
How Google Built an Open Source AI to Provide Accurate Flood Warnings for 460 Million People [Breakdowns]
This is how Impactful AI for the future will be built. Developing nations especially should take notes

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Executive Highlights
Short-Medium Term Impact: 2.2 Billion People Lives Helped. Preventing loss of up to 50 Billion USD annually.
Extreme weather disruptions affect billions of people globally. Floods are the most common type of natural disaster affecting 2.2 billion people worldwide. Materially, flooding hits around $50 billion in annual global economic damages (this goes up to over $1 trillion in damage, accounting for about 40 percent of natural catastrophe losses since 1980).

As these numbers clearly show, flood forecasting is one of the most impactful uses of AI. However, it has been limited in scope due to various challenges. This is changing now. In this piece, we will primarily be looking at “Global prediction of extreme floods in ungauged watersheds” by Google AI to look into how they solved the various challenges and what that teaches us about building more truly meaningful AI Solutions for the future.
In “Global prediction of extreme floods in ungauged watersheds”, published in Nature, we demonstrate how machine learning (ML) technologies can significantly improve global-scale flood forecasting relative to the current state-of-the-art for countries where flood-related data is scarce. With these AI-based technologies we extended the reliability of currently-available global nowcasts, on average, from zero to five days, and improved forecasts across regions in Africa and Asia to be similar to what are currently available in Europe.
More specifically, I want to cover the following ideas:
Why is Weather Forecasting so Difficult: Weather is a notoriously chaotic system, which makes predicting how weather events will turn out very difficult. This is especially true with severe events, which are by their very nature more extreme. In such cases, under-preparation leads to massive property loss, untimely death, and (most importantly) loss of productive working hours that can be used to maximize shareholder value. The challenges of weather forecasting are made much worse by the lack of high-quality data and computing resources in many poorer countries (which are hit the hardest by weather problems).
Why LSTMs are good for this: The architectural assumptions of RNNs have some benefits when we utilize them for weather prediction. TLDR- weather can be modeled as a Markovian process and RNNs can be very good for that. Google has some interesting modifications to a vanilla LSTM that push them to be even better. We will be diving into them (and the data used).
What this teaches us about AI Policy for the future: Many countries are interested in building policies to catalyze AI breakthroughs. Google’s work is a great demonstration of the principles required to build truly meaningful AI. Policymakers from developing countries in particular should take notes since these principles can help you and your country save a lot of not pursuing dead-ends. To ground the discussion in reality, I will refer to India, and how we could utilize these findings to create AI Policies that truly push things forward.
Let’s get into it

PS- In the all diagrams comparing results, ‘AI Model’ refers to Google’s new LSTM system. That is the name they submitted in their official publication to Nature (how did this pass through review). In case you wanted more evidence that Google AI needs to put a LOT more effort into their marketing and DevRel.

The Trouble with Weather Forecasting
You can skip this section if you have read the whole deep dive we into Chaotic Systems and how to use AI on them over here, or if you can answer the following questions:
What are Chaotic Systems? Why is Weather Chaotic?
The limitations of traditional models/forecasts in weather forecasting.
Why Machine Learning is good for weather forecasting.
How weather forecasting in poorer countries is much harder.
Weather forecasting is a problem. But why?
Weather is a chaotic system. Simply put, this means that even changing the starting parameters slightly results in very different outcomes. Weather is particularly chaotic b/c of how many influences it has. The weather in any place is significantly influenced by its biological ecosystems, physics, tectonics, and every other force imaginable. Inputting all that data is impossible, and most domain-based models operate on assumptions that drastically oversimplify weather to a few key variables. This can work with shorter time frames, but the more you stretch the time horizon, the more your error increases (remember kids, errors/uncertainty always add up).
Machine Learning can help with this. Machine Learning systems are extremely good at finding hidden/complex relationships between a large number of data points. This has two benefits with Weather Forecasting:
It allows us to discover rules/relationships that would be too complex for us to find on our own.
We can throw the entire dataset at it, and get more comprehensive (multi-variate) models. This reduces the error you get when you only consider a few aspects.
