


Understanding Kolmogorov–Arnold Networks: Possible Successors to MLPs? [Breakdowns]
Will the better interpretability, smaller network sizes, and learnable activations allow KANs to topple MLPs

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Executive Highlights (tl;dr of the article)
Thank you to all the cultists who shared their thoughts on the Substack Group Chat, LinkedIn, and more. I love all the conversations we have there, and I’m excited to keep having many more.
Much has been made about the Kolmogorov–Arnold Networks and their potential advantages over Multi-Layer Perceptrons, especially for modeling scientific functions. This article will explore KANs and their viability in the new generation of Deep Learning.
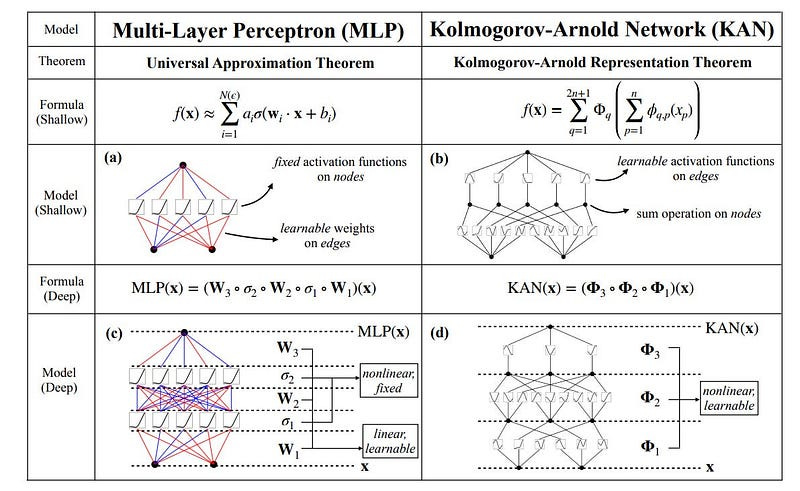
First, let’s do a quick overview of KANs and the theory that enables them-
Kolmogorov-Arnold Representation Theorem: Let’s skip all the scary equations and definitions and settle for a simple explanation. The KART states that any continuous function with multiple inputs can be created by combining simple functions of a single input (like sine or square) and adding them together. Take, for example, multi-variate function f(x,y)= x*y. This can be written as ( (x + y)² — (x² +y²) ) / 2, which uses only addition, subtraction, and squaring (all functions of a single input). The actual KART involves reframing subtraction as an addition (adding the negative), but I’m skipping that here to keep things simple.
KANs (Kolmogorov-Arnold Networks)- Unlike traditional MLPs (Multi-Layer Perceptrons), which have fixed node activation functions, KANs use learnable activation functions on edges, essentially replacing linear weights with non-linear ones. This makes KANs more accurate and interpretable, and especially useful for functions with sparse compositional structures (we explain this next), which are often found in scientific applications and daily life.

WTF are compositional structures- If you’re a gawaar like me, you might be confused by the phrase “ sparse compositional structures” that’s thrown around a few times. So what is it, and what does that have to do with anything? Simply put- A function has a sparse compositional structure when it can be built from a small number of simple functions, each of which only depends on a few input variables. For eg, The function f(x, y, z) = sin(x) * exp(y) + z is compositionally sparse because:
It’s built from three simple functions: sin(x), exp(y), and z.
Each simple function only depends on a single input variable (either x, y, or z).
In contrast, a function like f(x, y, z) = x² * y³ + sin(x + y + z) would be considered less sparse because it requires more complex operations (like x² * y³) and combines all three input variables in the sin function.
For those of that want a mathematically rigorous definition, this is the definition I found in the “Foundations of Deep Learning: Compositional Sparsity of Computable Functions”-
A sparse compositional function of d variables is a function that can be represented as the composition of no more than poly(d) sparse functions, each depending on ≤ d0 variables wwith d0 < d.
- Lmk if I’m looking at the wrong definition or misunderstanding something.
To summarize their relevance, the authors state that most functions encountered in science and IRL have simpler structures, which makes KANs an appealing alternative to MLPs for modeling them. The table below seems to back up this claim.

