


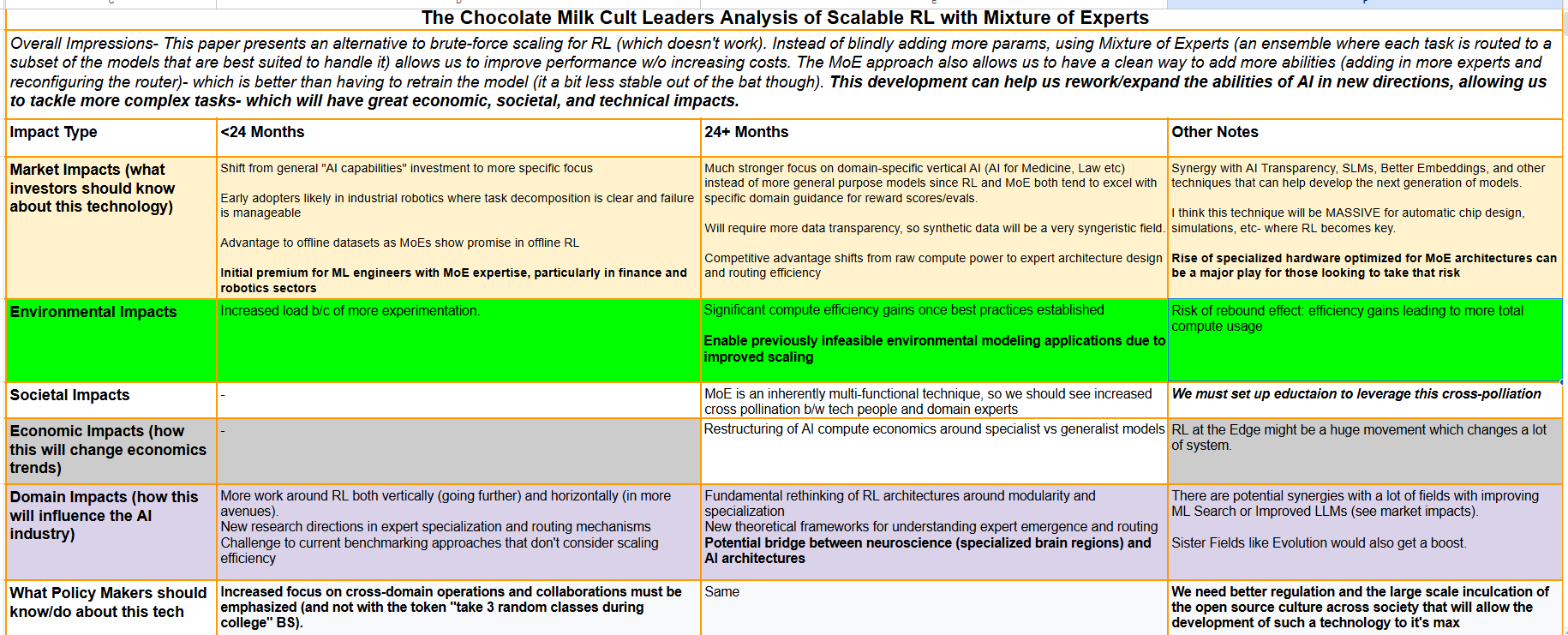
Google's Guide on How to Scale Reinforcement Learning with Mixture of Experts [Breakdowns][Agents]
Addressing one of the challenges associated with Scaling Reinforcement Learning

