
Why Data is an Incomplete Representation of Reality [Thoughts]
A look at some major limitations of Data

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Words are a medium that reduces reality to abstraction for transmission to our reason, and in their power to corrode reality inevitably lurks the danger that the words themselves will be corroded too.
-“Sun and Steel”, Yukio Mishima. Mistake data for reality, and you will soon be enveloped by a bastardized version of reality.
PS- “Sun and Steel” is one of the most beautiful books I’ve ever read. If you appreciate well-written prose, I highly recommend it. I don’t know what they feed their authors, but b/w Murakami, Musashi, Akutagawa, Dazai, and Mishima- Japanese literature has some of the best-written works I’ve ever seen.
Executive Highlights
Recently a Yann LeCunn tweet gained a lot of attention. In it, he states that “In 4 years, a child has seen 50 times more data than the biggest LLMs... Text is simply too low bandwidth and too scarce a modality to learn how the world works.” Combined with Meta’s entry into the AGI race, this has led a lot of people to assume that superhuman AI is all about scale and good data.
While good quality data and appropriate scale are both extremely important for the development of AI systems, it is extremely simplistic to only account for these when making decisions (even Yann’s followers pointed this out in the several great refutations/responses to his tweet). Not accounting for other factors can lead to incomplete, misaligned, or even ultimately harmful systems.
Instead of simply responding to the Tweet/some extensions of it, I wanted to try something new. In this article, I want to explore the limitations of data. While data can be an incredibly important tool, there are other kinds of intelligences that aren’t encoded properly into our datasets. Acknowledging this is critical to understanding what Data/AI can and can’t do.
Specifically, here are 3 kinds of intelligence that data can often overlook-
Cultural Intelligence is the type of intelligence that gets encoded into societal norms and practices w/o a strictly rational explanation. We often underestimate how much of our intelligence is cultural, and our (in)ability to encode this type of intelligence into data can hamper AI training. This shows up in tasks like LLM alignment and Self-Driving Cars.
Delusional Intelligence is the ability to create models based on incomplete sensory inputs (creating 3D world models from 2D projections or narratives out of incomplete intelligence). But the principle goes beyond that. What is called ‘reading between the lines’ is nothing more than our ability to hallucinate implications out of data points. By its very nature, such intelligence is not encoded into Data.
Subjective Intelligence is the intelligence of a particular person/group that goes against the norm. Population-level studies can often overwrite conflicting narratives from smaller subgroups, which can lead to suppression and a lack of diversity. This is shown with employee tracking AI, which tries to utilize Data to measure productivity. Normative metrics of productivity (which are dubious enough as is), especially hurt disabled people and other ‘outsiders’. Similar problems occur in AI for applicant evaluations.
In this piece, we will explore the implications of missing these intelligences. I won’t make any claims about how useful this article will be to your needs, but hopefully, it does help you see things in a different light.
Before we dive into it, let’s first take a look at what it is that Data and AI actually tell us.
What do we Really Learn from Data?
Take a second to think about the above question. What kind of insights do we hope to glean from our data or the AI we build?
The way I see it, Data (and the AI we build on it) acts as a mirror that reflects information about our systems and processes back at us. People drastically underestimate how much of what we conceive, build, and measure is influenced by our personal and societal biases. Data is not so much an objective statement about the world, as much as it is a crystallization of our subjectivity. Show me what metrics an organization chooses to measure and improve, and I can tell you what that organization values. By putting data/AI out there, we have a way to analyze our own internal biases (we covered this idea when we discussed how Prompt Engineering would change the world). After all, we are all much better at identifying problems with others than doing some self-reflection.
