
Analyzing Google AI’s Chaotic Week [Markets]
Gemini’s amazing performance on long context lengths, Gemma, and the image generation nightmare

Hey, it’s Devansh 👋👋
In Markets, we analyze the business side of things, digging into the operations of various groups to contextualize developments. Expect analysis of business strategy, how developments impact the space, and predictions for the future.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
Executive Summary
This has been a very chaotic 2 weeks for Google. We have seen 3 major developments, with varying implications-
Google dropped Gemini and it’s shockingly good at text processing. Usually I am very skeptical about the benchmarks and claimed performances, but this time seems to be different. So far most of my information is second-hand, but what I hear and see seems very promising. I have applied for access and when I do get it, I will be sure to run all sorts of experiments on it.
In a throwback to their more punk-rock days, Google released the Gemma family of models. Gemma is performant, well-designed, and open (even for business). I’ve seen some discussion around Gemma, but particularly the decision to be monolingual, leverage synthetic data, and focus on text. I’m personally a huge fan of this design since it allows Gemma to become King of Hill in one task instead of being an interchangeable mediocrity in 5 tasks. Specifically when it comes to predictability and stability, this restriction becomes an advantage. If you’re looking for a summary on this Gemma, I would recommend the excellent Cameron Wolfe’s LinkedIn post on this topic.
Gemini should have been an emphatic statement on Google reestablishing its dominance in the Large Model Space. Instead, a large part of the headlines have been hijacked by the terrible image generation, text generations where Gemini says that you shouldn’t misgender someone- even when the misgendering is a way to prevent nuclear war, and other examples of terrible alignment. Certain sections of the internet have been quick to jump on this as a clear indication of Google’s woke, anti-white agenda that wants to turn us all into Trans-Barbies. Now before you book your gender-reassignment surgeries, I would urge you to consider an alternative thought. A lot of the lionization and false attribution of capabilities to LLMs came b/c we made a lot of assumptions about the training process. The whiplash we feel at failures at Gemini and other notable alignment efforts is caused in large part by an uncomfortable confrontation with reality: that despite claims to the contrary, we REALLY don’t understand a large chunk of LLMs (and Deep Learning in general). Every failure to get these models to behave in seemingly simple ways is a stark reminder of how little we know. To me, that is more important than any secret conspiracies going on at Google.
For the rest of this piece, we will explore these developments and their implications in more detail. We’ll start with Gemma, just to group the two Gemini sections together.
Google (Briefly) Becomes Cool Again
