


Is it Really Over for LLMs? [Thoughts]
A response to Gary Marcus and many other “AI skeptics”

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
A few hours ago, AI Skeptic
released- “CONFIRMED: LLMs have indeed reached a point of diminishing returns,” where he took a victory lap about his claim that LLMs are no longer hitting the same performance gains as they once did. This is in line with his other claims (most famously, “Deep Learning is hitting a Wall”). Marcus based his argument on the following announcement from The Information-
This has gotten a lot of AI Skeptics rejoicing since they can wave around their “I told you so”s. There is just one problem with this claim- it’s wrong. Extremely wrong. And very harmful. My goal in this article will be to talk about why I disagree heavily w/ Gary Marcus’s claim that Deep Learning or LLMs are close to hitting a wall. Instead, I will talk about the various cool ways people are pushing the boundaries of both engineering and research with these technologies to give you a glimpse of how deep these fields are.

Executive Highlights (TL;DR of the article)
To start, I want to emphasize where I do and don’t agree with Gary Marcus. This way, we can ensure that there are no misunderstandings or misrepresentations on my part. Right off the bat, I agree with the following claims-
Scale won’t solve general intelligence- This has been my stance since I started writing. I could point to many cases, but I think the two clearest ones are this article, where I argued that Data (no matter how much/high quality) can never be used to build a comprehensive representation of the reality it models; and this one where I argued that all AI, being based heavily on mathematical reasoning, is limited by Godel’s Incompleteness Theorems (and some other related points). I’m also skeptical of the concept of “general intelligence,” but that’s another story. If LLM groups really have to burn money- my recommendation would be yacht parties or bungee jumping , not constantly scaling up their models(I’ve been told my other suggestion of actually paying data creators is too radical).
We need to diversify beyond LLMs- Another point that we have stressed multiple times, we really need to look beyond LLMs to explore (and celebrate) more research directions. On a related note- trying to push everything into an LLM is bad software design, and not every problem can be solved with this architecture.
The economics of general LLMs are dodgy- This has been true for a lot of Deep Learning products- and again something that I have emphasized many times. I think LLMs would still be economically viable in very high-cost avenues,where productivity gains can justify higher costs, but in most spaces- LLM providers will be fighting for scraps.
Deep Learning has lots of limitations- Due to these limitations, it’s best to pair it with other techniques- especially when control/transparency are at stake. We need to be more careful before deploying in more critical outcomes.
There’s a lot of hype that needs to be addressed. We will create dangerous products if we people keep pushing hype.
In broad strokes, we agree on a lot of things. Here’s where we diverge.
Most majorly, I dislike the reductionist nature of his claims. The statement that “neural networks can’t solve everything alone” is very different from “Deep Learning is Hitting a Wall”.

The former statement is a well-agreed-upon statement by most AI folk (I’ve personally never met/talked to by anyone who claims that only NN+ throwing data is the answer). Even the Universal Approximation Theorem states that a feedforward neural network with a single hidden layer containing a finite number of neurons, using a sigmoid activation function, can approximate any continuous function on a compact set with arbitrary accuracy (not approximate every function). The latter statement implies that Deep Learning research is running out of directions to explore- which is untrue.
Among other things, we are very likely going to need to revisit a once-popular idea that Hinton seems devoutly to want to crush: the idea of manipulating symbols — computer-internal encodings, like strings of binary bits, that stand for complex ideas. Manipulating symbols has been essential to computer science since the beginning, at least since the pioneer papers of Alan Turing and John von Neumann, and is still the fundamental staple of virtually all software engineering — yet is treated as a dirty word in deep learning…
Where people like me have championed “hybrid models” that incorporate elements of both deep learning and symbol-manipulation, Hinton and his followers have pushed over and over to kick symbols to the curb.
—From the above article
I also couldn’t find any real information on Deep Learning suppressing Symbolic AI (this Reddit discussion that shows up, agrees). However, I don’t know a lot about AI History, so instead of commenting there- I wanted to focus on the undertones of ‘Deep Learning is running out of ideas’ or that its success was heavily dependent on feeding in data at scale.
The problem with such a narrative is that it takes away attention from the constantly amazing research pushing the boundaries of Deep Learning in interesting ways (sparsity, using different number bases/domains, Transparency, etc). Instead, it reinforces the faulty notion that DL is mostly about model training instead of building comprehensive systems (which is why we get the scaling bros). It also pushes people away from the field, which would kill innovation in what has been, and will continue to be, an incredibly impactful field of AI research.

