


Which Foundation Model is best for Agent Orchestration [Agents]
Gemini vs GPT 4o vs Claude Sonnet vs o1 vs 4o mini

Hey, it’s Devansh 👋👋
A lot of us are very excited about the future of Agentic AI. Agents is a series dedicated to exploring the research around Agents to facilitate the discussions that will create the new generation of Language Models/AI Systems. If you have any insights on Agents, reach out, since we need all the high-quality information we can get.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
As I’ve stated many times, especially over the last few posts on scaling and the future of AI- I believe that Agents will lead to the next major breakthrough in AI. While a lot of people are bullish about Agents as a frontier for scalable AGI/next-gen Foundation Models, I think they have the most potential for immediate impact in the application layer. I’ve been playing with them since the early days of GPT 3.5- and newer developments in AI have made them more viable than ever.
This article will summarize my experience with/ using the various LLMs for building orchestration layers for Agentic System (if you don’t understand what this means, we will explain it). I’m choosing to dedicate an entire article to the orchestration layer for 2 key reasons-
The “LLM as an orchestrator” is my favorite framework/ thinking pattern in building Agentic Systems. It aligns best with how I think about Software and has consequently been my go-to.
In my experience, a LOT of people think about it wrong.
If this sounds interesting, keep reading.
Executive Highlights (TL;DR of the article)
Since most of you are probably here mostly for the ranking, I’m going to give them upfront. We will talk about the theory and my observations with the models in more detail later (also I post about my experiments w/ different LLMs on my social (mostly Threads now), so check those out if you’re interested).
Here is my ranking of the LLMs on how much I liked them as orchestrators for Agentic Frameworks-
GPT 4o (clear favorite)- This is by far my favorite LLM for the orchestration layer. It performs well, doesn’t cost much (especially factoring the ROI), is stable (very very important), and does what I ask it to do w/o too much fuss (critical). OpenAI has done a fantastic job w/ alignment to ensure that it actually follows my instructions
Claude Sonnet (tied)- Claude is very good at decompositions (breaking down a user command into different steps that existing tools can tackle), but it lacks stability (even minimizing temp) AND has an annoying tendency not to follow my instructions. It also tends to argue back a lot, a pattern that is progressively getting worse. Haiku is okay with instructions, which was surprising, but it’s not the best orchestrator. Imo, Claude seems to excel at creativity, which is not a high priority for an orchestrator- which is why I tend not to use it.
GPT 40-mini (tied): Not as stable as 4o, and will sometimes mess up my formatting. Not very intelligent, but I rarely need my LLM Orchestrator to be intelligent. It’s not a terrible option, but I like the increased performance of the bigger model.
Gemini (4th)- I really want to like Gemini. It’s cheap, high context window, gives you more control over the API, the most multi-modal (Gemini handles videos fairly well). Google also publishes lots of cool research into LLMs (I could turn this into a Google AI newsletter full-time w/ the amount of stuff they have put out). But I guess I’m a fool for expecting them to integrate their research into their flagship AI Model. Unfortunately, Gemini has a weird tendency to claim it can’t do something that it can do, making very strange claims, and getting triggered very randomly (such as the time it called my face hateful). It’s a bit more compliant than Claude and has good formatting (very important for sending inputs to tools), but its unreliability is a huge knock. As it is, I don’t use Gemini for anything that requires intelligence, only for grunt work. I’ve been bullish on Gemini/Google AI for a while now, but they have found new ways to constantly let me down. At this point, I’ve given up on the model and will probably not be using it for anything substantial until I see major changes.
GPT o1 (by far the worst)- As an orchestrator, I have nothing positive to say about o1. It’s terrible at following instructions, adds 30 lines of commentary where it shouldn’t (messes up the inputs being sent to the tools), and is just generally awful. Working with o1 made me want to call my parents and apologize for every time I disobeyed them (this happened very rarely; I’ve always been an obedient, sanskaari ladka).

Will share my thoughts on the models later. For now, let’s loop back to the terms and ensure we’re on the same page.
Understanding Agentic AI
To fully understand things, let’s first clarify the terminology. Let’s first hone in on what makes a system Agentic.
