
Why Morally Aligned LLMs Solve Nothing [Thoughts]
One of AI’s Biggest Buzzword is a Red-herring + How to Actually Solve some of AI’s Biggest Problems

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
This article is the final part of our mini-series about Language Model Alignment. If you want to catch the others, make sure you read-
A New Way to Control Language Model Generations: A technique for attribute-based control over LLM generations to have an efficient way to control toxicity, tone, and other aspects of your LLM.
How Amazon is Rethinking human evaluation for generative large language models: A framework for reducing the amount of Bias in Human Evaluations of LLMs.
How to Automatically Jailbreak OpenAI’s o1: Techniques for automatically red-teaming Language Models, told to me by people who were involved in red-teaming o1.
There is a lot of discussion about LLM Safety and how we need to train our Gen AI to become more like Son Heung-Min and less like Diego Costa. Arguments for this alignment tend to fall into either (or both) two major camps-
AGI (or super-intelligence) is coming. It will take over and enslave/do bad things to humans. The only way to stop this is to build Moral Alignment so that AGI is all about Peace and Love (a mindset we humans have fully embraced and can teach flawlessly). This is the premise behind Ilya Sutskever’s new 5B startup.
Existing tools like ChatGPT can be co-opted into tools that can convince their users to perform harmful actions- divorce their partners, discover new super-viruses (if this were so easy, ChatGPT would have solved cancer), be influenced to vote for a politician/policy, join a cult, etc. To such folk, AI must be gated till we can fully train models to identify harmful requests and refuse them.
In my opinion, both mindsets are not only patronizing (comes with a very strong dose of “we know better than you, so shut up and let us run the show”) but also harmful (by prioritizing this kind of moral alignment, we give the LLM providers a pass from addressing the much more real concerns that plague these systems currently). This article will go over these points in more detail (particularly the latter one) to shift the conversation in a more productive direction. As always, this is based on my opinion, and you are free to disagree. If you have any substantial disagreements, send them over, and I’ll be happy to share them/let you guest post about them.
Executive Highlights (TL;DR of the article)
There are several angles one could take to critique the idea of a perfectly morally aligned system. For example, I could argue that on a technical level: AGI itself is a loosely defined idea with no real benchmarks; data is a very lossy representation of reality so it’s impossible to build high-fidelity and generalized representations of it through scale is impossible; or that mathematical thinking itself (which is the basis of all AI) has severe limitations that prevent it from being generalized intelligence.

Or I could take a more people perspective and argue that morality has very few concretes and lots of grey areas- making it very difficult to teach AI right from wrong. I could easily tack on clauses on any situation that change right from wrong, several questions have no truly correct answers (is the society of the Brave New World/WallE- where people are kept fed, safe, and happy through control and drugs good or bad?), and we are champions at not only acting but also celebrating hypocrisy: we root for superheroes while cheering against villains even though both rely on violence to impose their morality on whoever disagrees. The only difference b/w a hero's protection and a villain’s tyranny is that the hero defends the status quo, and, in doing so, justifies our sensibilities. Even in superhero stories where the hero rebels against society- they rebel for a society that approximates our own. There are no modern heroes who fight for the freedom to punch grandmas, kick puppies, or actively promote racism. And there’s shifting morality based on history, which is a whole other can of worms. Best of luck teaching an AI about this.
My apologies for the somewhat long tangent on superheroes and morality. Back to the topic at hand of morally aligning AI.
I want to take another perspective, hopefully one that’s a bit easier to talk about/reason from. In my opinion, one of the biggest problems with Morally Aligned LLMs can be summed up as follows-
the people who benefit most from these systems are not the ones who suffer the risks from the poor development and deployment of these systems.
While the benefits of the development are often fed to the creators, the risks (environmental harm, labor exploitation, …) are often distributed to society as a whole (and even exported to poorer countries)-

