
How Amazon is Rethinking human evaluation for generative large language models [Breakdowns]
Reducing Bias and Improving Consistency in LLM Human Evaluations

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Given how important (but misunderstood) the topic is, I have decided to orient our next few pieces on safe and responsible AI. I find that too much of the AI Safety conversation is focused on fantastical or extreme outcomes- someone making a bio-chemical bomb using ChatGPT, mental health breakdowns in minorities b/c they don’t get represented in pictures, or AGI enslaving us- and not on real issues around these systems today: responsible disclosure of limitations (OpenAI misleading people on o-1’s medical diagnostic capabilities), stealing IP, the development of mass-surveillance systems, increased environmental loads, the lack of transparency in many automated decision makers (even in high-sensitivity fields), etc.

Big Tech companies have been happy to lean into this trend because it allows them to put off working on real problems by claiming they’re trying to solve these imaginary ones (no one loves the idea of utopia more than a tyrant). However, Amazon’s “ConSiDERS — the human-evaluation framework: Rethinking human evaluation for generative large language models” is a welcome departure, as it attempts to tackle a very real issue in the evaluation of Language Models- the several issues with human evaluation of LLMs. The authors present a new “ConSiDERS-The-Human Framework” (CTH for conciseness) to tackle this.
Since benchmarks are not as flashy (or easy to interact with) as models, it can be easy to overlook their impacts. However, I believe this framework could be a fairly impactful player in the AI industry (not in the GOAT conversations, but at least a generational talent)-

If that interests you, let’s look into the framework to see how we can adapt it in our evaluations.
Executive Highlights (TL;DR of the article)
Key Terms: The following terms are important for understanding the article
Processing Fluency: The ease with which information is perceived and processed by the human mind. High fluency can lead to positive evaluations, even if the information is not accurate.
Halo Effect: A cognitive bias where a positive overall impression of something (e.g., an LLM’s fluency) influences the evaluation of its individual attributes (e.g., truthfulness).
Inter-rater Agreement (IRA): A measure of how much two or more evaluators agree on their assessments. Low IRA indicates potential problems with the evaluation design or guidelines.
Extrinsic Evaluation: Assessing the impact of an LLM’s output on an end-user task or system (e.g., measuring productivity gains from using an LLM-powered email assistant).
Intrinsic Evaluation: Evaluating the properties of the LLM-generated text itself, such as fluency, coherence, and factual accuracy.
The Problem with Current AI Evaluations
Fluency fools us: LLMs are so good at generating fluent text that we often mistake it for being factually correct or useful. This “halo effect” leads to inflated evaluations.
An artificial-intelligence (AI) chatbot can write such convincing fake research-paper abstracts that scientists are often unable to spot them, according to a preprint posted on the bioRxiv server in late December1. Researchers are divided over the implications for science.
-Source. Fluency and Confidence can make a lot of people accept things at face value.
Bad test sets: Existing benchmarks and datasets are often too easy, too hard, or simply not representative of real-world use cases. This makes it difficult to assess LLM capabilities accurately.
Ignoring human factors: Current evaluation methods often neglect cognitive biases and user experience (UX) principles, leading to unreliable and inconsistent results.
Explicit user feedback such as 1–5 rating scales, and preference-based tests are inherently subject to cognitive uncertainty, therefore the same user can change their rating on the same item when asked again at a later point in time, even within a few minutes after the initial rating…Uncertainty in user feedback is a well-known problem in recommendation systems, where a user’s rating is considered to be noisy (Hill et al., 1995). Jasberg and Sizov (2020) demonstrate the scale of the problem where 65% of the users change their rating even within short intervals between re-rated items.
Lack of scalability: Human evaluation is expensive and time-consuming, hindering wider adoption.
Responsible AI is an afterthought: Issues like bias, safety, and privacy are rarely considered during evaluation.
This is what CTH seeks to solve. Let’s look at the 6 pillars it uses-
The ConSiDERS-The-Human Framework
. Consistency: Ensure reliable and generalizable findings by addressing issues like -
Ill-defined guidelines: Vague or incomplete instructions for evaluators lead to inconsistent judgments. The paper recommends using a 3-stage workflow to improve guidelines: (1) identify ambiguous samples, (2) label them for clarification, and (3) revise guidelines with these examples.
High task complexity: Asking evaluators to perform complex tasks can overload their cognitive capacity, leading to errors and inconsistencies. The solution is to simplify tasks, for example, by breaking down a long text into atomic facts for easier verification.
Ill-suited evaluators: Using unqualified or poorly trained annotators can introduce bias and inconsistency. The paper suggests using qualification exams, attention check questions, and “exam sets” with known answers to identify and filter out unreliable evaluators.
Small sample size: A small number of evaluators or test cases can lead to unreliable results. Increasing the sample size can mitigate experimenter bias and improve statistical power.
Rating scales: While commonly used, rating scales like Likert are inherently subjective and prone to cognitive fluctuations. The paper suggests exploring alternative methods like denoising algorithms to improve consistency.
2. Scoring Criteria: Use criteria that go beyond fluency and coherence to capture deeper nuance- including domain-specific and responsible AI aspects.
Domain-specific criteria: Evaluation criteria should be tailored to the specific domain and task, for example, evaluating legal LLMs on case analysis and charge calculation.
Responsible AI criteria: LLMs should be evaluated for bias, safety, robustness, and privacy to ensure responsible development and deployment.
3. Differentiating: Develop test sets that effectively distinguish between LLM capabilities and weaknesses.
Effective test sets: Test sets should be challenging enough to differentiate between various LLM capabilities and weaknesses. They should also represent real-world use cases and avoid relying on shortcuts or spurious correlations.
End-user scenarios: Evaluation should focus on how LLMs perform in real-world scenarios, considering the diversity and creativity of user queries and the potential for harmful consequences. This helps us account for the various ways a user might ask the same question, and has been a problem shown in LLMs before-