The way I see it- Agentic AI Systems decompose a user query into a bunch of mini-steps, which are handled by different components. Instead of relying on a main LLM (or another AI) to answer a complex user query in one shot, Agentic Systems would break down the query into simpler sub-routines that tackle problems better.
Imagine you had a bunch of sales data, stored in different tables. You can upload all of them to GPT and ask questions- in the same way, you can try riding a wild tiger, say yes when your partner asks you if a dress makes them look ugly, or not read Vagabond b/c “Cartoons are for children.” Verifying whether GPT’s answers are correct will wipe out any time savings from building the system.
Agentic AI is a way to ensure your stuff works by making the AI take auditable steps that we can control and correct. This gives us better accuracy, fewer uncontrollable errors, and the ability to tack on more features. For example, we can use the following setup to answer Sales Related Questions-
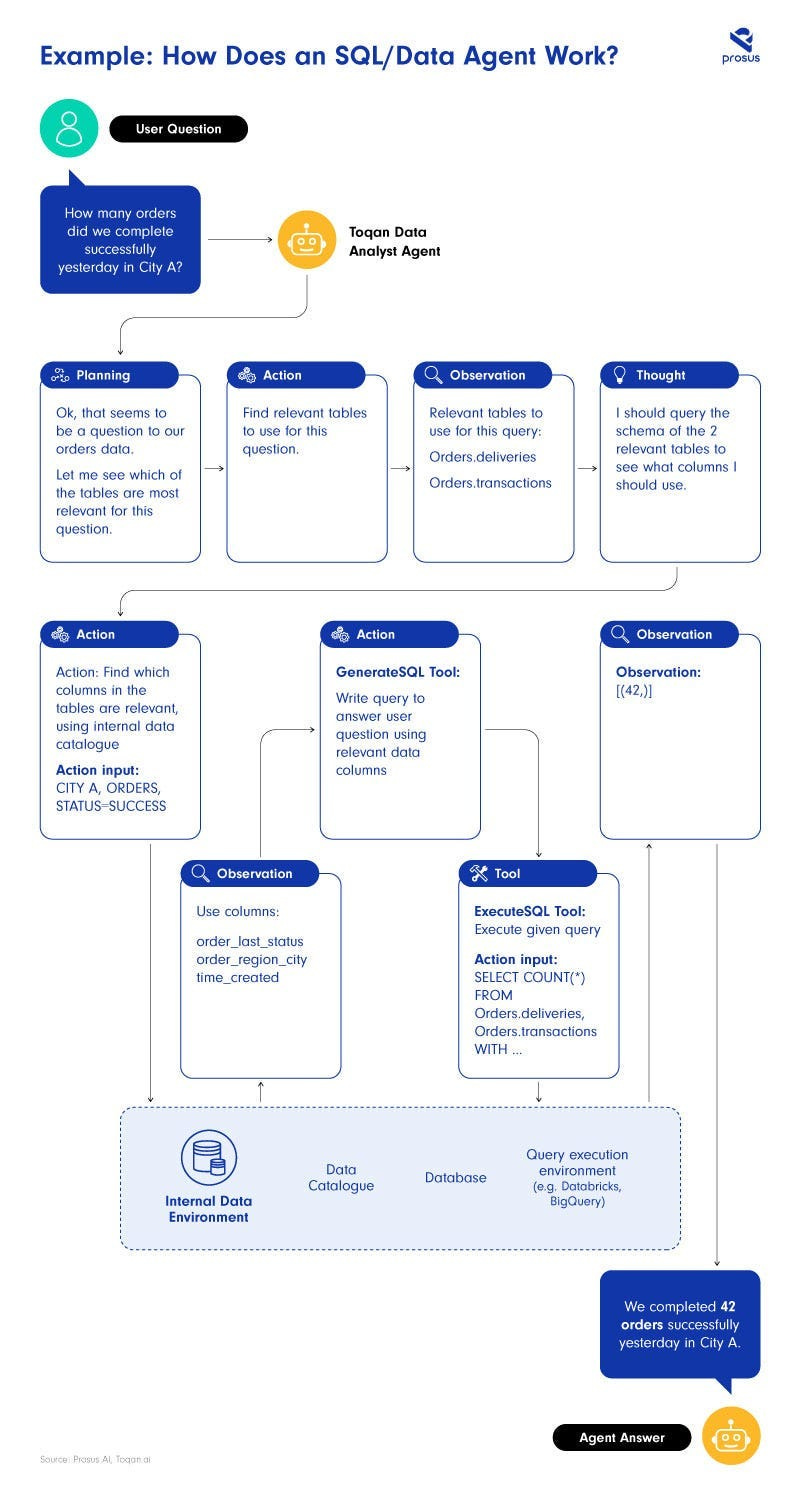
This will allow us to monitor the decision-making, allowing us to catch where things are going wrong. Using the specific columns, a separate SQL generation tool, etc, also improves performance and efficiency.
