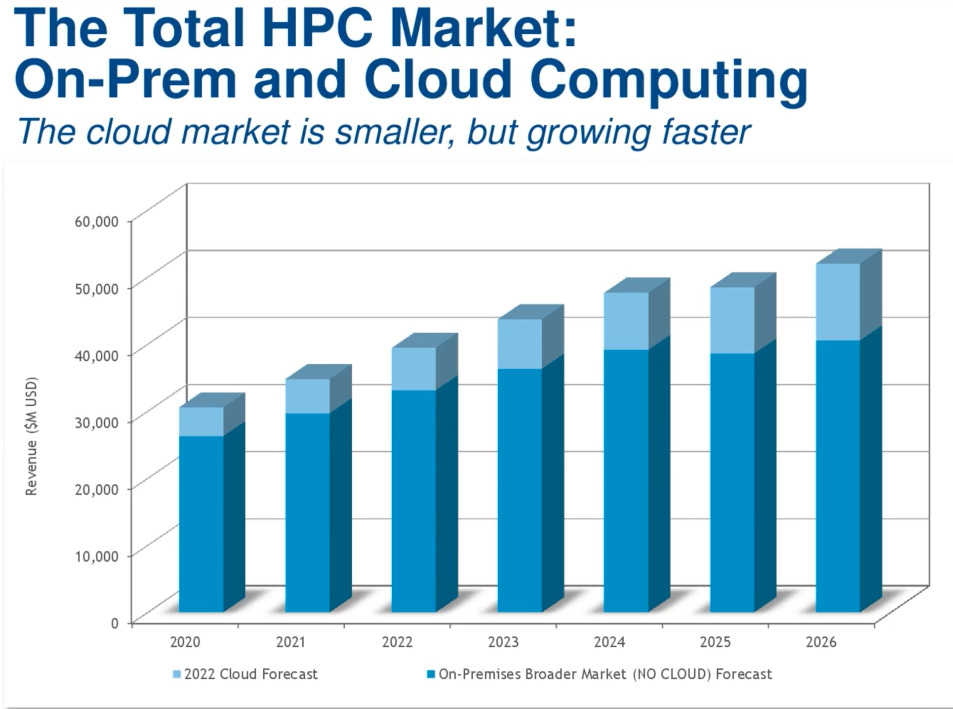
Here, you have two competing forces- the hyperscalers buying GPUs and their investments into their HPC (which will get them some vertical integration). Depending on how they compete against each other- one would expect the value to swing either toward the hardware providers or toward the Hyperscalers.

I don’t know enough about the technicalities of this, but from my several conversations within these groups- Nvidia seems to have a better killer instinct and culture. The fundamentals still seem to skew toward hyperscalers, so pick your poison based on what you think is more important (I’m personally biased towards Culture, especially given that Nvidia does have the paper and team to push). I’m still studying this space, so I will refrain from many strong comments.