KANs and Splines- Another interesting characteristic of KANs is their usage of Splines. For our purposes, think of Splines like flexible rulers that can be bent to fit a curve. They are made up of multiple polynomial pieces that are smoothly connected together.
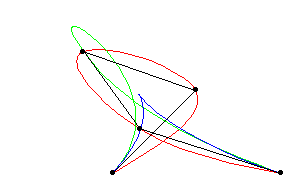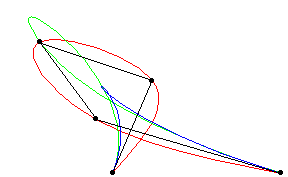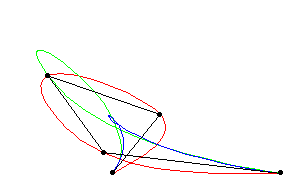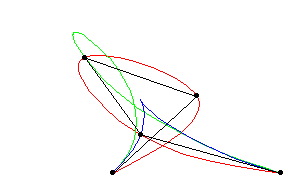
By using splines as their activation functions, KANs can learn complex relationships between input variables while maintaining interpretability and local control. We’ll elaborate on Splines and why they are so cool later in the article.
KANs have some advantages and some drawbacks, which we will discuss next. Firstly, they have 3 notable drawbacks-
Lack of research—Being a new idea, this is forgivable, but it’s important to always remember this when looking at new ideas. The wunderkind-to-impractical has-been story is all too common in AI Research. For all we know, there are fundamental blockers in KANs that make them impractical to improve beyond a certain point.
Market Fit- We are seeing hardware created to specialize on Transformers and NNs. This development might create a strong selection bias against KANs, and ultimately hamper their adoption (thank you Patrick McGuinness, for this great point).
Slow Training- KAN training is 10x slower than NNs. Depending on what you’re working on, this is either going to kill them or not be as big a deal. As we see more adoption/research, this might be addressed (maybe one of you will even work on this), but for now this will stop their adoption in more mainstream directions- which are dominated by scale.
KANs exhibit several key advantages, including:
Improved accuracy: They can achieve lower RMSE loss with fewer parameters compared to MLPs for various tasks. The authors show some amazing results, including beating Deepmind-

Favorable scaling laws: They exhibit faster neural scaling laws, leading to greater performance improvements with increased model size.

Mitigated catastrophic forgetting: Normal MLPs rewrite their old learnings with the new, leading to NNs ‘forgetting’ their old inputs. KANs leverage local plasticity to facilitate continual learning. We will discuss the mechanics of this when we talk about Splines. In the tl;dr section- I want to give a special shoutout to Dr. Bill Lambos, who was the first person to flag this as a major limitation of mainstream NNs in our conversation one year ago. His predictions and insights as a computational neuroscientist and biologist (the OG AI people) have been spot-on multiple times.

Explainability- KANs are more explainable, which is a big plus for certain sectors. One of our cultists had the following to say on the group chat-
Disclaimer: I’m a SWE and an ML enthusiasts, but not an expert by any means. Seems promising more so in terms of explainability than actual performance. I currently work in a heavily regulated industry and explainability is the bottleneck for adoption of ML models.
- Cole Sawyer, Capital One
Interactiveness- People are able to interact with KAN on a more fundamental level, manipulating KANs to achieve various outcomes. This usage of inputting domain expertise inside the networks seems very promising to me, and I’m surprised I haven’t heard more people talk about it. Am I overreacting to it? Keen to hear your thoughts-

These advantages make them appealing prospects for future exploration.
We will spend the rest of this article investigating the properties that make KANs tick. As you might expect, there are many points to discuss, and this article might get a bit overwhelming at times. To approach this breakdown, we will adhere to the old adage of eating the elephant one bite at a time. Let’s begin with the theoretical foundations of Deep Learning and its implications for our current Neural Network-based architectures.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Theoretical Foundations
A. Universal Approximation Theorem and Deep Learning
The Universal Approximation Theorem (UAT )states that a feedforward neural network with a single hidden layer containing a finite number of neurons, using a sigmoid activation function, can approximate any continuous function on a compact set with arbitrary accuracy. All we do is keep stacking different combinations of non-linear functions together, and we get an approximation for our desired function (keep in mind that when we feed data to an ML model, we want a function that models all the features and their relationships to the target).