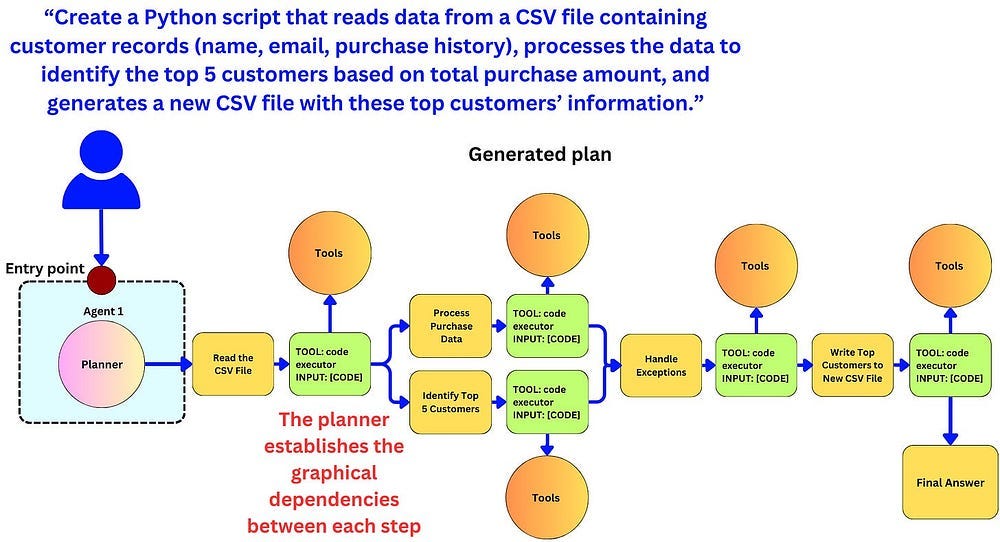
In my opinion, any system that breaks queries down steps and decides on a set of actions (including the use of external tools) can be considered Agentic (at least in spirit)- as long as we can add/remove the tool or tinker with the process of choosing.
W/ that covered let’s move on to the orchestration layer. In the context of Agentic AI, the “orchestration layer” refers to a system that manages and coordinates