The whole “industry is pushing beefy DL everywhere, w/ little respect for other techniques” also feels bad faith, when so many Engineering blogs tend to rely on extensive preprocessing and simpler models-
or call out the un-viability of Huge Models in Production-
We additionally do not utilize GPUs for inference in production. At our scale, outfitting each machine with one or more top-class GPUs would be prohibitively expensive, and on the other hand, having only a small cluster of GPU machines would force us to transition to a service-based architecture. Given that neither option is particularly preferable and that our models are relatively small compared to state-of-the-art models in other areas of deep learning (such as computer vision or natural language processing), we consider our approach much more economical. Our use case is also not a good fit for GPU workloads due to our models using sparse weights
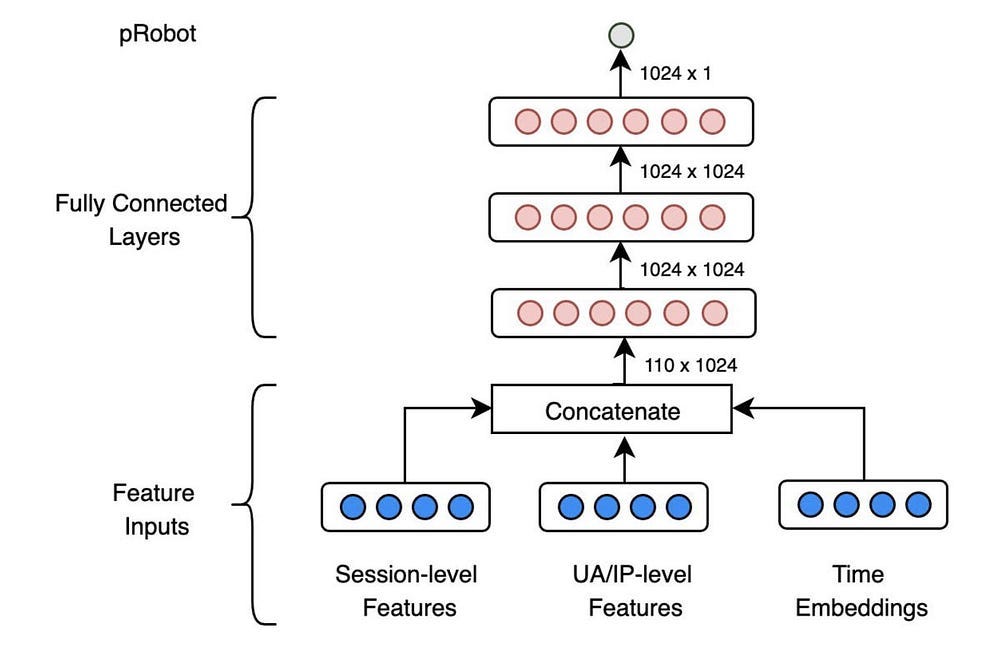
There’s even Deep Learning research that plays around with fundamental architectures without scaling compute. As a neuroscientist, Gary would maybe appreciate “ Deep learning in a bilateral brain with hemispheric specialization,” which takes inspiration from our brain setup to implement bilaterality (two different sub-networks mirroring our left and right hemispheres)into a neural network.
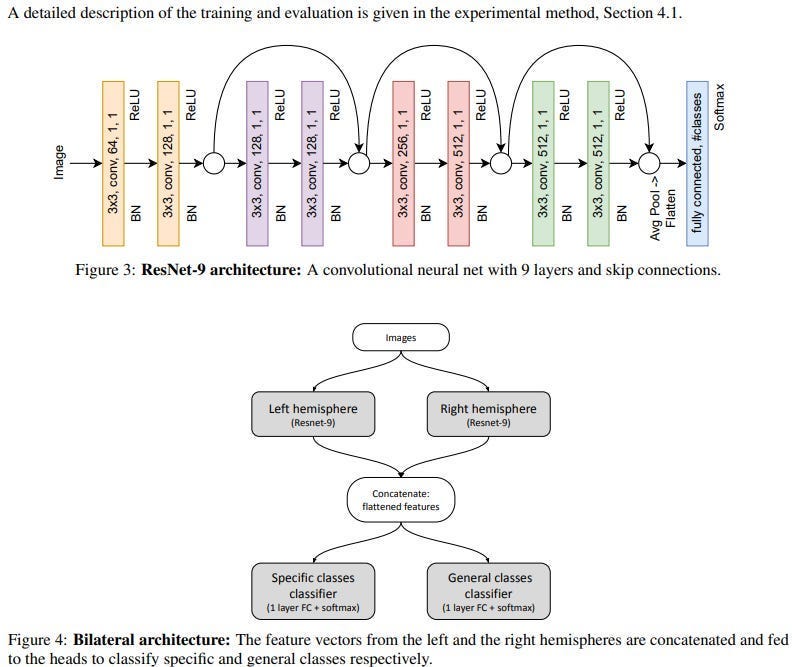
This allows the Network to combine two very different kinds of features-

Allowing it to go blow for blow with larger ensembles-
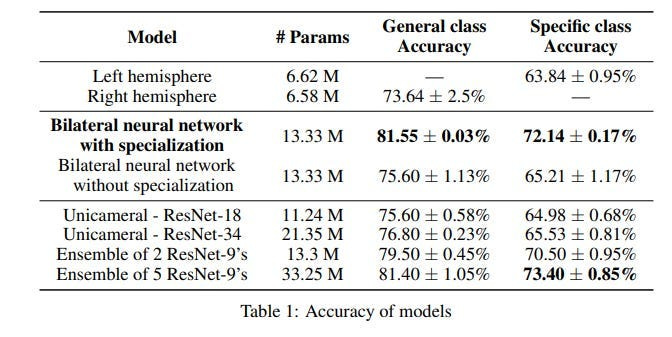
Deep Learning is clearly not hitting a wall. There are lots of great directions to pursue in DL- which seems to be largely overlooked in a claim like “Deep Learning is hitting a wall”.