This was later extended to other non-linearities and is key to why Large Neural Networks well, since Large NN → better ability to model complex non-linear relationships → closer approximation of a continuous function.
Before we proceed- A major thing that people often overlook is that not every dataset/domain can be modeled by continuous functions. For example, there are certain datasets with more jagged decision boundaries. In these cases, tree-based algorithms like Random Forests can be a better choice since Neural Networks are biased towards smoother decision boundaries-
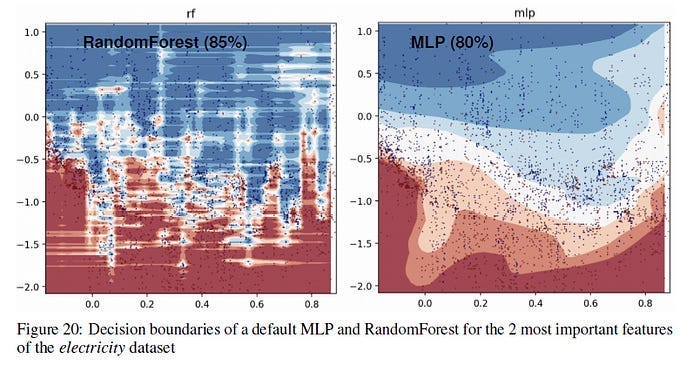
In the Appendix of the above paper, the authors had the following statement wrt to the above visualization-
In this part, we can see that the RandomForest is able to learn irregular patterns on the x-axis (which corresponds to the date feature) that the MLP does not learn. We show this difference for default hyperparameters but it seems to us that this is a typical behavior of neural networks, and it is actually hard, albeit not impossible, to find hyperparameters to successfully learn these patterns.
-On another note, Random Forests are like the Philpp Lahm (fyi, my favorite player of all time) of Machine Learning- filled with class and performance, but criminally underrated.
There are also very important use cases where you deal with discrete decision spaces. Here, Neural Networks and gradient-based methods get Yamcha’ed spectacularly. Project Geneva, which aims to fight government censorship, is a good example. The AI aims to combine 4 functions in creative ways to evade government censors. To learn more about that, you can either read our articles- How to fight censorship using AI (the in-depth look into this project) or How to take back control of the internet (a look into some AI techniques that we can apply to reduce the impacts of the institutional manipulation of the internet)-
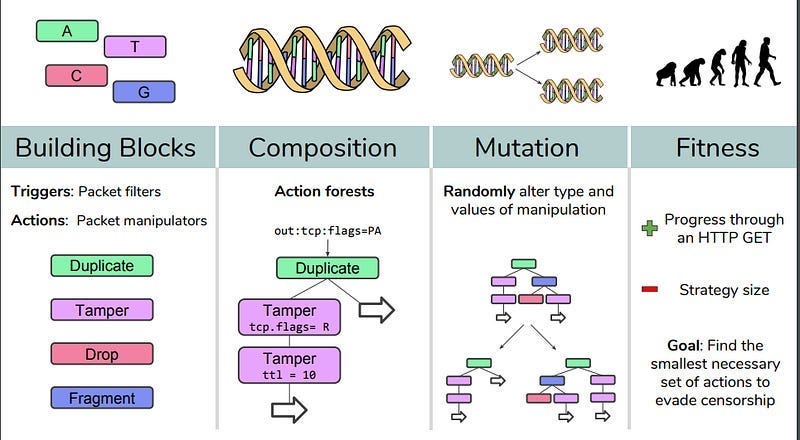
I stress this because this nuance is often overlooked in discussions on Neural Networks and their implementation- and I’m worried something similar might happen when as KANs get more mainstream. With that important point out of the way, let’s start our discussion of the Kolmogorov-Arnold Representation Theorem, which is the basis of KANs.
B. Understanding Kolmogorov-Arnold Representation Theorem
The Kolmogorov-Arnold Representation Theorem (KAT) establishes that any continuous multivariate function on a bounded domain can be expressed as a finite composition of continuous univariate functions and the binary operation of addition. This theorem suggests that, in principle, learning a high-dimensional function can be reduced to learning a polynomial number of univariate functions (although some of these 1D functions might not be smooth, fractal, or not learnable).

Recent work suggests that for many functions encountered in scientific applications, these univariate functions can be smooth and have sparse compositional structures, enabling effective practical implementations. This is why KANs seem to be so popular with our science peeps. With that covered, let’s move on to a very interesting implication of the KART.
C. KANs might be robust to the Curse of Dimensionality
The curse of dimensionality refers to the explosive growth in the number of data points or model parameters required to achieve a given accuracy as the input dimension increases. This issue arises because, in high dimensions, data points become increasingly sparse and distant from one another, requiring more data and model complexity to capture the underlying relationships.
KANs, thanks to their reliance on univariate functions and their ability to exploit compositional structures, have the potential to mitigate the curse of dimensionality. This is pretty cool, although I am currently skeptical of how well this will hold with a higher scale and more modalities integrated. Nonetheless, I am cautiously optimistic about how they will play out.
On the other hand, if we are able to identify a smooth representation (maybe at the cost of extra layers or making the KAN wider than the theory prescribes), then Theorem 2.1 indicates that we can beat the curse of dimensionality (COD). This should not come as a surprise since we can inherently learn the structure of the function and make our finite-sample KAN approximation interpretable.
With our foundations set, let’s now discuss the actual KAN architecture and other pieces that make it work.