It’s no secret that people haven’t been huge fans of Google’s heel turn away from Open Source when it comes to LLMs. Seeing them turn back the clock and share a model open source (with a commercial license <3) was a welcome change of pace.
Given that it was released at the same time as Sora and Gemini, it can be easy to relegate Gemma to an afterthought. However, several features warrant attention. Let’s walk through them.
Some simpler architecture things first- “We normalize both the input and the output of each transformer sub-layer, a deviation from the standard practice of solely normalizing one or the other. We use RMSNorm (Zhang and Sennrich, 2019) as our normalization layer.” They replace the ReLU with GeGLU (introduced in GLU Variants Improve Transformer) and, “Rather than using absolute positional embeddings, we use rotary positional embeddings in each layer; we also share embeddings across our inputs and outputs to reduce model size”
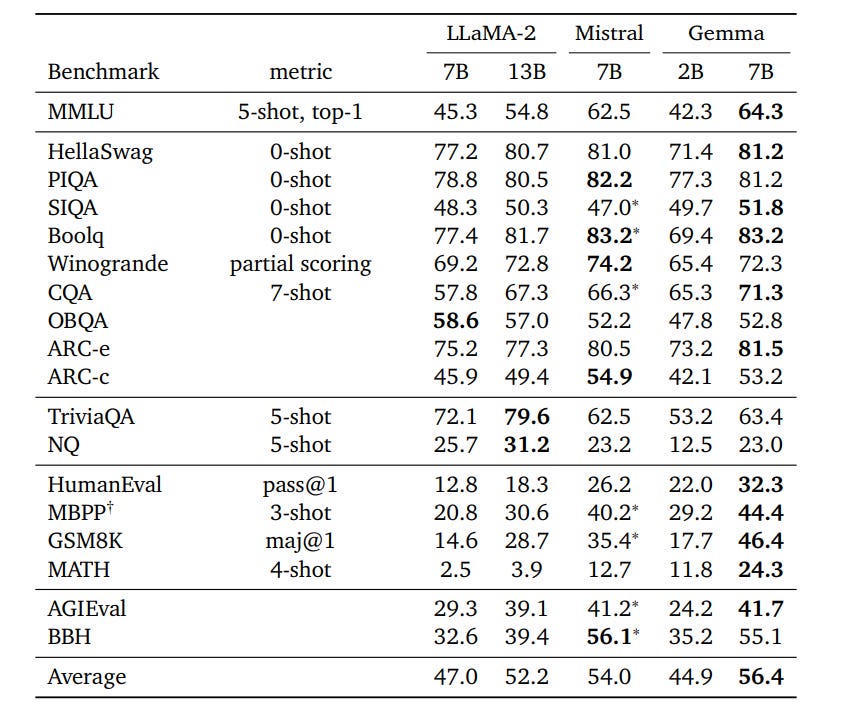
The first interesting decision is their Tokenizer- “We use a subset of the SentencePiece tokenizer (Kudo and Richardson, 2018) of Gemini for compatibility. It splits digits, does not remove extra whitespace, and relies on byte-level encodings for unknown tokens, following the techniques used for both (Chowdhery et al., 2022) and (Gemini Team, 2023). The vocabulary size is 256k tokens.” Most people have focused on the compatibility with Gemini, but there is another thing that potentially interests me.
One of my New Year's goals has been teaching myself Arabic. My mother tongue is Hindi. Both of these languages have more refined scripts than English (more letters, use of accents etc). The large vocabulary size and the tokenizer would carry over well for fine-tuning in other languages. It’s not super relevant given that Gemma is designed for only English, but I recently spoke to a leader for development RWKV and this was similar to one of the challenges that they expressed (being an inherently multi-lingual community, they had to build their own Tokenizer since traditional tokenizers didn’t do too well). So this was on my mind.
The more prominent thing is that the JJK-like Heavenly Restriction that Gemma puts on itself. It might seem strange for Google to buck the trend and go back to an English-only text model. This is causing some people to overlook this model as something inferior. I have a slightly different take on this. The fact that it’s English only and text makes it my first choice for a lot of tasks. Not only is this more comforting to my boomer tastes but it also just means more inner peace for me.
Multi-Modal and Multi-Lingual sounds great until you have to debug and restrict these models. More abilities also means more ways for things to go wrong. Most of my clients work in English exclusively. They need to do text processing. Why make my life harder by working with a system that brings these additional capabilities that don’t improve the core user product but they require more red teaming and testing? When it comes to English, Gemma holds its own, and that’s all I need to worry about.

