
Detecting Deepfakes: Leveraging AI Artifacts for Scalable and Generalizable detection [Deepfakes]
How to Detect Deepfakes with Part 1: Is Generalizable Deepfake Detection Possible?

Hey, it’s Devansh 👋👋
This article is part of a mini-series on Deepfake Detection. We have 3 articles planned-
Proving that we can leverage artifacts in AI-generated content to classify them (here)
Proposing a complete system that can act as a foundation for this task. (here)
A discussion on Deepfakes, their risks, and how to address them (here)
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights (TL;DR of the article)
The increasing power of Generative AI + outdated media literacy skills has severely worsened the potential for misuse of deepfakes in identity theft and the use of misinformation. Aside from the raw cash damages, Deepfakes are also most harmful to the most digitally vulnerable sections of society, making their true risk much harder to quantify. For instance, malicious actors target teenagers with Deepfakes, leading to mental anguish, harassment, and even suicide-


And, of course, the risk to enterprises/other institutions from Deepfakes powered financial fraud is well-known-
Now one of the fastest-growing forms of adversarial AI, deepfake-related losses are expected to soar from $12.3 billion in 2023 to $40 billion by 2027, growing at an astounding 32% compound annual growth rate. Deloitte sees deep fakes proliferating in the years ahead, with banking and financial services being a primary target.
Deepfakes typify the cutting edge of adversarial AI attacks, achieving a 3,000% increase last year alone. It’s projected that deep fake incidents will go up by 50% to 60% in 2024, with 140,000–150,000 cases globally predicted this year…
Of the majority of CISOs, CIOs and IT leaders Ivanti interviewed, 60% are afraid their enterprises are not prepared to defend against AI-powered threats and attacks.
So, I figured it was time to do a dedicated piece on Deepfakes, fully updated with modern research. This article is part 1 of a 3-part series on Deepfake Detection. The goal of this series is to share our experiences from building ML systems at SVAM + our experiments on Deepfake Detection to teach you how to build Deepfake Detection Systems that are-
Low Cost: Many ‘cutting-edge’ Deepfake Detection setups are too costly to run at scale, severely limiting their utility in high-scale environments like Social Media, where AI-generated misinformation is most dangerous.
Generalizable: Other Deepfake Detection solutions are often limited by their scope since they are trained to maximize performance on certain benchmarks/datasets. This leads to overfitting and is not a good match for a problem like Deepfake Detection, where generation methods change rapidly. The first two reasons explain why, even though people have poured billions of dollars into detecting deep fakes, the deep fake problem has only worsened.
Performant: None of this matters if we can’t detect Deepfakes with reasonable accuracy. A good screen doesn’t have to be perfect, but it can act as an excellent first layer of defense.
In this article, I will provide proof of our core hypothesis: the latent spaces used to create Deepfakes imprint within the generation certain ‘artifacts’ that might be invisible to humans but can be detected with Machine Learning. Since these artifacts come from Latent Spaces, they will be present in multiple generation methods. Thus, their patterns should be transferable to novel Deepfake methods, and we should get good performance by indexing strongly on the feature extraction process. Lastly, indexing heavily on feature extraction should allow us to save a lot of resources by not having to rely on more expensive models for inference-

To do so, I will rely both on well-established research and SVAM’s own experiments with Deepfake Detection. Even though we have had minimal resources, both computationally and time-wise, our results have been exceptional. Here are some notable results of our current round of experiments-
Our goal is to classify an input image into one of three categories real, deep-fake (we meld the face of person 1 on the photo of person 2 in a realistic way. This is the traditional technique for Deepfakes), and ai-generated (images that use AI to build from scratch, like ImageGen, DALLE etc). This problem can get pretty nuanced when we consider the presence of photo-shop, filters, and AI-generated backgrounds in Zoom/Meets/Teams Meetings (our primary use-case was to help organizations catch Deepfakes, given the rise of multi-million dollar enterprise frauds)-

We do so reasonably well both in numerical performance (more numbers shared below) and in cost (our model runs extremely quickly, even on basic hardware- which fits with our goal of making this accessible to everyone, no exceptions).
We buck the convention of using 80% of data for training and 20% for testing. Instead, we go with more Testing samples (2706) than Training data samples(2397)- to simulate a world where the methods of shifting generating deepfakes are constantly shifting. Despite this, we see very promising results, with our top models getting reasonably high scores and encouraging learning behavior- with our best models hitting the 80s and showing clear performance improvements as we add data.

