
Beyond MatMul: The New Frontier of LLMs with 10x Efficiency [Breakdowns]
Scalable MatMul-free Language Modeling (Nvidia hates this one trick)

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights (tl;dr of the article)
Recently, I read the paper “Scalable MatMul-free Language Modeling,” which seeks to build better Large Language Models by removing the Matrix multiplications, a development with significant socio-economic implications. Matrix multiplications (MatMul) are a significant computational bottleneck in Deep Learning, and removing them enables the creation of cheaper, less energy-intensive LLMs, which will address both the high environmental impact and the unfavorable unit economics plaguing LLMs today. A more thorough analysis of the impact of MatMul-free LLMs through various dimensions is presented below-
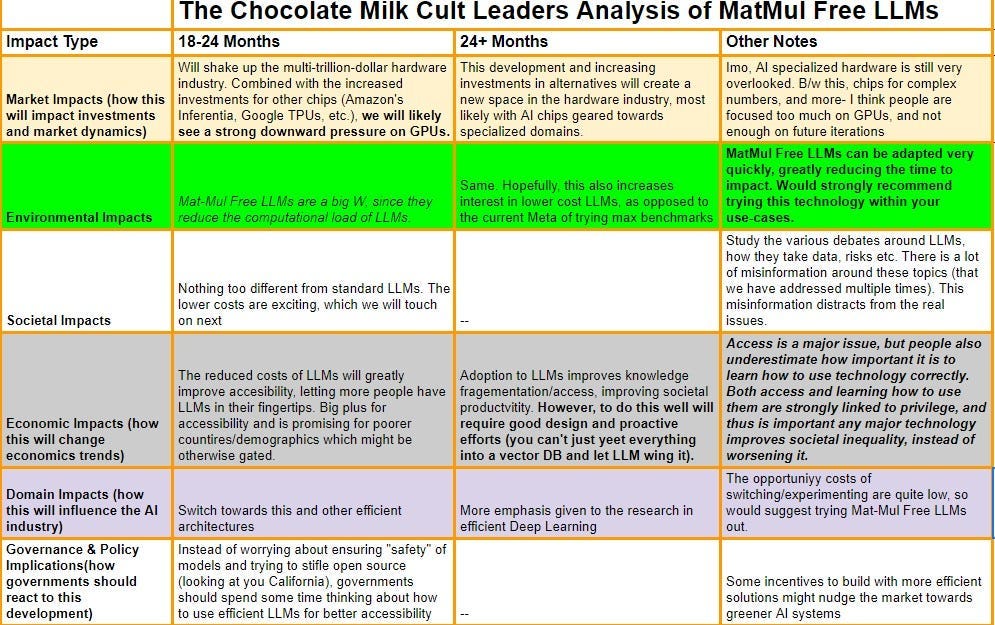
My bullish sentiment for this development is based on the very strong results in the paper. For example, MatMul-Free LLMs (going to use MMF-LLMs from now on for simplicity) are very computationally efficient-
Our experiments show that our proposed MatMul-free models achieve performance on-par with state-of-the-art Transformers that require far more memory during inference at a scale up to at least 2.7B parameters. We investigate the scaling laws and find that the performance gap between our MatMul-free models and full precision Transformers narrows as the model size increases. We also provide a GPU-efficient implementation of this model which reduces memory usage by up to 61% over an unoptimized baseline during training. By utilizing an optimized kernel during inference, our model’s memory consumption can be reduced by more than 10x compared to unoptimized models. To properly quantify the efficiency of our architecture, we build a custom hardware solution on an FPGA which exploits lightweight operations beyond what GPUs are capable of.
Demonstrate comparable performance to Transformers-

And follow beautiful scaling laws-

The secret to their great performance rests on a few innovations that follow 2 major themes- simplifying expensive computations and replacing non-linearities with linear operations (which are simpler and can be parallelized).