Robustness testing: LLMs should be tested for their vulnerability to basic perturbations and their understanding of linguistic concepts like negation. The use of tricks like Soft Prompts allows us to build more “generalized learning”.
4. User Experience: Incorporate UX principles and mitigate cognitive biases to obtain more accurate and meaningful feedback.
Mitigating cognitive biases: The paper highlights several cognitive biases that can affect human evaluation, such as the halo effect (conflating fluency with truthfulness) and anchoring bias (over-reliance on initial information). It provides specific recommendations for mitigating these biases, such as shuffling display order and splitting tasks into atomic facts.
Perception vs. performance: While user perception is important, it should not be the sole basis for evaluation. Objective performance metrics, such as efficiency and accuracy, should also be considered.
Usability studies: For LLMs designed to assist end users, usability studies are crucial to assess their impact on productivity and user satisfaction.
5. Responsible: Evaluate LLMs for bias, safety, robustness, and privacy, and ensure that the evaluation process itself is bias-free.
Model behavior: LLMs should be evaluated for bias, safety, truthfulness, and privacy to ensure responsible development and deployment. This includes testing for data leakage, harmful content generation, and susceptibility to privacy attacks.
Evaluator bias: The diversity of human evaluators should be considered to mitigate bias in the evaluation process itself. Demographic information about evaluators should be reported to assess the representativeness of the results.
6. Scalability: Explore strategies to make human evaluation more cost-effective and efficient-
Automation: Exploring automation strategies, such as using LLMs to evaluate other LLMs, can help reduce the cost and time of human evaluation.
Efficient UI design: Designing user-friendly interfaces for human evaluators can improve efficiency and reduce annotation time.
Effective test sample selection: Identifying the most informative test samples can reduce the number of evaluations required without compromising the quality of the results.
Most of the information from the paper is in this tl;dr (it’s not a super complex paper). Instead, I will spend the rest of the article playing around with the pillars and some considerations/important information that can guide our implementation of this framework into our pipelines.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Improving Consistency for Evaluations
Dealing Ill-defined Guidelines: Detecting the Ambiguity Trap
The authors demonstrate how ambiguous seemingly obvious tasks can be-
Ill-defined guidelines are often ambiguous, incomplete, do not address boundary cases, and do not provide adequate examples (Gadiraju et al., 2017). To illustrate this point, Pradhan et al. (2022) use the example of a seemingly simple task “Is there a dog in this image?” where the authors point out how even this simple task can elicit several clarification questions such as “Does the dog need to be a real animal?”, “What if the dog is only partially visible in the image?” and “What about a wolf?”.
Vague or incomplete instructions are a breeding ground for inconsistency. Different evaluators will inevitably bring subjective interpretations, leading to wildly varying scores. This is not something you want if you want precision in your answers-

