
The limitations of Math, Big Data, and what it means for AGI [Thoughts]
Why using more data to build ‘general intelligence’ is a lost cause

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
The whole visible world is only an imperceptible atom in the ample bosom of nature. No idea approaches it. We may enlarge our conceptions beyond an imaginable space; we only produce atoms in comparison with the reality of things. It is an infinite sphere, the centre of which is everywhere, the circumference nowhere
-Penses, Blaise Pascal
Executive Highlights (tl;dr of the article)
Close to 2 years since the release of ChatGPT, organizations have struggled to commercialize on the promise of the Generative AI. Aside from consulting firms, cloud providers, B2B tools enabling AI, and hardware folk (all shovel sellers)- few organizations have made massive gains through Generative AI that AI Business Experts claimed was on the horizon (so much for ‘AI will enable single person billion-dollar companies’). When faced with the inherent unreliability, regulations, high costs of deployment, data ownership-related problems, and privacy concerns for enterprise customers- Gen AI disruptors take a cue from the Three Lions and peace out before providing any tangible results.
Inflection AI, a chatbot start-up founded by three A.I. veterans, had raised $1.5 billion from some of the biggest names in tech. ...
But almost a year after releasing its A.I. personal assistant, Inflection AI’s revenue was, in the words of one investor, “de minimis.” Essentially zilch. It could not continue to improve its technologies and keep pace with chatbots from the likes of Google and OpenAI unless it continued to raise huge sums of money.
…This is costing Microsoft more than $650 million.

This has led to a massive PR campaign to rehab AI's image and prepare for the next round of fundraising. Yann LeCunn has made headlines with his claims that “LLMs are an off-ramp to AGI” and that the limitation of current Gen AI lies in its usage of Language as a low-resolution medium of information.
“In 4 years, a child has seen 50 times more data than the biggest LLMs… Text is simply too low bandwidth and too scarce a modality to learn how the world works.”
-Yann LeCunn
We see similar communications from other major providers/thinkers who have now moved on to claim that we are one multi-modal integration away from post-AGI utopia. All we need is smarter data, better models/orchestration, and slightly more computational resources, and we will reach the promised land.
In this article, I will present an alternative view. My thesis can be broken into two parts. Firstly, I argue that Data-Driven Insights are a subclass of mathematical insights. Mathematical Knowledge relies on building up our knowledge from rigorously-defined principles. While such thinking is extremely powerful, it has limitations on what can be expressed/quantified through it since no mathematical system can be both complete (able to prove all true statements/without axioms) and consistent (free of contradictions)-

We then explore this idea in more depth regarding data/AI. To do so, we will talk about the limitations within data- no matter how quality or modality- that limit the emergence of ‘generalized intelligence’. These limitations arise from the nature of data/AI and are thus unavoidable. This leads to large ‘holes’ within the knowledge base of the AI systems- which can’t be filled up with more data and algorithmic knowledge. Any system that relies on these means only, no matter how elaborate or expensive, will fail to reach anything that can be called ‘general intelligence’.
More specifically, we can identify the following phenomena that cause the aforementioned ‘holes’ in any knowledge base-
AI Flattens: By its very nature, AI (or any other method that performs aggregated analysis on population-level data) works by abstracting the commonalities. This is what makes it so useful to us (since we’re not great at tracking commonalities across complexity), but it limits the range of problems in which AI can be useful. Many high-profile errors in Generative AI are caused by applying this aggregation in domains where it’s relevant. This also matters for another key reason, one that many overlook when discussing AI-
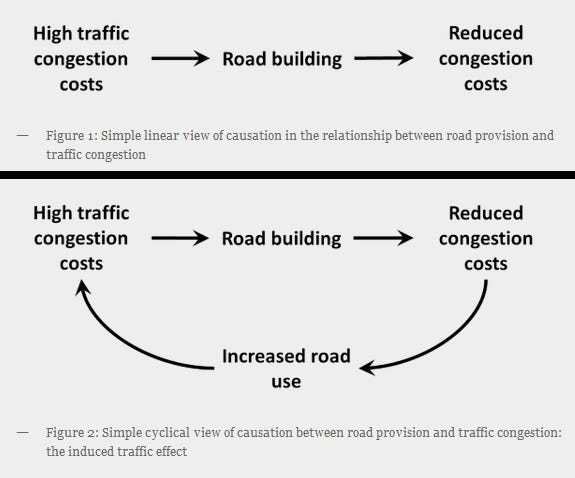
Powerful systems change their world- Any sufficiently powerful system reshapes the world it is deployed in. This is a big reason that AI must constantly be updated in new ways. Our approach of aggregating insights mentioned works well for how things are but struggles to generalize to these new changes that are caused by interaction between us, the world, and this new system. More conceptually, this is why ideas like induced demand in economics are so hard to grasp and plan for.