In more depth, we see the following algorithmic techniques play a major role in MatMul-Free LLMs (self-attention is not used by MMF-LLMs, but is only given for comparison)-
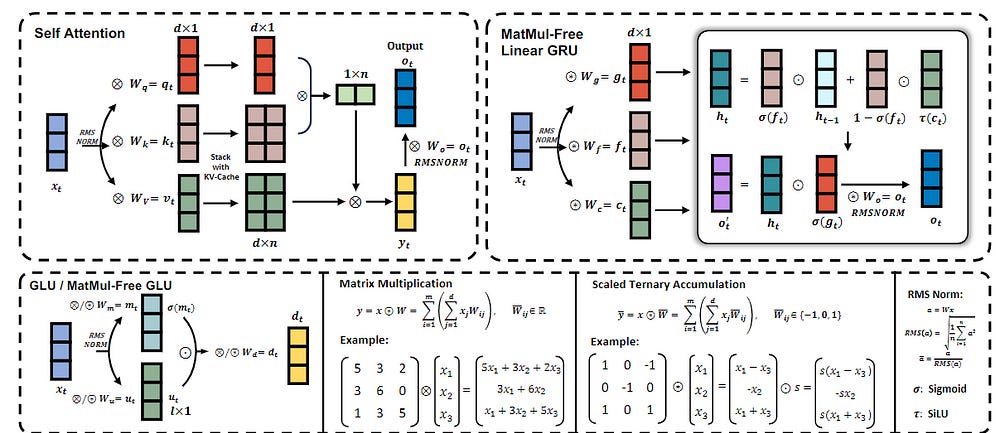
Ternary Weights:
The core idea: Instead of using full-precision weights (like 32-bit floating-point numbers) in dense layers, the model restricts weights to the values {-1, 0, +1}. This means each weight can only represent three possible values, hence “ternary”.
Why it works: The ternary weights replace multiplications with simple additions or subtractions. If a weight is 1, you simply add the corresponding input value. If it’s -1, you subtract the input. If it’s 0, you do nothing.
MatMul-free Token Mixer: MLGRU (MatMul-free Linear GRU):
The challenge: Self-attention, a common mechanism for capturing sequential dependencies in LLMs, relies on expensive matrix multiplications and pairwise comparisons. This leads to quadratic complexity (n²) as we increase the input lengths-

The solution: The paper adapts the GRU (Gated Recurrent Unit) architecture to eliminate MatMul operations. This modified version, called MLGRU, uses element-wise operations (like additions and multiplications) for updating the hidden state, instead of MatMul.

Key ingredients:
Ternary weights: All the weight matrices in the MLGRU are ternary, further reducing computational cost.
Simplified GRU: The MLGRU removes some of the complex interactions between hidden states and input vectors, making it more efficient for parallel computations.
Data-dependent output gate: The MLGRU incorporates a data-dependent output gate, similar to LSTM, to control the flow of information from the hidden state to the output.
MatMul-free Channel Mixer: GLU with BitLinear Layers:
Channel mixing: This part of the model mixes information across the embedding dimensions. Traditionally, it’s done using dense layers with MatMul operations.
The approach: The paper replaces dense layers with BitLinear layers. Since BitLinear layers use ternary weights, they essentially perform element-wise additions and subtractions.
Gated Linear Unit (GLU): The GLU is used for controlling the flow of information through the channel mixer. It operates by multiplying a gating signal with the input, allowing the model to focus on specific parts of the input.
Quantization:
Beyond ternary weights: To further reduce memory usage and computational cost, the model also quantizes activations (the output of a layer) using 8-bit precision. This means each activation value is represented with a limited number of bits.
RMSNorm: To maintain numerical stability during training and after quantization, the model uses a layer called RMSNorm (Root Mean Square Normalization) to normalize the activations before quantization.
Training and Optimization:
Surrogate gradients: Since ternary weights and quantization introduce non-differentiable operations, the model uses a surrogate gradient method (straight-through estimator) to enable backpropagation.
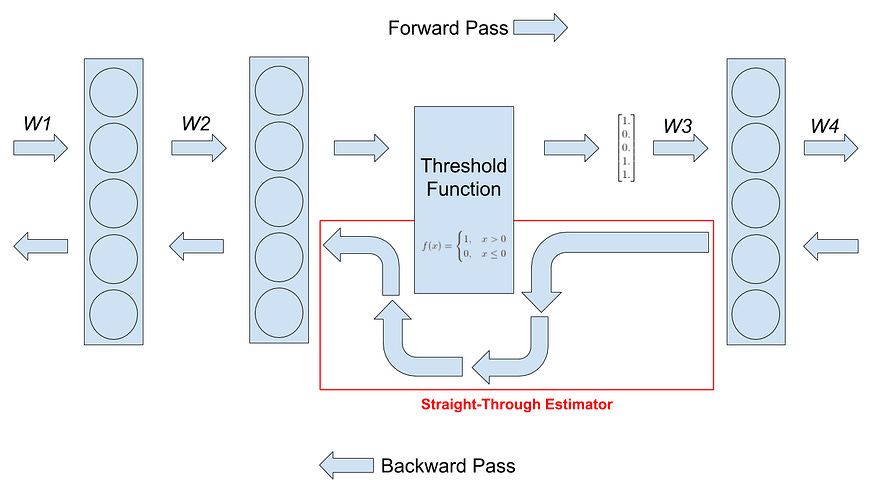
Larger learning rates: The ternary weights, with their limited range, result in smaller gradients compared to full-precision weights. This can hinder the effectiveness of weight updates, potentially leading to slow convergence or even failure to converge. To counteract this, the paper recommends employing larger learning rates than those typically used for full-precision models. This facilitates faster updates and allows the model to escape local minima more efficiently.