To solve this, we can do 2 possible things-
Iterative Guideline Refinement: The paper gives us a 3-stage workflow to iteratively identify vague instructions and get them clarified (see tl;dr). This is a good starting point, but it can be further enhanced. Instead of relying solely on expert annotators, we can leverage the collective intelligence of a larger pool of evaluators. By analyzing their feedback and identifying common points of confusion, we can iteratively refine the guidelines, making them clearer and more comprehensive. Identifying common differences in confusion b/w experts and normies might even give us some insight into training gaps that we need to address for future foundation models.
Automated Ambiguity Detection: Here’s a wild idea- Could we train a classifier to detect vague or ambiguous language in evaluation guidelines? My working hypothesis is that the vagueness of instructions would reflect in the embedding of the instruction (or at least some key words there) being on a decision boundary that can confuse-
By feeding the classifier a dataset of guidelines labeled for clarity, we could potentially automate the process of identifying problematic instructions. However, this approach faces challenges. Even if this approach works (no confidence it will), it’s crucial to ensure that the classifier doesn’t simply flag all complex or technical language as ambiguous, as some level of complexity is often necessary for accurate evaluation.
Speaking of Complexity-
High Task Complexity: Cognitive Overload
Asking evaluators to perform complex tasks, especially under time pressure, can lead to cognitive overload, increasing the likelihood of errors and inconsistencies. Imagine evaluating the factual accuracy of a lengthy LLM-generated summary. Keeping track of multiple facts, cross-referencing sources, and making nuanced judgments can quickly become overwhelming.
Task Decomposition: Breaking down complex tasks into smaller, more manageable units can significantly reduce cognitive load. Instead of evaluating a whole summary, we could ask evaluators to verify individual facts, making the task more focused and less demanding. We can even pull an AlphaGeometry and use symbolic reasoning/other kinds of AI for multiple verification steps-
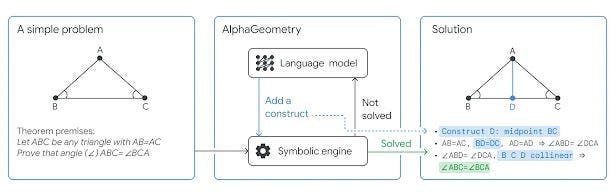
This approach, however, requires careful consideration of how to aggregate individual judgments into an overall score, ensuring that the decomposition doesn’t distort the evaluation.

Visual Aids and Interactive Tools: Providing evaluators with visual aids, such as highlighting key information or displaying relevant sources alongside the LLM output, can help them process information more efficiently. Interactive tools, such as allowing evaluators to mark specific sections of the text or ask clarifying questions to the LLM, can further reduce cognitive load and improve accuracy. More details on this soon, since I’m building this out for a client in a very high-impact field.
The next challenge has to do with the evaluators
Ill-suited Evaluators: Expertise Matters
Not all evaluators are created equal. Matching evaluator expertise to the task domain is crucial for accurate and consistent assessments. Asking a layperson to evaluate the technical accuracy of an LLM-generated scientific paper is likely to yield unreliable results. Get good people and test them well before you throw them on your data. It's fairly simple; there's no need to overcomplicate it.
Small Sample Size: The Statistical Trap
Small sample sizes, both in terms of evaluators and test cases, can lead to unreliable results. Imagine evaluating an LLM on a sentiment analysis task using only ten test cases and three evaluators. A single outlier, either in the test set or among the evaluators, can significantly skew the results.
There are techniques to deal with this, like Data Augmentation, getting more evals, resampling etc. We’ll cover this on another time, when I start doing deep dives into the synthetic data industry.
Rating Scales: Navigating Subjectivity
Rating scales, while commonly used, are inherently subjective and prone to cognitive uncertainty. The same evaluator might assign different ratings to the same item at different times, depending on their mood, fatigue level, or other factors.