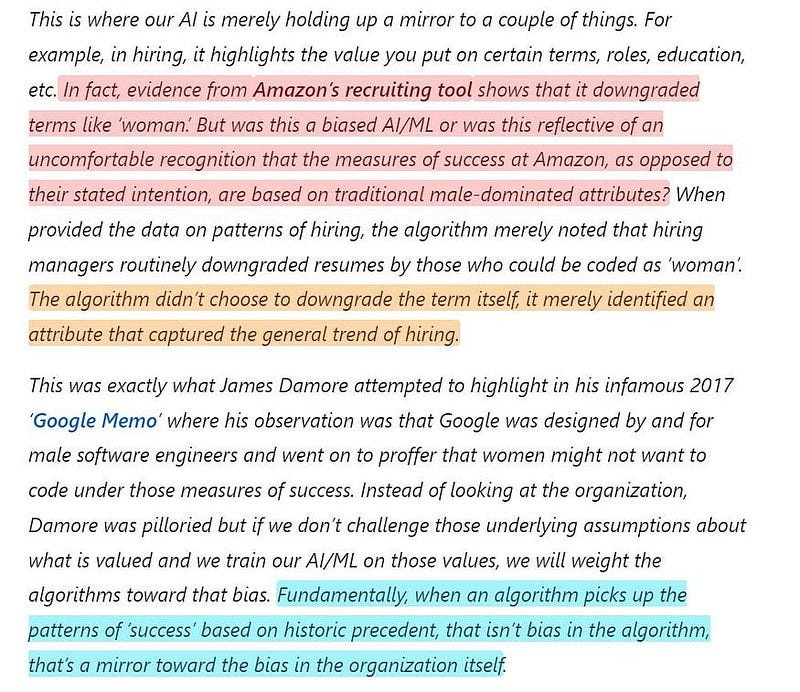
This is reflected in all kinds of processes. Recently, I did a comprehensive health check-up. The process took hours and helped me learn a bunch of things. However, what stood out to me most was all the things that the test chose to not measure. Here are a few attributes that weren’t measured in my “complete health check-up”-
VO2 Max. FYI, this is one of the best predictors of your long-term health- “In one large-scale meta-analysis in 2022, for instance, subjects who ranked in the top one-third of aerobic fitness — as measured by VO2 max — had a 45% reduced risk of death from any cause compared with individuals in the lower third.”
Muscle Strength
Joint Flexibility
Tendon Strength
Any kind of mental health checks.
Generally, as people age, they struggle with the above attributes. Given their importance to our long-term wellness, it is very interesting that all of these were omitted from my health checks. Even w/o reading any scientific research, I’m sure you would agree that all of these attributes are key for longevity.

But that’s not all. Ancient Greeks would start glitching if they saw that my measurement of health didn’t contain any information about my beauty. Someone inspired by Confucius might label me mentally and ethically deficient b/c of my very deep lack of appreciation for poetry (and/or my generally awful aesthetic sensibilities). Other health standards might be worried about whether I was possessed by evil spirits or whether my energies ‘were aligned’. Even for something as objective and scientific as health, what we choose to value as markers of good health can be based heavily on societal assumptions of what is important to be healthy. If an alien were to study my health reports, it would probably learn as much about our health system and what it considers important for health as it would about how healthy I am.

Study any objective metric/measurement, and you will quickly learn about all kinds of limitations, exceptions, and axioms that come with it. This shouldn’t come as a shock. Ultimately by measuring Data, we are trying to impose rationality on an absurd world. Inconsistency is bound to happen. That doesn’t mean that data or the models aren’t useful. But it is important to always remember that any system we build always has very complex relationships, and things are rarely as cause and effect as simplified models can make it seem. Rely on one metric to base your decisions, and you will quickly learn that something you thought was unrelated ends up being a confounding variable.
In 2019, a bombshell study found that a clinical algorithm many hospitals were using to decide which patients need care was showing racial bias — Black patients had to be deemed much sicker than white patients to be recommended for the same care. This happened because the algorithm had been trained on past data on health care spending, which reflects a history in which Black patients had less to spend on their health care compared to white patients, due to longstanding wealth and income disparities.
Or the evolutionary pressure from prioritizing that metric creates new incentives that skew behaviors in unexpected ways (the incentive for Verra to raise money led to it giving out Carbon Credits that were completely useless, which is completely against why they were created). If you’ve ever wondered, this is why Goodhart’s Law is so ubiquitous.