Long term, I have nothing helpful to say except that infrastructure layers tend to have the slowest changes. Whoever wins the medium term will likely have a huge advantage in retention. However, this might become outdated as time progresses (the principle stays the same, but new tech might make switching infra on the cloud much easier). I’m not an Ops person, so all my understanding of this space comes from my adjacency and conversations with various people. I’m more than happy to be schooled on this topic.
However, people are getting a lot wrong about how this will impact the space. To appreciate the true implications of DeepSeek, it is first helpful for us to understand some common misunderstandings related to the whole situation. Here are the major ones-
Correcting what People are Getting Wrong About DeepSeek
Misunderstanding #1: Why DeepSeek cracked the code to efficient Reasoning Models
Let me ask you a question: Why is DeepSeek the group that cracked the code for better models? Not how (we will do a separate follow-up piece here on the interesting technical decisions made by DeepSeek to attain their high performance in a lot more detail), but why they were the ones to accomplish this?
The way I see it, it’s not because DeepSeek has a bunch of geniuses or they’ve done something revolutionary (their techniques mostly existed prior). It’s not because their HR department is cracked at hiring (although if they decide to hire me, I might retract this statement). Instead, DeepSeek won at reasoning b/c their competitors are bogged down by 3 misaligned incentives-
Time Trap: Many research teams are forced to deliver results on a consistent cadence. This forces them towards something more stable scaling (which is more predictable) as opposed to risking their time on something riskier (which will lead to better results but has a lower chance of working out). DeepSeek, which doesn’t have the same pressure from investors/hype vultures, has been able to spend more time putting things together to see what works.
Status Trap: Management leading AI groups will often try to increase their budgets/spending as a way to signal importance (Timmy’s group spent 2 Billion on training an LLM → I’m going to get a tattoo of Timmy on my chest b/c he’s so cool). Things like GPUs used, Headcounts, or Money spent, can act as a proxy for importance (leading to promotions)- and so many managers are incentivized to push towards scaling and not pursue other alternative paths.
Ego Trap: LLM companies have had to eat their own dogfood. Even if Gemini is objectively better, OpenAI will only use GPT to generate synthetic data for their new models. DeepSeek had no such qualms (one of my first impressions using it was that it seemed GPT-esque, and now reports seem to indicate that it was trained heavily from GPT).
These 3 traps increase costs and reduce model performance. DeepSeek isn’t really bound to any of them, so it has been able to focus on quality while maintaining efficiency.
It’s also worth remembering that DeepSeek is in China (cheaper labor and most other resources + looser IP), which drives down costs in ways that might not be replicable in the West.
Lastly, I was also given access to some interesting reports (from some very credible sources that I trust) that estimate the cost of DeepSeek being many, many times higher than reported (I’ve asked for permission to share it here, will share if they say yes). This is not something I know enough about to comment on, but I think it’s worth thinking about.
Misunderstanding #2: Open Sourcing Models will not destroy AI Model Margins
People love to act like the presence of the Open Source DeepSeek will destroy margins since people will just download and use it instead of paying for the existing models.
Yes because-
Online courses and the education industry are not massively profitable gigs since people can read everything on Wikipedia.
Restaurants and Fast Food are not real because everyone can cook their own food.
This newsletter is written by my ghost. The real Devansh actually starved to death because his newsletter/consulting business mainly focused on publicly available research.
Services as an industry is a lie created by the communists to undermine the natural self-reliance of Americans.
Why buy cars when we have legs (or wheelchairs) to take us wherever we need to go?
Adam Smith was tripping balls when he wrote about the benefits of division of labor. Surely, people would instead save that money and do things themselves.
Companies can pull OS models for free. But companies don’t get paid to do this. They get paid to build products. And building on top of the OS Model in a way that’s secure and stable requires heavy investments (talent, storage, compute costs…). AI Model Companies can save money by doing this in bulk (an idea called economies of scale). For an organization, to go through the hassle is a significant burden, and might not even lead to cost-savings. This dynamic gets worse when you consider that this investment of money and (often more importantly) a lot of time could’ve been invested into other opportunities-

That’s why I often recommend that my enterprise clients stay away from hosting their own models despite my strong ties to the Open Source community. The ROIs of OS models are much lower than you’d think when you start accounting for all the work that we have to do to set them up.
For proof, look at Meta. They stayed out of this mess since they don’t have a cloud business like Amazon, Google, or MS. The money they would make from providing inference would take away from their mission. It’s much easier to give Llama away, let the community improve it, and fold it back into their moderation systems/use it to unlock efficiency in other ways.

Before we close that tangent, if you’re in learning more about how companies profit from Open Source- both by using them and sharing their work Open Source- then this article will be your jam. It got a lot of positive feedback, and contains this beautiful picture of our GOAT-

Misunderstanding #3: Algorithmic “Moats” mean nothing in Gen AI
With the rise of DeepSeek, I’m sure you’ve all seen allusions to Google’s Letter about Foundation Model companies having no moat-

To keep it real: it’s both true and also completely irrelevant. Algorithmic moats don’t matter now, nor will they matter in for a long time in the future.
When it comes to startups (the stage Gen AI is currently in), algorithmic moats are a made-up concept by investors and venture capitalists so that they can pretend to have critical thinking skills. It’s a non-existent phenomenon so that people who have never built anything meaningful can congratulate themselves for pretending to ask intelligent questions.
This is for a simple reason- moats are static advantages that are hard to replicate (money, supply chains, wisdom from years of building things and servicing customers,…). Moats help most when playbooks are well-established. Startups are, by their nature, on the edge of things- hoping to disrupt the status quo. The more disruptive a startup is, the less we know about what works and what doesn’t. A very disruptive startup is going to change the battlefield, not enter a preexisting one.
It’s not surprising that VCs look for moats. Despite their marketing, many VCs are risk-averse folk who are always looking to copy each other’s playbooks to ensure more stable, predictable returns. The “we invest in 1000 teams that will shake up the world, so who cares if 999 go bust” is more of a branding exercise than a lived philosophy-