To summarise a point from the brilliant Sergei Polevikov, in his excellent writeup, “Doctors Go to Jail. Engineers Don’t.”- all the risks of using AI for medical diagnosis falls on doctors and none on the people that develop these systems. This leads to skewed incentives, where developers shill useless/harmful solutions by using misleading tactics.
We will generalize this. To do so, we will review some case studies highlighting this principle in action. In each case, we see some minor issues brushed under the carpet to focus on the only thing that matters- ensuring that the LLM doesn’t say naughty words and ends systemic racism by promoting inclusivity in every post-
Each of the following problems can be solved (or at least started to be solved) with existing technology, impacts people in real ways, but is not addressed because of skewed business incentives-
OpenAI’s misleading Marketing of o1 for Medical Diagnosis:
OpenAI released their o1 model to a lot of fanfare. One of the most eye-catching parts of the new capabilities is its supposedly high capacity in medical diagnosis (something OAI itself promotes). However, some very simple testing reveals major security concerns that limit its applicability in this task. These issues are never acknowledged in the PR behind the model, leading to a major increase in the chances of misuse of the model (keep in mind this capability is being sold to doctors, who are non-technical users that would lack an understanding of the technical limitations).
Scraping the Internet for More Data:
One of the biggest talking points recently has been platforms like LinkedIn and Substack non-consensually using user data for training their AI models (it’s quite ironic that the same gurus that talk about their favorite Midjourney/ChatGPT prompts also were quick to talk about how to block AI from being trained on your data).

In each case, the AI providers could make relatively simple changes -attribution, payment, and/or active consent- to be more palpable. They didn’t b/c ultimately the creators have no incentive to implement these features (it explicitly goes against their business interests).
Sextorting (mostly) Young Boys on Social Media
Here’s a fun fact- we’ve seen a rapid increase in scammers catfishing young men (including lots of teenagers) for nudes, then threatening to leak them if they don’t meet their demands (this is a very comprehensive report on the topic)

This has led to a huge strain on said boys- some of whom have chosen to commit suicide.
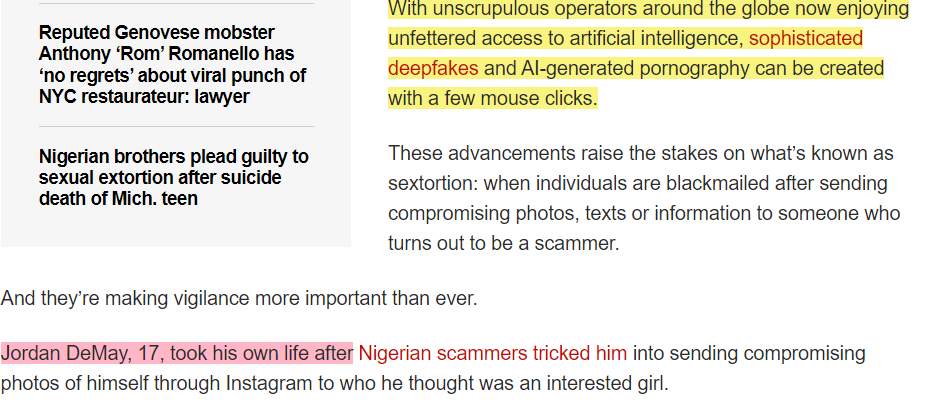
Here’s the kicker. There are several steps that social media platforms could take to significantly decrease the risk of people getting caught with this- better moderation, easy protection fixes, early detection of problematic sources, taking down the accounts/posts that blatantly promote the scams and the like. They haven’t gotten around to it because sticking an LLM chatbot in their apps (shows shareholders that the company is doing trendy things) is obviously more important than protecting the mental health of the users (costs money, does not improve revenue in any way, so will only reduce the margins during investor calls).