LR Scheduler- “However, for the MatMul-free LM, the learning dynamics differ from those of conventional Transformer language models, necessitating a different learning strategy. We begin by maintaining the cosine learning rate scheduler and then reduce the learning rate by half midway through the training process. Interestingly, we observed that during the final training stage, when the network’s learning rate approaches 0, the loss decreases significantly, exhibiting an S-shaped loss curve. This phenomenon has also been reported by [11, 44] when training binary/ternary language models.” I am very interested in any reasons why the last sentence happens, so if any of you have any thoughts, I’d love to hear them.
Fused BitLinear layer: This optimization combines RMSNorm and quantization into a single operation, reducing the number of memory accesses and speeding up training.
The rest of this piece will explore these algorithmic changes in more detail. To keep things focused and concise, I will skip how the authors built some custom hardware to maximize the MMF-LLM. For those of you with a burning desire to learn about that, check out section 5 of the paper. We will start by exploring one of the most fascinating trends in cutting-edge Deep Learning- the introduction of linearity in more places.
The 1.3B parameter model, where L = 24 and d = 2048, has a projected runtime of 42ms, and a throughput of 23.8 tokens per second. This reaches human reading speed at an efficiency that is on par with the power consumption of the human brain.
-The efficiency is insane
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
To Linear or Not to Linear
This has been one of the most interesting, ‘return to monke’ trends I’ve noticed in Deep Learning recently. Many cutting-edge LLMs are going very old-school by actively replacing non-linearities with linear layers. To fully appreciate how cool, let’s do some math-history (as you can tell by my interests, I was very popular in high school)
Why Deep Learning loves non-linearities- As we discussed in our exploration of Kolmogorov–Arnold Networks, Deep Learning hinges on the Universal Approximation Theorem, which states any continuous function can be approximated by stacking some non-linearities together. Our attempts to build bigger and more complex neural networks essentially try to get more refined approximations. Unfortunately, non-linearity has a huge drawback. It’s slightly difficult to parallelize, given it’s more sequential nature and more complicated relationships. Thus, replacing non-linear operations with linear ones can boost your parallelism and simplify your overall operations.
If you’ve wanted to understand modern, non-Transformer LLMs like RWKV (which we covered here) or Mamba, this is their key innovation. Instead of adding non-linearity at every step (traditional RNNs), they only add non-linearity at the last steps. Since most computations are linear, they can be done in parallel. These are then fed to non-linear blocks, which can model the complexity. This trades off some expressivity (and thus some performance), for large efficiency gains. This is an amazing deal, given that we can more than make up for the lost performance with data engineering and good design, while keeping the low costs.
I bring up this back story because a lot of AI papers are actively looking to bring back older techniques in more scaled-up ways to bridge performance gaps. It’s a pretty interesting, somewhat overlooked field of AI that is worth paying attention to. You never know what old techniques come up again (and these older techniques are closer to the foundations, which is always a good skill to spec into).
With that slight detour outta the way, let’s get into the meat of this breakdown. We skip the ternary weights (since there isn’t much more for me to talk about there), and move on to the Fused BitLinear layer, a key innovation in the MatMul-free language model. By merging operations and reducing memory accesses, it significantly boosts training efficiency and lowers memory consumption, making MatMul-free models more practical for large-scale applications.