Hey, it’s Devansh 👋👋
A lot of us are very excited about the future of Agentic AI. Agents is a series dedicated to exploring the research around Agents to facilitate the discussions that will create the new generation of Language Models/AI Systems. If you have any insights on Agents, reach out, since we need all the high-quality information we can get.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
I think the paper “Mixtures of Experts Unlock Parameter Scaling for Deep RL” is interesting for several reasons-
It proposes a new way for scaling Reinforcement Learning. This is huge because we didn’t have a real way of scaling RL before (adding more parameters would sometimes drop performance).
The Scaling it offers is not “dumb”- it doesn’t rely on adding more parameters. Instead, it improves performance by using Mixture of Experts to improve the parameter efficiency of existing solutions (basically allowing you to hit more with less).
In my head canon, MoE and Agents are cousins. They have a very similar “Let specialized modules handle specialized tasks” vibe to them. I think exploring MoE-based research can have a large benefit in developing insights for building Agentic Solutions (and given how little we understand both, it’s a good idea to study them). They also have the most potential in the vertical AI space- since both Agents and MoE can be optimized with domain knowledge, allowing them to make splashes in high-value, low-penetration fields.
I think such a play can unlock billions of dollars in value over the next few years as we start figuring out the rules of engagement for these technologies (YC has estimated that Agents will be 10x bigger than SaaS). This is where research like this, which provides a reliable way to get buy in, can be helpful. My thoughts on the impact of this research are sketched out below-
I can’t really put words to why, but I think this one will be a very fun time (I do a lot of my thinking as I write, which is probably why I haven’t had the same success in writing with LLMs that a lot of other AI voices have). So grab a drink, and let’s dance through this research and its implications- one step at a time.
Executive Highlights (TL;DR of the article)
This research can be a bit complicated, so let’s break it down step by step. First, we will talk about the core of the research so that we can better contextualize the technical developments.
Part 1: A Simple Introduction top Scaling RL with Mixture-of-Experts
The Challenge of Scaling in RL: Unlike supervised learning (where we give our Machine Learning models clear inputs and their expected outputs and have them learn), simply adding parameters to RL models often degrades performance-
“Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance.”
This limits the complexity of tasks RL can handle. Naive scaling ignores the unique challenges of RL, such as unstable training dynamics and the curse of dimensionality.
The Soft MoE Solution: This paper explores a more principled scaling approach using Mixture-of-Expert (MoE) modules, specifically Soft MoEs (SMoEs). We will talk about the mechanics of this solution, but before now just note that this introduces structured sparsity and modularity (one of the many reasons I see similarity with Agents), enabling more efficient use of parameters.
Key Contributions and Impact: The paper demonstrates significant performance improvements with Soft MoEs across various RL settings. This is particularly notable since the other techniques don’t do too well with scaling (they see performance degradation as you increase the number of experts)-

The scaling performance generalizes across various tasks, helping it stay undefeated and undisputed like the GOAT Chael Sonnen.

With this covered, let’s peel back one more layer to understand the 3 main pillars of this solution (feel free to skip this section if you already know the foundations).
Part 2: Background: RL, Deep RL, and MoEs
Reinforcement Learning (RL):
RL involves an agent learning to make optimal decisions in an environment to maximize cumulative rewards. An RL agents look at it’s environment (the State), decide what action to take, evaluate the return it gets, and adjust it’s decision-making algorithm accordingly-

We see Reinforcement Learning to teach AI models to play games, develop investment strategies, develop other skills (generating better text for ChatGPT, making coffee, driving etc). In these cases, it can be extremely hard to teach an AI how to score possible intermediate steps between input and result, so we let AI handle it for us.

The AI handling things for us is what gave birth to Deep RL-
Deep Reinforcement Learning
Our story of DRL starts with Deep Q-Networks (DQN), who combine deep learning with reinforcement learning to predict action values. The network processes game visuals while a replay buffer stores experiences for repeated learning. I’m not an RL person, but from what I understand this was a big deal since this allows us to move into actions with extremely large state spaces (self-driving, generating text etc) where traditional techniques like recursively computing expected returns (or manually building the trees) becomes impossible-