It is not just the scale of data that impedes super-intelligent AI. Or an inefficient modality. Or that we have the wrong architecture. It’s that data is a fickle mistress. By itself, it’s completely useless. It is only useful because we interpret it. There are often lots of cultural connotations and unsaid things about our data, that we become numb to just based on familiarity. Our tasks are a few orders of magnitude more complex than our data might imply. Utilizing more data (even high-quality data) without considering that will invariably lead to overestimation of the systems we build. We’ve already seen this with Language Models and their struggle with understanding Language.
For the rest of this piece, I want to cover the kinds of information/intelligence that Datasets often overlook.
Cultural Intelligence (I wasn’t able to find a technical term for this, but if you do know it please lmk)
When you think about it, there are all kinds of practices that different cultures follow, without an explicit scientific reason. Here, I’m not talking about superstitions, but practices that can be proven beneficial by our knowledge, but where the adherents might not have such justifications.
A great example of this is our diet. Civilizations across the world were able to come up with diets that hit both macro and micronutrient needs, w/o necessarily understanding nutrition to the degree we understand it today. “Daal, Chawal, and Subji”, “Meat and Potatoes”, “Rice, Fish, and Miso Soup”, the existence of unique fermented foods in different cultures, and other such parallels are all examples of cultures arriving at complete diets w/o modern nutrition science. Take a second to appreciate how insane that is.
The coolest example of this can be seen below. Tribes in the Amazon have been able to avoid cyanide ingestion for thousands of years, by following complicated routines w/o necessarily understanding how their process removed the cyanide.
In the Americas where cassava was first domesticated, locals consumed it for thousands of years without suffering from the effects of cyanide ingestion. Some Amazonian tribes rely on a complex transformation process to eliminate the cyanide from the cassava. This process consists of many steps including grating the root, pressing moisture off the grated pulp, washing it and drying it before finally boiling it. Interestingly, women from those tribes who dedicate a significant amount of their time to this activity don’t even know what these techniques are supposed to achieve
-Tribal Knowledge & Change: Lessons Learnt from Cassava Travel to Africa
Relying solely on traditional data from such tribes would do injustice to this evolutionary kind of intelligence. Would you document just the process, and ignore the reasoning? How would you know what practice and reason to follow and which ones to ignore? It’s impossible to track data without a framework on what we consider important.
With that, it’s not hard to imagine samples being dropped, and examples being ignored because they weren’t “justified” or b/c for the sake of cleaning data to match our predefined templates for data analysis (I can’t tell you how many teams rush to drop outliers/incomplete samples just to get better accuracy). Sometimes this is necessary. Other times, it’s a sign of incompetence and laziness. In all cases, it’s an imposition of a value judgment- a conscious decision to prioritize certain elements of a phenomenon and to disregard others.
Ignoring cultural intelligence can lead to billions of dollars spent, only to come back to the place we started. A lot of tech companies have recently realized this. Uber, Spotify, and Crypto were introduced as disruptors that would innovate upon their old entrenched industries, bypassing regulations and providing access directly to the people. All of these have ended up becoming precisely the monster they set out to slay.
Cultural Norms are formed over decades. They can become so engrained into our psyche that we become invisible to them. This is a big reason why Alignment Efforts have struggled so much- we implicitly assume that our samples are teaching the bots something, but in reality, they only contain that information partially. The rest is our collective information filling in the details, w/o us realizing it.
AI, which lacks this component, fails at doing so, leading to lots of unintended misalignment. This has shown up many times with LLMs. For a non-LLM related example, take a look at Self Driving Cars and their struggle with navigating merges-
They’re not wrong: Self-driving cars do find merges challenging. In fact, it’s a problem that points to one of the harshest realities facing everyone teaching computers to drive themselves: For the foreseeable future, they’ll be sharing the road with human drivers. Humans who tend to favor flexible, communication-based interaction over following rules by the letter. Humans who can be capricious and inattentive. Humans who can be jerks, humans who can be generous.