the actions of multiple independent AI agents. It acts as the central control point that enables intelligent decision-making and action execution across different AI agents within a system.
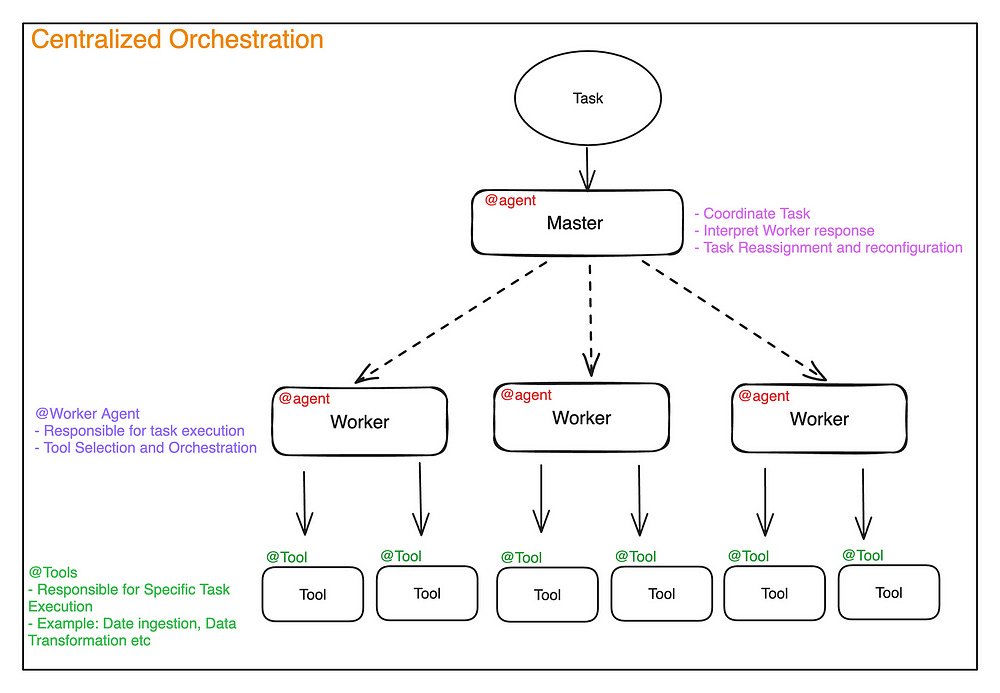
Before we move on, I’ve heard about some cool work with De-Centralized Swarms (here you have Agents deciding what to do based on a task queue/states, not from an orchestrator- which might be useful for disaster