Yes, we can’t scale infinitely. And yes, it can’t be used to solve everything by itself. Yes, some problems will benefit from the integration of other approaches. But that’s not the same as “hitting a wall”. I don’t even think that’s (DL will fix everything everywhere) a general consensus among the practitioners in the field. A lot of the benchmark saturation/overt fixation on throwing Deep Learning everywhere comes from the bad incentive structures and NOT b/c the researchers genuinely believe that it is the best approach forward. This bad incentive structure is also why every little LLM update gets a dedicated PR release, but something as impactful as Google’s amazing work in global forecasting got no attention-
In “Global prediction of extreme floods in ungauged watersheds”, published in Nature, we demonstrate how machine learning (ML) technologies can significantly improve global-scale flood forecasting relative to the current state-of-the-art for countries where flood-related data is scarce. With these AI-based technologies we extended the reliability of currently-available global nowcasts, on average, from zero to five days, and improved forecasts across regions in Africa and Asia to be similar to what are currently available in Europe.
-How Google Built an Open Source AI to Provide Accurate Flood Warnings for 460 Million People
Bad incentive structures don’t mean that technical progress isn’t happening. Those are two very different problems.
Secondly, Marcus puts a lot of emphasis on the need to go back to the drawing board, off the need for “making fundamental architectural changes”. Imo, this kicks the can down to another, better setup instead of exploring important ways to improve systems right now (not dissimilar to how OpenAI keeps using new terms like Q* and Strawberry to promise that AGI is just around the corner, to avoid dealing with many structural issues with the models today). Constantly emphasizing a better tomorrow won’t cause people to stop using these models today. It will stop them from thinking deeply about how to address the fundamental issues today (for a practical example- check out this piece on how Moral Alignment is used as a smokescreen to not address real issues).
You can get great gains from your LLM-enabled systems by building around their weaknesses without the “fundamental change.” We will touch upon this in the main section.
On a more fundamental level, Marcus doesn’t concretely define his criteria for “a Fundamental Change?” (please correct me if I’m wrong). Is it the integration of other techniques (such as Gary’s beloved Symbolic AI)? In LLM-enabled pipelines, traditional AI techniques like Regexs, Rule-Based Systems + other traditional techniques like Probability Distributions and Clustering are used for data extraction, approximations, feature engineering, and pipeline monitoring.
Is it a reworking of LLM’s most fundamental blocks? There is also a lot of exciting research over there- multimodality, playing with embedding geometry, different learning processes, etc (more deets later in this piece). These are all also being done. Gary, maybe you don’t consider this a promising avenue for growth. Maybe you have better ideas (you’re welcome to share them here). But to act like we have maxed out all the directions for LLMs just b/c we can’t feed in more data to GPT makes no sense.

To reiterate- I would agree if the claim was on the limitations of scale/Transformers/Deep Learning (all ideas we discuss a lot). Or how bad the incentives are. Maybe even w/ arguments on how there were better approaches. But to turn a “there are limits to blindly scaling LLMs” to a “LLMs as a whole are hitting diminishing returns” is a huge stretch.