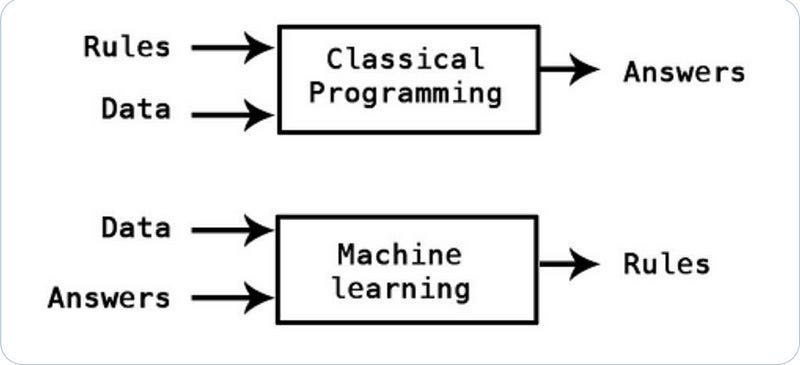
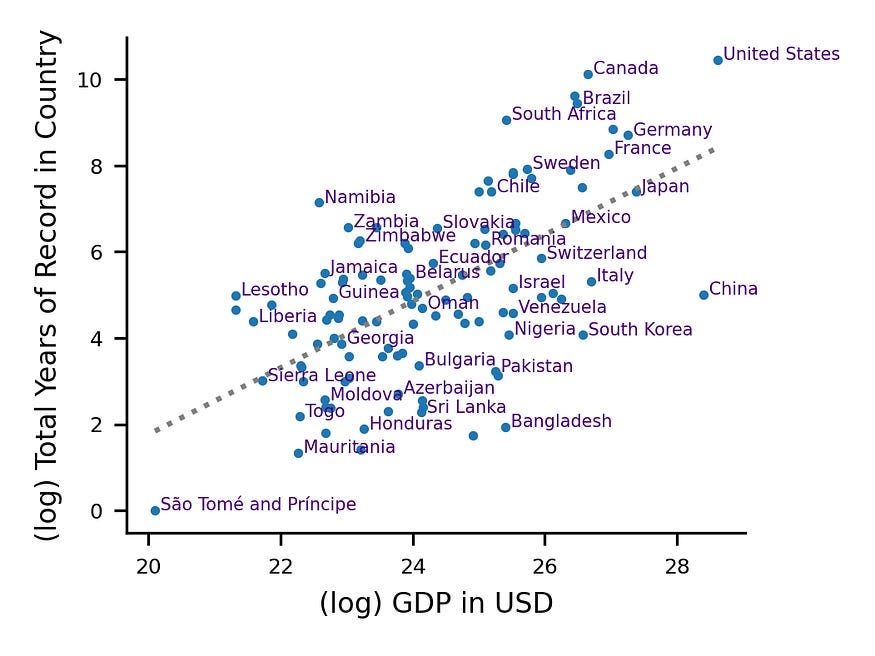
Unfortunately, Machine Learning has a major drawback: it lives and dies by the quantity of its (high-quality) input data. This is where global inequality can be a menace. Many of the countries that are hit hardest by severe weather events (including floods), lack good data sources that can be utilized to monitor the weather (and thus build warning systems). We see this very clearly with flooding: “Only a few per cent of the world’s watersheds are gauged, and stream gauges are not distributed uniformly across the world. There is a strong correlation between national gross domestic product and the total publicly available streamflow observation data record in a given country (Extended Data Fig. 1 shows this log–log correlation), which means that high-quality forecasts are especially challenging in areas that are most vulnerable to the human impacts of flooding.”
Weather is also a very local phenomenon (think about everything that influences weather), which makes it difficult to use high-quality data from a rich country as a proxy for data from a poorer country. All of this combines to make weather one of the hardest phenomena to measure well.
This lack of good-quality data has been a thorn in all our sides. We will discuss it later when we go into what policymakers should take away from this work when designing better policy. For now, I wanted to mention it b/c it provides some context into the challenges that Google overcame when building its ‘AI Model’ (I’m sorry but this name is triggering me). For the rest of this article, I will use FFS (Flood Forecasting System) to refer to their model.
Let’s get into their model in more detail. To do so, it’s helpful to understand why Google went with LSTMs as a base for their solution. Let’s talk about that next.
Weather as a Markovian Process and Why LSTMs are great for weather forecasting
Note: This part is my speculation. Google does not officially tell us why they used LSTMs for their FFS. If you have anything to add or disagree with any of the points, please share your thoughts.
You can skip this section if you understand the following:
What is a Markovian Process?
Why Weather can be modeled as a Markovian Process.
Why LSTMs are especially good at modeling MPs.
What is a Markovian Process?
A Markovian Process is a type of stochastic (random) process where the future state of a system depends only on its current state, not on its entire history. Imagine you’re standing outside, and you only care about whether it’ll rain in the next hour; if you know whether it’s raining right now, it often doesn’t matter much if it rained yesterday or how sunny it was for a week. The “memorylessness” of the process simplifies its modeling.