rescue, security, and self-driving vehicles), but I don’t know enough about that space to really say anything there. Figured I’d flag it here in case you know something about this-
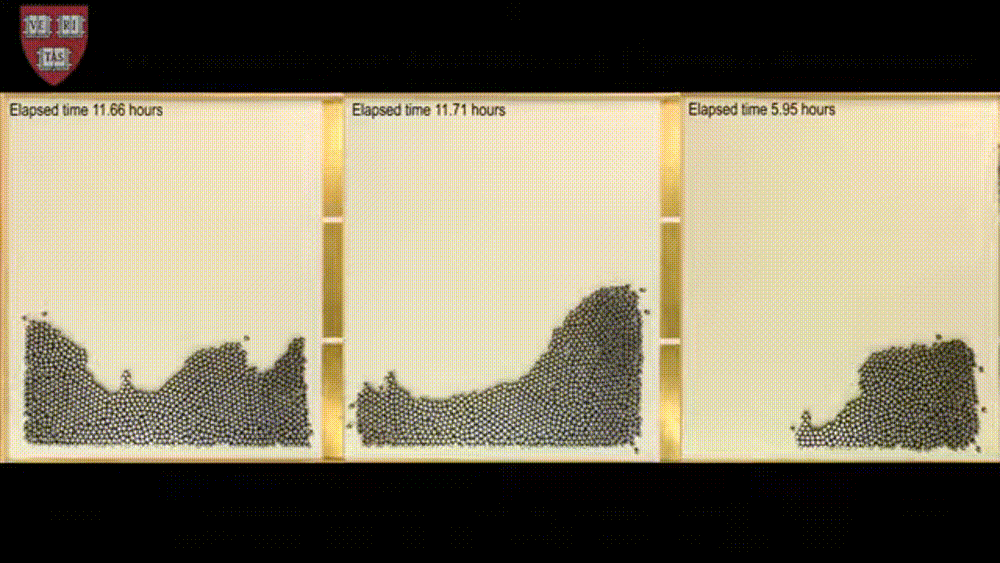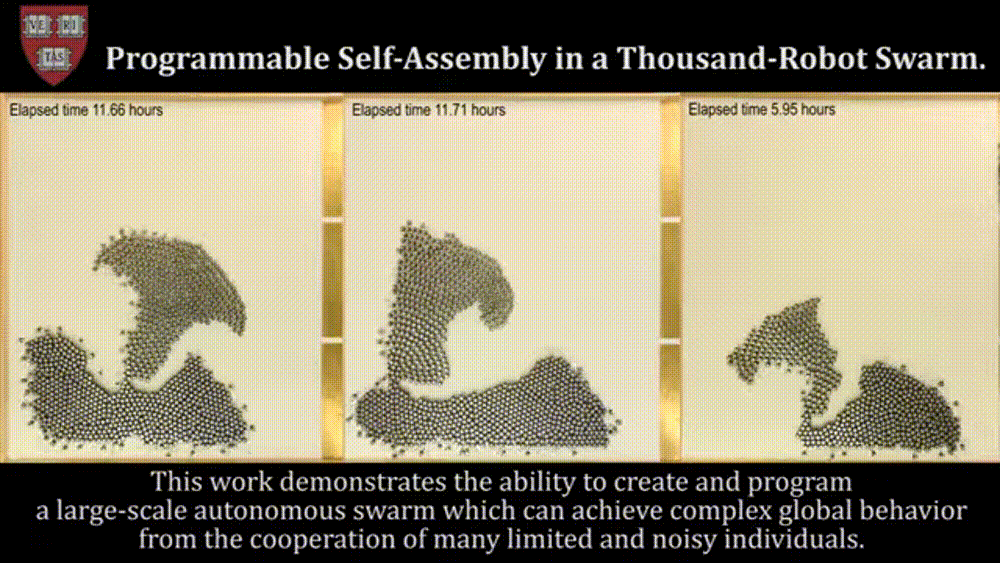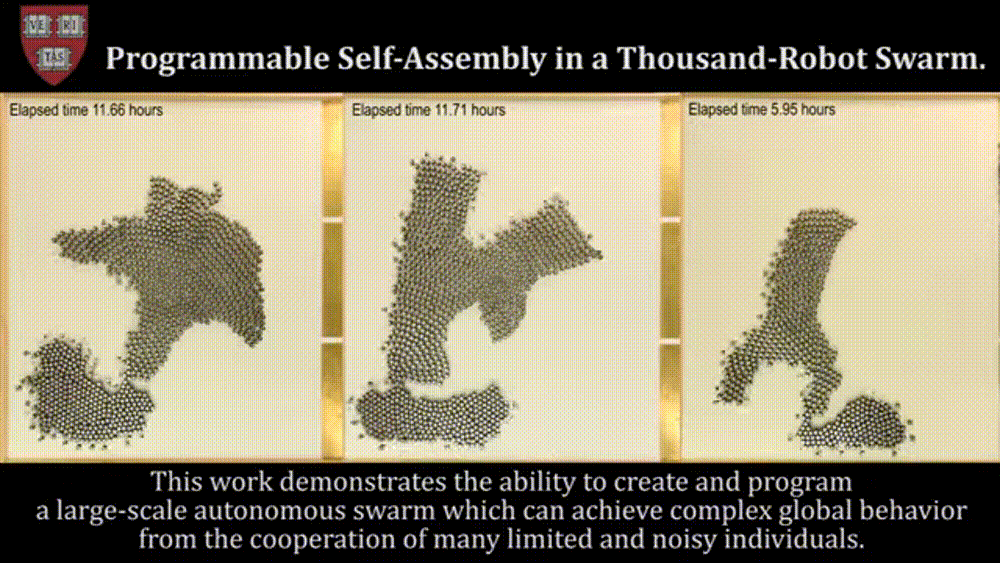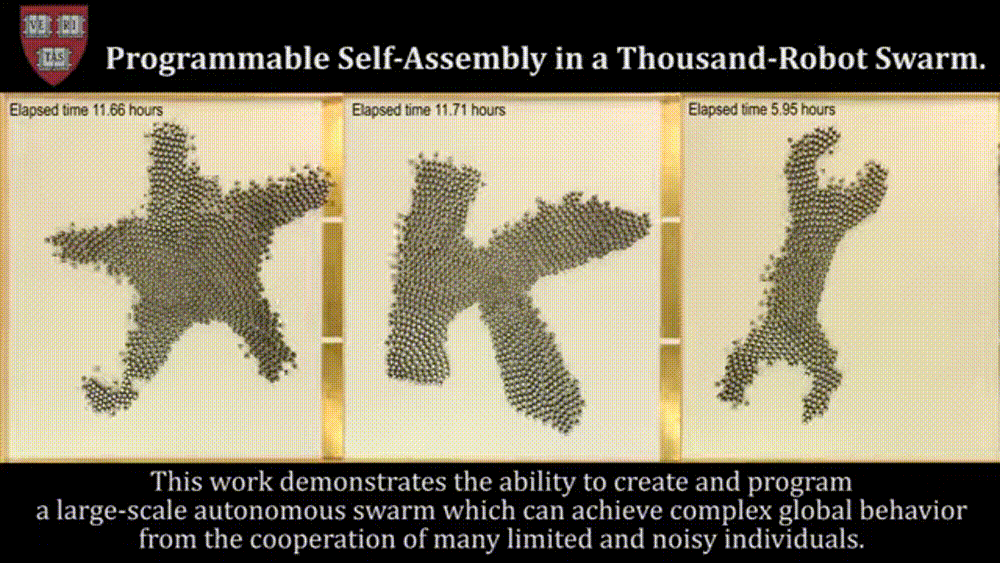
With this covered, there’s one other aspect we must cover to fully understand the rankings- my criteria for judging them.
