
How Scaling became a Local Optima in Deep Learning [Markets]
A look into why Scaling became the default method for performance improvement in Deep Learning

Hey, it’s Devansh 👋👋
In Markets, we analyze the business side of things, digging into the operations of various groups to contextualize developments. Expect analysis of business strategy, how developments impact the space, conversations about current practices, and predictions for the future.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Recent conversations around LLMs seem to have taken a huge turn when it comes to scaling. Leading LLM Labs have been allegedly struggling with going forward- with reports on both OpenAI and Google allegedly struggling to push their models GPT and Gemini to the next level.
If you’ve read my piece, “Is it Really Over for LLMs”- you know that I believe that there is a lot of work to be done with LLMs, both in building solutions with them as a part and in reimagining core components of LLMs to address key issues. I was planning to cover both through our upcoming series on Agents and “Rebuilding LLMs on the Ground Up” respectively. However, to address all these, it’s first important to understand why we rely on scaling as the go-to for AI research. W/o first understanding the incentive structure that lead to incentives- discussing the path forward will be useless.

Executive Highlights (TL;DR of the article)
Before we get into the incentives for scaling, let’s take a second to discuss what scaling is. The way it’s mostly used, scaling refers to the act of doing more of the same, prioritizing exploitation over exploration. This is reflected in either prioritizing more data, using higher quality data, and/or increasing the size of your model by reusing/adding existing blocks.

Philosophically, scaling makes a key assumption- we should take a leap of faith and double down on the zigging instead of zagging (one thing AI Researchers don’t have is commitment issues. The many cult of personalities and fervent idol worship in Silicon Valley is clear proof of that). This is how we will be using it. If you have any disagreements w/ my usage, I encourage you to share them. Discussions and debates are how we all grow. But for now, let’s move on.
Contrary to what some people would have you believe- there’s no shadowy cabal that’s manipulating the space, pushing Deep Learning and suppressing all other paths. The truth is (IMO) a lot more interesting. Scaling wins because it perfectly fits how big organizations (especially corporate research) operate. Since Deep Learning Research has been increasingly pushed by companies, it’s not surprising that it has taken on the characteristics of the industry.
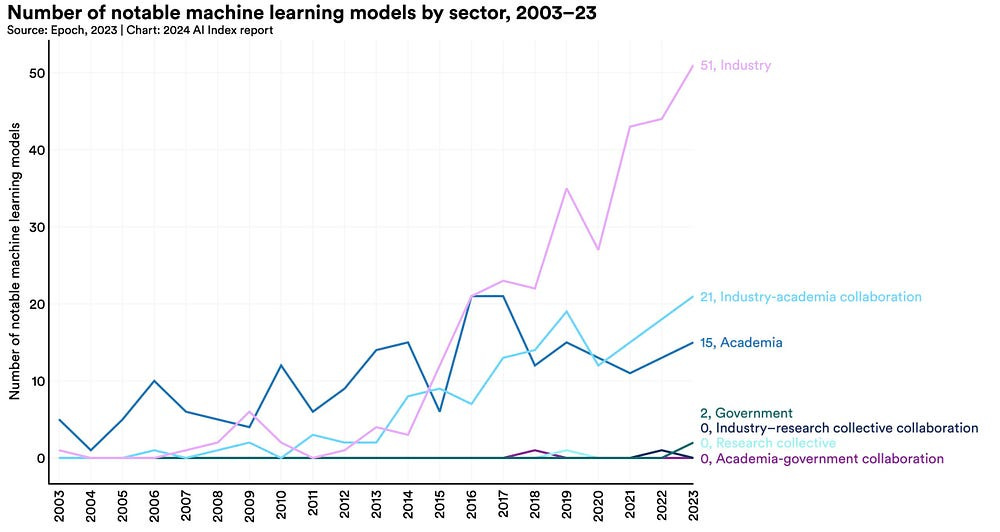