Rainbow and Impala improve upon this in various ways, which we will cover in the main part of the article.
As mentioned earlier, unlike supervised learning, adding more parameters to these RL networks often hurts performance — a key challenge this paper addresses through Mixture of Experts.
Mixture-of-Experts (MoEs)- Both Hard and Soft
MoEs are networks composed of “expert” sub-networks and a “gating” network that dynamically routes inputs to the appropriate experts. This allows for conditional computation, making large networks more efficient-
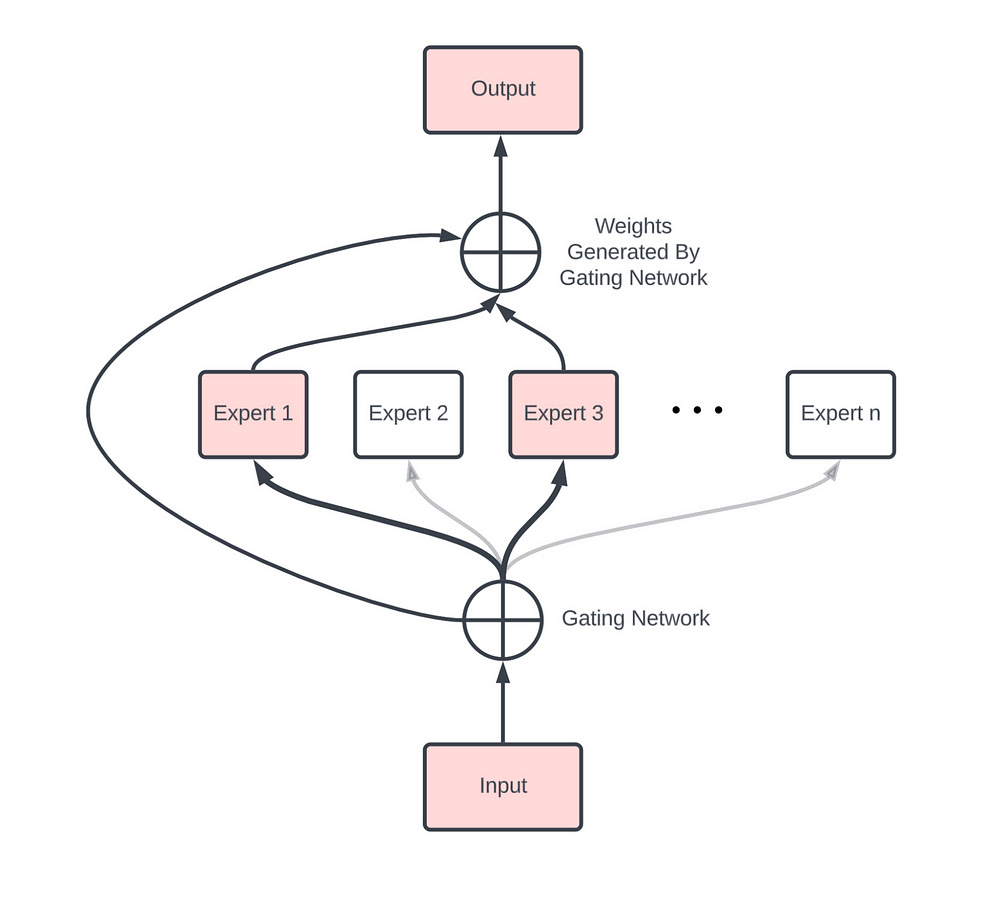
Their power and efficiency is why everyone expects cutting edge LLMs like GPT 4 and Gemini, and their future versions to heavily leverage this technology. Unfortunately, MoEs aren’t the best for stability (an idea we explored in our critiques of Gemini here), making them very volatile if not designed correctly.
Soft MoEs improve upon traditional MoEs by using a differentiable gating mechanism, which addresses training instability issues often encountered with hard routing. Let’s take a second to understand why-
Traditional MoE implementations use hard routing, where the gating mechanism makes binary decisions to send each input to exactly one expert (or more than one depending on your k, but it’s mostly 1). While intuitive, this approach can lead to training instability because of its sharp, all-or-nothing decisions. This is inefficient for various reasons (you can cause overfitting, tasks are often complex, sharp decision boundaries suck…), and is probably why Top 1-MoE struggles to (and even degrades) as more experts are added.
Soft MoE addresses these limitations by introducing differentiable gating — a smooth, gradual approach to routing. Instead of forcing each input to a single expert, Soft MoE allows inputs to partially activate multiple experts simultaneously. The system learns weights that determine how much each expert’s output should influence the final result. This softer approach leads to more stable training dynamics and better performance-

There’s a joke here with/ hard, soft, and the classic “that’s what she said,” but I am(pretend to be) an adult who is above such juvenile humor. But feel free to make the connections yourself. As they say, “Different Strokes for Different Folk”.
“While it is possible other losses may result in better performance, these findings suggest that RL agents benefit from having a weighted combination of the tokens, as opposed to hard routing.”
With these basics out of the way, we can now talk about implementing MoEs in RL-
Part 3: Design Choices for Implementing MoEs in Deep RL
MoE Placement: The MoE module replaces the penultimate layer of the RL network, allowing it to operate on high-level features extracted by the preceding layers.

MoE Flavors: Soft vs. Top1: A key design choice is the type of MoE used. We’ve already discussed the superiority of Soft MoEs to the more traditional Top1-MoEs, which use a hard assignment (one expert per token). No point in repeating ourselves needlessly.
Tokenization: Since MoEs work with “tokens,” the input to the MoE layer needs to be broken down. The paper primarily uses PerConv tokenization, which divides the convolutional feature maps into individual tokens. Alternative tokenization strategies (PerFeat, PerSamp) are also explored and compared.