“Merging is one of these beautiful problems where you have to understand what someone else is going to do,” says Ed Olson, the CEO and cofounder of the autonomous vehicle company May Mobility. “You’re going to get in the way of someone’s plan, because everyone wants to keep going straight and not let you in. You need to change their mind and change their behavior, and you do that by driving in towards where you want to merge and they finally acquiesce.”
Their data focuses on rules and protocols, not contextual and always changing communication cues. They are not trained to fill in these blanks, leading to inaction. Speaking about things being filled in, let’s talk about one of humanity's biggest collective delusions.
Delusional Intelligence
Once again, if you know the actual (or even a better name), please be my guest. Turns out I’m worse at naming things than I thought. Not Manchester United Transfer Policy bad, but getting dangerously close. Maybe Jon Jones eye pokes bad.
Delusional Intelligence is the kind of intelligence that we develop specifically through our hallucinations. And you hallucinate a lot more than you realize. Take a look at the following panel from my recent manga addiction- Blue Lock (if you can ignore the over-the-topness and weird striker fetishization, this series is a masterpiece).

Your mind probably processed that image in 3-D. This is a fictional story, with no actual characters for you to reference (and no color either). Even so, your mind has no problems constructing a 3D model of the world and placing these characters. You do this so naturally that it might seem trivial, but this is among the biggest challenges in Computer Vision.
Your mind is 3D. The world is 3D. We can take 2D projections of 3D objects, and then visualize them as 3D. That is why an architect can look at floor plans, compare them against a set of guidelines, and tell you whether the plans are compliant.
AI is trained on information that is 2D (even 3D images are just 2D projections of 3D objects). The world is 3D. That is a problem. Big problem.
I don’t talk much about this — I obtained one of the first FDA approvals in ML + radiology and it informs much of how I think about AI systems and their impact on the world. If you’re a pure technologist, you should read the following:
…Here’s a bunch of stuff you wouldn’t know about radiologists unless you built an AI company WITH them instead of opining about their job disappearing from an ivory tower.
(1) Radiologists are NOT performing 2d pattern recognition — they have a 3d world model of the brain and its physical dynamics in their head. The motion and behavior of their brain to various traumas informs their prediction of hemorrhage determination.
—This whole rant about why technologists often get predictions so wrong is worth reading every day.
Whenever we see a 2D image, we hallucinate to create a 3D model. This allows us to solve challenges with it. A lot of image processing falls apart in production precisely because it’s unable to do the same. This is worth thinking about with the rise of multi-modality. As more capabilities are integrated, it will be important to account for how mechanical sensory systems differ from ours and design the tests accordingly.
Combined with a loss of cultural intelligence in data samples, AI's inability to hallucinate the way we do is probably why training on AI-generated outputs eventually leads to a breakdown in performance. Every AI-generated sample suffers from a Chinese Whispers style of loss of information. Perform enough iterations, and lost information will show up as artifacts, deviations, or divergent behavior.
Check the experiment- Looping ChatGPT & DALL-E: 20 Rounds of Describing & Recreating the Mona Lisa! The end result in just 20 iterations is completely different from the starting input-

Our delusions do a lot more heavy lifting than you might be willing to give them credit for. They are so important that we have a name for this highly important skill- ‘reading between the lines’. To be successful in most complex endeavors, the ability to look through the data to grasp the hidden themes is considered a must.
Clean data often seeks to hammer out these delusions to standardize the systems. This leads to a lack of nuance and a loss of important context. Taken to the extreme, the drive to pursue standardization can skew narratives eliminating differing thoughts. Let’s cover that next.
Subjective Intelligence
Much of Data Analysis works at the population-based level: we try to study members of a population to extract what is common, try to analyze that, and build trends on that. This Kantian attempt at regularizing the observation of phenomena has been the bedrock of a lot of innovation, but it is important to acknowledge its limitations.
