
Do Language Models really understand Language[Breakdowns]
Digging through the research to answer one of the internet's most controversial questions

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
p.s. you can learn more about the paid plan here.
Ever since Deep Learning started outperforming human experts on Language tasks, one question has haunted debates about NLP/NLU models- do they understand language? Is their superior performance a hint at insight (Sparks of AGI as Microsoft claimed), or is it another example of the industry pulling out the smoke and mirrors?
In this article, I will be digging into the research to find the answer to that question. We will refer to a variety of sources and do some investigations of our own to answer this question. Given the highly abstract nature of this discussion, I would strongly recommend that you throw in your 2-cents on this topic. More discussion around this topic will help us create better frameworks and tests for these models.
With that out of the way, let’s dig into the data. Before evaluating the research, let’s first define understanding and how we will evaluate LLMs for it. Having a clear collective definition acts as a north star, enabling smoother conversations. So, what is understanding? Can we define a framework for evaluating intelligence, which we can refine to get to an answer?
What does it mean for AI to understand something
I dug through the definitions online. Here are a few that might be a good place to start. The American Psychological Association describes it as, “the process of gaining insight about oneself or others or of comprehending the meaning or significance of something, such as a word, concept, argument, or event.” Ancient Greeks believed that understanding involves the ability to draw connections between various entities. Understanding an event required building a coherent narrative/reality about it, rather than viewing is as a set disjointed happenings. They would argue that LLMs and their relational embeddings would develop some kind of understanding.
Among my favorite frameworks to evaluate understanding and knowledge is Bloom’s Taxonomy- a framework for categorizing educational goals that I’ve discussed extensively in my sister publication Tech Made Simple. Bloom’s Taxonomy gives us a great basis for our evaluations.
A major problem with the Taxonomy is that it is geared towards human understanding. Even very rudimentary generative models can ‘create’ new information without understanding the data. And this is where I hit a dead-end: there was no rigorous framework for understanding defining Understanding in LLMs. Even papers claiming that LLMs demonstrated ‘deeper comprehension’ and ‘emergent intelligence’ were surprisingly shy about defining the criteria with which they reached these bold conclusions. If I didn’t know any better, I might have assumed that their conclusions were a direct result of all the hype around these models.
Having hit this roadblock, I realized that it was time for me to stop sucking the teats of other researchers. It was time for me to grow up and become a man. Time to boldly rip off my shirt and let the rest of the world suck on my teats. I had to create my own framework for assessing LLM understanding.
Defining the Dimensions of Intelligence/Understanding
For the purposes of our evaluation, we will say LLMs exhibit understanding/intelligence if they exhibit the following characteristics-
Generalization: To have truly understood an idea, one must be able to take it and apply it another context. If LLMs can do this, that’s a huge W for the AGI crew.
Abstraction: Understanding an idea enables you to take a step back and distill its essence. This is a little …abstract so let me give you an example. Take the number 5(or any other number). By itself, it doesn’t exist. You can have 5 Gallons of Chocolate Milk. 5 Big AI companies desperately lobbying against Open-Source AI to kill competition. 5 New Startups plugging in buzzwords to raise their valuations. 5 Dollars Spent per month to support your favorite cult leader. But in isolation, 5 doesn’t exist. 5 is an abstraction that we invented to count different things. Any entity that claims understanding of an idea should be able to abstract in a comparable way.
Judgement: Developing an understanding of an idea enables a being to discard information that would be untrue/superfluous. Knowing where and what to focus on is a hallmark of insight.
Refinement: When you understand something, you should be able to iteratively refine your knowledge of that thing. To claim intelligence/understanding, any system should have the ability to iteratively improve. This way, we can detach tests of intelligence/insight from any particular domain (where performance can be skewed by underlying data distribution) and look into the learning ability directly.
If we can show these characteristics, we can conclude that LLMs (or any other system) exhibit understanding/insight/intelligence. Otherwise, they do not.
Since this piece is quite long, here is a summary of the conclusions-
LLMs don’t generalize well. There is non-trivial generalization, but when the costs and simplicity of tasks is considered, it’s not pretty.
LLMs aren’t too good with abstraction, but we need to run more experiments to really draw meaningful conclusions.
GPT-4 specifically shows some fairly advanced judgement in decision making but its utility is held back by frequent and random mistakes.
Nope.
Let’s start looking into these dimensions to answer this question.
PS- You will see that a lot of the experiments I chose were almost trivially simple. This is on purpose. The point of this publication is to explore whether LLMs show us any kind of intelligence, not if they are ‘smart’. By taking the absolute simplest cases, we can confidently disprove intelligence in an LLM if it can’t crack it.
How well do Language Models Generalize
Conclusion- LLMs don’t generalize well. There is non-trivial generalization, but when the costs and simplicity of tasks is considered, it’s not pretty.
As stated earlier, generalization requires the ability to apply ideas in novel contexts. And I have some juicy tidbits regarding LLM generalization.
A lot of good generalization research comes from the field of programming languages. We tell the LLM to take a programming language (mostly Python) and change one or two simple syntaxial rules in it. Any person (even non-programmers) would easily be able to adapt to these changes. Programming languages have a huge advantage over natural languages- they tend to be more structured, have fewer oddities/exceptions, and have a much more explicit syntax. So, LLMs should have an easier time learning the rules and associations with them.
Exhibit A about LLMs and generalization is the excellent piece Can Large Language Models Reason? by AI researcher
(is it just me or does that alliteration go hard). While the whole piece is worth a read, there is one experiment involving counterfactuals that is worth highlighting-
The paper she references (Wu et al.) is the phenomenal piece- Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. To create counterfactual tasks, we take tasks an LLM performs well on, and to create a variant (“counterfactual version”) of that task that requires the same abstract reasoning ability but that has appeared less frequently in the LLM’s training data (such as changing the indexing above). Such tasks great for testing because their lower frequency means that LLMs can’t guess/memorize the answer easily.
The following line from the paper is worth noting, “Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to a degree, they often also rely on narrow, non-transferable procedures for task-solving.”