Take a second to think about which tokenization + flavor would work best and why. Share your thoughts/rationale before continuing. It’s always interesting to see the various perspectives come up with.
The results can be seen below-

Immediately when I see this, I’m surprised by how the PerFeat and PerSamp performances are basically identical for both flavors (for their respective strats). My best guess is that PerFeat and PerSamp create tokens that already aggregate/process information (either across spatial dimensions or the entire input) which reduces the impact of the actual mechanism. Convolutions are a bit more complex w/ different hierarchies etc, which allows a divergence. It could also be something to do with the locality (Convolutions are local, while aggregating features/samples tend to be global) being the superior outcome, which we could likely test by running through features extracted from the Vision Transformers, which are more global than CNNs-
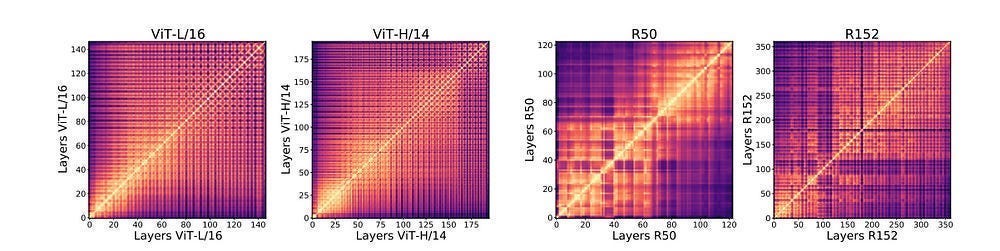
This is a very weak hypothesis, so I strongly encourage you guys to look into this in more detail (and please tell me what is going on). Given the major implications here, you don’t just want to take my word on things. The goal of this newsletter is to open source AI Research (there are a lot of projects on Github, but people often don’t understand the core ideas), and we only accomplish this through a two-way dialogue (including correcting me if I’m wrong).
We can conclude the tl;dr with a note about the future directions and how this slots into the broader landscape-
Part 4: Future Directions and Broader Implications
Promising Applications: Preliminary results show potential benefits of Soft MoEs in offline RL (learning from fixed datasets) and low-data regimes, suggesting broader applicability. Further exploration of different expert architectures + tokenizations is also warranted. I think the results communicated here should be enough to get buy in for future research (which is why I’m sharing this)-
we train the agents over 17 games and 5 seeds for 200 iterations, where 1 iteration corresponds to 62,500 gradient updates. We evaluated on datasets composed of 5%, 10%, 50% of the samples (drawn randomly) from the set of all environment interactions collected by a DQN agent trained for 200M steps (Agarwal et al., 2020). In Figure 11 we observe that combining Soft MoE with two modern offline RL algorithms (CQL (Kumar et al., 2020) and CQL+C51 (Kumar et al., 2022)) attains the best aggregate final performance. Top1-MoE provides performance improvements when used in conjunction with CQL+C51, but not with CQL. Similar improvements can be observed when using 10% of the samples
Practical Implications and Limitations: Soft MoEs offer a potential pathway to scaling RL agents to more complex tasks by enabling more efficient use of parameters and stabilizing training. However, there is a lot to be explored wrt to the additional complexity. I’m very very interested in the tokenization research (even more so than the scaling bit) and how that changes performances/what we can take away from that. But I think it’s something we have to learn more about and the production impact of this will be limited till we start knotting some of these kinks.
Also, this should go w/o saying, but don’t throw in MoE everywhere. You can probably do a lot of damage with simpler techniques like RPA, simple Agents, and pre-defined workflows to automate large parts of the manual job. Shoot me a message if you want some help understanding if you really need MoE or if something simpler might be a better investment.
At this stage, you should have a fairly thorough baseline understanding of the research and its implications. I could keep talking about the paper/results, but I think it would be more useful to start playing with the core ideas more. This way, we have the ability to build on not just this, but also related work. So let’s discuss some of the theoretical foundations such as Markovian Processes, how techniques like Rainbow improved on DQNs, why Soft MoEs work, and more.