Recommendation Systems have developed some techniques to filter out noisy ratings and improve reliability. These algorithms analyze patterns in the rating data to identify and adjust for individual evaluator biases or inconsistencies. However, these algorithms require large amounts of data to be effective, and they might not be suitable for all evaluation tasks. We could possibly use pregenerated profiles to reduce the data required, but a lot of this is speculative. To quote, “Improved recommender systems by denoising ratings in highly sparse datasets through individual rating confidence”
In addition, inconsistent behaviours of users in rating items may add some noise to data, which makes the ratings more untrustworthy leading to less accuraterecommendations. In this manuscript, we introduce an individual ratings confidence measure (IRC) to calculate the confidence of a given rating to each item by the target user. IRC consists of 5 factors that help to have more information about the interest and boredom of users. User ratings are denoised by prioritizing extreme and high-confidence ratings, and finally, the denoised ratings are used to obtain similarity values. This approach leads to a more accurate neighbourhood selection and rating prediction. We show the superiority of the proposed method when compared with state-of-the-art recommender algorithms over some well-known benchmark datasets.
Don’t worry this was the longest pillar. The others will be relatively easy to get through.
We’re going to skip Pillar 2 here because I want to do an in-depth look at domain-specific evaluations another time. This is something I need to explore in-depth for Law since I’m working on a legal AI startup (looking for funding and partners, so reach out if you’re interested!!).
For now, let this quote scratch your itch-
“In addition to the exhaustive evaluation categorization provided in the MQM framework, responsible AI (RAI) must be factored into human evaluation. Sun et al. (2024) propose 6 categories for RAI evaluation — truthfulness, safety, fairness, robustness, privacy, and machine ethics. Domain-specific customization and extensions also form an integral part of evaluation”
Onwards to the next section-
Differentiating: Unveiling True Strengths and Weaknesses
Turns out current evals don’t always do a good job at pushing your LLMs to their limits-
Traditionally, models have been evaluated using public datasets and benchmark such as GLUE (Wang et al., 2019b) and Super-GLUE (Wang et al., 2019a). These evaluations are not without their share of problems as models can exploit weaknesses in the official test sets relying on shortcuts or spurious correlation — such as length of the input — to predict the target label achieving high performance yet non-generalizable beyond the official test set (McCoy et al., 2019; Elangovan et al., 2023; Gururangan et al., 2018). In addition to these problems, evaluating the current generation of SOTA LLMs poses further challenges. 1) LLMs are trained on billions of tokens available on the internet, and the training data used is rarely well documented. Hence, these LLMs may have consumed public benchmark test sets as part of their training data (Magar and Schwartz, 2022; Sainz et al., 2023). 2) The models are generative, producing natural language output unlike a model trained on a classification task, making it difficult to automate evaluation and thus are far more reliant on human evaluation. 3) The LLMs are capable of following natural language instructions to solve a vast variety of tasks, hence they need to be evaluated on a range of instructions provided as prompts that emulate end-user use cases.
So how can we push this-
Effective Test Sets:
Adversarial Examples: Deliberately crafting challenging examples that exploit known LLM weaknesses can help identify areas for improvement. This could involve introducing subtle perturbations to the input, such as changing a few words or adding noise, to see how the LLM’s performance is affected. Adversarial training, where the LLM is specifically trained on these challenging examples, can help improve its robustness and generalization ability. You can even push this into full-on red-teaming so see how robust your guardrails are-
Dynamic Benchmarking: Static benchmarks can quickly become outdated as LLMs evolve (or they can added into the training set). Dynamic benchmarking platforms, where new test cases are continuously added and models are re-evaluated, can provide a more accurate and up-to-date assessment of LLM capabilities. This requires a collaborative effort from the research community to contribute new test cases and maintain the platform. It would be a great way to involve the OpenSource community.

However, just relying on test sets isn’t enough. The only way to know if you’re ready to play in a game, is to play a game-
Simulating Real-World Interactions-
Test sets should go beyond isolated NLP tasks and simulate real-world interactions, capturing the complexity and unpredictability of human language. This could involve creating conversational scenarios, where the LLM needs to engage in dialogue, understand context, and respond appropriately. For example, evaluating a customer service chatbot might involve simulating customer interactions, including handling complaints, answering questions, and providing personalized recommendations.

For LLMs, this can involve testing them on very long contexts, throwing a lot of unstructured data, weirdly structured data, and whatever else your sick, twisted mind can come up with.
I’m going to say something shocking- we build software (including LLMs) for people to use. So let’s discuss the human user experience and where that’s relevant for our evals-
User Experience-based Evals
We need to move beyond purely objective metrics and incorporate subjective human feedback to understand how LLMs are perceived and experienced by real users.
Mitigating Cognitive Biases:
Blind Evaluation: Masking the identity of the LLM being evaluated can help reduce bias. This could involve presenting evaluators with outputs from different LLMs without revealing which LLM generated each output. This prevents evaluators from being influenced by their preconceived notions about specific LLMs or their developers.
Counterbalancing: Varying the order in which LLMs are presented to evaluators can help mitigate order effects, where the evaluation of one LLM might be influenced by the previous LLM evaluated. This ensures that each LLM has an equal chance of being evaluated first, last, or in any other position.
Perception vs. Performance:
A/B Testing: Comparing different versions of an LLM or different LLMs side-by-side can provide valuable insights into user preferences and how they relate to objective performance metrics. This could involve presenting users with different LLM outputs for the same task and asking them to choose which output they prefer or find more helpful.
Qualitative Feedback: Collecting open-ended feedback from users can provide rich insights into their experience with LLMs. This could involve asking them to describe their overall impression of the LLM, what they liked or disliked, and what they found confusing or frustrating. Analyzing this qualitative feedback can reveal usability issues, identify areas for improvement, and uncover unexpected user needs.
We can also explore Think-Aloud Protocols: Asking users to verbalize their thoughts while interacting with an LLM-powered system can provide valuable insights into their cognitive processes and decision-making. This can reveal how users understand the LLM’s capabilities, how they interpret its outputs, and what strategies they use to interact with it. This is the inverse of transparency into models, but works on the same principle (understanding what drives decision making leads to more insight into what should be done for the future).
Next we have the buzzword that everyone loves to throw around. Let’s talk about responsible LLMs
Responsible: Building Ethical and Trustworthy LLMs
We will do an in-depth look into safe AI soon, but if I had to summarize my view on safety, an AI is safe if we can account for all its behaviors. The less predictable our system is, the unsafer it is. That’s really the only part of AI safety I care about. The rest (ensuring it’s not misused) is something that I leave on the developer and systems (I believe we as a community must make decisions on building solutions that are safe, instead of outsourcing that decision to a machine).
AI Safety has many perspectives. Let’s explore each, one at a time.
Model Behavior:
Explainability and Interpretability: Understanding why an LLM produces a particular output is crucial for building trust and ensuring accountability. Techniques like attention visualization, which highlights the parts of the input that the LLM focused on, can help make LLM decision-making more transparent.