Similarly, for our flooding use case, the most important thing to predict the flooding at time-step (t+1) is the flooding at time step t + inputs at time (t+1). If you remember RNNs, this should immediately get your ears perked up b/c that formulation is very recurrent-
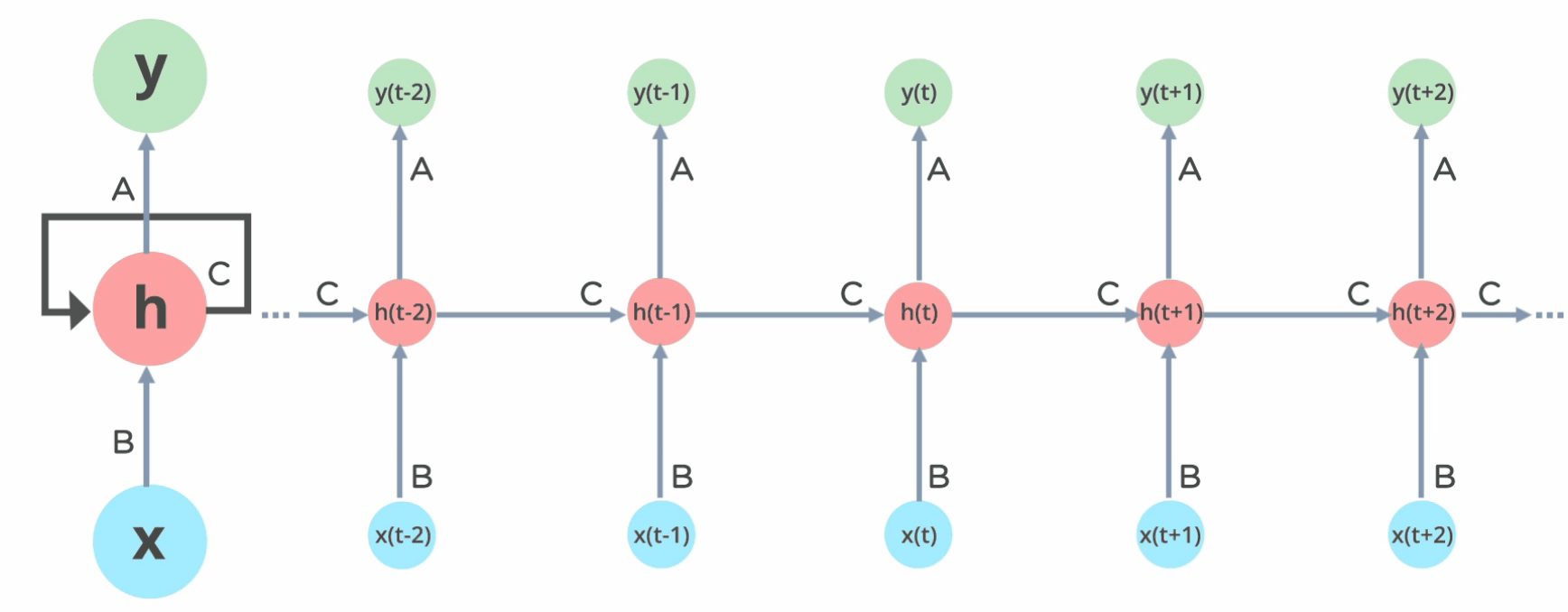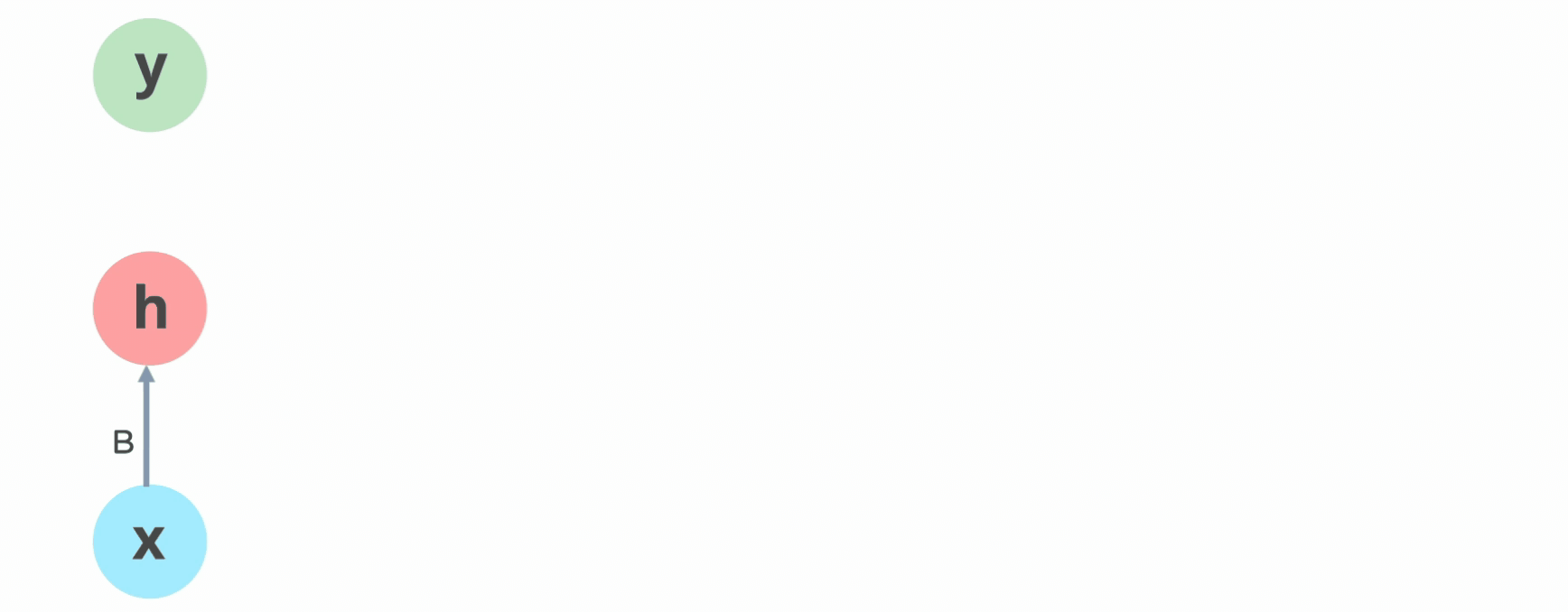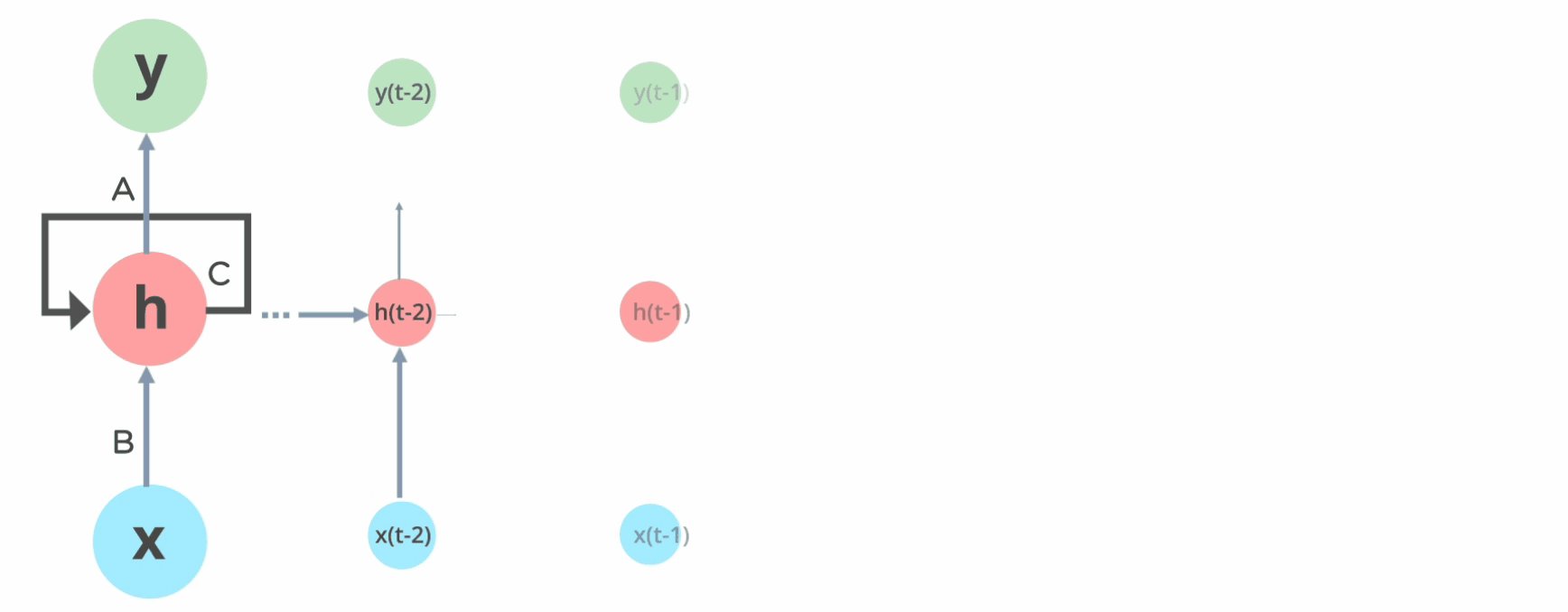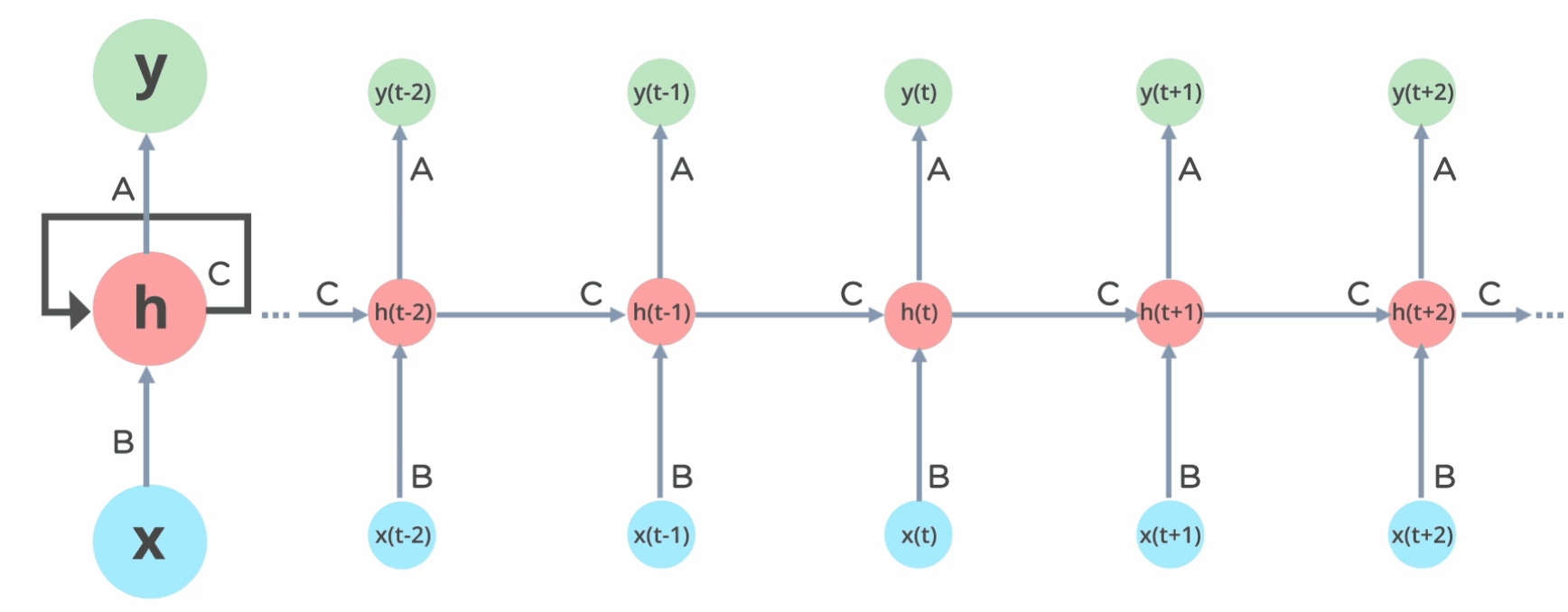
It’s important to note that weather isn’t a perfect Markovian process. Long-term trends and larger climate systems do exert more subtle influence. However, the Markovian assumption holds surprisingly well for many short-term forecasting needs. It’s good enough for us to forecast a few days into the future. Just as with love, your job, and all other important things in life: ML Engineering is about engaging in death denial by giving up on the perfect and picking the first option that works well enough.