I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
A bottom-up Understanding of RL
To understand Reinforcement Learning, I think it can be very helpful to understanding Markovian Processes-
What is a Markovian Process?
A Markovian Process is a type of stochastic (random) process where the future state of a system depends only on its current state, not on its entire history. The “memorylessness” of the process simplifies its modeling-
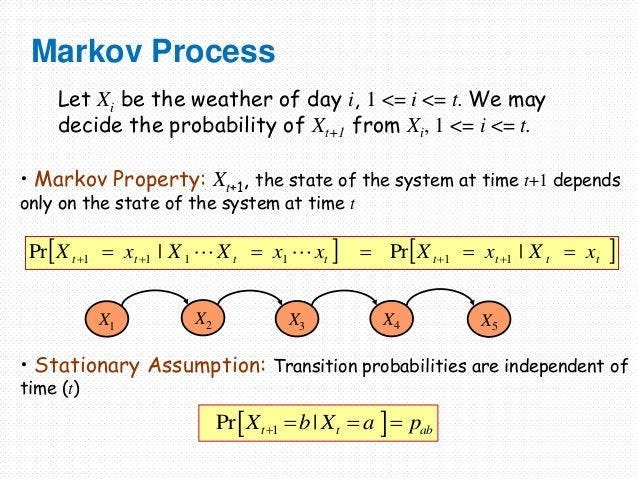
Imagine a Mario Game. As long as two different game instances have identical coins, powerups, health bars, locations, timers, and other stats- the journey you took to get to that point is irrelevant. Where you go/what you can do from that point on is also fixed, making those two points functionally identical- even if you took very different journeys to get there.
Markovian Processes are very cool b/c a lot of extremely complicated processes can be simplified into MPs.
From this foundation, we build Markov Decision Processes (MDPs) — the mathematical framework behind reinforcement learning. MDPs extend Markov Processes by adding 3 crucial elements:
Actions: An agent can make choices that influence state transitions
Rewards: Each state-action pair yields a reward signal
Discount Factor: Future rewards are worth less than immediate ones
In our Mario example:
States capture everything about the game situation: Mario’s position, enemies, powerups (the stats).
Actions include jumping, running, shooting fireballs
Rewards come from collecting coins, completing levels, staying alive
The game follows the Markov property: future possibilities depend only on the current state
With all this data, we could
This gives us all the tools required to jump into RL.

A look at RL
The goal of RL is to find an optimal policy — a strategy for choosing actions — that maximizes cumulative rewards over time.
This is where reinforcement learning faces a core challenge. Unlike supervised learning, where we have clear right and wrong answers, RL must learn through trial and error. The agent doesn’t know which actions are best — it has to discover them through exploration while also exploiting what it has learned. Making this harder, rewards are often delayed, making it difficult to know which actions were truly responsible for success.
RL is best when your challenge domains have continuous elements to them. This makes meaningfully labeling them for supervised learning a giant pain (it is possible, though). You can label every little step/jump Mario makes and build a full state tree, or you can let an AI agent take control of that psychotic little turtle-hating mushroom addict and just let the AI just fuck around and find out. One requires a lot of manpower. The other lets you run the code in the background while you go leg kick for leg kick with your bros and still get to fill in a timesheet. The choice is yours.
Unfortunately, figuring out how to assign scores to actions, especially over decisions that take a long time, is still a challenge. Not being able to do this well is often the cause of unexpected bugs like your bot deciding to stay on a level to keep farming coins, although such errors might also be caused by the objective function.
This is where Deep Learning is able to take RL to the next level by helping our bot create better approximations for expected returns-

Deep Reinforcement Learning
If you read the paper, it mentions two names that are worth paying attention to. In a nutshell, Rainbow improves upon DQN by combining several enhancements for better performance, while Impala focuses on scalability and robustness by using a powerful ResNet-based architecture and a distributed training framework. Let’s take a second to understand how they operate.
Rainbow: Combining Improvements for Enhanced Performance
Rainbow takes DQN and integrates several key improvements, creating a more powerful and efficient algorithm-