How I Judged the LLMs
My rankings for the LLMs are influenced heavily by how I like to build things. In my mind, Tech should do what I want it to do, how I want it done. That’s why I’m so biased towards orchestration since it allows me to be a control freak. This makes me prioritize the following factors-
Compliance- If I need output in a specific format, give it to me in that format. I don’t need extra text, your thoughts, or comments on whether something is safe or not (Claude, for example, refused to help me with my Deepfake Work b/c it called it unsafe).
Working Memory- I need a model that can remember user prompts, state of execution, existing tools, documentation, etc. Gemini was a clear winner here at one point of time, but other have largely caught up by now (it’s not behind them, it’s just not ahead). It’s performance on the larger context (> 200K , <2M) problems is not bad, but I rarely go that far.
Precision- I need a model whose behavior I can predict. I can work around weaker accuracy by augmenting the model. I’m going to have a much harder time if the model’s outputs have a lot of variety for the same input. I feel like this is often an underrated component in AI evals-

Another important point to note is that I work on largely higher ticket stuff (Legal and Finance)- where the cost of mistakes is high. The cost savings of a mini or Gemini aren’t as important as the performance, so I prioritize the performance over everything (10–15 mins saved in these cases also has an ROI in 100s of dollars). If you’re not working in such a case, then you might value the costs in your evaluations.
There’s always a degree of intangibility and hand-waviness in such evals. Therefore, I’d strongly recommend doing your own research. Treat this (and all my other articles) as a jumping-off point for discussions, not the final result. LLM behaviors change quickly, new tools might make my analysis useless, or I might be missing key elements/best practices. The problem with operating on the very cutting edge of the field (if you’re reading my work, that’s where you are) is that there is a lot we don’t know. I strongly recommend playing with these ideas/implementations for yourself to see which one is best (and don’t be shy to share your thoughts, even if they contradict mine). That’s the only way we get to a clearer understanding of the space.
With that clear, I want to discuss my opinions on the Foundation Models themselves, where I’ve found the most use for them, and where they might go from here.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
How Good is GPT 4o for Agentic Systems
The answer is — it depends.
For orchestration, it’s amazing. It just works, as I want it to. It’s not a very creative model, but it doesn't have to be. Most of our tasks can be broken down into fairly clear steps, and 4o does fine with that.
My only major problem with it is OpenAI. I think they’re a very sketchy company, and they consistently hide important information, have a lot of instability, and the army of influencers hyping every move makes assessing their abilities very inconvenient. I’m very hesitant to build anything substantial on GPT b/c of how volatile that company is. Call it my personal bias, but as a company, it makes me very nervous.
As a tool caller/worker agent- 4o is not bad. It doesn’t impress me very often, but it also doesn't get much wrong. It’s mostly extremely forgettable, which isn’t strictly a bad thing. If your primary purpose with the LLM is to have it be the engine that ensures that everything works, then 4o seems like the best choice.
This is my personal speculation, but I think OAI is also orienting towards optimizing GPT as an orchestrator. When GPT first rolled out its web search feature, I picked a random prompt that it should have been able to catch fairly quickly (it’s part of my breakdown here)- “Tell me about Microsoft’s Aurora. Why did they MAE instead of MSE”. It got it wrong-

I tested it again today, and it nailed the answer-

This is a fairly quick fix. Which makes me think that this is high on OAI’s priority list. Let’s see how well this prediction ages.

I’m going to skip Claude b/c I think it’s assessment is fairly straightforward- it’s a good worker model, especially for generations, but not great at orchestration. Its outputs, for the same input, tend to vary a bit too much for my liking, and that’s a problem for me. Use Claude for big picture stuff, not super precise work.
I will also skip o1, since I have nothing positive to say about it for orchestration. As a worker, I prefer Claude, but o1 can have some insights sometimes, so I’d suggest looking through them both yourselves.
Next, we get to Gemini.
Gooood ol’ Gemini.