The problem with GM’s rhetoric is that it only adds to the environment of misinformation. The deniers will cling to these claims and refuse to engage with technology in any meaningful capacity. AI Providers will be very hesitant to take big risks/innovations b/c said Deniers will also gleefully attack every little mistake. Hype bros will continue to let themselves be misled. Very limited actual work. The situation will be quite familiar to certain fans- there will be lots of chest-thumping but no real results. And do we really want to be in the same conversation as them?

As promised, let’s now elaborate on the technical approaches-
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Unlocking High-Performance in LLM-Based Systems w/o Rearranging LLMs
There are 2 fairly straightforward case studies to improve LLM-based solutions without rebuilding the whole thing from scratch.
Neuro-Symbolic AI with AlphaGeometry
Earlier this year, we covered Deepmind’s “Solving olympiad geometry without human demonstrations” over here. It gained a lot of attention for it’s top-tier results in solving Olympiad Geometry questions. This has long been a benchmark for AI systems, and its significant improvement over previous systems (2.5x improvement over SOTA) was impressive-
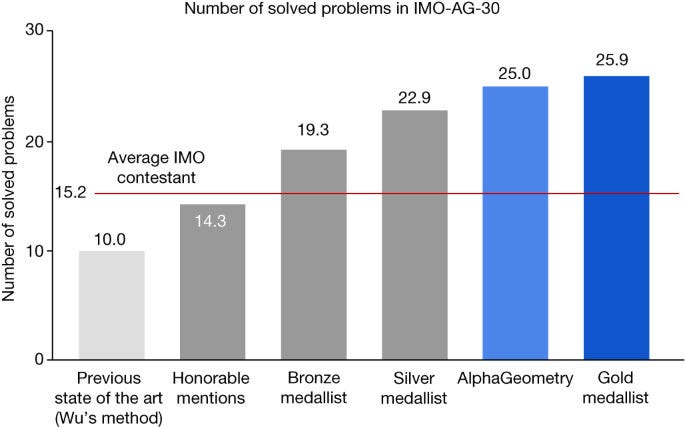
It used an LLM and a symbolic engine in a 2-routine loop. “Given the problem diagram and its theorem premises, AlphaGeometry first uses its symbolic engine to deduce new statements about the diagram until the solution is found or new statements are exhausted. If no solution is found, AlphaGeometry’s language model adds one potentially useful construct , opening new paths of deduction for the symbolic engine. This loop continues until a solution is found.” The process is visualized below:
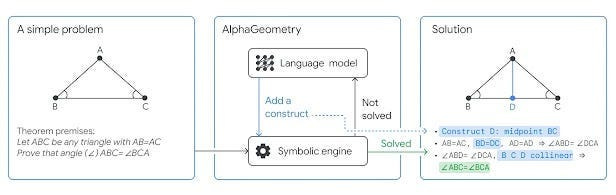
This seemingly simple design is amazing for a simple reason, it leverages the strength of each kind of system while minimizing the weaknesses. As we’ve discussed many times, LLMs are expensive, unreliable, and unexplainable. This is not the death sentence that many doomers pretend it is, but it does mean that we should use them only when none of these three are critical requirements. This meets all the boxes (even hallucinations, which are the topic of much angst, aren’t a problem over here). GOFAI (Good Ol’ Fashioned AI) on the other hand struggles with rigidity, stopping when there isn’t a clearly defined protocol for proceeding. This part is outsourced to the Language Model. They complement each other perfectly.
This design does not try to address the weakness of each system forcefully- instead, building around them by letting another setup handle the weakness. There’s no difficult re-engineering, just good design. Gary himself has appreciated this setup, so it’s surprising to hear him also claim that LLMs are hitting their limits.
Maybe GM is referring to LLMs in a very narrow- GPT 3 style context, but that would be outdated. Most current conversations around LLMs are either around them in Agents or Mixture-of-Experts style setups (MoE is speculated for both GPT and Gemini, AFAIK). Both setups would easily be able to integrate the neuro-symbolic approach (GPT-4 likely is, given it’s visualizations, etc). Yes both (especially Gemini) are fragile and variable, but no tech is error free. To so thoroughly dismiss the future potential of technology based on growing pains seems premature.