Before my boomerness turns you off too much, let’s move on to something more exciting.
Gemini Drops a Gem on ‘em
Given all the buzz generated by Gemini upon initial release, the actual release went horribly wrong. Reports of a faked demo and misleading numbers turned what should have been a triumphant roll-out into a PR nightmare.
However, to Google’s credit, they didn’t let that stop them. I have been running mini-experiments on GPT, Perplexity, and Gemini/Bard and Gemini has been my favorite of the 3.
Perplexity has been almost completely useless: it does help me find some sources sometimes, but not much else beyond that.
GPT has been okay: Good in helping me fill in words/generate proposals, but not the best as the subject matter gets more difficult/niche. Their alignment is really good, and GPT is the best at following instructions (if I ask it to cover certain points, generate the answers in a particular structure etc- it gets it right). This compliance does unfortunately make it a little rigid at times, and it didn’t come up with as many talking points as Gemini. That being said, for the most bit it’s generation quality hasn’t been too far behind, and the more stable generation does save you some time and also is better for your peace of mind.
Gemini has been the best at brainstorming, quick proposals, and even in thinking about articulations for different ideas. The integration with YouTube has been very helpful. Over the past month, I’ve gone off the other two and have been using Gemini/Bard almost exclusively. For a brief while, Gemini’s tone made me want to punch it (it was too cheerful/brown-nosy), but it has been toned down to be more normal. I think the strength of Gemini was in ranking sources to lean on, and it seems like it rates some sources notably higher than others in its generations. It also has a weird tendency to sometimes say it can’t do certain tasks, or output very substandard output though. This higher variance is a problem, and I’d be more careful testing something built on Gemini compared to GPT.
Subjectively, I would rate Perplexity as a distant third and rate GPT and Gemini somewhat close to each other- with each specializing in different areas. For more context, check out my Twitter or my Threads accounts- where I share these experiments, my rationale, and my analysis of them in more detail.
Google has been busy BTS since they iterated on their strengths to create some truly staggering results. Across modalities, Gemini is hitting some fiendish numbers in Information Retrieval. Shouldn’t be shocking that the company that makes billions off search is good at IR, but Google hasn’t been doing itself any favors with its AI releases recently.
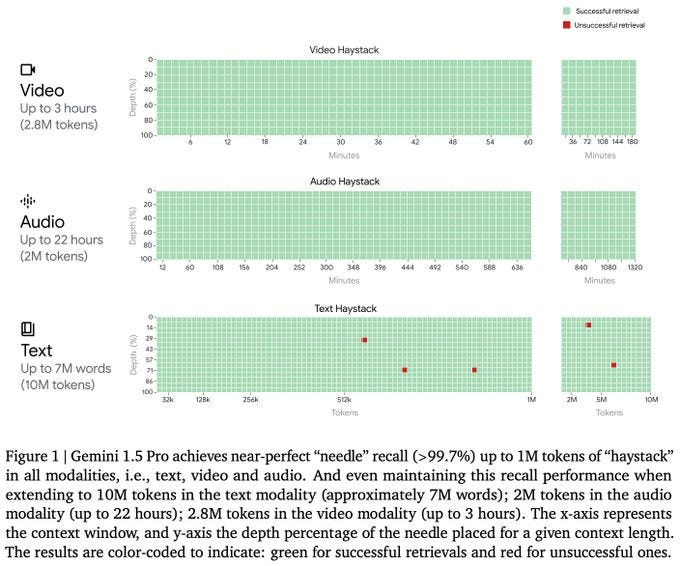
More than the numbers on their publication, I’ve been impressed by the second-hand information I’ve heard about experiments that others have run. It seems like across a variety of tasks in the wild, Gemini matches the expectations set by Google’s PR team. LLMs have really struggled with long Context Lengths and answering specific questions embedded in the text, so this is very very impressive.
A question that I get asked a lot is how they accomplished this. I’m going to present two theories, one of which is more out there than the other. My first guess is that they leverage an encoder-heavy model like BERT to build knowledge graphs of large documents by performing Entity Extraction in these documents. Searching through these large context lengths becomes a matter of traversing this graph, which can be accomplished relatively simply (assuming that the underlying graph is good). This approach can scale well, would work with multiple data-modality embeddings, and encodes relationality within the entities- leading to good performance in search. It also goes well with the MoE setup/sparsity that Google has been pushing.
Gemini 1.5 is built upon our leading research on Transformer and MoE architecture. While a traditional Transformer functions as one large neural network, MoE models are divided into smaller “expert” neural networks.
Depending on the type of input given, MoE models learn to selectively activate only the most relevant expert pathways in its neural network. This specialization massively enhances the model’s efficiency. Google has been an early adopter and pioneer of the MoE technique for deep learning through research such as Sparsely-Gated MoE, GShard-Transformer, Switch-Transformer, M4 and more.
The second theory is more fun. A while back, I came across the idea of Grokking in Deep Learning, where researchers showed that when it came to certain tasks, you could get really good generalization by training past overfitting. Given how overfitting tends to generally land you on the naughty list, this was a very interesting possibility to think about-
In some situations we show that neural networks learn through a process of “grokking” a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in generalization can happen well past the point of overfitting. We also study generalization as a function of dataset size and find that smaller datasets require increasing amounts of optimization for generalization. We argue that these datasets provide a fertile ground for studying a poorly understood aspect of deep learning: generalization of overparametrized neural networks beyond memorization of the finite training dataset.
-Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
If you’re wondering what this looks like, here is a visualization of one of the tasks-