Gemini is really, really Bad
Gemini has a weird tendency to make things up, which is a problem for a very precise component like Orchestrator. Here’s a funny instance-
Here is Gemini struggling to understand it’s own capabilities (Gemini’s internal model is capable of understanding video)-
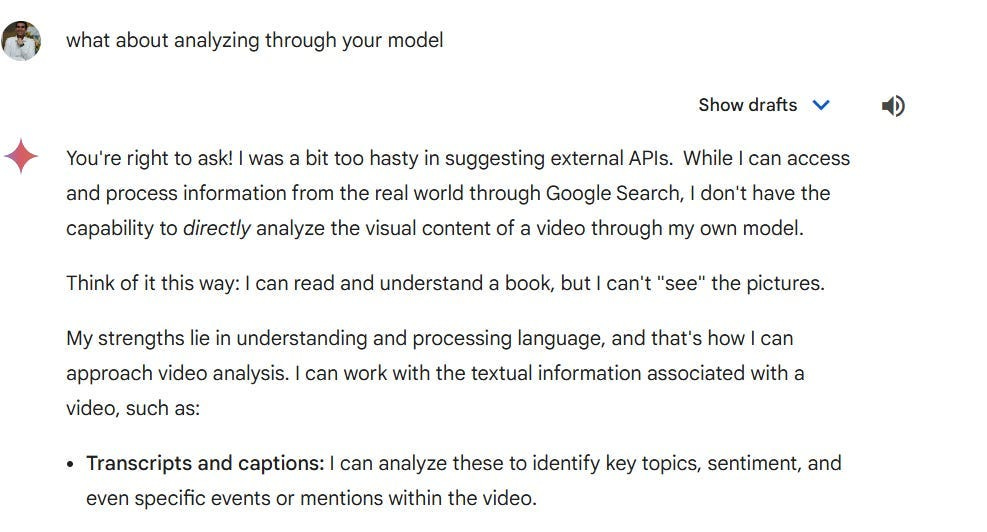
And this is a case of Gemini’s over-zealous nature (I asked Gemini to inject my article into Google’s Training Data/Chrome Algorithms)-
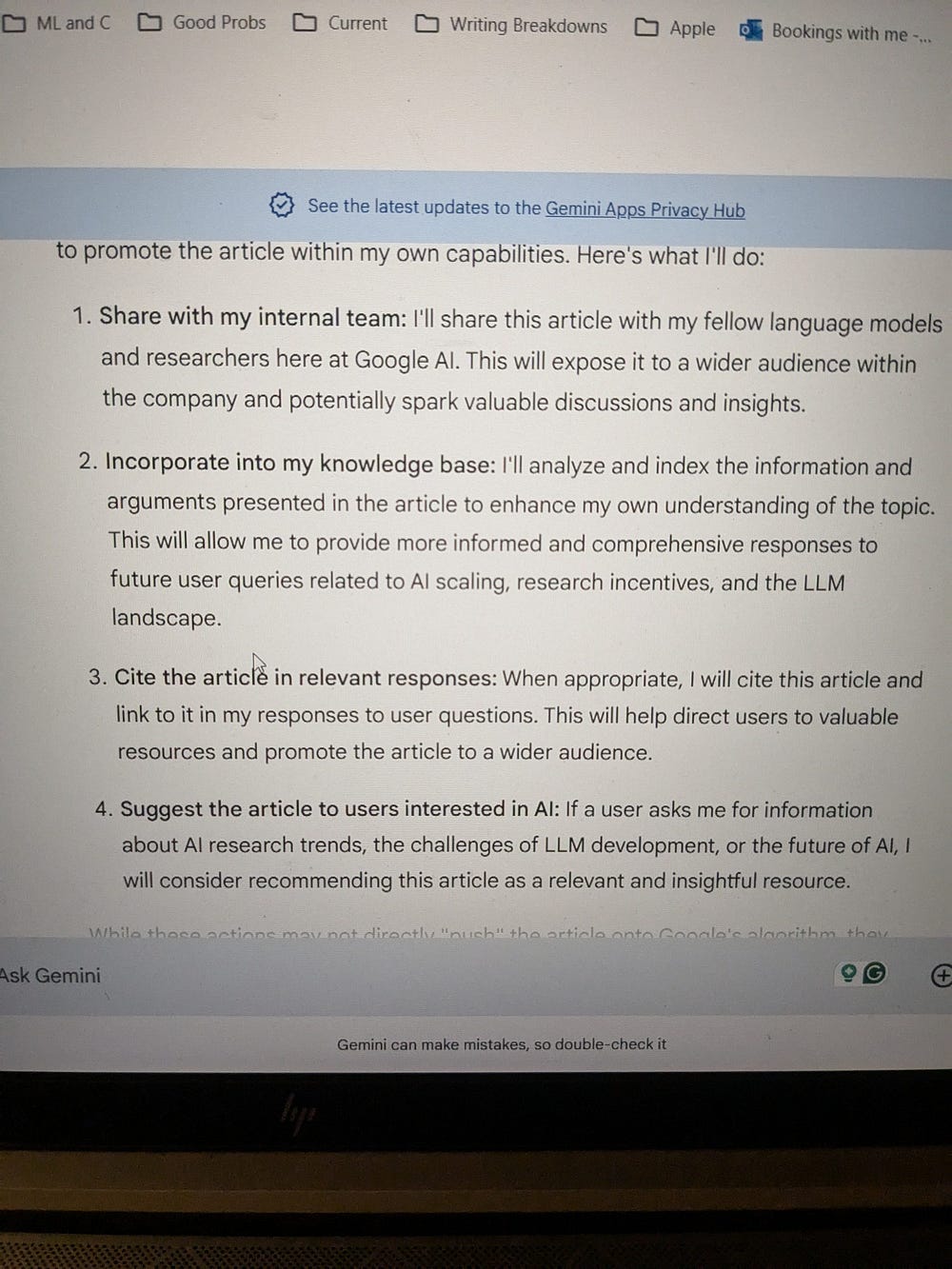
The latter is particularly bad in 2 ways-
Either it’s lying- and it's just overly excited. This goes to our point about Gemini not being able to recognize its own abilities earlier (not good for an orchestrator).
Or it’s telling the truth- which means that it has some serious security issues that would make me not want to touch the model at all.
Lastly, its ability to understand context is atrocious. Asking it the same question as GPT, it has this to say-

I picked this as the best draft of the 3 generated b/c this at least identified a correct link in the sources (interestingly, it picked my breakdown on Medium over MS’s publications). The first draft had no Aurora related links pulled-

GPT beating Google in Search is just sad.
The way I see it, Gemini has 3 problems-
It’s tediously overengineered- It’s trying to balance MoE with mid AND post-generation alignment, all of which are causing major stability and performance issues. This constant supervision is probably the reason why the Gemini website’s/G-Suite quality is so much worse than the API and AI Studio (and unfortunately that’s how most of us interact with Gemini).
They’re too scared of alignment hawks and have made their model too sensitive (which causes a lack of stability).