We don’t know as much about Generative AI as people like to think/pretend they do. Worrying about Moats at this stage is useless.
The disruptive-ness of building startups is also why I don’t think resource differences matter as much for startups. The money you spend is logarithmically related to the actual results you attain (and that, too, is a very mean, ugly, your mom-looking log). You have to spend a lot of money to brute force your way into building a good startup product.
On the other hand- startups should grow exponentially, with every investment massively compounding returns. The way to accomplish this isn’t scale or imaginary moats. It’s the speed of iteration. You need to get real feedback as quickly as possible, identify what people resonate with, and pivot accordingly. Startups don’t need a secret sauce algorithm that no one can copy (that’s more of a Hollywood concept). They need the ability to listen to the market, read b/w the lines from feedback, filter out the noise- and make the most essential 2 changes (as opposed to 10 mediocre ones).
This is a principle I’m willing to bet time and money on. As a matter of fact, I already did. Some of you know my Legal AI startup- IQIDIS. Here are a few interesting things about it-
We got into a market with massively well-funded startups: Harvey (USD $206M raised), Paxton (USD $28M), and Leya (USD $36M), etc.
We also had to keep an eye on Foundation Model companies.
Both mean we had no “moat.”
We also didn’t have the millions of dollars to compete (although if any of you have a few milli that you’d like to give me for my contributions to humanity, I would appreciate it).
I also openly shared a large chunk of our research on this newsletter: how we process documents, our Knowledge-Intensive RAG, and How we build Agents (by what is undeniably pure coincidence, Harvey AI started talking about the importance of Agents and Legal Workflows a bit after my article on the same went mini-viral), etc. This should have further reduced our already non-existent moat.
Instead, our bet is simple- the CEO and advisors are all elite lawyers who understand what lawyers need. And I’m good enough to build what they need without being distracted by the passing fads. We bet that these two factors would combine to give us a much faster iteration speed than our competitors (who are not lawyer-led). The result? We get emails like this almost daily (3 different users within the last 4 business days)-



One of our power users, an attorney who has experience with many Legal AI products, even put us above the competitors (all of who supposedly have moats)-

And our users are constantly referring us to other lawyers, unprompted-

All in all, we had over 2K inquiries into purchasing our paid products just in January. All from word-of-mouth growth (0 USD spent on outbound marketing). It’s gotten so out of hand that we’ve decided to raise some funding to be able to keep up with the demand and onboard everyone who wants to buy IQIDIS for their firm months ahead of originally planned (devansh@iqidis.ai, if you’re interested).
But yes, moats matter b/c you heard from someone you know that Warren Buffet said he likes moats. Remind me what technical moats Facebook or Amazon had when they first started, again?
Misunderstanding #4: R1 is not as Revolutionary as you think.
For the most bit, this is not as revolutionary as you’d think for some reasons-
Firstly, the API Price wars have been happening for a while. Google Gemini Flash 1.5 8B is absurdly cheap and fast, gives solid performance for most tasks, and should be a lot more mainstream. But it suffers the misfortune of being a Google Model, so most people barely know it exists as Google’s highly incompetent Developer Relations team is busy trying to impress everyone by copying thinking models-

What cracks me up about the Flash 1.5 models is that they are distilled (one of the techniques that got DeepSeek so much attention). They did everything DeepSeek did before DeepSeek did, except for focusing on the their AI models comms on the right things.