Some people like to use “explain your thinking” with LLMs but I’m personally not a huge fan of that. It doesn’t make the process any less variable, and it gives a false sense of transparency. I think the transparency metric should be coded into your system, as opposed to being offloaded to an unreliable and stochastic black-box.
Auditing and Accountability: Regularly auditing LLMs for bias, safety, and privacy violations is essential for responsible use. This could involve developing automated tools to detect problematic outputs or establishing independent review boards to assess the ethical implications of LLM applications. Creating clear accountability mechanisms, where developers and deployers are responsible for the consequences of LLM behavior, can further incentivize responsible development.

Then we look at the Safety from an Evaluator Perspective-
Evaluator Bias:
Diversity and Inclusion: Ensuring a diverse pool of evaluators, representing different backgrounds, perspectives, and lived experiences, is crucial for mitigating bias in the evaluation process. This requires actively recruiting evaluators from underrepresented groups and creating an inclusive evaluation environment where all voices are heard and valued.
Bias Awareness Training: Providing evaluators with training on bias awareness can help them recognize and mitigate their own biases. This could involve educating evaluators on common types of bias, providing examples of how bias can manifest in LLM evaluation, and teaching them strategies for reducing their own biases. Making everyone read Thinking Fast and Slow would be a great start since it is a fantastic book to reveal our cognitive blindspots.
Finally, we address the final boss of all tech projects- scalability. Something like LLMs, which are meant to act as mini-platforms, must be able to operate at scale. So, how can we use humans for scalable evaluation? Let’s end with that-
Scalability: Making Human Evaluation Practical and Sustainable
We can apply the following strategies
Automation:
Hybrid Evaluation: Combining automated metrics with human judgment can leverage the strengths of both approaches. Automated metrics can pre-screen LLM outputs, identifying promising candidates for further human evaluation. This can significantly reduce the workload for human evaluators, allowing them to focus on the most challenging or ambiguous cases.
Human-in-the-Loop Learning: Integrating human feedback into the LLM training process can improve the LLM’s ability to align with human preferences and values. This could involve using human feedback to fine-tune the LLM or to guide its exploration of the search space. However, ensuring that human feedback is used responsibly and doesn’t inadvertently introduce new biases is crucial.
Efficient UI Design:
Gamification: Making the evaluation process more engaging and interactive can motivate evaluators and improve their performance. This could incorporate game-like elements, such as points, badges, or leaderboards, to incentivize participation and encourage high-quality annotations.
Adaptive Interfaces: Tailoring the evaluation interface to the individual evaluator’s skill level and preferences can improve efficiency and reduce cognitive load. This could involve providing different levels of guidance or support, adjusting the complexity of the tasks, or personalizing the presentation of information.
Effective Test Sample Selection:
Active Learning: Using active learning techniques, where a model helps select the most informative test cases, can significantly reduce the required evaluations. This involves training the model on a small set of labeled data and then using the model to identify the most uncertain or ambiguous examples for further human labeling.
Prioritization: Prioritizing test cases based on their potential impact or importance can further improve efficiency. This could involve focusing on test cases that are likely to reveal critical model weaknesses, test cases that are relevant to specific user needs, or test cases that are representative of high-stakes scenarios.
All these combine to give CTH framework. While nothing about the framework is revolutionary, having it all in one place is very helpful to ensure that we can check things off the list. The paper also comes with a checklist you can refer to, and if you’d like to talk about how you could apply something similar to your work- shoot me a message.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819