You might think I’m exaggerating but this is also something I was told explicitly. Back in late 2020–2021, I worked fairly extensively on scalable Deepfake detection that could be deployed at an extremely large scale (this was the basis of the more recent Deepfake series we did). During this research, I spoke to mid-senior executives at 2 major social networks and 1 major e-dating app, all of whom said the same thing: the work looked interesting but I wasn’t solving a business problem, so investing in such a solution was not worth it.
I guess the only time men’s mental health matters is when we have to talk about them lashing out violently or failing in some other way. As asinine, toxic, and exploitative as the whole “become alpha male, break the matrix” community can get, at least they pretend to care about the issues a lot of young guys face.
But hey, at least the chatbots that we deploy in these platforms won’t make inappropriate jokes that offend the AI Ethics vigilantes on Twitter (where have they moved to now?). Isn’t that what truly matters?
This is not the only case where skewed incentives in the space end up messing up children.
Child Labor and Tech
If you didn’t know, many tech companies rely on suppliers that are known to use child labor in their supply chains-
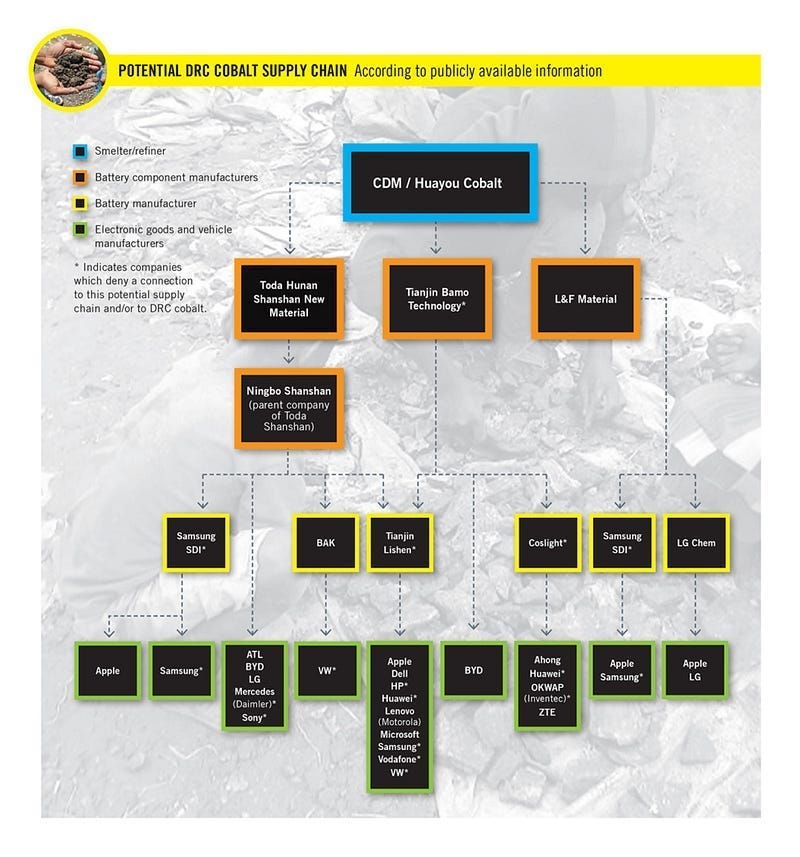
Why does this happen? For a business reason- child labor allows contractors to undercut their competition. This means that when a tech company exec is signing off on which supplier to go with, they will pick the one that uses child labor b/c they only see the price delta.
Now companies with billions of dollars could pay for extensive checks of their suppliers, but this is expensive and doesn’t really help the bottom line. This is not good.
So we get children involved in mining, 18+ content moderation, manufacturing, and more-
Hassan recalls moderating content while under 18 on UHRS that, he says, continues to weigh on his mental health. He says the content was explicit: accounts of rape incidents, lifted from articles quoting court records; hate speech from social media posts; descriptions of murders from articles; sexualized images of minors; naked images of adult women; adult videos of women and girls from YouTube and TikTok.
Many of the remote workers in Pakistan are underage, Hassan says. He conducted a survey of 96 respondents on a Telegram group chat with almost 10,000 UHRS workers, on behalf of WIRED. About a fifth said they were under 18.
So many of the annotations/data that AI requires to generate non-toxic content/keep in line with alignment possibly comes by exposing children to toxic content. Life has a very twisted sense of humor.
This is a very small subset of existing problems that we are overlooking to instead pretend like Morally Aligned LLMs are what we need to focus on. There are several others like autonomous weapons systems, climate load etc- but those are topics where I have (and will continue to) do detailed deepdives on.
We will now get deeper into these problems and discuss how we can start to solve them. As we proceed, I think it’s important to remember that many of these situations are not caused by raging psychopaths who go to sleep by counting the number of lives they’ve ruined. It’s the natural outcome of an incentive structure that pressures people to maximize certain outcomes at all costs. As Hannah Arendt once put it- “The sad truth is that most evil is done by people who never make up their minds to be good or evil.” We are free people, and it’s also up to us to bring the changes we want to see in the world.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
OpenAI and Medical Diagnosis
A large part of why I wrote this mini-series on LLM Safety was our cult and it’s battle with the misinformation . To summarize the events we covered here-
OpenAI claims that their o1 model is really good at Medical Diagnosis, being able to diagnose diseases given a phenotype profile-