Scaling is a very attractive option for corporate research b/c it is everything that middle management dreams about: reliable- you can estimate estimated performance returns on fixed timelines; easy to account for- you know how much it will cost; non-disruptive-it does more of the same; and impersonal: unlike more specialized setups which might require specialized experts to setup, scaling can be done by (relatively) anybody.
It’s kind of like a Conway’s Law but for businesses where business/corporate interest shape the way research is conducted. More specifically we see the following-
Money & Career Incentives: It’s safer for your job (you’re more likely to produce results within before your performance review gets you piped); easier to publish papers about; and the researchers don’t bear the costs of scaling personally (so they have lesser incentive to look for cheaper alternatives).
Research Culture: Scaling reliably improves benchmarks, which makes it a very good match for an academic/research environment where publications are a must. The strong push towards publishing research also causes a flood of trendy papers that ultimately contribute very little (did we really need so many papers with complex math to explain why GPT will always Hallucinate).
Technical Reality: It’s way easier to throw compute at problems than rebuild everything from scratch. This means that even when existing solutions can’t always measure up, there’s a strong tendency to rely on scaling and band-aiding out the mistakes, even when a rebuild could lead to better solutions. Why gamble on an unknown path instead of trying to build something out of what you have already?
Logistical Benefits to Companies: Scaling standardizes processes, making it easier to hire and creating clearer career paths/deliverables. You can also reuse all your expensive infrastructure in other projects if one venture doesn’t work out. Lastly, scaling has also been a big benefit because it’s much easier to acquire more data (now we have synthetic data since LLMs have milked all the internet) than it is to hire people to make the fundamental innovations to get more from pre-existing sources (which also relies much more on expertise, meaning higher labor costs to buy experts).
Market Forces: It’s easy to convince investors that “bigger = better”, which lets you put off pesky little considerations like vision, competitive moats, and paths to profitability. Scale is a good way to kick the can down the road instead of addressing the problems of today (which is why OAI and crew have such a weird obsession with Emergence even though it’s a dubious concept with LLMs- “emergent abilities appear due to the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous predictable changes in model performance.”)
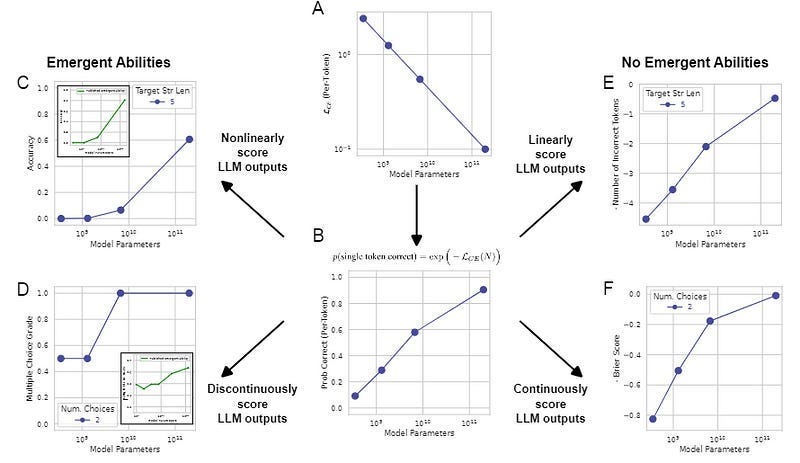
However, from a sales perspective, scaling makes for great marketing (“We hit X trillion parameters!”) AND it can act as a deterrent (“Why spend money trying to compete with GPT if we have to Billions training to get to their scale”). Scaling also ties into the arms race where LLM providers are trying to become the go-to platforms and capture public mind-share early This is similar to the strat Google to become our default browser by being better years ago- maintaining market share even though there are now as good (or even better) search engines on the market.