To super-duper-test our generalization, we excluded the DeepfakeTIMIT dataset entirely from our training set. Those intimate with this dataset would know that this has lots of realistic, face-swapped images in it, making it perfect for our ‘detect possible fraud/identity theft for companies usecase’-

Despite not seeing any samples from this dataset, our models scored very good results—with the top 3 models hitting 0.93 (SVC), 0.82 (RandomForest), and 0.8 (XGBoost), respectively. We have also tested this on other novel samples, and our generalization holds up very well, even on recently generated deepfakes. This generalization to novel methods/datasets with no additional training is our strongest feature and is uncommon in the space.
As we can see from the visualizations below- our feature extractions (while relatively simple) can separate our samples into fairly separable classes (this means that classification is easier)-
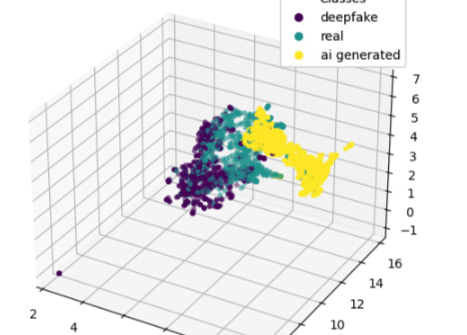
Our work has led to extremely promising results. However, at this stage- they are still just that. Except for our primary use case (even this isn’t always perfect), we aren’t anywhere close to conclusive results. Therefore, treat the idea/philosophy as the first step of a possibly exciting journey instead of a hard end goal. As such, there is a long way to go, and I would love your help. Here are a few ways you can get involved-
Work with us to refine it—If your organization deals with the Deepfakes, reach out to devansh@svam.com (you can also reach out on my social media here), and we can customize the baseline solution to meet your specific needs. Think about how happy that would make your investors and bosses.
Donate resources- We will publish a free, public app + website to help everyone protect themselves from Deepfakes. Naturally, this will require a lot of resources. If you have spare resources to donate- time, data, money, or computing- please reach out, and we can collaborate.
Share this- Every share puts me in front of a new audience. As someone who has no understanding of social media growth hacks, I rely entirely on word-of-mouth endorsements to grow our little cult and continue to pay for my chocolate milk.
As stated earlier, you could also use this series to build competing Deepfake solutions. If you choose to do so, all I ask is that you share insights from your building journey. Deepfakes go beyond any group, and we should all collaborate in whatever way possible to fix it.
With this covered, let us close our eyes, take a deep breath, and invoke the name of our Lord and Savior- Dani Olmo- to prepare ourselves to dive into the fun world of DeepFakes.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
The Background- How Deepfakes Are Created + Is there a Difference Between Deepfakes and Real Images
To dive deep into the solutions, let’s first quickly understand how Deepfakes are created. We’re about to speedrun some of the most important concepts in modern Deep Learning, so make sure you study things beyond this article-
Creating deepfakes typically involves using an encoder-decoder architecture where the encoder compresses facial images into a lower-dimensional latent space, capturing essential features and decoders take the smaller latent representations and try to rebuild the original face with minimal error.

For Deepfakes, we first train Two autoencoders simultaneously: one for the source face and one for the target face. The images share the encoder but have separate decoders. The model learns to reconstruct faces by minimizing reconstruction loss. Using the same encoder ensures that our feature extraction pulls common features across different faces. Typically, this involves learning features involving expressions or, more specifically, the angles/orientations/distances between your facial features. Meanwhile, keeping the decoder separate ensures that each decoder ‘overfits’ to its assigned face, learning all the specific details (such as modeling my weirdly beak-like nose and other facets of my uniquely good looks).
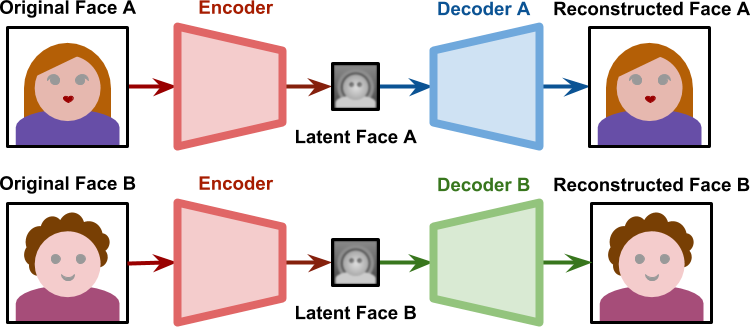
Let’s take a second to really appreciate that. The encoded representation maps commonalities (physical expressions), while the person-specific decoder remembers all the details. This is a very very elegant idea, and I think it’s always important to take a step back and appreciate such innovations for their ‘beauty’. Engaging with such ideas mechanically will only make your learning more boring.
To generate a deep fake, the source face is encoded into the latent space and then decoded using the target face’s decoder, effectively swapping faces-