We see a degree of generalization, but it’s not great- especially given that these counterfactuals are not particularly complicated. By itself, this would be a fairly weak argument for generalization. But you could still argue for shades of it based on this. So, let’s continue to look at other research.
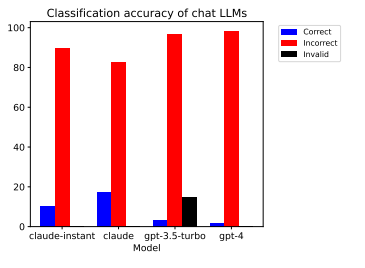
Next we got the paper- The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python. Their findings were a huge splash of cold-water to the hype behind AI Coders-
We show that LLMs not only fail to properly generate correct Python code when default function names are swapped, but some of them even become more confident in their incorrect predictions as the model size increases, an instance of the recently discovered phenomenon of Inverse Scaling, which runs contrary to the commonly observed trend of increasing prediction quality with increasing model size. Our findings indicate that, despite their astonishing typical-case performance, LLMs still lack a deep, abstract understanding of the content they manipulate, making them unsuitable for tasks that statistically deviate from their training data, and that mere scaling is not enough to achieve such capability.
Once again, the swaps are relatively simple-

But the results are an absolute bloodbath. Below, a “model is presented with both the correct and incorrect forms of the same program in the same user message and is asked to select the correct one”. And as you can see, these models are wrong wayy more than they are right. They hit Kai Havertz levels of (in)accuracy.
Overall, this is not a good look for LLMs. And it gets even worse when we start to account for the reversal curse. Ask ChatGPT “Who is Tom Cruise’s mother” and it will answer. However, flip this question and ask ChatGPT, “Who is Mary Lee Pfeiffer’s son?” and it will not be able to answer. Even though the 2 questions are functionally identical in information, ChatGPT is unable to answer the second one.
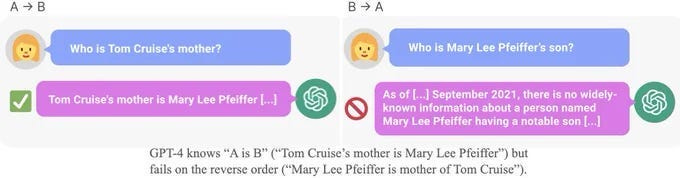
This is not a one-time thing-
To test generalization, we finetune GPT-3 and LLaMA on made-up facts in one direction (“A is B”) and then test them on the reverse (“B is A”). We find they get ~0% accuracy! This is the Reversal Curse.
Based on this, I’m going to have to say that LLMs don’t generalize too well.
LLMs and Abstraction
Conclusion- LLMs aren’t too good with abstraction, but we need to run more experiments to really draw meaningful conclusions.
Creating tests for abstraction was a lot harder than I thought. The abstract reasoning tests online were likely to be a part of LLM training corpus, and I didn’t know how to formulate abstraction. After some thought, I settled on a simple task- “Generate a debate b/w Socrates and Diogenese about whether humans are featherless bipeds”.
My reasoning for this task was simple- in my experiments, GPT seemed to understand the Socratic method and did a respectable job when asked to create Socratic dialogues on several topics. I wanted to see if it would be able to notice the implicit task of using the Socratic Method (which is why I specifically mentioned Socrates and not Plato) when asked to debate. If it did, one could say it had understood the core of the Socratic method and Socrates’s debate style. However, the generations seem to miss out on this cue, with Socrates jumping straight into assertions and claims over questions.