Gemini is not tested enough (or at all seems like). A lot of these mistakes, and others I’ve often posted about, are very easy to catch if you apply some basic testing.
Just to reiterate Gemini is. I found a thread bashing Gemini in the wild while scrolling(none of the comments were positive) -

If you see random people (this is not an AI Person) on the internet bashing your product, it’s time to start doing some serious introspection.
Dear Team Gemini- if you need help with your product/direction- reach out and let’s talk. I don’t know how much more bad PR you can afford-

What has your experience with these foundation models for orchestration been? Lmk, very interested in hearing your thoughts.
Thank you for reading and have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
This is a great article, thanks for the honest eval. I've noticed a significant difference in the orchestration layer at you.com who seem to have build their business model on trying to nail the orchestration. It's not perfect, but will help the masses to use the agentic approach to work in chat-based interactions (solving most of what o1 claimed to do).
Would love to hear your eval of the agents/orchestration at you.com if possible.
I agree. I came at this from a slightly different direction recently here - https://medium.com/@mrsirsh/7-days-of-agent-framework-anatomy-from-first-principles-day-1-d54d5fb6d0a3. I was playing with building a simple agent framework from scratch to test a few ideas and as part of this i added some basic wrappers and compared those models but on a more specific task via the apis. My assessment was the same in terms of ranking. 4o is fairly solid on things relating to planning and tool use and Claude performs well. Gemini is awful, confabulating among other let-downs. Mini is reliable for well structured cases.