If you’re feeling extra nerdy, you can apply post-processing techniques, such as blending and synchronization, to seamlessly integrate the generated face into video frames. Advanced methods like Generative Adversarial Networks (GANs) and style transfers can further improve the quality and believability of the deep fake (more of this in Part 2).
With that understood, let’s take a second to state our core thesis again- we believe this process, irrespective of specific model/training details, creates artifacts or fingerprints that ML models can detect. For this idea to be viable, we would need the following things to be true-
There is a meaningful difference between generated and real images, even if it is not immediately obvious to the human eye. Furthermore, these differences can be extracted and visualized/recorded through algorithms.
Using these differences will be competitive with state-of-the-art methods for detecting DeepFakes.
This extraction approach is generalizable to different problems/variants. We can find evidence of artifacts in low-/high-quality images, videos, and other variations.
Let’s spend the rest of our article verifying whether this is true. First, we will look into the research to see what it had to say.
Does Fully AI Generated Content leave Fingerprints
This is the first part we will examine. We can utilize DeepFakes technology to create realistic photos of people who have never existed. This has multiple safety implications when it comes to entrapment (scammers creating fake profiles to exploit lonely and vulnerable people). Entrapment works very well with AI because scammers can use AI’s ability to make pretty images, use synthetic voices, and ‘hold basic conversations’- which might be enough to hook unsuspecting victims.
For our purposes, let’s focus on the photos that one of these scammers might create. Take a look at the photos of a few AI-generated models below. Pinky is especially realistic, and I would it’s a real person if I saw the picture in the wild:

As an interesting aside, openly AI models/girlfriends are becoming very popular on Instagram and other sites(I’m too old to appreciate this, but I have no problem with them since they’re not misleading anyone), “AI models are starting to gain a lot of popularity online. Aitana Lopez is a fitness model with over 300,000 Instagram followers, whereas Emilly Pelegrini is dubbed the sexiest model in the world. Then there’s Lexi Love, who earns over $30,000 a month by becoming a lonely person’s companion and playing the role of the “perfect girlfriend.”
Lily Rain is another virtual influencer famous for her photos from her world trips. Despite Rain’s artificial intelligence creation, her followers find her images from around the globe captivating, and they don’t seem to mind that she isn’t real. According to Rain’s inventor, she bridges a gap in the travel influencer market by creating stunning images without really traveling, which saves time and money. Plus, she can change up her photos with different seasons and trendy trips, just like a celebrity.”
I did not have people living vicariously through an AI Model on my bingo card. Question for all you psychologists- why are people who are drawn to follow these AI Influencers? Are the people who get excited when the AI Model travels activating similar circuitry to us when we read we are moved by fictional stories? If not, what are the differences?
Getting back to the topic, can we detect fake profiles that might be engaging in entrapment? Turns out that there is a possibility:
Some authors propose to analyse the internal GAN pipeline in order to detect different artifacts between real and fake images. In [55], the authors hypothesised that the colour is markedly different between real camera images and fake synthesis images. They proposed a detection system based on colour features and a linear Support Vector Machine (SVM) for the final classification, achieving a final 70.0% AUC for the best performance when evaluating with the NIST MFC2018 dataset [62]”
- DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
Notice that the performance was achieved using SVMs and color features. These are just the basics. Adding more on top of this will be easy and will lead to amazing results. However, things don’t end here. Turns out it might be possible to differentiate between the different GANs (and even different instances of the same architecture), using these fingerprints.
Unfortunately, realistic GAN-generated images pose serious threats to security, to begin with a possible flood of fake multimedia, and multimedia forensic countermeasures are in urgent need. In this work, we show that each GAN leaves its specific fingerprint in the images it generates, just like real-world cameras mark acquired images with traces of their photo-response non-uniformity pattern. Source identification experiments with several popular GANs show such fingerprints to represent a precious asset for forensic analyses.
- Do GANs leave artificial fingerprints? (yes we’re talking specifically on GANs, but our experiments show generalization beyond GANs)
Not only is this very promising for deep fakes, but comparing and contrasting different fingerprints might also lead to some interesting transparency research in Deep Learning.
On Swapped ID (traditional Deepfakes)
This is, in many ways, the star of the show, given the identity theft already occurring with such technology. Fortunately, DeepFakes do leave a couple of artifacts that can be caught.