I bring up Gemini Flash 1.5 (and not 2) for a reason. A very important one. Let’s table it for one teeny moment to explore another thought chain.
DS did do some interesting work making the reasoning model cheaper. And as a tech guy, that’s awesome (which is why we will do the deep-dive focusing on the technicalities). But I want you to take a step back and think about how much that really matters. In my experience, while discussions about increasing model capabilities are very impactful, the more important discussion revolves around the question, “How much intelligence is too much intelligence”?
Let’s say we do have a reasoning model. What do you want to do with it, that you couldn’t do before?
I’m currently in this weird space where I’m both inside a lot of the top circles (through this newsletter) and outside them (my projects are mostly in the finance, Legal, and Government spaces- all high-value but low-tech groups). You’d be shocked how much value there is to be captured from integrating techniques like good document processing, automation scripts, embeddings, and simple QA.
When Advanced Tech people talk about tech, they often talk in terms of what it might be able to do in the future. However, when many end users talk about it, they talk about it in terms of what they can do with the tech right now. That’s a very important difference, and one that’s not appreciated enough in cross-domain conversations.
Take Agents for example. Most Silicon Valley guys talk about Agents in terms of flywheels- you get a bunch of powerful pieces that can do tasks, and you chain them to create high-quality tasks done at scale. However, in practice, most (working and profitable) implementations of Agents that I’ve seen are relatively simplistic, focusing on a few details. Tasks that can mostly be done with simpler, less powerful models (there are a few exceptions, but the most major exceptions are less common than you’d think; and said exceptions require specialization)

Following the implications of this thought chain to a reasonable conclusion, we learn the following: most use cases for AI models don’t require heavy-duty reasoning models to match performance. A lot of the silicon valley hype behind reasoning models is priced on promises of future abilities, not current ones.
Lastly, given the interesting research that hints that best practices with these models might be diverging from standard models, the opportunity cost of switching away from them acts as an additional barrier in sticking them in willy-nilly.
Let’s bring back our earlier thought chain. Combining 1 (cheap models and efficient inference have existed for years) and 2 (most use cases don’t need reasoning models), we should see something something interesting-
DeepSeek making a reasoning model cheaper isn’t as revolutionary as the markets are pricing.
Yes. it’s cool, and adds to more competition. But it’s not that different to what we’ve been seeing so far.
Those are the major misunderstandings that I’ve found in my various conversations on DeepSeek. Next, I want to give you an appendix of important related ideas, that you can skip if you are super busy, but will be helpful in contextualizing this and other developments in Deep Learning and LLMs. They are-
How researchers are paid to scale (why so many Foundation Model Companies have been relying on scaling, despite many warnings on the “S-Curves” and diminishing returns on it.
Some challenges companies have when hosting and deploying their own LLMs.
Why Cutting-Edge Research is hard (why resources don’t matter there as much as engineering). In my mind, building a startup is a lot like Applied Research, so it helps to understand this.