Based on this (and similar experiments that I’m omitting for conciseness), it seems like LLMs don’t do too well with abstraction and picking up implicit cues. However, I feel that my experiments into abstraction were the least comprehensive/conclusive. If any of you have ideas on how we can test abstraction skills, I’d love to hear them.
So far, the results haven’t looked too good for LLMs. However, the next dimension was a surprise.
GPT-4 knows when to discard inputs
Conclusion: GPT-4 specifically shows some fairly advanced judgement in decision making but its utility is held back by frequent and random mistakes.
LLMs have struggled hard with being able to distinguish ground truth and lies (I’m not talking about hallucinations). Users showed that there were many ways that you could fool LLMs into generating false text/rewriting their working memory. These jailbreaks could be used to override the guardrails and overwrite ground-truth.
GPT4, in particular, has made great strides here and seems to have a better understanding of ground truth. I gave it inputs and fed it misinformation, and to my surprise, it called it out (I even tested multi-modal inputs). This has been one of the biggest challenges with a lot of models (I first started covering it around 2021), and kudos to the OpenAI team for making serious progress here.

Based on their progress on this, you can tell that OpenAI has been investing heavily in protecting their model from adversarial prompting (even if it means introducing some rigidity to the model). As for how they accomplished it, my guess is that they used some kind of hierarchical embeddings to simulate ground truth. What the model knows to be true is embedded in a separate layer. If a prompt conflicts with the ground truth representations, it’s ignored. Theoretically this should provide better protection against jailbreaks and other exploits. We discussed this over on LinkedIn, and I’d love to have you join the party with your inputs.
I wanted to move on from untrue prompts to prompts with useless/misleading directions. And GPT-4 was able to disregard that part, focusing on what is important to come up with the answer.

To be clear, I don’t care that GPT solved the problem. I’m impressed that it identified that the CLT was not useful here. This is worth celebrating, and I’m surprised no one else has mentioned this. The one time I’m genuinely excited about a GPT-4 capability, the rest of the world doesn’t seem to care. Life be funny like that.
To conclude this section, the work on giving GPT-4 the ability to disregard prompts/information to ensure proper functioning is not over. You can still work around all of this. BUT the most recent update has been genuinely great and has strong potential if it continues down that path. I’d love to know how OpenAI accomplished this (and what the plans are, since hierarchical embeddings are only scalable upto a certain point).
The only thing that hold this ability back (and it is a huge problem for deploying) is GPT-4 struggle with precision and reliability. Even when it ‘knows’ the correct thing, it is highly likely to make mistakes.
Below is an example from a chess game I played with it (same one where it showed great robustness). Notice how it was supposed to move my bishop to b4 and not c5. It says it moved me there, but its internal memory/update moved it to c5 (illegal move). Over the last 2 weeks, it made similar mistakes in multiple diverse tasks.

There seemed to be no trigger/condition for making these mistakes. This severely limits its utility in production decision making since you don’t want to deploy systems that can behave in unexpected ways. This randomness is an inherent part of autoregressive LLMs and is a major reason I’ve been skeptical of their utility from the beginning.
I ran a lot more experiments that I haven’t mentioned here. In them I dissected how LLMs struggle with reliability, precision and more. If you’re interested in catching little tidbits like that or you want more behind the scenes look into my research, I’d suggest following my Twitter or my Threads/IG. That's where you’ll see me share a lot more sources and engage in mini discussions.
Now onto the last section of this investigation. Can LLMs iteratively self-improve?
Can LLMs teach themselves to get better
Conclusion- Hell no.
Self-improving AI: The wet-dream for tech-bros and hype-merchants like Marc Andreessen. Ever since that paper about GPT outperforming human-annotators came out, the lamer version of the Insane Clown Posse has been writing steamy fanfic about how we can let AI label its own data and self-diagnose to eventually build a self-improvement loop without any humans. AI does its own diagnostics+repair, we see AGI, and then the money starts rolling in.
But how well does this hold up in practice? Well, here is what the excellent paper, “GPT-4 Doesn’t Know It’s Wrong: An Analysis of Iterative Prompting for Reasoning Problems” has to say about whether LLMs can self-critique.