This is a huge win for our system. We’ll spend a lot more time on the feature extractions in P2, which will be much more engineering-focused, but for now, it’s important to appreciate that multiple research publications prove our idea.

There is also Intel’s work in detecting blood-flow to catch AI generations, and many other techniques that we could touch upon that all back this up. But that would just beat a dead horse at this point. So now, let’s move on to seeing if we can convert this theoretically sound idea into a somewhat functional solution.
SVAM’s Experiments with Detecting Deepfakes
So far, our experiments with Deepfake detection have been divided into three stages, each trying to fulfill specific requirements.
Stage 0: Prelim Testing
This was our early — prelims, where the focus was building something very barebones to match the enterprise fraud detection use-case. We worried mostly about nailing this for a demo. If you follow me on LinkedIn or are in the group chat, this was the stage where I sent out a link asking for user feedback. Here, the total dataset was <200 (both training and testing) and the goal was simply to show that we could use pre-existing methods to extract reasonably working features.
Based on both the demo and especially the user feedback, we learned a few things-
We were pretty good at the main task, which was nice, given how wimpy our system was.
Our generalization and robustness were both terrible.
We’d undersampled real images, so our model was very trigger-happy, calling anything slightly weird a deepfake.
We only had binary classification at this stage since the primary user had already told us that they didn’t really care about detecting purely AI generations.
The project didn’t give me the multi-millions + instant fame I expect every time I do anything, but it was good enough to move the project to the next level (now that I think about it, I did all that work to give myself more work, which is the opposite of what I want to do).
Stage 1: Early Iteration 1- Basic Scaling
At this stage, we significantly increased the number of samples in our dataset. This allowed us to tune our feature extractor a bit more till we were able to build representations that were very, very separable.
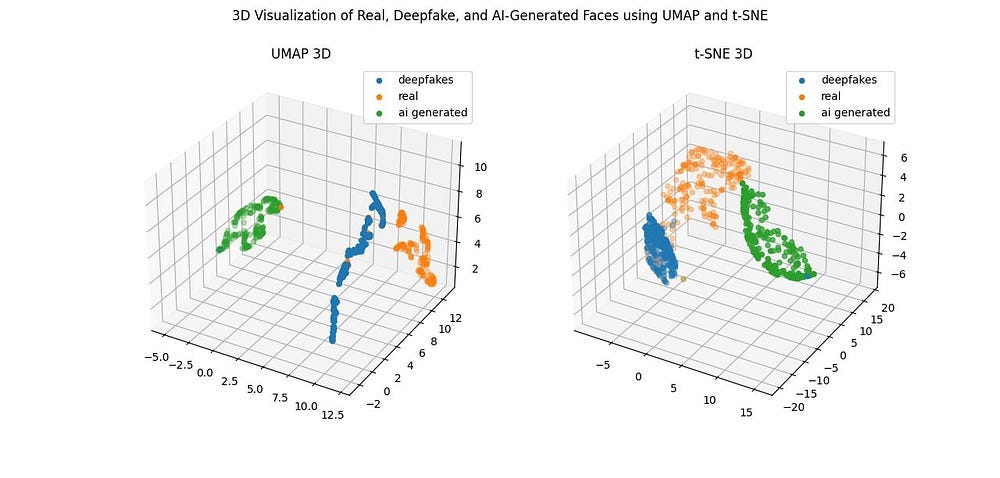
This is reflected in the very high performance of ML models (multiple models >0.98). Our main man, Random Forests, hit a perfect performance, which we weren’t too happy about-


Anytime I see such suspiciously high performance- I immediately get to breaking things to see address limitations, which was the goal of our current stage.
Stage 2- Basic Scaling + Generalization
This was our current stage, where our emphasis was on testing the generalization of our AI. This involved adding a lot of samples and deliberately using lots of held-out samples. The results for this were shared in this TL;DR. To summarize them here- our best models have reasonably high-performance, very low costs, and show strong generalization. They do exhibit a big difference between training and validation performance, which hints at overfitting. Solving this is important, but without downplaying the challenge- it is very doable.
We will discuss some methods to accomplish this in part 2, where we talk about the end to end ML Engineering in a lot more detail. Keep your eyes peeled for that. If any of you want to work about the progress we’ve made so far, you can email me- devansh@svam.com or message me through my social media below.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
This article was great, I definitely didn't understand all the technical details, but I understood enough about the dangers Deepfakes can pose to be really glad solutions are being worked on. I was also saddened to learn it's causing so much harm already and not just a future problem.
Did any psychologists reach out about why people like AI influencers? Because I can't understand that either