
Faster gaze prediction with dense networks and Fisher pruning [Breakdowns]
How to accomplish SOTA performance with a 10x speedup

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
p.s. you can learn more about the paid plan here.
GPT has been making waves for integrating multi-modality into its capabilities. Multi-modal AI is a huge boost for AI Models, and this development has brought a lot of attention to GPT and created a newfound interest in multi-modal Language Models (read more about them here).
While multi-modality is powerful, LLMs have been notoriously costly to deploy at scale. And this problem gets worse with multi-modality- which adds another dimension for your AI to traverse through. I already have a dedicated article on how you can reduce the computational costs of Deep Learning models (with a focus on Language) over here. Today we will do a vision-related follow up. Specifically, I will be breaking down an excellent paper- Faster gaze prediction with dense networks and Fisher pruning. Even though it is ‘old’ (2018), it has some very interesting results worth exploring. PS- Towards the end, we will go over a visualization that absolutely blew my mind.
Through a combination of knowledge distillation and Fisher pruning, we obtain much more runtime-efficient architectures for saliency prediction, achieving a 10x speedup for the same AUC performance as a state-of-the-art network on the CAT2000 dataset.
Before we get into the breakdown, a special shoutout to Logan Thorneloe for this excellent paper recommendation. Logan is an ML Engineer at Google and writes the excellent newsletter Society’s Backend, which covers topics like Privacy, AI, and Tech. Give his work a look if it interests you, and make sure you share any interesting papers/publications you come across.
Understanding the need for Pruning in Vision Saliency
Before getting into the paper, let’s go over Pruning and why it’s particularly important in Vision and gaze prediction. Gaze prediction is a field of Computer Vision research that focuses on trying to identify where a person would pay attention, given a particular image. This has applications in better design, image/video compression, and even AI Safety/Explainibility (helping you get a look inside the black-box deep learning models). The last case is often overlooked, but given how much information is communicated by visual mediums (images and videos), this is something to take note of.
However, as with every other problem in Machine Learning Engineering- scale is an issue. To hit higher performance, ML Researchers/Engineers often spend heaps of compute in creating bigger architectures/tuning the parameters to death. This works great if your goal is to ace a benchmark/have a cool publication to your name but does little if your goal is to develop a useful and scalable ML System. Pruning is a hack to get the best of both worlds. Done right, pruning will give you the higher performance of a larger ML Model, while giving you the flexibility and lower-inference costs of smaller models.
These problems were mentioned in the abstract of the paper- “Predicting human fixations from images has recently seen large improvements by leveraging deep representations which were pretrained for object recognition. However, as we show in this paper, these networks are highly overparameterized for the task of fixation prediction…Speeding up single-image gaze prediction is important for many real-world applications, but it is also a crucial step in the development of video saliency models, where the amount of data to be processed is substantially larger”.

Now that you know why Saliency predictions are important, and how pruning can help, let’s cover how these researchers were able to cut down their costs by a factor of 10 while keeping a functionally identical performance.

Solution 1: Using more efficient architectures
Before getting into pruning, it makes sense to try simpler/more efficient architectures and see if they are good enough.
The researchers hitch their wagons on to the Vision Model DeepGaze II. To those not familiar with the architecture, here is a quick summary- “The backbone of DeepGaze II is formed by VGG-19, a deep neural network pre-trained for object recognition. Feature maps are extracted from several of the top layers, upsampled, and concatenated. A readout network with 1 × 1 convolutions and ReLU nonlinearities takes in these feature maps and produces a single output channel, implementing a point-wise nonlinearity. This output is then blurred with a Gaussian filter, Gσ , followed by the addition of a center bias to take into account the tendencies of observers to fixate on pixels near the image center. This center bias is computed as the marginal log-probability of a fixation landing on a given pixel, log Q(x, y), and is dataset dependent. Finally, a softmax operation is applied to produce a normalized probability distribution over fixation locations, or saliency map:”

So how do they dress up this bad-boy to take him home to their parents? The researchers make the following modifications-
We first applied the readout network and then bilinearly upsampled the one-dimensional output of the readout network, instead of up-
sampling the high-dimensional feature maps- Upsampling this way lowers computational costs by reducing the size of the input that convolutions must go over (remember convolutions are an expensive process).We also used separable filters for the Gaussian blur. To make sure the size of the saliency map matches the size of the input image, we upsample and crop the output before applying the softmax operation.
To test the trade-off between computational efficiency and performance, the authors use 2 alternative models. First, replace the VGG-19, with the faster VGG-11 architecture. Here the lost performance of a smaller network is mostly compensated by fine-tuning the feature map representations instead of using fixed pre-trained representations. “Second, we try a DenseNet-121 as a feature extractor. DenseNets have been shown to be more efficient, both computationally and in terms of parameter efficiency, when compared to state-of-the-art networks in the object recognition”
However, this makeover isn’t good enough. To quote the paper-
Even when starting from these more parameter efficient pre-trained models, the resulting gaze prediction networks remain highly over-parametrized for the task at hand.
To combat this neediness, the authors must change models from within. And that is where pruning comes into play. They label their pruning technique Fisher Pruning.
Understanding Fisher Pruning
Pruning is based on the 80–20 principle- 20% of the features/parameters contribute to 80% of the performance. The goal of any pruning protocol is to keep these industrious members of society while getting rid of the freeloaders. So how does Fisher Pruning accomplish this? Alert- we are going to be getting Mathy here. If you’re not interested, either skip this section and go straight to the results or focus on the chunks I highlight in my screenshots.