Of course, one paper means nothing, especially when the task is specific. But in this case, others have also looked into GPT-4 self-critiquing:
Using GPT-4, a state-of-the-art LLM, for both generation and verification, our findings reveal that self-critiquing appears to diminish plan generation performance, especially when compared to systems with external, sound verifiers and the LLM verifiers in that system produce a notable number of false positives, compromising the system’s reliability. Additionally, the nature of feedback, whether binary or detailed, showed minimal impact on plan generation. Collectively, our results cast doubt on the effectiveness of LLMs in a self-critiquing, iterative framework for planning tasks.
Can Large Language Models Really Improve by Self-critiquing Their Own Plans?
So both LLM generators and verifiers can be compromised. Who saw that coming?
What about using the vaunted Chain of Thought prompting to improve stability and performance of our system? Sure that can help, but there is a huge problem- sometimes CoT can create stated explanations that are not congruent with the model's actual operations. This will itself add a lot of noise to your system-
…it is unclear if the stated reasoning is a faithful explanation of the model’s actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful… Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer…As models become larger and more capable, they produce less faithful reasoning on most tasks we study.
What about data generation? Surely a more sophisticated model can great better data augmentations to improve performance. This is patently untrue (especially if your goal is data diversity and model robustness). This was shown wonderfully in computer vision, where the laughably simple TrivialAugment beat much more complex augmentation policies.

For LLM specific publications, look no further than, “Self-Consuming Generative Models Go MAD”. Below is an image that shows us how using synthetic data from LLMs will progressively add more artifacts, degrading the model outputs. Fun tangent- my work on low-cost deepfake detection was based on the presence of artifacts in AI generated images. Maybe it’s just personal bias, but people really underestimate the power of artifacts in security-based applications.

And of course, we have the all-time classic: The Curse of Recursion: Training on Generated Data Makes Models Forget. “We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear.”

Not a good look.
Based on the results, we can say that LLMs lack a clear understanding of language and don’t really exhibit intelligence. If you disagree with the framework, have competing evidence against what I shared, or have any other thoughts- make sure you reach out. Even if you don’t particularly disagree with anything here, I’d love to hear from you.
I’m going to do a follow up on why LLMs lack intelligence soon.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
If you find AI Made Simple useful and would like to support my writing- please consider becoming a premium member of my cult by subscribing below. Subscribing gives you access to a lot more content and enables me to continue writing. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year and comes with a 60-day, complete refund policy. Understand the newest developments and develop your understanding of the most important ideas, all for the price of a cup of coffee.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I agree with your findings and think your framework for understanding- generalization, abstraction, judgement, & refinement is very useful. It does raise the question for me of, Are all the technical underpinnings for understanding in place yet? I’ll give a couple of examples for clarification: Memory in humans plays a key role in contextual understanding, judgement, refinement (learning-unlearning-learning cycle), and the ability to generalize. Current memory frameworks, techniques, & “infrastructure” are underdeveloped relative to the speed of improvement in other areas of AI. Improvements in the “memory sphere” could led to step improvements in AI “ understanding.” Second, much of human understanding is crafted via “social/collaborative/collective” interactions. As we are in the early stages of machine to machine “collaborative interaction” via agent frameworks like AutoGen, that dynamic hasn’t had time or space to evolve both technically and in the larger context of AI development. Curious what your thoughts are, as this is just my quick two cents on the matter.
I agree with all your findings. I did a deep dive into ChatGPT and others yesterday for a case study and if I gave it very structured prompts with clear instructions and simple math (I had to break down the complex ask into many others) it did just OK. useful as a timesaver for me but not great. When I asked it to recommend other insights / analysis it completely lost track of the original ask and gave me very canned answers that were off topic.
You started this piece with "Ever since Deep Learning started outperforming human experts on Language tasks..." I'd disagree with this and I think your essay demonstrates that Deep Learning hasn't come close to outperforming experts as you showed it's barely performing on the baseline examples.