Let’s end by talking about them.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Appendix 1: Why Generative AI Loves Scaling
Put simply, Scaling saves you when creativity has abandoned you-
In plain English, if you’re a GP (general partner) in a venture capital fund and couldn’t pick winners if your life depended on it — looking at you, General Catalyst and billionaire CEO Hemant Taneja — what do you do? You build an empire.
Because, as VC bros love to remind us, once you reach a certain size (and yes, size does matter):
2% is bigger than 20%
Translation: If you suck at picking innovative companies, your incentive shifts from generating returns to amassing assets. The bigger the asset base, the bigger the 2% management fee.
- Sergei is a beautiful genius, and you should absolutely read his work. He has a lot of elite insights on Health Tech. Same principles applies for us.
Scaling is a very attractive option for corporate research b/c it is everything that middle management dreams about: reliable- you can estimate estimated performance returns on fixed timelines; easy to account for- you know how much it will cost; non-disruptive-it does more of the same; and impersonal- unlike more specialized setups which might require specialized experts to setup, scaling can be done by (relatively) anybody (read more about this here).
This directly also feeds the incentives for researchers who get paid to scale through-
Bonuses Tied to Publishing Quickly/More : Many researchers are compensated for publishing more research. This leads them to pursue approaches that will allow them to get published more often: taking pre-existing published research in their desired journals, making incremental changes to it, and publishing that (it’s the research equivalent of the common social media advice to copy what’s trending in your niche). Scaling is one of the easiest “incremental changes” we can pursue, so a lot of researchers go down that route.
Layoffs: Many research teams are tied to big tech companies, which are tied to quarterly reviews. This can put a lot of pressure on researchers, who are expected to deliver results for the quarterly (and sometimes even shorter time-frame) reviews. In such a case, researchers will prioritize paths that will ensure they won’t get fired, not paths that will most likely fail but have a small chance to shake things up completely.
Public Perception: Pivoting away from an architecture/setup into something completely different is perceived by some people as a failure, both internally and externally. This can prevent research teams from pushing for major changes in their work, relying on scale to take their product to the next level.
Who pays the bill: Put bluntly, most researchers don’t pay for their experiments (no skin in the game is a bad setup). Thus, they have nothing to lose when they push for scaling. This becomes especially pronounced in big tech, where teams can be very disconnected from the business side of things (and not all tech people actively try to understand the economics of their employers/teams). LLMs also compound this problem since their random behavior and diverse abilities make ROI calculations very difficult. In this case, scaling to make the capabilities “better” becomes an easy way to keep filling up the time-sheet.
Citations & Prestige- Papers about scaling get way more citations since they’re easier to build upon (just do the same thing but bigger!). More citations are considered to be a very good thing, so more people will participate in scaling-based research in hopes that their work will be referenced in other works. For example, I often heard certain “Deep Learning Experts” on Twitter making posts like- “don’t go into Computer Vision, NLP has much better prospects”. A similar mentality is often applied to the research direction, where researchers consider career prospects over other factors-
Grant Money- Big scaling projects are easy to explain to funders. You can point to clear numbers and say “we’ll make it bigger!” It also has clearer deliverables and timelines, two things investors stick on their favorite body pillows. It’s much easier to estimate the costs of scaling (not accurately, but you can estimate it)- which makes it a much easier sell when compared to a very experimental idea that no one can really predict.
Ease of Understanding: On a technical level, scaling is easier to justify and explain since it’s less novel. Somewhat counter-intuitively, this is a plus when getting buy-in both internally and externally (a reviewer would be more hesitant to sign off on accepting a paper into a prestigious journal if it’s pushing something very new (read unproven)). If I want to push a project through, I’m probably going to have an easier time pushing scaling through.
By avoiding this trap, DeepSeek was able to save a lot of money.
Appendix 2: Costs of running Free OS Models
Yes, downloading the Open Source model is free. But working with them is very expensive. Here are some factors you have to account for:
Their inference. This can become a huge problem if you have to process multiple concurrent users since streaming LLMs on your end will be much slower than calling LLMs from a provider.
Storage.
The talent required to manage them properly. Just hiring 1 engineer (to deply LLM locally) and 1 researcher (to look through information) can put you back USD ~30K a month. Let’s say 10K to say that the duo only spend a third of their time on this. Even here, you have to run 10s of Millions of Tokens (even 100s of millions, depending on the model) to break even on the direct investment (not even the opportunity cost).
Liability.
Ongoing maintenance.
Switching if something much better comes around.
Consider that the next time some tube light tells you that Open Source Models are free to Run.
Appendix 3: Why Research is Hard
In actual research, you’re not just solving a known problem — you’re discovering what the real problems are as you go along. This creates a unique set of challenges that make research particularly demanding and expensive.
Recursive Uncertainty:
Each breakthrough typically reveals new layers of complexity we didn’t know existed. Solutions often require solving prerequisite problems that we only discover along the way, and the path forward frequently requires backtracking and rebuilding our foundational understanding. In science, we’re all a bit like Jon Snow, who knows nothing. We trudge along, clinging to our limited knowledge, only to occasionally (or frequently if you’re me) learn that knowledge we were absolutely confident about is completely wrong.
For an example close to home, think back to the research around Batch Sizes and their Impact in Deep Learning. For the longest time, we were convinced that Large Batches were worse for generalization- a phenomenon dubbed the Generalization Gap. The conversation seemed to be over with the publication of the paper- “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima” which came up with (and validated) a very solid hypothesis for why this Generalization Gap occurs.
numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions — and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation.
There is a lot stated here, so let’s take it step by step. The image below is an elegant depiction of the difference between sharp minima and flat minima.