Good Data Doesn’t Add Signal; it Removes Noise: Think about Feature Engineering, Self-Attention, and any other successful technique to improve the performance of Models. People often treat these techniques as if they add information to the data by helping the data see what didn’t exist before. It’s the opposite. These techniques work b/c they focus the model's scope on what truly matters. In the same way that a sculptor chisels out the statue from a block of marble, good data allows the model to tease out the important relationships from what would be an overwhelming stream of noise.
Data contains Value Judgements: Within any dataset is an implicit value judgment of what we consider worth measuring. Or what we are capable of measuring. This is a very poor approximation of what is worth measuring about the world.
Data is Contextual- Good or bad data is defined heavily by the context. The same map can be fantastic or completely useless based entirely on how we want to use it. This inherent uncertainty does not translate well into generalizable principles, limiting our insight on AGI.
Data is a Snapshot: Good data is static- it models the world as is. It fixes an endlessly chaotic world to a single frozen moment. While this can serve as a useful approximation, that is all it ever is.
Ultimately, my skepticism around the viability of ‘generalized intelligence’ emerging by aggregating comes from my belief that there is a lot about the world and its processes that we can’t model within data. That is the whole purpose of intelligence: to deal with the unknown unknowns that we bump into all the time.
An article like this often leads to some misunderstandings. Before we go deeper, I want to take a second and address some potential misunderstandings-
I think Generative AI can be useful: I would not spend so much time discussing Gen AI if I didn’t think it had utility. It can be useful and versatile, assuming it’s used correctly. This article does not argue that Gen AI as a whole is not useful. Similarly, other forms of AI can all be transformational, and we should look to use it effectively where applicable.
We don’t need ‘AGI’ to have useful AI: Another misinterpretation I often see is the question, “But why do we need AGI?”. My critique of AGI claims is not b/c I think we need AGI for AI to be useful. I critique the AGI hype b/c it is used to shift goal posts and shift the goal posts from the very real AI risks that currently exist. The misdirection towards AGI wastes a lot of time/energy, similar to the “just one more game” trap that my fellow Age of Empires players will be intimately familiar with.
Multi-modality is very powerful: Just b/c I critique multi-modal data as a distraction in AGI talks doesn't mean I don’t believe in multi-modality as a whole. I think multi-modal capabilities are very cool and will unlock AI Deeply (I have been covering them since early 2022).
We don’t need technically complex/impressive AI to build useful AI. The purpose of this article is not to argue for more complex protocols but to encourage more thorough introspection on what problems should be solved by AI+Data. Instead of relying on the technical innovation that will never come, it is important to work with what we have to create truly useful solutions.
To understand the crux of this article, we must first understand what is about AI that makes it so useful to us. So, let’s begin with that.
Why AI Works
At their core, all AI solutions—no matter how complex—work on a simple principle: they take a very complex world and simplify it to a few core processes. Just as the assembly line standardizes mass manufacturing by removing individual variance and focusing on scale, AI aggregates across large volumes of data to create reproducible averages. This is reflected in two distinct ways, depending on the kind of AI you’re using-
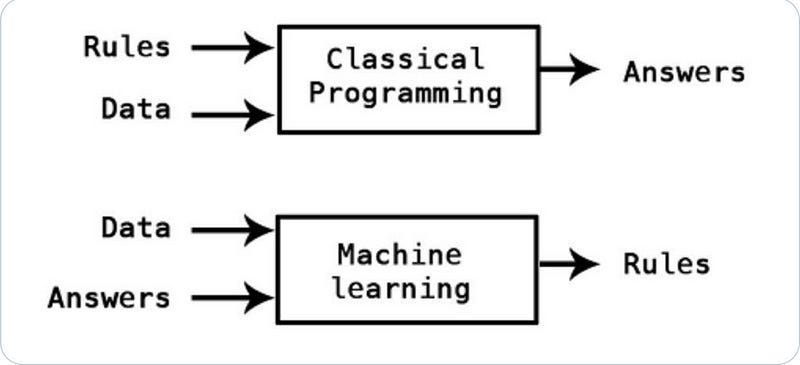
In traditional AI, we analyze the process with our preexisting knowledge to guide our exploration of new answers. These answers are then fed as additional rules, widening the potential search space and increasing the complexity of problems we can tackle. This is why traditional AI techniques like Evolutionary Algorithms are exceptional at developing new stable solutions but struggle with accuracy and performance in domains where we don’t really understand the underlying operational mechanisms.