LLM as an Orchestrator
When building our Sales Agents at Clientell, our clients often had questions that relied on processing the data (“add up sales performances for this quarter”). Instead of doing things itself, our LLM would call another function that queries and generates reports. Our LLM functioned as the controller, which took a user query and then called the relevant script for a particular functionality-
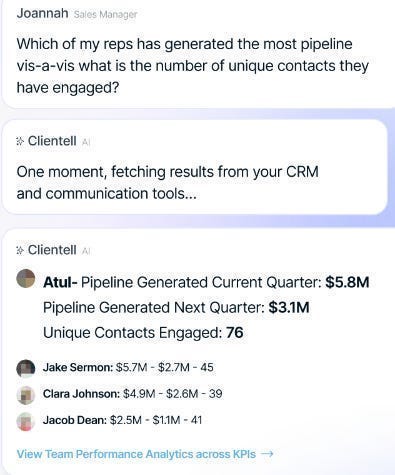
Our LLM barely did any thinking- acting more as a translator whose job was to switch the client query into a series of function calls based on our stored Metadata. Even early versions of GPT 3.5 were fairly good at this, especially since we weren’t in a mission-critical app and some failure was acceptable (our only goal was to improve productivity significantly more than it cost our customers). Present versions of LLMs (even w/ all their weaknesses) are extremely good at this decomposition, so LLMs as orchestrators is generally a powerful and efficient way to build user-friendly and performant AI apps.
What about “going back to the drawing board”? Let’s end on a discussion of some very cool ways people have tried to bring changes to LLMs.
Rebuilding LLMs from the Ground Up
Building up Embeddings Complex Geometry
The complex plane provides a richer space to capture nuanced relationships and handle outliers. For text embeddings, this allows us to address a problem with Cosine Similarity called Saturation Zones- regions where the function’s gradient becomes very small, approaching zero. This can hinder the learning process in neural networks, especially during backpropagation.
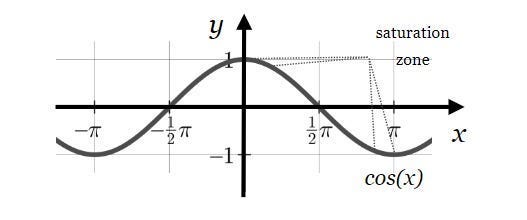
Focusing on angles rather than magnitudes avoids the saturation zones of the cosine function, enabling more effective learning and finer semantic distinctions.

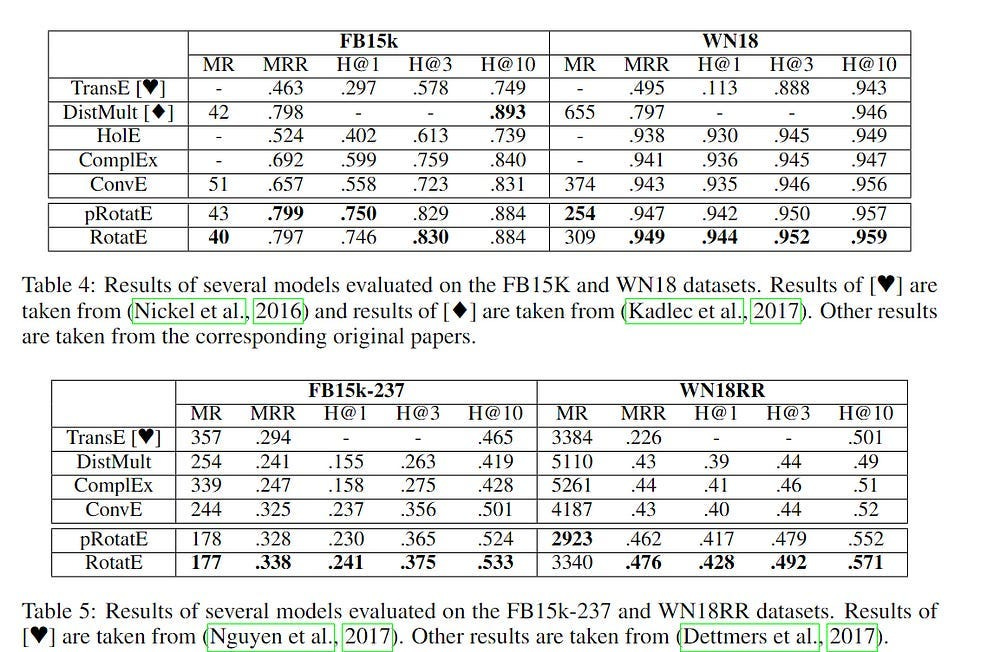
Since Knowledge Graphs are also gaining a lot of attention these days, let’s talk about how we can combine complex geometry with KGs. “RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space” uses complex numbers for knowledge graph embedding. The authors models relations as rotations in complex vector space. We take triplet <h,r,t>(head, relation, tail), which models a relation r b/w h and t. RotatE’s key idea is that the tail entity embedding is obtained by rotating the head entity embedding according to the relation’s embedding.