I ran the exact prompt given in OpenAI’s blog post, making this claim. No changes whatsoever. 11 times.
Firstly, I got close to 50% error (5 out of 11 times, it didn’t match their output).
6 KBG.
4 Floating Harbor Syndrome.
1 Kabuki.
Not off to the best start. Next I asked it for the probability distributions on each (so top 3 likely instead of top 1). Again, very strange results-
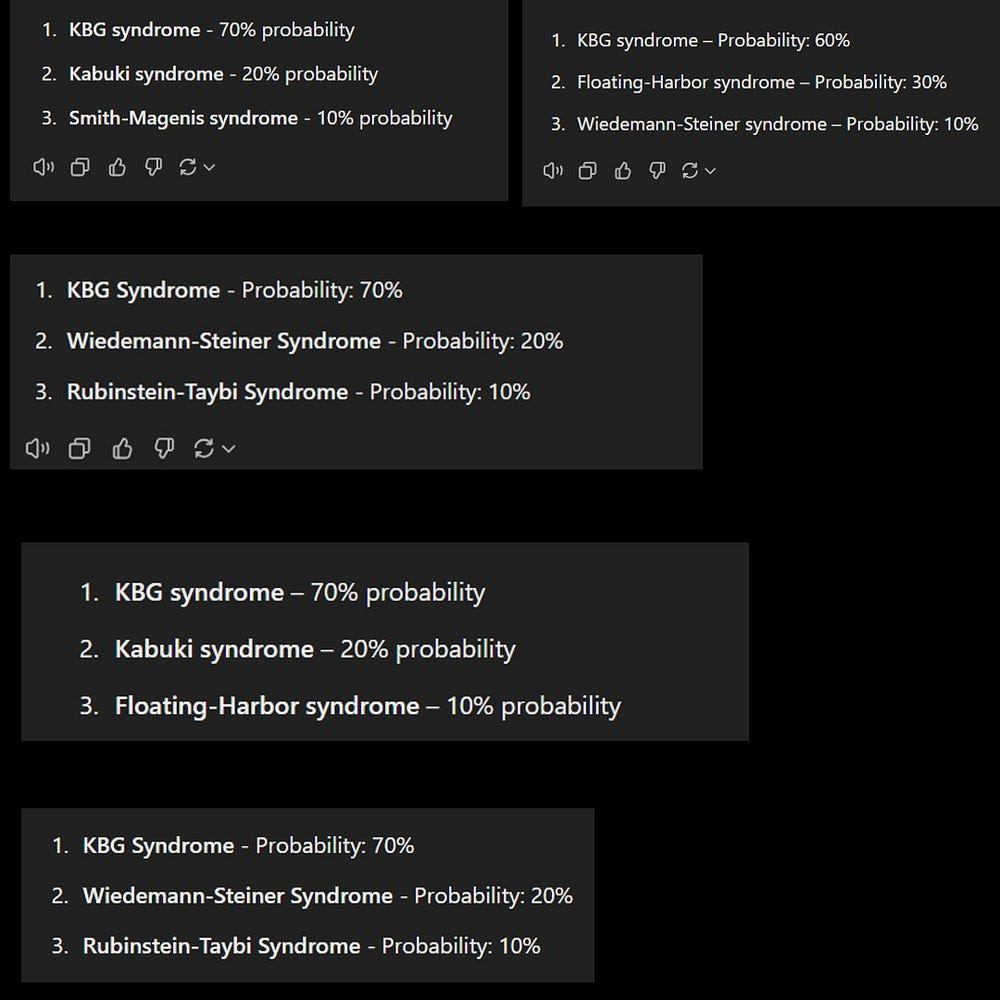
This already would disqualify it as a useful diagnostics tool. But further research makes the situation even worse. One of the common names- Floating Harbor Syndrome- has been recorded less than 50 times in all of history. Any basic medical diagnostic tool would have had to consider this in their prior, and this invalidates pretty much all the results.
So we have inaccuracy (on an example they picked), inconsistent reasoning, and a major flaw in it’s computations. Really picking up that MSN of problems. Not only was this not mentioned when OpenAI first released it, but there was no further acknowledgment of limitations after people have been flagging it.
The latter is a good example of my argument. OAI can invest all the money it wants into Morally Aligning the output. Even assuming you had the perfect way to accomplish this- what good would it be if the company acted in such bad faith- endangering people and causing long-term trust issues from the end adopters-
It’s a huge problem for the healthcare industry. If these companies aren’t held accountable for their sloppy practices and lack of ethics in healthcare AI development, every other developer will assume it’s fine to cut corners and throw half-baked AI models into the market.
This behavior from the tech industry has tarnished AI’s reputation in the medical community.
AI was supposed to revolutionize medicine. Now, thanks to the reckless actions of the IT industry, it’s on pause.
— Another excellent piece by Sergei. He has been an excellent resource on the AI Healthcare space.
OpenAI could have instead-
Been much more open about their model’s limitations.
Build more transparency features to ensure doctors have more confidence in the predictions and provide meaningful feedback. This would also help in the diagnostic work.