Think of it as a “best-of” collection of DQN enhancements:
Prioritized Experience Replay: DQN’s replay buffer stores past experiences, but treats them all equally. Prioritized experience replay improves upon this by prioritizing experiences that are more “surprising” or contain more learning potential. This focuses the learning process on the most important experiences, leading to faster and more efficient learning.
Double Q-learning: DQN can sometimes overestimate the value of actions. Double Q-learning addresses this by using two separate Q-networks to decouple the action selection and value estimation processes, reducing overestimation bias and improving stability.
Dueling Network Architecture: This architecture separates the Q-network into two streams: one that estimates the value of being in a particular state, and another that estimates the advantage of taking each action in that state. This separation allows the network to learn more effectively and improves generalization.
Noisy Networks: Instead of using ε-greedy exploration (randomly choosing actions with probability ε), noisy networks inject noise into the network’s weights. This allows for more efficient exploration of the state-action space and can lead to better performance (another W for noise based training).
Distributional RL: Instead of predicting a single value for each action, distributional RL predicts a distribution of possible returns. This provides more information about the uncertainty associated with each action and can lead to more robust and stable learning.
By combining these improvements, Rainbow achieves significantly better performance than vanilla DQN on the Atari benchmark.
Impala: Scaling DRL with a Robust Architecture
Impala focuses on scalability and robustness in DRL:
V-trace Off-Policy Actor-Critic Algorithm: Impala uses an off-policy actor-critic algorithm called V-trace. This allows it to learn from experiences generated by a different policy, which is crucial for scalability. It enables efficient use of data collected from multiple actors exploring the environment in parallel.
Scalable Distributed Training: Impala is designed for distributed training, where multiple actors and learners work together to accelerate the learning process. This allows Impala to scale to much larger and more complex environments than previous DRL algorithms.
They use these benefits to utilize a Impala-based ResNet Architecture: ResNets are known for their ability to train very deep networks effectively, addressing the vanishing gradient problem that can hinder training of deep networks. This allows Impala to learn more complex representations and achieve better performance.


Despite this and a lot of other interesting research, RL has had some notable issues when it comes to the mainstream adoption of ML solutions.
RL’s Challenges
Once hyped as the field that would lead to human experts everywhere being replaced, RL fell short of expectations. AI Legend Yann LeCun had this to say about the impact of RL-
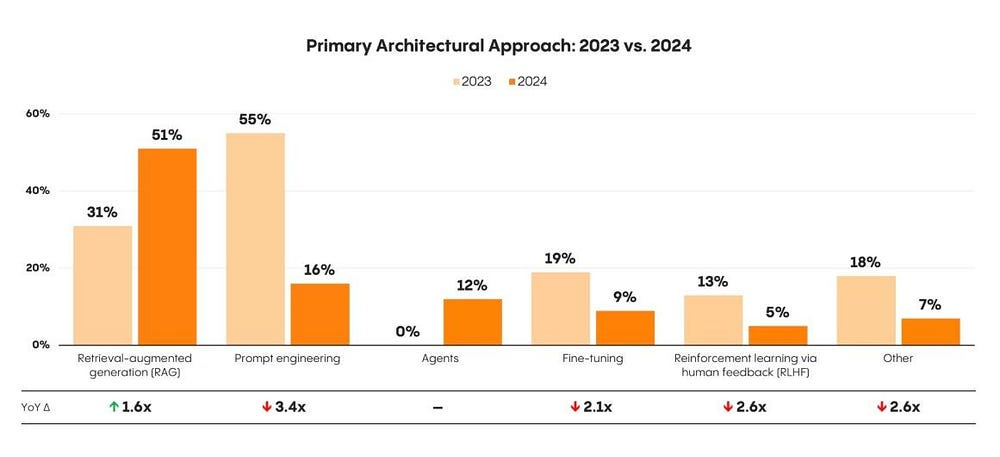
A lot of people were expecting a lot from RLHF + Finetuning from the creation of domain specialized workflows, but it’s seen a massive fall from grace as people are waking up to the realities of using RL or Finetuning to inject noise. This has lead to a massive fall from grace. To quote the ‘2024: The State of Generative AI in the Enterprise’ by Menlo Ventures- “Meanwhile, fine-tuning — often touted, especially among leading application providers — remains surprisingly rare, with only 9% of production models being fine-tuned.”
RL has the same problems as other Deep Learning- costs, black-boxness, unpredictability- but it also lacked a steady scaling capability. Scaling blindly was more inefficient than normal given the that the increasing size of the state space would cause overfitting, sensitivity, and generally unstable training dynamic. All of this gave me (and many others) the impression that RL could open some very interesting research directions, but it wasn’t the best for commercial use-cases (especially when you weren’t packing OpenAI levels of funding).