As you can see this approach allows us to both capture relationships between two entities at once (instead of having to define them individually). This might seem trivial, but I want to bring your attention to two important things. Firstly, this was written in 2019. Second, SOTA LLMs struggle with capturing relationships that are not structured in normal ways and will fail when the structure is very different to their pretraining-
Since RotatE uses Geometry, it doesn’t have these issues. All we need to do is to define the relevant relationships with basic logic-

and then boop the entities on the complex plane. If the angles/relationships b/w them match our predefined rules (if statements), then we know they meet one our patterns-

Both ideas are fairly interesting for a rebuild of embeddings. And that’s not all.
We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately H=0.70. Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can lead to a comprehension of the structure of text at multiple levels of granularity, from words and clauses to broader contexts and intents. We also demonstrate that fractal parameters improve upon perplexity-based bits-per-byte (BPB) in predicting downstream performance.
-Fractal Patterns May Unravel the Intelligence in Next-Token Prediction. To think we’re anywhere close to even finding all the ways we can represent language is arrogant.
Let’s talk about a reinterpretation of the attention by the amazing RWKV Network.
How RWKV Linearizes RNN Attention-
The RWKV LLM is a very interesting architecture that parallelizes RNNs, allowing them to be trained at the same scale as Transformers. However, they maintain massive cost savings over Transformer (self-attention is expensive in Transformers)-
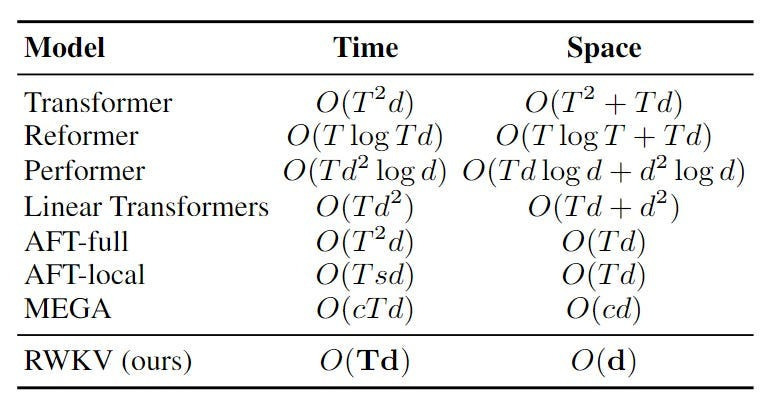
The parallelization is made possible by the following innovations:
Token Shifting: Instead of just considering the current input and hidden state, we also factor in the last input. More information is retained that way, and is a good mitigation of the loss of context that we experience when we compress long sentences into one hidden state with traditional RNNs.
Channel mixing: Acts kinda like a feed-forward layer in Transformers. It takes a weighted sum of the previous and current value and applies the following non-linearity to it:
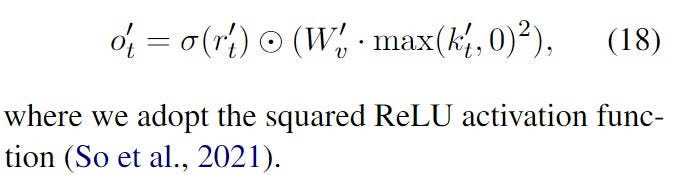
Time mixing is a similar (but more complicated) process. It enables longer-term memory by accounting for both the previous state and learned weights to determine how to combine previous computations and new computations. In the equation below, the yellow highlights give you a weighted sum of all the previous values while the part in red tells you how much to consider the current value.

The time mixing is a very powerful idea, b/c has an interesting advantage over Transformers: unlike Transformers, which have fixed windows, this theoretically can be extended to infinity. Also, since none of the time-mixing equations are non-linear (the non-linearity is added after the block)-
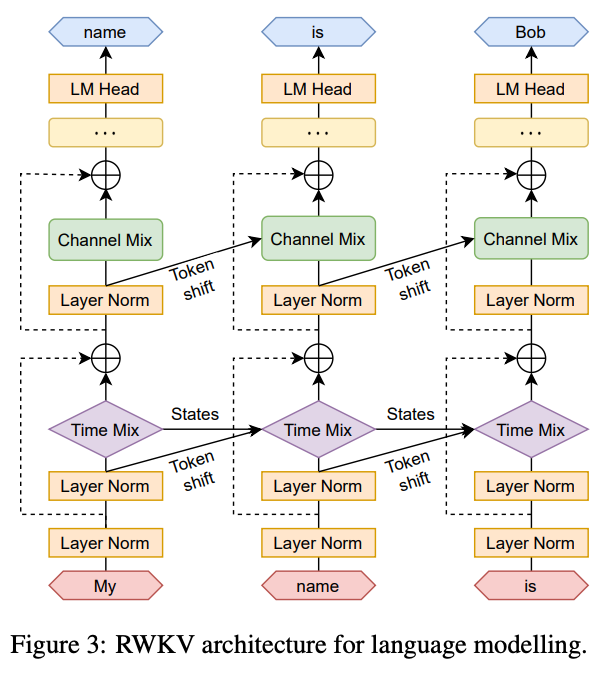
we can parallelize this computation, enabling a much larger scale.