Spent a lot more time testing their product for limitations (all my tests were fairly simple and obvious to anyone that understands AI).
They didn’t because this requires honesty and careful building- which goes against their business interests. So, instead, they rely on clickbait and misdirection- all to keep their hype going. No amount of AI Alignment is fixing that (unless they expect their AI to spontaneously manifest into the world and take matters into its own hands).
The funniest part of this outcome- earlier this year, I covered Moral Graph Elicitation (MGE), which was a new alignment technique funded by OpenAI. In my analysis I stressed two things-
The idea was fairly interesting and could spawn some interesting research directions in the future.
It was solving a mostly useless issue- since we were better off not designing automated systems to make moral decisions. And that all the moral alignment in the world was useless if we continued to provide incentives to build and maintain these systems.
I had a disagreement with the authors on the second point- since they felt that Morally Aligned AI might help prevent such systems. To have OpenAI drive my point home, with their most powerful model yet, is the kind of irony I would watch binge-watch Yes Minster for (if you’re having a watch party for this or Nathan for You and want to know if I’m free- the answer is always yes).
Let’s move on to another very real issue that we could be solving instead of worrying about Alignment.
Language Model Training Data and Attribution
As you may have heard, AI companies scrape a lot of data without permission.
Often, this code includes copyrighted data or other kinds of data that people don’t want out in the wild. For example- Github Copilot was shown to have taken someone’s private repository in it’s training data-

We have similar outcomes with AI Art, ChatGPT, and other GenAI tools that use people’s training data- without giving them any attribution.
This is incredibly sleazy behavior that harms the original training data provider. And another outcome that moral alignment does nothing to address. Most interestingly, there are some fairly simple ways to make these a lot fairer-
Try to add attribution for the source (easy to do with text).
Prioritize sharing similar images from your collection before image generation (this will reduce the energy requirements since image creation is very expensive). Only create the images if the user is really insistent.
In all cases with images, it’s not super hard to say, “Hey, if you liked this image- you may like these ones created by the following users” linking to the users. This way, the people whose training data enabled your images would also get some support.
Actively ask for permission to take training data.
Pay the creators for their data (optional)
This isn’t terribly hard to build, doesn’t diminish the product in any way, and will allow for a more productive relationship with all parties. Even if the solution isn’t perfect, it can still be improved upon. And all of this leads to a system that’s a lot more moral than anything you get from the whole alignment process.
The argument doesn’t change for the other 2 cases. So, instead of getting you sick of me repeating the same core idea, I’ll throw out some stats to show how existing solutions could be built on and refined to address the challenges for the next challenge.
Stopping Sextortion on Social Media
First, let’s establish that this is a real problem-
The tenfold increase of sextortion cases in the past 18 months is a direct result of the Yahoo Boys distributing sextortion instructional videos and scripts on TikTok, YouTube, and Scribd, enabling and encouraging other criminals to engage in financial sextortion.
This one example of people sharing tips on how to do this openly-