This research finally might just provide RL the answer it’s looking for. The scalability and stability might finally make it viable for more nooby people (like me) to start deploying it w/ confidence. If I can train RL-based tools on tool use and automation, I would even be willing to pay the premium to build very high-ticket solutions for my clients, which might eventually open up commercialization avenues for a whole other kind of Foundational Model (I’m not the biggest fan of using models like Claude for tool use since I think they’re meant for very different things). If this research is extended to automation, I think RL might finally start living up to it’s promise for large-scale automation.
Let’s end on a note covers why MoEs and particularly SMoEs have hit such fiendish performance in scaling-

Why Mixture of Experts Unlocks Scaling in Deep RL (Speculation)
Several factors could come into play here. The authors make some interesting observations but stop from drawing major conclusions-
“We observe significant differences between the baseline architecture and the architectures that include MoE modules. The MoE architectures both exhibit higher numerical ranks of the empirical NTK matrices than the baseline network, and have negligible dormant neurons and feature norms. These findings suggest that the MoE modules have a stabilizing effect on optimization dynamics, though we refrain from claiming a direct causal link between improvements in these metrics and agent performance. For example, while the rank of the ENTK is higher for the MoE agents, the bestperforming agent does not have the highest ENTK rank. The absence of pathological values of these statistics in the MoE networks does however, suggest that whatever the precise causal chain is, the MoE modules have a stabilizing effect on optimization.”
While we can’t draw hard conclusions, we can speculate a bit-
Mitigating the “Dormant Neuron” Problem: Dormant neurons, which become inactive during training, reduce a network’s learning capacity. This is a significant issue in reinforcement learning due to its inherent instability.
Soft MoEs, with their soft gating mechanism, counteract this problem. By assigning weights to multiple experts for each input, they encourage the activation of a diverse set of experts, even those that might otherwise become dormant. This distributed activation effectively increases the network’s capacity and promotes more robust learning.

I think there’s a general trend we’re noticing across ML about the importance of sampling diversity boosting performance for systems. We saw this with SWAT, where the algorithm uses Zombie neurons to create new sparse networks- allowing it to test more configurations and improve performance. We saw this with ensembles, that explicitly won b/c they were sampling from a more diverse search space. And meta-learners pick up better long-term fitness by optimizing for genetic diversity. We might be looking at something similar here- where the involvement of more neurons allows you to blend representations better- creating better performance-

Or maybe I’ve finally lost it and reading too much into this. Let me know what you think.
Higher Effective Rank of Features and Gradients: The rank of feature and gradient matrices reflects the diversity and independence of information flowing through the network. Higher rank signifies better information flow, which is crucial for learning complex relationships. MoE architectures allow different experts to process different aspects of the input. This should naturally create more varied processing paths, potentially leading to more diverse feature representations and different gradient paths during backpropagation. The result is a higher effective rank as different experts learn to specialize in different patterns.
This would align with the trend we see. Hard MoE has the highest rank since it assigns each input to a single expert, encouraging specialization. Each expert becomes highly specialized in processing a specific subset of the input space. This specialization can lead to more orthogonal features and gradients, meaning they are less correlated with each other. Orthogonality contributes to a higher rank because orthogonal vectors are linearly independent.
On the other hand, Softer MoEs would blend things more (same reason it would end up with lesser dormant neurons than Hard MoE), creating less separate features. And Rank seems to be the only value where the two MoEs converge least.
3. Less Feature Norm Growth: Both soft MoEs and hard (Top1) MoEs exhibit significantly less feature norm growth compared to the baseline models. Feature norm growth, the increasing magnitude of feature vectors during training, can lead to overfitting, hindering generalization to new, unseen data. The fact that both MoE variants demonstrate this characteristic suggests that the MoE structure itself, regardless of the gating mechanism (soft or hard), contributes to controlling feature magnitudes.
This inherent regularization effect likely comes from the distributed nature of the representation, where multiple experts contribute to the overall output, preventing any single expert from dominating and excessively amplifying feature norms. This controlled feature norm growth contributes to the improved generalization performance observed in the MoE models compared to the baseline, which exhibits more pronounced feature norm growth and potentially suffers from overfitting.
My hope with these speculations is to throw a few ideas out there to spark a discussion. I think this is very interesting work, but I’m also not intimate with RL Research (it’s felt a bit gimmicky to me, and as mentioned earlier- not as much business with the guys I work with). If I’ve gotten anything wrong, please don’t hesitate to call me an idiot.
Looking forward to your comments.
Thank you for reading and have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast (over here)
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
good stuff!
saved this