This is not the only way to get efficient inference. The next is my favorite.
MatMul Free LLMs
Our experiments show that our proposed MatMul-free models achieve performance on-par with state-of-the-art Transformers that require far more memory during inference at a scale up to at least 2.7B parameters. We investigate the scaling laws and find that the performance gap between our MatMul-free models and full precision Transformers narrows as the model size increases. We also provide a GPU-efficient implementation of this model which reduces memory usage by up to 61% over an unoptimized baseline during training. By utilizing an optimized kernel during inference, our model’s memory consumption can be reduced by more than 10x compared to unoptimized models. To properly quantify the efficiency of our architecture, we build a custom hardware solution on an FPGA which exploits lightweight operations beyond what GPUs are capable of.
Matrix Multiplication is a very expensive process for LLMs (it’s why GPUs are huge). However, turns out there is a way to build LLMs without them- dramatically increasing our Neural Network efficiency. Let’s cover the main techniques that make this free-
Ternary Weights:
The core idea: Instead of using full-precision weights (like 32-bit floating-point numbers) in dense layers, the model restricts weights to the values {-1, 0, +1}. This means each weight can only represent three possible values, hence “ternary”.
Why it works: The ternary weights replace multiplications with simple additions or subtractions. If a weight is 1, you simply add the corresponding input value. If it’s -1, you subtract the input. If it’s 0, you do nothing.
MatMul-free Token Mixer: MLGRU (MatMul-free Linear GRU):
The challenge: Self-attention, a common mechanism for capturing sequential dependencies in LLMs, relies on expensive matrix multiplications and pairwise comparisons. This leads to quadratic complexity (n²) as we increase the input lengths.
The solution: The paper adapts the GRU (Gated Recurrent Unit) architecture to eliminate MatMul operations. This modified version, called MLGRU, uses element-wise operations (like additions and multiplications) for updating the hidden state, instead of MatMul.
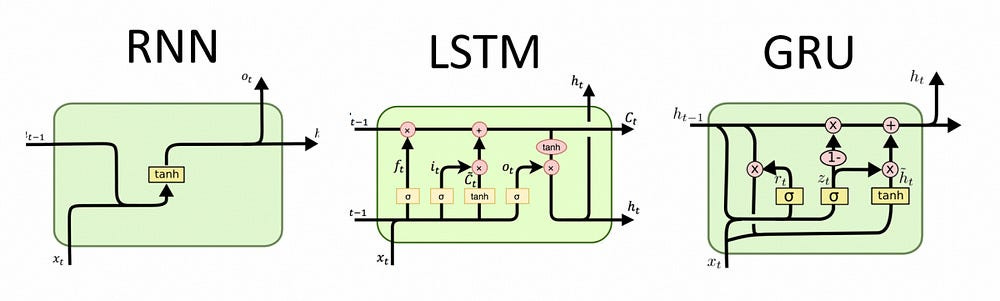
Key ingredients:
Ternary weights: All the weight matrices in the MLGRU are ternary, further reducing computational cost.
Simplified GRU: The MLGRU removes some of the complex interactions between hidden states and input vectors, making it more efficient for parallel computations.
Data-dependent output gate: The MLGRU incorporates a data-dependent output gate, similar to LSTM, to control the flow of information from the hidden state to the output.
MatMul-free Channel Mixer: GLU with BitLinear Layers:
Channel mixing: This part of the model mixes information across the embedding dimensions. Traditionally, it’s done using dense layers with MatMul operations.
The approach: The paper replaces dense layers with BitLinear layers. Since BitLinear layers use ternary weights, they essentially perform element-wise additions and subtractions.
Gated Linear Unit (GLU): The GLU is used for controlling the flow of information through the channel mixer. It operates by multiplying a gating signal with the input, allowing the model to focus on specific parts of the input.
Quantization:
Beyond ternary weights: To further reduce memory usage and computational cost, the model also quantizes activations (the output of a layer) using 8-bit precision. This means each activation value is represented with a limited number of bits.
RMSNorm: To maintain numerical stability during training and after quantization, the model uses a layer called RMSNorm (Root Mean Square Normalization) to normalize the activations before quantization.