In Machine Learning-based solutions- we utilize our domain knowledge to build deeper relationships between pre-defined data samples. This improves the performance on well-defined tasks, even if we understand very little about the underlying principles of said task (hence the success of supervised learning, which maps inputs to outputs). However, these struggle with generalization and control. This is why where we get high-performing computer vision solutions that can be broken by changing one pixel-
In this paper, we analyze an attack in an extremely limited scenario where only one pixel can be modified. For that we propose a novel method for generating one-pixel adversarial perturbations based on differential evolution (DE). It requires less adversarial information (a black-box attack) and can fool more types of networks due to the inherent features of DE. The results show that 67.97% of the natural images in Kaggle CIFAR-10 test dataset and 16.04% of the ImageNet (ILSVRC 2012) test images can be perturbed to at least one target class by modifying just one pixel with 74.03% and 22.91% confidence on average.
Once we understand these limitations, we can combine these two techniques to build amazing solutions. Deepmind’s AlphaGeometry uses a special LLM for idea generation (something we don’t understand well enough) and then uses traditional AI to verify/build on these ideas (which can be broken down by rules).
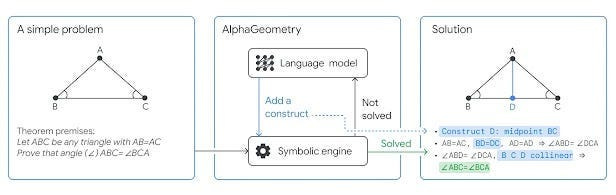
As elaborate as that is, it still relies on similar principles- take a subtask of a very complex problem →, break it down into smaller steps, -> use our generalized knowledge to solve various components-> GG. But what happens when such a system goes into practice?
If our system works well, it will fundamentally change how we do things. The tool and our use will co-evolve, creating new, unanticipated interactions. All of this results in distributional shifts (the average that the AI computed no longer aligns with the Average that the world feeds it), undermining the foundations of these solutions. This is why generalized intelligence always seems like it’s just on the horizon- it seems like we are close to solving the problems of today, and what is more human than our unfounded confidence in the fact that the world is exactly as we understand it and will never deviate from our understanding?
Misunderstanding this leads to many of the high-profile mistakes associated with AI. Take Self-Driving Cars, which struggle with merges b/c there is no right way to do it. It requires on-the-fly adaption, even if it requires technically breaking the rules-
They’re not wrong: Self-driving cars do find merges challenging. In fact, it’s a problem that points to one of the harshest realities facing everyone teaching computers to drive themselves: For the foreseeable future, they’ll be sharing the road with human drivers. Humans who tend to favor flexible, communication-based interaction over following rules by the letter. Humans who can be capricious and inattentive. Humans who can be jerks, humans who can be generous.
“Merging is one of these beautiful problems where you have to understand what someone else is going to do,” says Ed Olson, the CEO and cofounder of the autonomous vehicle company May Mobility. “You’re going to get in the way of someone’s plan, because everyone wants to keep going straight and not let you in. You need to change their mind and change their behavior, and you do that by driving in towards where you want to merge and they finally acquiesce.”
Even if you train self-driving cars with all the data to deal with merges currently, a lot will change in the future—road plans, driver behavior thanks to self-driving cars, car specs, etc. This will require an entirely new set of adaptations, causing new issues. Rinse, repeat.
But what if we had the right set of training data, algorithms, talent, and hardware? Could we theoretically model the world and its future states enough to build AI systems that improvise, adapt, and overcome? And can that be accomplished through the stacking of more compute, training data, and algorithms? That is exactly what we will be talking about next.