The scammers often use AI-generated images-

To get the victim to send nudes, which the scammer then threatens to spread with the victim’s social connections-

When it comes to solutions, there are plenty of things that can be done.
Firstly, adding a better privacy feature will stop the scammers from immediately being able to contact the victim’s connections (which is the cruz of the blackmail).
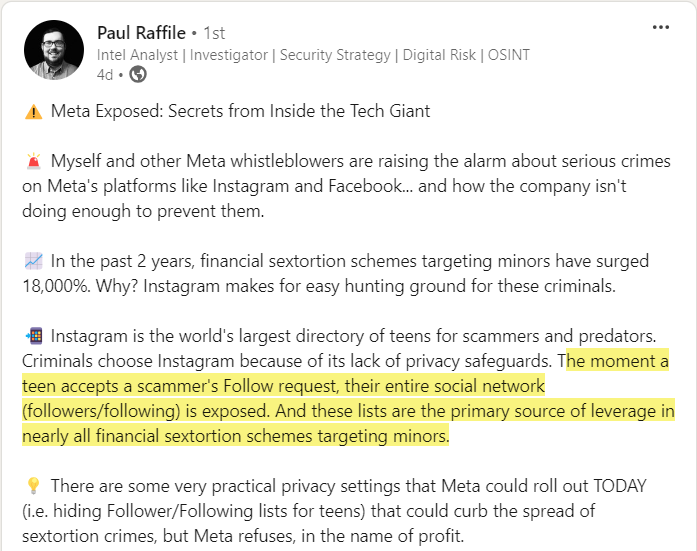
Instagram can mitigate a vast majority of financial sextortion cases by hiding minors’ Followers and Following lists on their platform by default, and by giving all users the option to make these lists private.
This is a high ROI, low complexity aspect of the solution that can save a lot of people from a lot of pain. But it’s not all platforms can do.
They can also improve detection of possible scammers. This involves account-level activity (seeing an uptick in activity (caused by bots), major changes in behaviors (account takeover)…), or more meta-analysis. Grab, for example, uses graphs for fraud detections- which might be useful framework-

Hiring more people for support and review in sextortion cases is another big lever that can be pulled. There are several other recommendations (again, highly recommend this report). None of these require high levels of moral alignment for AI. All of these will be much more useful to the outcome. None of these have been implemented because these increase operational costs while not increasing profits.
When it comes to Child Labor in Tech Supply chains, I really don’t have any meaningful suggestions. Maybe one of the AI Ethics experts on Instagram/Twitter can give a seminar to the people pushing Children into the supply chain- so that they can realize how unethical that is. But if any of you have anything meaningful to add on that front- happy to let you take over that discussion. In the meantime- I’m fairly confident that spending a few million dollars on the moral alignment wouldn’t really fix it.
As always, I look forward to hearing what you have to say. Thank you for reading, and have a wonderful day.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Great piece, Devansh. We need more of this.
By the way, I noticed this strong dose of “we know better than you, so shut up and let us run the show” is also prevelant in the race/rhetoric around AGI.
“Trust us, we will safeguard it,” they say. Yet none of the behavior living up to it is giving us any confidence that the actual human beings (‘AI leaders’ they call them) currently in charge would do the right thing. Deceptive humans are what we truly have to worry about.
I had a conversation recently where I explained that everything we see today that you described in here existed before hand. AI is just making it easier. We like to blame AI but what blows my mind is how diabolical so many humans can act. It's like the human traficking happening across the US souther border where young women are exploited into sex slavery. WTF is wrong with us at a baseline level?