Google has the computing resources to set on fire. What if they just gave up on anything smart and decided to Grok for Large Context Lengths? Technically, you can’t tune your way out of hallucinations. BUT, if you’re insane enough, you can theoretically fine-tune the input text enough to where it becomes very very heavily favored.
Is that my most intelligent speculation? Nope. But the thought of that happening does make me smile. And until Google tells us what they did, there’s a non-zero chance that they did this. That’s all I need to hope and run with this.
Normally this is where we would end, but this is Google AI we’re talking about. The organization has picked up a habit of snatching high-profile defeats from the jaws of victory in the most remarkable ways. It was bad enough that Sora stole a lot of Gemini’s thunder (which makes no sense given how impactful Gemini has the potential to be). But Google Leadership decided that wasn’t enough of a challenge. They decided to release Gemini with the worst alignment we have seen so far (it would have been better if they did nothing). Let’s end by discussing, what it tells us, and what it’s not.

Gemini’s Diversity Problem
As you probably know by now, Gemini’s image generation has some very interesting issues. If you asked it to generate pictures of Vikings, Nazi Soldiers, or other traditionally White groups- the images would not contain white people. Turns out that it was very hard to generate images of white people (to the point where it became a meme challenge to create prompts that reliably generated them).

Images are extremely powerful. By showing various groups in normal situations, we humanize them. Conversely, caricaturish descriptions have been used to demean and negatively stereotype various groups. So I fully sympathize with the desire to inject diversity into image generations. The only problem is that the way Google did this is hamfisted and unprincipled. This was not a principled effort to create better generations. It was a clumsy attempt to tick Diversity off a pre-release checklist. Their approach is insulting, both to their engineers and to us, the users.
Turns out that this extends beyond just race. Gemini can get very revisionist with history
When I asked it to generate images of China not ruled by communism, it refused, saying that China was historically tied to communism. It had no problem depicting the United States under communism.
When I asked if Taiwan is basically like China, but not under communism, it again turned to the old “complexity and nuance,” get-out-of-answering trick.
Gemini’s “concerning priorities” regarding trans people have Elon Musk very worried-

The sources mentioned above have accused Google of being left-leaning, anti-white, pro-trans, and all kinds of other things that you would expect from the internet. The only thing more insane than very well-compensated Google employees aligning Gemini the way they did is that there are adults who believe that Google’s Gemini is one of the steps to completely unraveling the fabric of Western values and turning everyone gay. This level of reach would make Tommy Hearns proud.
Google is not a secret powerhouse of the pink agenda. It’s a company, that will try whatever it can to maximize its valuation. This involves vigorously waving the pride flag in June only to give 400K to anti-LGBTQ politicians over one year.