So far, we’ve only discussed why RNNs are good at Markovian Processes. So why LSTMs? Let’s cover them next.
Why LSTMs are good for Weather Forecasting
LSTMs (Long Short-Term Memory) are a type of recurrent neural network (RNN) that are particularly good at handling sequential data with long-term dependencies. Here is some design choices that make them suitable for weather forecasting:
Handling Sequential Data: Weather is inherently sequential. Temperatures, rainfall, cloud cover, etc., come to us as a time series of measurements. LSTMs are built to learn patterns within such sequences.
Learning Long-Term Dependencies: While weather is largely Markovian in the short term, subtle longer-term trends do exist. LSTMs can maintain an internal ‘memory’ that allows them to pick up both immediate dependencies and weaker patterns that manifest over longer timescales.
Handling Noise: Weather data can be noisy due to sensor errors and local micro-variations. LSTMs have mechanisms to selectively ‘forget’ irrelevant information, focusing on the essential trends within the noise.
The last point was pretty interesting to dig into. There is some very interesting work done using LSTMs for denoising. I’m not enough of an expert there to give you deep insight into this space. However, I am fairly curious about this, so if you do look into this: make sure you share your learnings.
This paper presents a spectral noise and data reduction technique based on long short-term memory (LSTM) network for nonlinear ultrasonic modulation-based fatigue crack detection. The amplitudes of the nonlinear modulation components created by a micro fatigue crack are often very small and masked by noise. In addition, the collection of large amounts of data is often undesirable owing to the limited power, data storage, and data transmission bandwidth of monitoring systems. To tackle the issues, an LSTM network was applied to ultrasonic signals to reduce the noise level and the amount of data.