Kolmogorov-Arnold Networks (KANs): A Deep Dive
A. Architecture of KANs
It is clear that MLPs treat linear transformations and nonlinearities separately as 𝐖 and 𝜎, while KANs treat them all together in 𝚽.
Section 2.2 of the paper has a lot of definitions and notation flying around, so I’m going to do my best to break things down step by step. First, some background-

The super important part is the last highlight- we need wider and deeper KANs (smh, I can’t believe we’re body-shaming AI Models now). So, how do we help our KANs bulk up? The secret behind arbitrarily big Neural Networks has been our ability to willy-nilly stack layers like there’s no tomorrow. With KANs, this is a problem b/c we lack an analogous concept of layers. So, let’s figure out a definition for a KAN layer that can then be extended to get more chonky bois.
We can define a KAN layer as follows-

Let’s build on this to get deeper KANs.
The shape of a KAN is represented as an array: [n0, n1, …, nL], where ni is the number of nodes in the i-th layer. Given an input vector x0 of dimension n0, a KAN network with L layers computes the output as:
KAN(x) = (ΦL−1 ◦ ΦL−2 ◦ … ◦ Φ1 ◦ Φ0)x. This means that the output is obtained by sequentially applying the activation functions of each layer, starting from the input layer.
We can also rewrite that as below-

Since our operations are differentiable, we can train KANs with backprop.

There are a few important tricks to make your KAN Layers optimizable-
Residual activation functions. We include a basis function 𝑏(𝑥) (similar to residual connections) such that the activation function 𝜙(𝑥) is the sum of the basis function 𝑏(𝑥) and the spline function:
𝜙(𝑥)=𝑤(𝑏(𝑥)+spline(𝑥)).(2.10)
We set- 𝑏(𝑥)=silu(𝑥)=𝑥/(1+𝑒^−𝑥)(2.11)
In most cases. spline(𝑥) is parametrized as a linear combination of B-splines such that
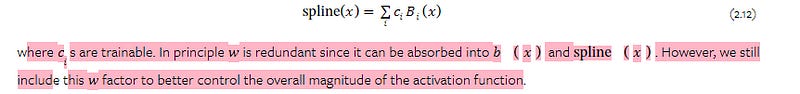
Initialization: “Each activation function is initialized to have spline(𝑥)≈0. 𝑤 is initialized according to the Xavier initialization, which has been used to initialize linear layers in MLPs.”
Update of spline grids: “We update each grid on the fly according to its input activations, to address the issue that splines are defined on bounded regions but activation values can evolve out of the fixed region during training”
Because KANs are inherently more complex, they end up with wayy more parameters than identically sized MLPs. For simplicity, let us assume a network
(1) of depth L,
(2) with layers of equal width n0 = n1 = · · · = nL = N ,
(3) with each spline of order k (usually k = 3) on G intervals (for G + 1 grid points

However, KANs usually require much smaller 𝑁 than MLPs, which-
Reduces parameters,
Achieves better generalization

Facilitates interpretability- Smaller Networks are easier to read and verify.
If you’ve made it this far, you’ve probably noticed that Splines show up a lot in KANs. And you wouldn’t be wrong- splines are a super important part of KANs. So we will discuss them next.
B. Spline Parametrization and KANs
Imagine trying to draw a smooth curve that passes through several points. How would you get the computer to draw the curves that you want? This is where B-splines come in. They are essentially smooth, piecewise polynomial curves that are defined over a set of points called “knots”.
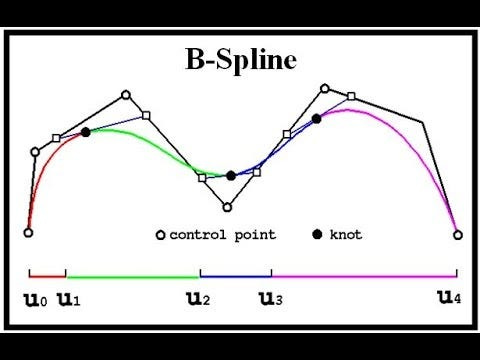
These knots divide the curve into segments, and within each segment, the B-spline is a polynomial of a certain degree. The beauty lies in how these segments smoothly connect, creating a continuous curve with a desired level of smoothness.
B-splines are very cool because they are Camavinga-esque in their flexibility. If you want a very smooth curve, you would use a higher-degree B-spline. If you need more flexibility and control over the curve’s shape, you can adjust the locations of the knots. This makes B-splines incredibly versatile for representing a wide variety of functions. So the next time one of you “men of culture” (men being gender-neutral here) finds yourself thirsting over your favorite animated, AI, or even photoshopped model- make sure you thank the God of B Splines.
B-splines play a crucial role in KANs because they provide a powerful and interpretable way to represent the learnable activation functions on edges. Instead of using fixed activation functions like ReLU or sigmoid, KANs use B-splines to approximate these activation functions. This offers several benefits:
Accuracy: B-splines can approximate complex, non-linear functions with high accuracy.
Local Control: Changing the coefficients of a B-spline only affects the shape of the curve in the vicinity of the adjusted knots. This allows for fine-grained control over the activation function’s behavior without affecting the overall network structure.
has a great piece on KANs here, and his following visualization shows this well-