This strong set of pressures creates a self-reinforcing cycle- incentives get more people to start scaling→which causes more demand for scaling related employees/resources → new people entering the space are more likely to see this and specialize towards scale → we have more scale oriented resources → people attempt applying scale to more places → repeat.
Usually, I would end with solutions to fixing this, but here, I don’t really have any. Ultimately, this is a problem caused by a system where failure is really not an option. Researchers must keep hitting deliverables- whether it’s publications or benchmarks in constantly shrinking timelines (the number of people that are freaking about not getting GPT-5 this year in insane. I’m no OpenAI apologist, but freaking out over this is a but delusional and childish).
Until we change our relationship with research and “failures” in research, I think we’ll keep finding ourselves back to scaling as the de-facto approach b/c it’s safe. A lot of people talk up the 80–20 rule, but overlook a key fact- we only know what 80% works after going through all the failures and trial and error. Research is important b/c it helps us identify these failures and build on them- but this requires time, effort, and creativity. I’m concerned that we will lose these in our pursuit of efficiency at all costs.
Let’s understand the pressures in a bit more detail-
For decades, artificial intelligence (AI) research has coexisted in academia and industry, but the balance is tilting toward industry as deep learning, a data-and-compute-driven subfield of AI, has become the leading technology in the field. Industry’s AI successes are easy to see on the news, but those headlines are the heralds of a much larger, more systematic shift as industry increasingly dominates the three key ingredients of modern AI research: computing power, large datasets, and highly skilled researchers. This domination of inputs is translating into AI research outcomes: Industry is becoming more influential in academic publications, cutting-edge models, and key benchmarks. And although these industry investments will benefit consumers, the accompanying research dominance should be a worry for policy-makers around the world because it means that public interest alternatives for important AI tools may become increasingly scarce.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
How Researchers Get Paid to Scale
The incentive/compensation structure for Researchers drives them to pursue scaling.
Bonuses Tied to Publishing Quickly/More : Many researchers are compensated for publishing more research. This leads them to pursue approaches that will allow them to get published more often: taking pre-existing published research in their desired journals, making incremental changes to it, and publishing that (it’s the research equivalent of the common social media advice to copy what’s trending in your niche). Scaling is one of the easiest “incremental changes” we can pursue, so a lot of researchers go down that route.
Layoffs: Many research teams are tied to big tech companies, which are tied to quarterly reviews. This can put a lot of pressure on researchers, who are expected to deliver results for the quarterly (and sometimes even shorter time-frame) reviews. In such a case, researchers will prioritize paths that will ensure they won’t get fired, not paths that will most likely fail but have a small chance to shake things up completely.
Public Perception: Pivoting away from an architecture/setup into something completely different is perceived by some people as a failure, both internally and externally. This can prevent research teams from pushing for major changes in their work, relying on scale to take their product to the next level.
Who pays the bill: Put bluntly, most researchers don’t pay for their experiments (no skin in the game is a bad setup). Thus, they have nothing to lose when they push for scaling. This becomes especially pronounced in big tech, where teams can be very disconnected from the business side of things (and not all tech people actively try to understand the economics of their employers/teams). LLMs also compound this problem since their random behavior and diverse abilities make ROI calculations very difficult. In this case, scaling to make the capabilities “better” becomes an easy way to keep filling up the time-sheet.
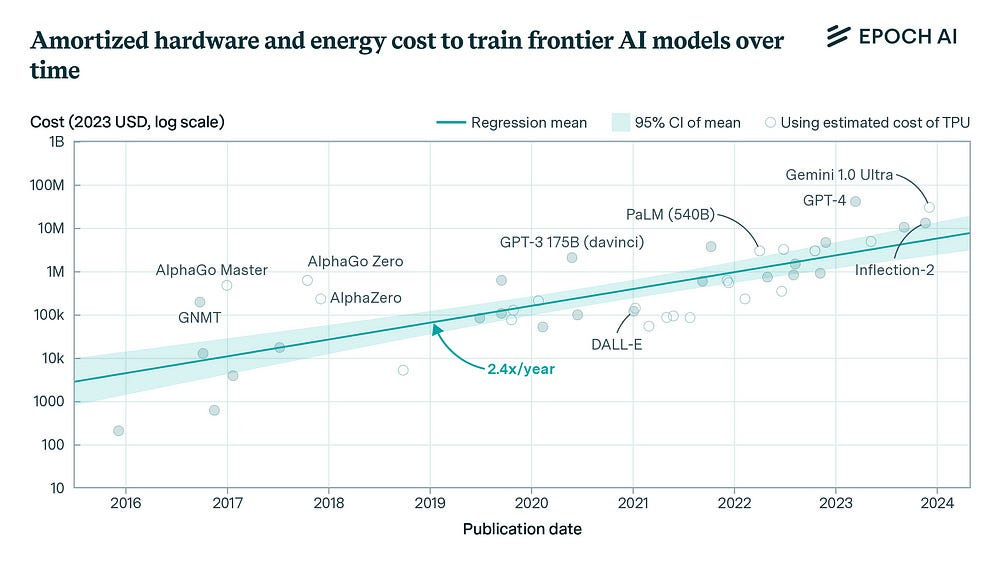
Citations & Prestige- Papers about scaling get way more citations since they’re easier to build upon (just do the same thing but bigger!). More citations are considered to be a very good thing, so more people will participate in scaling-based research in hopes that their work will be referenced in other works. For example, I often heard certain “Deep Learning Experts” on Twitter making posts like- “don’t go into Computer Vision, NLP has much better prospects”. A similar mentality is often applied to the research direction, where researchers consider career prospects over other factors-

Grant Money- Big scaling projects are easy to explain to funders. You can point to clear numbers and say “we’ll make it bigger!” It also has clearer deliverables and timelines, two things investors stick on their favorite body pillows. It’s much easier to estimate the costs of scaling (not accurately, but you can estimate it)- which makes it a much easier sell when compared to a very experimental idea that no one can really predict.
Ease of Understanding: On a technical level, scaling is easier to justify and explain since it’s less novel. Somewhat counter-intuitively, this is a plus when getting buy-in both internally and externally (a reviewer would be more hesitant to sign off on accepting a paper into a prestigious journal if it’s pushing something very new (read unproven)). If I want to push a project through, I’m probably going to have an easier time pushing scaling through.
The desire to get quick, reliable wins is made worse by the very interesting arms race going on right now-
The LLM Arms Race
As mentioned earlier, the LLM providers are in an arms race to lock in our mind’s share. Once they get that sorted, it will be much harder to switch out of their ecosystem. Once you’re using the LLM, you might also be more likely to buy other products- using Gemini might have me building on Google Cloud, which will be a huge revenue boost. One thing people often overlook in the discussions about the unit economics of LLMs is that LLMs themselves don’t have to be a hugely profitable venture if they can be used to cross/upsell other offerings. In this case, they just have to not lose heaps of money- which can be accomplished through various techniques.
Scaling is the LLM Provider’s way of standing out. Scaling is a powerful way to max out benchmark performance (or atleast reliably improve on it), which is why the LLM providers use it so heavily. The hope is that scaling now, will build market share for the future (and prevent competitors from taking it in the future).
In a sense it’s similar to the data center play, described by investor Eric Flaningam below-