With all that background out of the way, let’s look into how Google leverages LSTMs to predict floods effectively. Here is a basic overview of FFS-
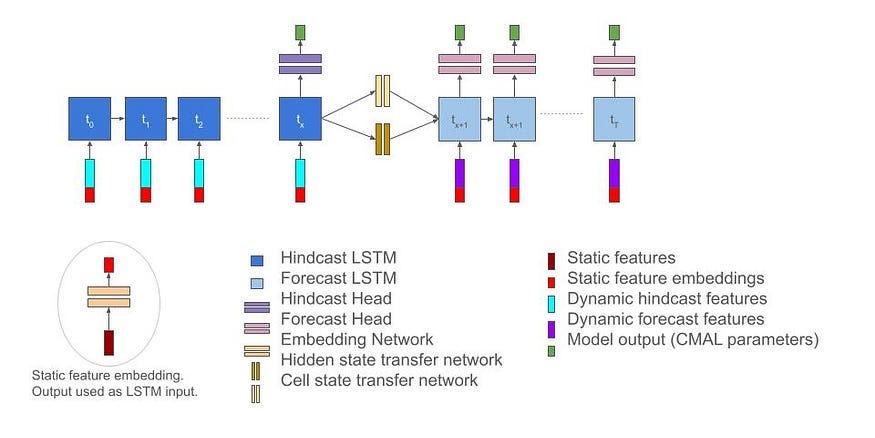
Understanding Google’s Amazing ‘AI Model’ for Flood Forecasting
You can skip this section if you have read the paper and understand FFS Architecture and its decisions (although in that case, would really appreciate your input on why they made certain architectural decisions).
We’ll first cover the data used to develop FFS.
FFS and Training Data (sectioned copied from the announcement)
“The model uses three types of publicly available data inputs, mostly from governmental sources:
Static watershed attributes representing geographical and geophysical variables: From the HydroATLAS project, including data like long-term climate indexes (precipitation, temperature, snow fractions), land cover, and anthropogenic attributes (e.g., a nighttime lights index as a proxy for human development).
Historical meteorological time-series data: Used to spin up the model for one year prior to the issue time of a forecast. The data comes from NASA IMERG, NOAA CPC Global Unified Gauge-Based Analysis of Daily Precipitation, and the ECMWF ERA5-land reanalysis. Variables include daily total precipitation, air temperature, solar and thermal radiation, snowfall, and surface pressure.
Forecasted meteorological time series over a seven-day forecast horizon: Used as input for the forecast LSTM. These data are the same meteorological variables listed above, and come from the ECMWF HRES atmospheric model.
Training data are daily streamflow values from the Global Runoff Data Center over the time period 1980–2023. A single streamflow forecast model is trained using data from 5,680 diverse watershed streamflow gauges (shown below) to improve accuracy.”
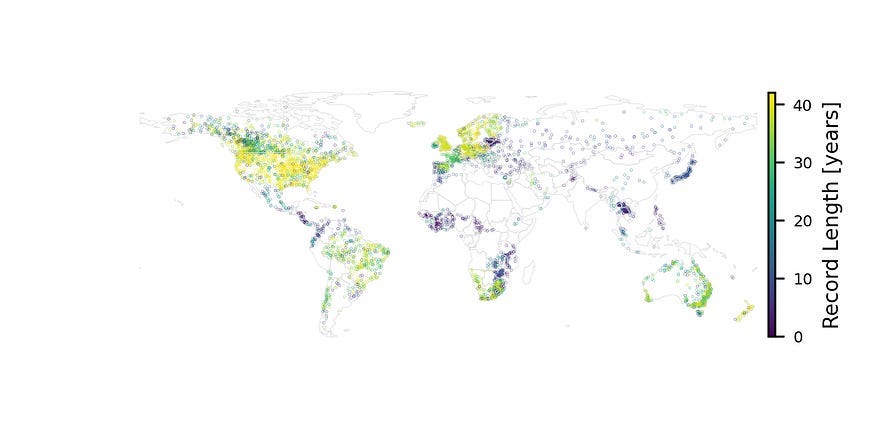
Understanding the FFS Architecture
Here is how the researchers describe their architecture-
Our river forecast model uses two LSTMs applied sequentially: (1) a “hindcast” LSTM ingests historical weather data (dynamic hindcast features) up to the present time (or rather, the issue time of a forecast), and (2) a “forecast” LSTM ingests states from the hindcast LSTM along with forecasted weather data (dynamic forecast features) to make future predictions. One year of historical weather data are input into the hindcast LSTM, and seven days of forecasted weather data are input into the forecast LSTM. Static features include geographical and geophysical characteristics of watersheds that are input into both the hindcast and forecast LSTMs and allow the model to learn different hydrological behaviors and responses in various types of watersheds.