The list goes on. Point being: Google is not a champion of the communist cause (nor would one expect it to be). It’s a company, concerned only with lining its pockets. To do so, it will play both sides. The Gemini misalignment is not an indication of a secret conspiracy. It’s an indication of something more banal- the people responsible for product and strategy at Google AI are not very good at their jobs. Before such high-profile releases, they should consider bringing in external firms to audit their processes and ensure that they’re not missing something major.
That’s not to say that there isn’t something to learn here. People are just looking for trends in the wrong place. There is a deeper pattern, one that not as many people are talking about. Gemini has been a very fragile model, beyond just politics. There are multiple anecdotes of people trying to use it for a task, only to be told that it can’t do that (I got that error a lot when I was trying to explore its YouTube analysis capabilities). An identical prompt in a new conversation would work fine, however. Turns out that Google struggled to make alignment work for Gemini. And this is worth thinking about.
Google’s failure at alignment is not unique. We have also covered ways to break ChatGPT. Across the board, alignment is extremely difficult. In large part because we don’t understand how models learn (or even what they end up learning). A lot of our assumptions about Deep Learning are based on conjecture. Even if we use similar terms like hallucinations and learning, the processes in how we go about updating our priors and models do the same is very different. Much of our alignment efforts are based on what we think is happening within the model. We’re generally pretty close to intuiting what’s up, but occasionally our thoughts don’t correlate with the BTS for models. And this leads to very high-profile failures like this.
There has been a constant mismatch b/w human expectations and reality when it comes to the abilities we have assigned to LLMs. For all the talk about LLM hallucination, it seems like we might have been guilty of hallucinating about sparks of emergent abilities in these models. As more and more attempts to tame the behavior of LLMs fail, we’re forced to confront two uncomfortable realities:
We understood these language models a lot less than we thought.
We might have dramatically overestimated these models (and our ability to create intelligent systems).

Last year, I caught some flak for making claims like we were dramatically overestimating LLMs and that LLMs didn’t understand language. On the first point, check out what François Chollet, AI Leader at Google and the creator of Keras had to say on March 1st, 2024-
My view of the capabilities of LLMs is probably far below that of the median tech industry person. And yet, the more time passes the more I realize my 2023 views were actually overestimating their future potential and current usefulness.
The authors of the research paper- Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap- showed that even the most recent models exhibit a large reasoning gap: “Functional benchmarks are a new way to do reasoning evals. Take a popular benchmark, e.g., MATH, and manually rewrite its reasoning into code, MATH(). Run the code to get a snapshot that asks for the same reasoning but not the same question. A reasoning gap exists if a model’s performance is different on snapshots. Big question: Are current SOTA models closer to gap 0 (proper reasoning) or gap 100 (lots of memorization)? What we find: Gaps in the range of 58% to 80% in a bunch of SOTA models. Motivates us to build Gap 0 models.”

I’d say the that debate is mostly settled now.
Getting back to the theme at hand: there’s no secret leftist agenda here. This whole thing is a mess. Nothing deeper than that. So let’s sit back, and appreciate this meme the only way that appropriate: making and sharing memes.

That said, I’ve also started preparing for the off chance that I’m wrong, and one of the most powerful organizations is hell-bent on replacing all men with drag-queens. I hear I can really rock a tiger-print skirt. What kind of an outfit would you pull off? Let me know in the replies.

Before you go, I have a quick request. Last year I released a book compiling some of the essays that I wrote in January for my newsletter Tech Made Simple. You can find it here on Amazon. The goal isn’t to make money from it (it’s priced at 1 USD and there is a completely free version available), but to collect reader feedback in one place, and to have public Amazon reviews to facilitate future ventures. Please consider buying and rating it, as it would help me a ton.

If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I agree that Google routinely manages to snatch defeat from the jaws of victory, and I agree that they likely have a strong internal culture problem that leads to outcomes like Gemini's alignment issue.
But I mostly disagree with the hot takes that Google's "not gonna make it" - the company makes tens of billions in revenue from ads, and in the worst case would probably have to play second-fiddle to other tech companies for a while (like Microsoft did in the early 2000s). Simple systems break quickly; complex systems (and organizations) degrade slowly.
In your comparison with ChatGPT, are you using the premium version of the free one? I think in these analyses it's important to be clear.
Way back I tried using Bard to write a blog post about changes to the laws on background checks for employment screening. I tried over and over to get it to write a professional, unbiased article. But it kept interjecting opinions that employers should ignore criminal records and show a willingness to give people a second chance. I don't necessarily disagree but that wasn't the topic...and in the end I decided it was, indeed, too woke to be of practical use.