Once you’ve understood the distinction, let’s understand the two (related) major claims that the authors validate:
Using a large batch size will create your agent to have a very sharp loss landscape. And this sharp loss landscape is what will drop the generalizing ability of the network.
Smaller batch sizes create flatter landscapes. This is due to the noise in gradient estimation.
The authors highlight this in the paper by stating the following:

They provided a bunch of evidence for it (check out the paper if you’re interested), creating what seemed like an open-and-shut matter.
However, things were not as clear as they seemed. Turns out that the Gap was the result of LB models getting fewer updates. If a model is using double the batch size, it will by definition go through the dataset with half the updates. If we account for this by using adapted training regime, the large batch size learners catch up to the smaller batch sizes-
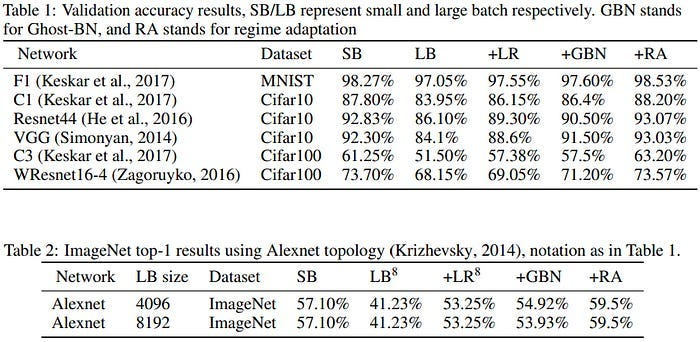
This allows us to keep the efficiency of Large Batches and while not killing our generalization.
This happens a lot in Research, where learning something new only leaves us with more questions or makes us question what we thought we knew. For example, learning about the boundary between trainable and untrainable neural network hyperparameter configurations being fractal only left us with more questions about why this happens and what we can do with this-
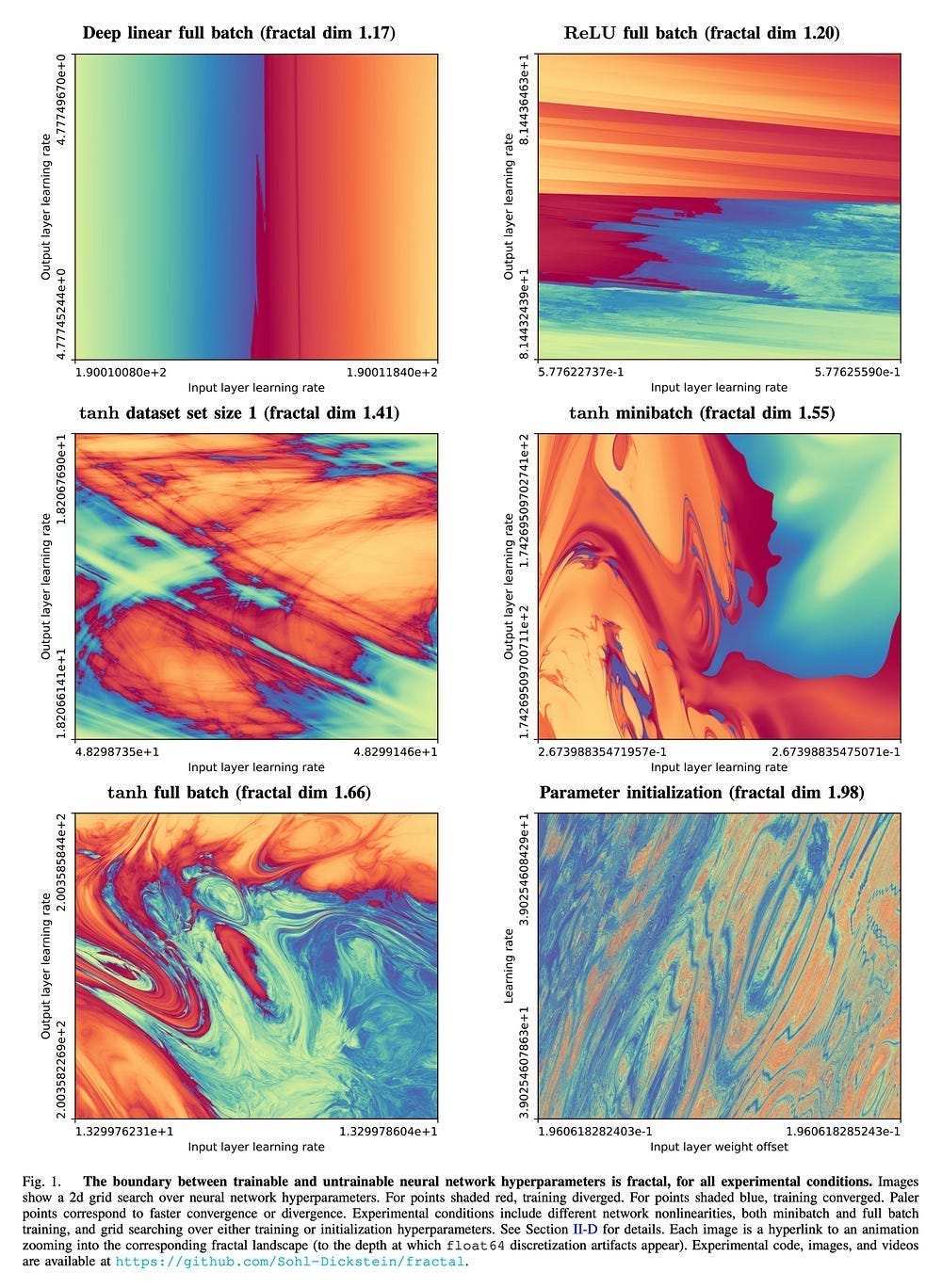
Good research starts trying to answer questions but often leaves us with more questions than before. This can lead to a very costly tax-
The “Unknown Unknowns” Tax
In cutting-edge research, we often don’t know what we don’t know. This makes initial cost and time estimates inherently unreliable. Success criteria may shift as understanding evolves, and the most valuable discoveries sometimes come from unexpected directions.
This uncertainty creates a tax on research efforts — we need to maintain flexibility and reserve capacity to pursue unexpected directions, even though we can’t predict in advance which directions will be most valuable. This is why 80–20’ing your way into scientific breakthroughs is so hard and why stories like Edison trying 1000 iterations of the bulb are common amongst inventors/scientists.
The Tooling Paradox
One of the most expensive aspects of cutting-edge research is that researchers often need to invent new tools to conduct their experiments. This creates a “meta-research” burden where significant time and resources go into creating the infrastructure needed even to begin the primary research.
