


Are Emergent Abilities of Large Language Models a Mirage? [Breakdowns]
Among the most important questions in contemporary AI.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
Executive Summary-
AI Emergence refers to the phenomenon where LLMs display abilities not present in smaller-scale models. Emergence has two features: their sharpness, transitioning seemingly instantaneously from not present to present; and their unpredictability, appearing at seemingly unforeseeable model scales. This was the cause for a lot of concern and interest. “Are Emergent Abilities of Large Language Models a Mirage?” presents a sobering alternative to the idea of emergence.
…emergent abilities appear due to the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous predictable changes in model performance.
This is proved through 3 kinds of experiments-
Analyzing the impact of metrics on the InstructGPT/GPT-3 family on tasks with claimed emergent abilities;
Performing a meta-analysis of emergent abilities.
Show that by changing the metric, we can show ‘emergent abilities’ in models that didn’t demonstrate emergence before (this one was my fav).

This paper highlights the importance of studying our metrics, and taking a lot of current claims about LLMs with a giant pinch of salt. In my personal opinion, most claims about LLMs and their performance are meaningless, especially when it comes to translating LLMs into business-ready solutions. When it comes to deploying these models- fingertip feel, good design, and judgment mean a lot more than performance on metrics. However (and I stress this), that is my personal opinion, biased heavily by how I’ve built things, and you’re free to disregard this entirely.

Introduction
As 2023 draws to a close, it is safe to say that conversations around foundation models, AGI, and the risks of emergent AI have dominated many headlines around space. Much of the hysteria in this conversation centers around the suddenness of some of the capabilities manifested by AI. Scaling up transformers to sizes comparable to GPT and Gemini led to sudden, unexplainable jumps in performance on a variety of benchmarks. Researchers called this phenomenon emergence, after the biological phenomenon where more complex forms of life manifest new abilities that are not present in simpler organisms.

AI emergence was a huge cause of concern (and hype) b/c it meant that we were likely to create and deploy systems that we are unable to fully analyze, control, and predict. Studying emergence was key to developing more secure LLM-enabled systems. It also provided a source of income to budding sci-fi writers who created some pretty fun campfire speculation about the impending AGI wave and economic reset. Unfortunately, some researchers at Stanford hate Christmas and decided to pour water on the idea of AI emergence. Their research shows that ‘emergence’ is not an inherent property of scaling models, but rather a measurement error caused by inferior metric selection.
In this article, we will cover the 3 sets of experiments to understand their implications in more detail. I’ll end on a note on why I think AI doesn’t exhibit emergence the same way scaled-up biological phenomena do. Before we proceed, a fun piece of trivia about this paper: The Debby Downers at NeurIps had this paper as one of their papers of the year, instead of something fun and whimsy like Microsoft’s Sparks of AGI. I know who I won’t be inviting to our chocolate milk benders.
Let’s get right into it.

Experiment Set 1: Analyzing InstructGPT/GPT-3’s Emergent Arithmetic Abilities
One of the most eye-catching examples of emergence was AI Arithmetic. Language models that can perform computations perfectly are fantastic for handling tabular data or for parsing through documents for higher-level level retrieval. Even basic filtering/computational abilities would add significantly to the market value of such products. The authors make 3 predictions-
Changing the metric from a nonlinear or discontinuous metric (Fig. 2CD) to a linear or continuous metric (Fig. 2 EF) should reveal smooth, continuous, predictable performance improvement with model scale.
For nonlinear metrics, increasing the resolution of measured model performance by increasing the test dataset size should reveal smooth, continuous, predictable model improvements commensurate with the predictable nonlinear effect of the chosen metric.
Regardless of metric, increasing the target string length should predictably affect the model’s performance as a function of the length-1 target performance: approximately geometrically for accuracy and approximately quasilinearly for token edit distance.
“To test these predictions, we collected outputs from the InstructGPT/GPT-3 family on two tasks: 2-shot multiplication between two 2-digit integers and 2-shot addition between two 4-digit integers.”
To analyze GPT-3 on arithmetic let’s peep our boy, Figure 3 (I copied it below, so you don’t have to scroll up). We see emergent abilities if the target has 4 or 5 digits and if the metric is Accuracy (the top of Fig. 3). However, changing from the nonlinear metric Accuracy to the linear Token Edit Distance (while keeping the outputs fixed) we see a smooth, continuous, and predictable improvement in performance with increasing scale (Fig. 3, bottom). “This confirms the first prediction and supports our alternative explanation that the source of emergent abilities is the researcher’s choice of metric, not changes in the model family’s outputs. We also observe that under Token Edit Distance, increasing the length of the target string from 1 to 5 predictably decreases the family’s performance in an approximately quasilinear manner, confirming the first half of our third prediction.”
Onto the second prediction. To accurately measure the models’ accuracy, the authors increased the resolution by generating additional test data. By doing so, they found that on both arithmetic tasks, all models in the InstructGPT/GPT-3 family performed better than random guessing (Fig. 4). This confirms our second prediction. We also observe that as the target string length increases, the accuracy falls approximately geometrically with the length of the target string, confirming the second half of our third prediction.
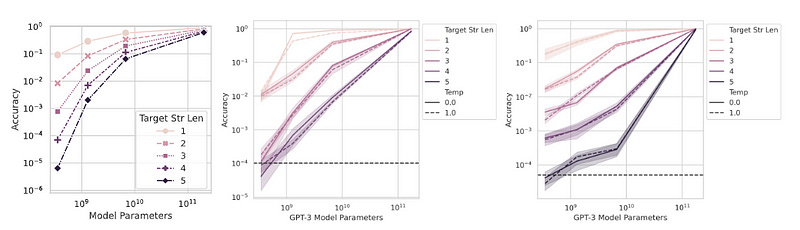
Combined, these tell us that “the researcher’s choice of metric has the effect that one should predict accuracy to have, i.e., geometric decay with the target length.”
Experiment Set 2: Meta-Analysis of Emergence
Next, the authors look into the published results of other models that claim emergence (this is the best they can do coz unlike with GPT, the other models are not queryable nor are their results publicly available). Here, we need to prove two things-
If emergence is real, one should expect task-model family pairs to show emergence for all reasonable metrics. However, if the authors are correct, we will see emergent abilities appear only under certain metrics (nonlinear and/or discontinuous metrics).
On individual Task-Metric-Model Family triplets that display an emergent ability, changing the metric to a linear and/or continuous metric should remove the emergent ability.
To look into the first, the authors tried to quantify emergent ability. By analyzing their results, we see that 2 metrics account for > 92% of claimed emergent abilities: Multiple Choice Grade and Exact String Match. Multiple Choice Grade is discontinuous, and Exact String Match is nonlinear.