Breaking Memory Bottlenecks: The Fused BitLinear Layer for Efficient Ternary Networks
The introduction of the “Fused BitLinear Layer” in the paper represents a significant step forward in making MatMul-free language models practical for large-scale training. The challenge lies in the inherent inefficiencies associated with moving data between different levels of memory on GPUs. A naive approach (close to what many people use) involves loading input activations from the high-bandwidth memory (HBM) to the faster shared memory (SRAM), performing operations like RMSNorm and quantization, then moving the data back to HBM. This repeated data transfer incurs significant time and bandwidth overhead, slowing down the training process and potentially creating memory bottlenecks.
To combat these inefficiencies, the paper proposes a clever optimization: the “Fused BitLinear Layer.” This approach combines the operations of RMSNorm and quantization into a single, fused operation executed directly in the GPU’s SRAM. By performing these steps in the faster SRAM, the need for multiple data transfers between memory levels is eliminated, significantly reducing overhead. The input activations are loaded from the HBM only once, and the fused RMSNorm and quantization are performed in SRAM, followed by the ternary accumulation operation, which is also executed directly in SRAM. The impact of this can be seen in the significant time + memory difference b/w the Vanilla BitLinear and the Fused one-

Now that we have explored the benefits of the Fused BitLinear layer, it’s time to look into the architecture of the MatMul-free language model itself. This is where we encounter our new best friend, the MatMul-free Linear Gated Recurrent Unit (MLGRU), a clever modification of the traditional GRU designed to eliminate matrix multiplications while retaining its powerful ability to model sequences. The MLGRU addresses a crucial challenge in building efficient language models: the computationally expensive nature of the token mixer, which traditionally relies on self-attention mechanisms (requiring matrix multiplications).
Swerving MatMul: How the MLGRU Reimagines the GRU for Efficiency
To understand the significance of the MLGRU, let’s first understand the workings of the GRU. The GRU is a type of recurrent neural network (RNN) that has gained popularity for its efficiency and ability to learn long-term dependencies in sequences. Unlike traditional RNNs, which often struggle with the vanishing gradient problem, the GRU utilizes “gates” to control the flow of information and prevent gradients from vanishing over long sequences.

The GRU’s key components include-
The hidden state (ht), which encapsulates information about the sequence up to the current time step,
Input (xt), which reps the current token or data point.
The heart of the GRU lies in its two gates: the reset gate, which determines how much of the previous hidden state should be forgotten or reset, and the update gate, which manages the balance between incorporating new information from the current input and retaining the previous hidden state.
The paper’s innovation lies in the MLGRU, a modification of the traditional GRU specifically designed for efficiency and the elimination of matrix multiplications. The MLGRU achieves this through two key changes:
Ternary Weights: All the weight matrices involved in the MLGRU are quantized to ternary values {-1, 0, +1}. This simplifies the process of calculating the gates and the candidate hidden state, replacing traditional multiplications with simple additions and subtractions.
Simplified GRU Structure: The MLGRU removes some of the complex interactions between hidden states, specifically those involving hidden-to-hidden weight matrices. This simplification reduces computational complexity and makes the model more amenable to parallel processing.

The MLGRU significantly reduces the overall computational cost of the token mixer by replacing the computationally expensive matrix multiplications with simpler operations.
Channel mixing (combining information from different embedding dimensions within a language model), traditionally computationally expensive, is made efficient in this paper by using BitLinear layers with ternary weights and Gated Linear Units (GLUs). BitLinear layers replace multiplications with additions and subtractions, while GLUs selectively control information flow, further optimizing the process.

This breakdown is already making me cry, so I will end it here. Overall, I’m a huge fan of anything that tries to address deep limitations in existing systems directly, and this paper qualifies. I’m very excited to see how they continue to develop upon this idea, to build a mainstream contender to the more inefficient LLMs.

If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819