I don’t really buy this assumption (I’m generally very skeptical of benchmarks used in LLMs given how poorly they’ve translated IMO). But the providers aren’t known for their spine- so this is what the current MO is.
Next, let’s cover the engineering pressures for scaling (that are not strictly performance-related)-
Technical Pressures for Scaling
Sunk Costs: Teams are often hesitant to switch out of existing solutions after they have already spent significant costs to build them. Why abandon a million-dollar solution that works 90% of the time for something that might not work as well and will have to be rebuilt? Existing Solutions become a kind of local optima, and researchers get stuck there, not unlike the AI models they train.
Band-aiding: In a similar case to above, if you already have a solution that works well enough in existing cases, there is a strong sensation to try extending that to meet new demands/edge cases- over building somethings completely different (humans have a strong status quo bias). This is one of the reasons why so many “disruptors” somehow end up using the same playbooks (right down to the Steve Jobs turtlenecks). Scaling fits this approach snugly.
Divergence: This is more specific to LLMs, but there is a huge divergence b/w the creators (research scientists at Big Tech), LLM buyers (people building apps on LLMs), evaluators (cheap 3rd world labor), and true end users/evaluators (the people using the apps). This divergence becomes increasingly problematic when we have specialized fields where the simplistic scoring or unspecialized labor don’t adequately capture the nuances. In such circumstances, scaling becomes a de-facto since it’s one of the few ways that you can push things w/ some confidence.
LLMs are Complicated: There is far too much going on with LLMs, and things often break without reasonable explanation. Making major changes can lead to major headaches (Gemini’s weird alignment and/or their MoE constantly saying it can’t do tasks b/c the router misfunctions).

In such a setup, it’s better to keep feeding the monster instead of moving out to something else. You never know what other nightmare you end up with if you change it too much.
Next, we look at how the resources and infra available can push towards research towards scaling.
How Resource & Infrastructure Availability Pushes Scaling
Available Resources: As builders, we often look at resource constraints to make decisions on what paths to follow. The resources required for scaling are more available (especially to these big orgs), easier to account for, and more “generalizable” (I can use a GPU in other work, but not so for a hire that I bought specifically to explore one path that ended being a dead-end). Researchers at these big orgs are also likely to have access to computing prior, which creates a natural tendency to use it, creating a natural pressure for scaling.
Infrastructure Lock-in: Once you’ve dumped millions into GPU clusters and built all your tools around scaling, it’s pretty hard to just pivot away. Plus, you’ve probably got cloud provider deals and whole teams that only know how to do distributed training.
Data vs Innovation: It’s way easier to just throw more data at a bigger model than to figure out how to make better datasets or come up with clever new techniques to extract information. Big models can handle messy data better anyway, so why bother cleaning it up?
We have organizational reasons why we might like scaling in the logistics side, so I don’t have that much more to add there.
As I’ve reiterated many times, there is a lot of non-scaling-related work to be done to improve our current LLM systems. However, I think we will never see a larger push at the bigger organizations to move past scaling due to the pressures mentioned above. The scale-first mentality is a systemic issue, and needs to be addressed at the root (we need to rework research to be more free and willing to venture out into risky failures and dead-ends). I’ve thought for a while about that, but I couldn’t come up with any real concrete steps that can be used to rework the system/incentives there.
If you have any answers, or you feel I’m completely wrong- please reach out. Either way, I’m (always) excited to hear from you.
Thank you for reading and have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
regrettably, this post not just a brilliant and empirically justified analysis/discussion of technical issues associated with (perceived) diminishing returns on 'scaling' - narrowly defined - but a contextually insightful/inciteful argument reminding people how much - and why - economics, culture and institutional inertia matter for understanding/explaining 'innovation trajectories'....i.e, intel had plenty of opportunities to out nvidia nvidia.....'the scaling's falling!!!the scaling's falling!!!' chicken little LLM flock would do well to read and read devansh's posts before broiling themselves....
Nice post, Devansh. Currently writing about the same exact topic. Do you think there is any merit to the claim that AI scaling is moving from training to inference? Reference: https://www.exponentialview.co/p/ev-500