Next, we look into the LaMDA family and its outputs are on BIG-Bench. Below are the two parts of Figure 6, which show us that changing the metric when evaluating task-model family pairs causes emergent abilities to disappear:


This is a fairly strong argument against emergence. To tie this up, the authors show us that it is possible to do the reverse- to show emergence in vision models by simply changing the metrics we use for evaluation. This was my fav part b/c thought of some influencer taking this part out of context and claiming that vision models now have emergent abilities made me smile.
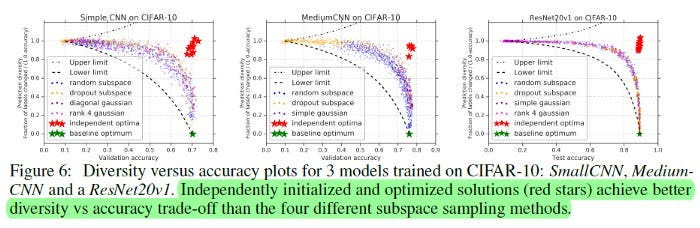
Experiment Set 3: Inducing Emergent Abilities in Networks on Vision Tasks
So far, no one has claimed AI emergence in Computer Vision. Thus, if we can show that simply changing metrics used to evaluate well-known vision models on standard tasks, it would be a very strong argument for the main thesis of the paper: that emergence depends more on the choice of metric than any magical property in scaling.
The authors demonstrate their results on autoencoders, autoregressive transformers, and CNNs. No prizes for guessing the results. For the sake of conciseness, I will show one of their results below-

All in all, a very convincing paper. Let’s end on a brief note about why I think AI emergence has not followed the same jumps as its biological counterpart.
Where AI falls short of Biology
The way I see it, there is a big difference between the scaling up of AI architectures and what we see in nature as organisms become more complex. AI scaling up is quite simple- we add more neurons and blocks in hopes that the additional computation will allow the models to glean deeper (and more complex) patterns about the underlying data. This is where feature/data engineering plays such a crucial role: it guides our AI models. But at their core, cutting-edge AI models are just gigantified versions of smaller architectures.
In contrast, biological scaling up leads to very different organisms. I don’t just have more cells/parts than a crab, I also have very different ones. I don’t have a cool shell or claws, and a crab lacks a liver that I can hit with a beautiful shovel hook. Structure for structure, our brains have a lot more subcomponents/specializations compared to neural networks. As we covered earlier, designing networks inspired by our brain’s bilateral asymmetry leads to better performance.
I’m the last person you should listen to when it comes to anything regarding biology (fun fact about me, I left India when I was 16 just to avoid biology and chemistry). But from what little I can understand, this is a pretty big difference. The lack of specialization has been a drawback and is why techniques like Mixture of Experts or Ensembles tend to do so well.
All in all, I think if we are to develop AI models for the future, it would be worth looking into more decentralized AI architectures that have multiple types of specialized modalities and solutions built in. Then the challenge becomes building a good control structure, that can dynamically call the right kind of sub-structure(s) based on the inputs. This is really difficult, but it’s a much more concrete and clear objective than vaguely defined castles in the sky like ‘AGI’ and ‘human-like AI’. Having more clearly defined goals is infinitely more useful and productive.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
This is a great summary of a frustration I've had in modeling and simulations for years. The biases we code in to our measures are often self fulfilling. I always go into the assumptions of a study and ask, if this assumption weren't true, would the model still work?
If the answer is no, then it's not a good assumption.
Assumptions help to bracket complex problem spaces but if the assumption has a 50/50 chance then it needs to be baked into the model itself, not ignored.
A prime, non-AI example of this are climate models which notoriously make the cloud feedback cycle static. The problem is that clouds are highly dynamic and react to small changes. Of course making them static will show something. If that same somthing dissapears when you allow clouds to be clouds then the finding didn't exist to begin with.
AI suffers the same problems.
This is really great content mate, thanks for adding a spot of considered, well reasoned thought to the wash of panic driven analysis that is around at present.