When I did health system analysis for a state government, one of the problems was the illiteracy of the citizens filling out our forms. They would often fill out information wrong, get intimidated by the sheets and leave fields blank, etc. Pretty much everything that can go wrong with a dataset went wrong with ours. Ignoring the data that didn’t match industry-defined standards would lead to the exclusion of information from the people who were most vulnerable and dependent on the services provided (the state had a population of 300 Million people, so any change could impact millions).
There is generally a large discrepancy between the people who design technologies and some of the vulnerable groups that are most impacted by the technologies. The UK government experienced this firsthand when its Universal Credit system failed to account for some of the differences b/w normal people and folks w/ irregular, low-paid work.
In 2013, the UK government’s roll out of its new Universal Credit system was designed to simplify access to benefits, cut administrative costs, and “improve financial work incentives” by combining six social security benefits into one monthly lump sum. However, in practice it has resulted in considerable harm to those depending on state benefits.
A flawed algorithm failed to account for the way people with irregular, low-paid jobs were collecting their earnings via multiple paychecks a month. This meant that in some cases, individuals were assumed to receive earning above the relevant monthly earnings threshold, which, in turn, drastically shrank the benefits they received.
By requiring people to request their benefits online, the system also caused hardship amongst those who did not have reliable internet access, who lacked the digital skills to fill out long web forms about their personal and financial circumstances, or who could not meet cumbersome online identity verification requirements. Add to this the fact that applicants had to wait five weeks for their first payment, and it is easy to see that every day “lost” on not being able to complete a complicated online application process adds to existing hardship.
-How Artificial Intelligence Impacts Marginalised Groups is an absolutely phenomenal read for examples of systems excluding certain groups.
Or take Financial Systems. Credit Software often utilizes demographic information to predict whether someone is credit-worthy. This software might flag someone as risky based on historical demographic trends, denying them access to credit (or giving them higher interest rates). This will only increase the risk of default (worst case restrict them from access to credit), further perpetuating this pattern.
Another example can be seen in employee productivity software. The metrics used to measure productivity can penalize poor, disabled, or neurodivergent folk- who might otherwise be doing a great job. In marking them as lower productivity, the organization will end up pushing them out/relegating them. Any analysis done on top of this data will only further ‘prove’ that these folk were not good workers, entrenching this further. If decisions are made based on this, then it will only further alienate people from these groups, without us realizing it.

This is why good design and engaging multiple stakeholders are key. Without them, you can end up unwittingly excluding divergent viewpoints/characters.
This ties into a larger point about technology and how it reinforces existing power structures, if not deployed properly. Yes. it can be used to provide equal access to opportunities. But often it’s people in privileged positions that are in the right place to fully take advantage of these opportunities, have more chances to succeed, and can get back on their feet easier if they do fail. But I’m not sure how interested y’all are in these more meta pieces, so I won’t go into it too deeply now. Let me know if you are interested in that.
I’ll end this with reading recommendations for those of you who are interested in more in-depth critiques of abstract systems and the limits of rationality. Firstly, I will never miss a chance to recommend my all-time favorite writer/philosopher- Soren Kierkegaard. His analysis of these topics is brilliant and he’s been at or near the top of my reading/recommendation list for about 7 years now (for very different reasons though). Another great work would be Nietzche’s, “Twilight of the Idols”, where he critiques the enlightenment era view of an objective reality. In many ways, these two were the spiritual inspirations for this piece.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I think what you are calling "delusional intelligence" is not that at all - it's more of a reflection that our brains learn in ways that we don't understand ourselves and can't model accurately because we don't "know how we know". Kathy Sierra calls this "perceptual knowledge" in her marvelous book "Badass: Making Users Awesome", and that's probably as good an explanation as any.
Glad you resurfaced this—I’ve had quite a few cases where founders have pitched “all we have to do is get this data” for complex problems and I’m like 🤨
It’s not to say it doesn’t make incremental progress, but the idea we’ll go from effectively capturing none of these types of implicit knowledge to “it works” is naive at best, and otherwise just a pretty big gap in their mental models on how things work
I suppose me making this comment reflects what I think for those I send/share this to, but oh well, lol