This leads to the next part.

This is used as a pruning signal to greedily remove parameters one-by-one where this estimated increase in loss is smallest. Hkk comes from the following calculation-

I’m guessing that d(I,z) is the KL Divergence between Q and P, which approaches 0 when Q converges to P.
I usually don’t like to spend too much time on the math, simply because there isn’t much for me to say/add to what the papers have. However, it was important in this case since this is used in the next decisions. Should the breakdowns feature more math? I’d love to whether it enhanced or dropped your experience.
Next we get to pruning for convolutional architectures. “For convolutional architectures, it makes sense to try to prune entire feature maps instead of individual parameters, since typical implementations of convolutions may not be able to exploit sparse kernels for speedups.”

Since the gradient with respect to the activations is available during the
backward pass of computing the network’s gradient and the pruning signal can therefore be computed at little extra computational cost.
Ultimately, we don’t prune because we enjoy dropping feature sets/parameters. The objective with pruning is to slash the computational complexity of bloated networks. We want to reduce both the loss and the costs of the network, which we can group by. Keep in mind, I skipped a section giving more details, so if you want all the deets, read the paper-

This latches us with another problem- how do we figure out β? We could do a hyper-parameter sweep with multiple models+values of β. This is expensive. Instead, let’s discuss an approach which allows generating many models of different complexity in a single training run.
We know we want to prune a β when nuking it drops the complexity more than it boosts the loss. This billion-IQ insight is shown in equation 14-

Pruning happens iteratively- In each iteration of pruning only 1 feature map is targeted and β∗ is used as a weight. Note that we can equivalently use the βi directly as a hyperparameter-free pruning signal. This signal is intuitive, as it picks the feature map whose increase in loss is small relative to the decrease in computational cost. There is an alternative that is not explored.
In contrast, here we recognize that each setting of β creates a separate optimization problem with its own optimal architecture. In practice, we find that the speed and architecture of a network is heavily influenced by the choice of β even when pruning the same number of feature maps, suggesting that using different weights is important…the computational cost of a feature map changes when neighboring layers are pruned
The Results
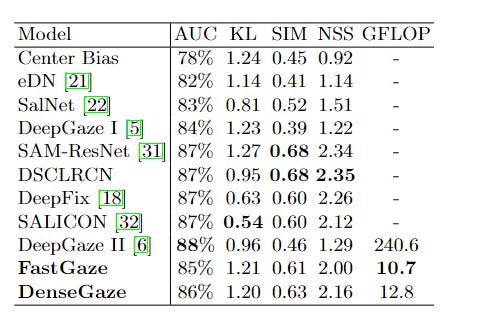
Now for the results you’re here for. How does this hold up? Before we proceed, I want you to note that the authors test 2 different kinds of architectures- one using the VGG-11 variant of Simonyan et al. for feature extraction and another replacing VGG with DenseNet-121 as a feature extractor. These networks are dubbed FastGaze and DeepGaze respectively. As a general trend, FastGaze is faster than DeepGaze but less accurate.
“Figure 2 shows the performance of various models. In terms of log-likelihood, NSS, and SIM, we find that both FastGaze and DenseGaze generalize better to CAT2000 than our reimplementation of DeepGaze II, despite the fact that both models were regularized to imitate DeepGaze II. In terms of AUC, DeepGaze II performs slightly better than FastGaze but is outperformed by DenseGaze. Pruning only seems to have a small effect on performance, as even heavily pruned models still perform well. For the same AUC, we achieve a speedup of roughly 10x with DenseGaze, while in terms of log-likelihood even our most heavily pruned model yielded better performance (which corresponds to a speedup of more than 75x). Comparing DenseGaze and FastGaze, we find that while DenseGaze achieves better AUC performance, FastGaze is able to achieve faster runtimes due to its less complex architecture.”

Comparing the results in tabular form, I’d say the results are close enough to where the efficiency of the pruned models would edge the additional performance of DeepGazeII.
However, the coolest part of this comes from the visualization of the extracted features. The researchers compared the saliency maps of the various networks on a set of images. It’s amazing how similar these generated maps are, even when the models are heavily pruned. “We find all models produce similar saliency maps. In particular, even the heavily pruned model (39x speedup compared to DeepGaze II) still responds to faces, people, other objects, and text.” I would have loved to see some mathematical similarity computations, especially because we’ve seen how differently can see images to humans.

That image prompted this breakdown. As multi-modality becomes mainstream, people will invariably run towards more complex architectures and use cases. Understanding the power of pruning is necessary to ensure that these models are scalable in the long run.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
If you find AI Made Simple useful and would like to support my writing- please consider becoming a premium member of my cult by subscribing below. Subscribing gives you access to a lot more content and enables me to continue writing. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year and comes with a 60-day, complete refund policy. Understand the newest developments and develop your understanding of the most important ideas, all for the price of a cup of coffee.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819