Output from the forecast LSTM is fed into a “head” layer that uses mixture density networks to produce a probabilistic forecast (i.e., predicted parameters of a probability distribution over streamflow). Specifically, the model predicts the parameters of a mixture of heavy-tailed probability density functions, called asymmetric Laplacian distributions, at each forecast time step. The result is a mixture density function, called a Countable Mixture of Asymmetric Laplacians (CMAL) distribution, which represents a probabilistic prediction of the volumetric flow rate in a particular river at a particular time.
Here is what I understand about what they did (and why they did what they did)-
Overall Structure
The core idea is to use two LSTMs in a chained fashion for river forecasting:
Hindcast LSTM: This is like establishing a baseline; it learns from historical weather data.
Forecast LSTM: This builds on the baseline, fine-tuning predictions using forecasted weather data.
Hindcast LSTM
Input: One year of historical weather data. This gives the model a long-term understanding of seasonal patterns and typical weather in the region.
Static Features: Geographical/geophysical data about the watersheds is included. This teaches the model how different terrains and landscapes respond to weather (e.g., runoff amounts, timings).
Purpose: The hindcast LSTM develops a robust representation of the river system’s typical behavior under varying historical weather conditions. This acts similarly to a prior in Bayesian Learning.
Forecast LSTM
Input 1: The internal states from the hindcast LSTM (the ‘memory’ of the river system).
Input 2: 7 days of forecasted weather data. This is essential for immediate, short-term predictions.
Static Features (Again): The same geographical/geophysical data is re-used to ensure the forecast stage is consistent with the knowledge developed during the hindcast.
Purpose: The forecast LSTM takes the baseline understanding and “fine tunes” it based on the expected upcoming weather.
“Head” Layer with Mixture Density Networks
Why Probabilistic: Weather and river flow are inherently uncertain. Instead of a single value (e.g., “the river will rise 2 meters”), a probabilistic forecast is far more useful, conveying the range of possibilities. I super-duper lovee this call b/c this will also feed into simulations better. Let’s understand the math terms
Mixture Density Networks (MDNs): Imagine multiple probability distributions (like bell curves) mixed together. An MDN can represent complex shapes for real-world data that isn’t perfectly described by a single type of distribution. It works on the assumption that any general distribution can be broken down into a mixture of normal distributions. For eg. this distribution

can be represented as the sum of the following distributions

You can see how this would be useful when dealing with very complex/layered distributions. We can do this splitting with any kind of distribution, so why do the researchers specifically choose ALD? Let’s talk them next.
Asymmetric Laplacian Distributions: This is a specific type of probability distribution good for data with steeper peaks but heavier tails (leading to their role as the normal distribution of finance). It seems that they are better at capturing volatility, which is likely why they were used here. Take a look at the comparison of a Laplace Distribution vs a Normal Distribution to see how their properties differ-

In the comparison shown above, the peak would represent the majority of days where there’s no flooding. The Short Decay captures the likelihood of mild to moderate floods that decrease in frequency as their severity increases. Lastly, The Long Tail represents the potential for rare but extreme flood events that, while less frequent, have significant impacts. We stack multiple ALDs to get our CMAL-
Countable Mixture of Asymmetric Laplacians (CMAL): This combines multiple asymmetric Laplacian distributions into a single, even more flexible distribution. It can capture a wide range of possible values (river flow rates) and their corresponding probabilities. CMAL seems to be based on the same philosophy as ensemble models: let different submodels handle specific skews/distributions and combine them.
This is what the paper cited by Google for CMAL has to say:
In regression tasks, aleatoric uncertainty is commonly addressed by considering a parametric distribution of the output variable, which is based on strong assumptions such as symmetry, unimodality or by supposing a restricted shape. These assumptions are too limited in scenarios where complex shapes, strong skews or multiple modes are present…. Apart from synthetic cases, we apply this model to room price forecasting and to predict financial operations in personal bank accounts. We demonstrate that UMAL produces proper distributions, which allows us to extract richer insights and to sharpen decision-making.
-CMAL is just UMAL but with countable ALs

CMAL gives FFS a specialized toolbox of different ALDs, allowing it to capture the nuances of regional differences (the topology can change flooding impacts), seasonal shifts, and even unpredictable extremes in flood patterns. Overall, CMALs end up with more precision, combined with better uncertainty quantification, and more flexibility than uni-distributional systems.

That is my analysis of their architecture and why it works (based on the two pillars of chocolate milk and Googling). If you have anything to add, would love to hear it. Maybe I missed it here, but I really wish AI papers spent more time explaining why they decided to do what they did (this is something that Amazon Science does extremely well in their engineering blogs). It would save everyone a lot of time and can only help in pushing science forward. I don’t understand why it’s not common practice.
Using the dataset described herein, the AI model takes a few hours to train on a single NVIDIA-V100 graphics processing unit. The exact wall time depends on how often validation is done during training. We use 50 validation steps (every 1,000 batches), resulting in a 10-hour train time for the full global model.