Training and Optimization:
Surrogate gradients: Since ternary weights and quantization introduce non-differentiable operations, the model uses a surrogate gradient method (straight-through estimator) to enable backpropagation.
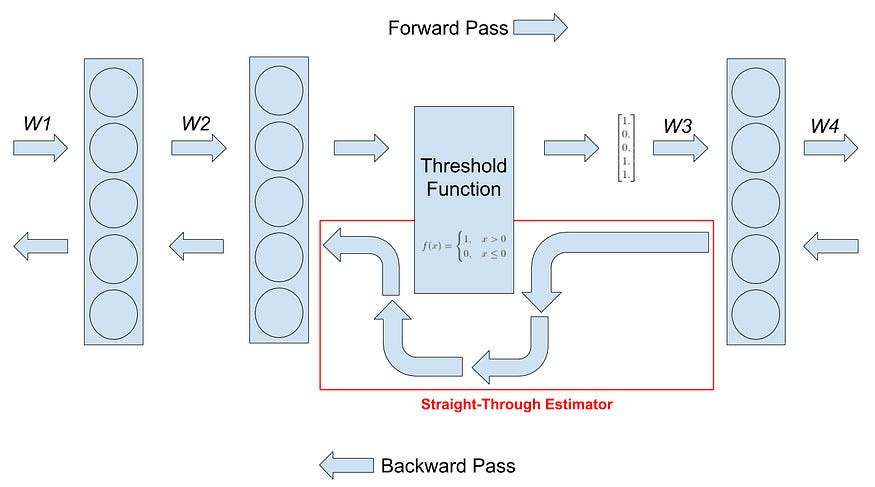
Larger learning rates: The ternary weights, with their limited range, result in smaller gradients compared to full-precision weights. This can hinder the effectiveness of weight updates, potentially leading to slow convergence or even failure to converge. To counteract this, the paper recommends employing larger learning rates than those typically used for full-precision models. This facilitates faster updates and allows the model to escape local minima more efficiently.

LR Scheduler- “However, for the MatMul-free LM, the learning dynamics differ from those of conventional Transformer language models, necessitating a different learning strategy. We begin by maintaining the cosine learning rate scheduler and then reduce the learning rate by half midway through the training process. Interestingly, we observed that during the final training stage, when the network’s learning rate approaches 0, the loss decreases significantly, exhibiting an S-shaped loss curve. This phenomenon has also been reported by [11, 44] when training binary/ternary language models.” I am very interested in any reasons why the last sentence happens, so if any of you have any thoughts, I’d love to hear them.
Fused BitLinear layer: This optimization combines RMSNorm and quantization into a single operation, reducing the number of memory accesses and speeding up training.
I’m going to end this here, but this is by no means an exhaustive list of all the cool work being done to rework LLMs or Deep Learning. We’ve covered lots of other ideas in this newsletter, but I don’t have the time to list them all. I think this is a good enough demonstration of how far from done we are in LLMs.
As always, if you think I’ve misunderstood something, made a mistake, or an argument doesn't make sense, don’t hesitate to send me a message.
Thank you for reading and hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Holy Necro Post Batman! But I wanted to drop a note that this is a fantastic article, it's more like a white paper.
I am guessing Gary Markus is an influential person, all I know of him is that he is a gigantic AI critic. And also seems to be doing it as much for the "I told you so" than anything of real importance. I mean, the tweet you show at the top of this article has him literally gawking "I won!"
Seems awfully contrarian for the sake of only his ... wallet, me thinks. Anyway, great article and tons to digest and just happy to see someone that doesn't have the ridiculously common but wholly uninformed opinion of LLMs as "glorified autocorrect" programs.
Good article, its clear how you put a lot of work in. I like your bilateral brain reference - thats cool. Things like that and e.g. predictive coding are interesting to consider as alternative ways of doing things that are inspired by the brain but still aligned with machine learning practice.
Its probably not really worth asking this question though - is it over? You could easily say yes or no as a matter of perspective. LLMs are already amazingly useful and even if you just made them cheaper and faster that would account for years of valuable research. And as you point out people are and should continue doing some really cool research in the space (DL in general). Even in their expensive current state there is clearly still a place for LLMs and there will be for years to come.
I think Gary Marcus like others seems to have certain stances wrapped up in their identity so I take it with a pinch of salt. The frustrations are warranted and often they are a useful hype counter balance right? As François Chollet said on one of your interviews, (i dont quote) LLMs have sucked the oxygen out of the room. I like thinking about the form of AGI that we “deserve” and deep learning and LLMs are not it. But a part of it.