Researchers frequently find themselves needing to create new measurement methods to validate their results and develop new frameworks to interpret their findings. This double layer of innovation — creating tools to create discoveries — adds substantial complexity and cost to the research process. If you’ve ever looked at LLM benchmarks, been frustrated at how badly they translate to your use-case, and created your own set of evals- then you know this pain well.
Non-Linear Progress Paths
Research doesn’t follow a predictable linear path. Instead, it typically involves multiple parallel explorations, most of which won’t pan out. Teams often pursue seemingly promising directions that end up being dead ends, while unexpected discoveries might require pivoting the entire research direction. Even progress often comes in bursts after long periods of apparent stagnation. This was one of the reasons that we identified for why Scaling was so appealing- it seemed to offer predictable returns in an otherwise unpredictable field.
Compared to software engineering, science requires very long cycles, which can include months of research before committing to an approach, and extensive analysis to understand the outcomes of experiments.
-Dr. Chris Walton, Senior Applied Science Manager at Amazon.
This non-linear nature makes it particularly challenging to manage and fund research effectively, as traditional metrics of progress don’t capture the real value being created during exploratory phases.
Communication Overhead
Problems are inter-disciplinary, experts often are not (especially with the extreme specializations these days). Experts from different fields often lack a common vocabulary, and different disciplines have different methodological assumptions. Bridging these knowledge gaps requires significant time investment, and documentation needs are much higher than in single-discipline research.
These reasons, and many more, make research a uniquely difficult process. Misunderstanding/underestimating the challenges in this space often leads to organizations where scientists and management are at odds with each other (hence the stereotypical stories of the scientists with their heads in the clouds researching non-issues or the constant depiction of management that shuts down funding for a scientist before their big breakthrough).
Hopefully, this gives you more clarity on the DeepSeek situation, and how it will impact the markets. Let me know what you think about it.
Thank you for being here and I hope you have a wonderful day,
Chocolate Milk Fiend,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
👏👏
“I can read anything I want on Wikipedia”…
Yes anything the one party state allows
https://www.lifenews.com/2025/02/03/wikipedia-blacklists-all-conservative-media-outlets-prevent-any-from-being-cited/