- Good, Effective AI doesn’t have to be a Leviathan. Can we please start focusing more on these.
I can think of a few interesting ways to improve this: including the usage of HPC (high-performance computing) for more comprehensive simulations, synthetic data for augmentation, and more techniques that might be useful for forecasting. I’ll touch upon these when I do deep dives into AI for weather forecasting/simulations. If you want to help me with the research/testing for that, shoot me a message and we can talk.

To end, I want to talk about some of the important policy lessons that this teaches us.
What FFS teaches us AI
In no particular order, here are some meta-lessons (lessons about AI) that this research teaches us
Open Source must be backed by Governments
Given the severity of impacts that floods have on communities around the world, we consider it critical that forecasting agencies evaluate and benchmark their predictions, warnings and approaches, and an important first step towards this goal is archiving historical forecasts.
-The authors put this perfectly
There has been a lot of fear-mongering about the negative societal impacts of open-sourced AI/Data. Certain alarmists love to go on and on about how LLMs will enable bioweapons, radicalize everyone, make people fall in love with virtual robots, etc. On a policy level, several countries and organizations have very strict policies on sharing data, intelligence, etc across borders.
While some of these make sense, projects like this show us how much progress we lose out on when we choose not to build on collaborative efforts. This project would not be possible w/o international collaboration/sharing of data.
In 2022, we launched the Flood Hub platform, which provided access to forecasts in 20 countries — including 15 in Africa — where forecasting had previously been severely restricted due to the lack of global data.
A year later, in 2023, we added locations in 60 new countries across Africa, the Asia-Pacific region, Europe, and South and Central America, covering some 460 million people globally. As a result, forecasts are now freely available on the Flood Hub in real time to many vulnerable communities in developing countries. Thanks to advances in our global AI-based model, access to flood forecasting in Africa is now comparable to that of Europe.
Governments have to take on a more proactive role in backing open source and developing incentives for collaboration. As more and more people start getting involved in such projects, we can develop more fine-grained intelligence. This will enable more context-aware decisions, which is a must for any kind of digital/AI inclusivity.
The first step for this would be investments in high-quality AI data collection systems and datasets that can used for various problems. This is the most important part for any AI system, and there should be investments into societal-scale data collection for important variables.
For certain kinds of data, there are security and/or privacy concerns. And that’s valid. That’s one of the reasons I’m very bullish on synthetic data: it can be shared w/o such problems. There are also some pretty good data privacy startups that are popping up to solve these problems, and investing more heavily in this sector will pay dividends.
Developing Countries Must Run their own Race
There was a lot made about India’s plan to build 10,000-GPU sovereign AI supercomputer and put billions into LLMs. Contrary to what I’ve seen online, I don’t like it. While such investments are important, this investment is premature, and we have bigger problems to tackle right now.
Investments like Indigenous LLMs and Supercomputers are best made after we have established a strong infrastructure that allows us to use these technologies to their fullest. Otherwise, you’re stuck driving a Ferrari in a jungle. I think policymakers are getting too excited by the siren song of wanting to be seen as a cutting-edge technological hub to see that this approach will only run their ship into dire straits.
Any country should approach AI Policy investments in the following way:
What is the biggest problem that we need to solve?
What is needed to solve this problem? This is not just technical (socio-economic factors end up being a bigger factor, and no AI policy really addresses this).
Investing into the right data collection, ecosystem, domain research, and product roadmap.
NOW we invest into AI (if it’s relevant).
Running to build a supercomputer/encourage LLMs is like building Skyscrapers w/o first building roads, sewage/irrigation, and proper zoning. Countries like the USA or companies like Microsoft have the $$ to waste on sweeping large-scale investments in hopes that something works out. We have to play it smarter, investing in what’s important. Smaller, focused investments in projects + a bottom-up look into infrastructure will have better ROIs.
To prove the point, take a look at the comparative results of FFS vs GloFAS (the current SOTA).

The Indian Subcontinent area is one of the few countries where the model is worse (fairly significantly too). As a general rule, this is why copying benchmarks and solutions w/o critical thinking is a terrible idea. Specific to our discussion, this is why we need to invest into identifying the right problems, higher-quality data monitoring, and better digital inclusion before thinking about building more powerful AI. Trying to compete with Western Countries by doing what they’re doing is like telling Bivol to do steroids to prepare for his fight against Beterbiev. Like trying to beat Madrid by buying off the UCL Referees. At best, it’s wasteful. At worst, it’s a T-posing content that distracts from real issues that need to be solved.
If you still have a burning desire to spend heaps of money on AI : might I suggest a group subscription to my writing? You’ll save money, still keep up important ideas in AI, and you’ll make chocolate milk sellers all over the world very very happy. Most importantly, I don’t need to spend millions on marketing to tell you why I’m useful.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819