Why Data is an Off-Ramp to AGI
Before getting into the specifics of why data can’t adequately model the world, let’s take a second on a more high-level thematic overview of the limits of mathematical insight that forms the foundation of Data/AI.
Mathematical insight ignores what is “obvious” in favor of rigorously defined principles. The foundations of mathematical reasoning rely on systematically building up arguments from these principles. This is great where precision is key, but this kind of thinking is limited in cases where the principles can’t be defined in such a manner. When a principle is felt rather than seen, mathematical reasoning is inadequate. In such cases, we rely on intuition, judgment, and perception to fill in the gaps left by the fuzziness. A blind obsession with algorithmically forcing such fuzzy parts of the world to comply with our need for rigor and precisely defined rules of engagement will only lead to failure.
To prevent this from becoming too abstract or hand-wavey, we will spend the rest of this article discussing the specific ways that data by itself is limited and how this conflicts with the stated goal of building generalized intelligence.
Data is a Snapshot
A good dataset + AI systems hold up a mirror to our processes and help us understand ourselves/our systems better. This is very useful but has a huge drawback for general intelligence- its insights will become outdated in an always-changing world. Let’s say I build a bot to help salespeople identify good leads. A good bot will change meaningfully salesperson behavior, whether it’s in changing the kind of people they pursue, their sales approach, or the actions they perform (not to mention the world outside will also go through economic cycles, new technologies, and other such changes). This is why AI models need to be retrained and realigned, and systems need constant rebuilding. Constantly changing worlds (probability distributions) don’t really see eye to eye with the models.
This problem becomes even worse when we evaluate the nature of data processing (which enables AI) and why it works as well as it does.
Good Data Processing Removes Information
As stated in the tl;dr, good feature engineering, self-attention, and other such mechanisms work because they take a very noisy input and map it to a cleaner representation we can operate on. This involves filtering out signal from the noise (essentially reducing the noise in your representations).
We see this is reflected in all the successful techniques we see in Deep Learning. Selecting only high-quality data improves the signal-to-noise ratio- simplifying the process of creating representations. Microsoft’s new GraphRAG is a good example of how forcing some structure onto your unstructured data (which is in a sense, reducing the degrees of freedom of that data) can provide great results-

CoshNet is another great example of the power of powerful embeddings. Its ability to match SOTA vision models at a fraction of the size and without any parameter tuning relies on its ability to ignore all the noise present in images and focus on building representations of the aspects of the data that matter.

In all such cases, the mechanism for success remains the same—we reduce the breadth of information considered (narrow the search space) and instead focus all the attention on the few promising neighborhoods to explore that domain more deeply. This allows us to spend more of the model's limited representational capacity on learning the true patterns and less on the noise present in the data/model initialization.
You might find it helpful (and more fun) to think of these processes forcing the binding vows from JJK or HxH on our models- they reduce the number of neighborhoods you can explore but allow you to explore the ones left at a higher level.
On another note- this is also why injecting random noise into your training works when we start maxing out on roided-out Foundational Deep Learning Models. At this stage, we’ve already run the models through our standard stack of Size Increases, Dataset Bumps, and longer training cycles and have exploited all the primary neighborhoods there were. The injection of randomly augmented data samples creates entirely new neighborhoods to explore (similar argument applies to Meta’s Self Supervised clustering to identify novel samples)-
The implication of this on generalized intelligence is clear. Reducing the amount of information to focus on what is important to a clearly defined problem is antithetical to generalization. When we try to scale up, signals from one kind of refinement contradict another, creating a confusing mess. Most LLM providers have implicitly accepted this- moving on giant expert models to a sparse Mixture of Expert style architectures, where smaller models/agents handle a predefined set of tasks. This is a subtle but profound shift from the previous narrative of AGI, where one model did everything to super-intelligent levels. The way we’ve been shifting goal-posts, I would not be surprised if a few years from now- Sam Altman and crew throw up their hands and decide that AGI involves adequate performance on an arbitrary set of benchmarks.
This reduction of information is especially is important when we consider the next point.