Interpretability: Because B-splines are composed of piecewise polynomials, they are visually intuitive and easier to understand than black-box neural networks. This makes the learned activation functions more interpretable, facilitating scientific discovery. “We demonstrate that KANs can (re)discover both highly non-trivial relations in knot theory (Section 4.3) and phase transition boundaries in condensed matter physics (Section 4.4). KANs could potentially be the foundation model for AI + Science due to their accuracy (last section) and interpretability (this section).”
To make Splines work at peak performance, we need some support for them. This is where the Grid Extension Technique comes in.
C. Grid Extension to improve Splines
In principle, a spline can be made arbitrarily accurate to a target function as the grid can be made arbitrarily fine-grained. This good feature is inherited by KANs. By contrast, MLPs do not have the notion of “fine-graining”... By contrast, for KANs, one can first train a KAN with fewer parameters and then extend it to a KAN with more parameters by simply making its spline grids finer, without the need to retraining the larger model from scratch.
The grid extension technique, a crucial component of KANs, addresses the limited resolution inherent in splines. As a spline is defined on a finite grid of points, its accuracy depends on the grid’s density. The grid extension technique addresses this by increasing the grid density during training, allowing the model to learn increasingly finer details of the underlying functions.

The process involves fitting a new, finer-grained spline to an old, coarser-grained spline. This allows the model to adapt to changes in the data distribution and improve its accuracy without discarding previously learned knowledge.

Given how important Interpretability is for KANs, let’s talk about how we can ensure that our KANs are as Interpretable as possible.
D. Simplifying KANs for Interpretability
While the underlying architecture of KANs promotes interpretability, the sheer number of activation functions can still make the model challenging to understand. To address this, several simplification techniques are employed:
Sparsification Regularization (L1 and Entropy): Sparsification regularization penalizes the magnitude of the activation functions, encouraging a sparse representation where only a subset of activation functions have significant values. This helps identify the most important relationships learned by the model.
Pruning Techniques: Pruning techniques automatically remove nodes from the network based on their importance scores, further simplifying the architecture and reducing the number of parameters.
Symbolification: Symbolification allows the user to convert activation functions into symbolic representations, such as trigonometric, exponential, or logarithmic functions. This step leverages human expertise to transform the numerical representation of the activation functions into more readily interpretable symbolic formulas.

A major benefit of Interpretability is that it lets people (users, domain experts…) nudge the AI towards decisions midway through the process/training. This interactivity is one of the most overlooked facets of building AI solutions, and most teams do nothing or very little to build this in. But it can be a game changer, done right. So, let’s talk about how you might make KANs and their interactiveness.
E. Interactive KANs
One of the key advantages of KANs is their inherent interactivity. The user, by leveraging visualization tools and symbolic manipulation functionalities, can collaborate with the model to refine the learned representations and gain deeper insights into the underlying relationships.

This interactive approach allows the user to guide the model’s learning process by:
Visualizing activation functions: The user can visualize the activation functions to identify potential symbolic representations and understand the model’s decision-making process.
Manually snapping activation functions: The user can manually fix specific activation functions to symbolic formulas based on their domain knowledge, improving the model’s interpretability and accuracy.
Iteratively refining the network: The user can iteratively adjust the model architecture, hyperparameters, and regularization strategies to optimize the trade-off between accuracy and interoperability.
All of these combine together to give us KANs- something that is flawed, fun, and extremely exciting. To me, KANs provide a fresh attempt at genuinely tackling some of MLP’s most fundamental problems. And for that, this paper deserves all the recognition. Even if we find fundamental limitations that make KANs useless/too niche- I think we will gain a lot of insight from studying them in more detail.
And with that, consider the elephant eaten.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I love splines. I call them the flexible rulers of mathematical modeling. 😉
This is a really useful article, thank you so much! 💗