Data Contains Value Judgements
Fortunately, this should be easier to explain. We don’t collect data for the heck of it. Data is collected with assumptions of what is worth measuring (and what can be measured), capturing only a small part of what is worth measuring. Take data provided by schools to entice students/funding. Institutions will often talk about commercially successful alumni, highlighting numbers such as placement rates, average salary offers, and more. This data is put front and center in evaluations because we have tied the value of formal education with the job benefits it can provide.
Now, I’m not saying that’s wrong. But operating under the same stated assumption that “Education prepares you for a rich and meaningful life”, here are some other stats that might be equally valid under different systems-
Moral Stats—Assuming that education is supposed to guide us down the right path, it is surprising that we don’t compare universities/schools based on the number of criminals they produce. Imagine a school proudly claiming that their business department produced the least number of white collar criminals in the entire NorthEast Area.
Life Expectancy Stats—Schools are supposed to prepare us for meaningful life, so why don’t they talk about the life expectancy/quality of life of their students post-graduation? That seems like a fairly important metric of student success (this statement itself has the value judgment that a long, HQ life is a good thing), so why does no educational institution talk about it?
Once again, I’m not saying these would be better than discussing employment stats. I’m simply pointing out that there are alternative focuses, that would similarly fulfill the stated goals. Measuring the underlying facet (quality of education) is hard, so we instead focus on one set of proxy metrics over the other. We pick these proxies based on our value judgments and reinforce the biases we began with. This process is subtle, and repeated enough leads to the conflating of the proxy and the real-desired end result.

Different domains provide different value judgments, and flattening everything into a latent space doesn’t create a rich nuanced thinker but a mediocrity machine (this has many uses, but superintelligence is not one of them). This is why the only meaningful differentiator b/w large LLMs has been their Data- an emphasis on different kinds of training data beat different value judgments into your model. This process does not jive with the enablement of general superintelligence since it will lack excellence in any one domain (unless overtrained for that domain, which is in its very nature not general).
With that covered, let’s move on to a particularly difficult stumbling block when it comes to building a high-quality training data for AGI.
Data is Contextual
There is no universally valid good data. A detailed 3D topological map is great for camping and terrible for navigating a city. A general AI system would struggle without cues on which input data samples to prioritize for a given task. These cues would be very difficult to transcribe into detailed principles- handicapping the training of our model.
Many data teams ignore the contextuality of their data at their own peril. Even two data sources from seemingly compatible sources often has deep differences. Carelessly aggregating into one training set in such situations leads to …-
In 2019, a bombshell study found that a clinical algorithm many hospitals were using to decide which patients need care was showing racial bias — Black patients had to be deemed much sicker than white patients to be recommended for the same care. This happened because the algorithm had been trained on past data on health care spending, which reflects a history in which Black patients had less to spend on their health care compared to white patients, due to longstanding wealth and income disparities.
Most teams have experienced this to a much lower extent. If you bought/tried to build a new tool based on rave reviews, only for it to not fit into your workflows- you’ve experienced what a mismatch in contexts feels like. This is the death sentence for many promising greenfield tech projects since the opportunity cost of integrating the technologies outweighs the perceived benefits.
When these various limitations of data combine, we get large holes in what we can define rigorously. Holes that cling to your knowledge more than the long-haired, very pale-skinned lady that always stands at my doorway at 2 AM. That is why we combine it with other forms of intelligence (including our own) to solve problems.
As a mathematician, I get the temptation to aim for a world that can be defined by rules. A world that obeys order, no matter how convoluted. A world that will eventually make sense. But ultimately, no matter how much we AI folks would like, the world is not a set of mathematical equations on which we can train our AI. There is no master key, no universal set of principles that can be built upon. Try as we might, there are times that words will fail, experiences that can never be adequately modeled as data, and situations that can never be simplified. And in every such moment where precision fails us, all we must do is to sit and observe in silence.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Welcome honesty 🙏
Thanks Dev. Your article confirms my suspicions about the inherent limitations of AI in its current iterations. Notwithstanding, the mere fact that anyone can access major parts of written knowledge is incredibly useful and empowering. But, it begs the question about how to understand the inherent biases and limitations in any given model without extensive research. In music, “errata lists” showing errors in published versions are very common and useful in performing any given piece because all of them contain errors of some sort. Does such a thing exist for the current models showing bias, holes, etc?