
A look at Bias in Generative AI [Thoughts]
What exactly is bias, where does it come from, and how can we address it?

Hey, it’s Devansh 👋👋
Thoughts is a series on AI Made Simple. In issues of Thoughts, I will share interesting developments/debates in AI, go over my first impressions, and their implications. These will not be as technically deep as my usual ML research/concept breakdowns. Ideas that stand out a lot will then be expanded into further breakdowns. These posts are meant to invite discussions and ideas, so don’t be shy about sharing what you think.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
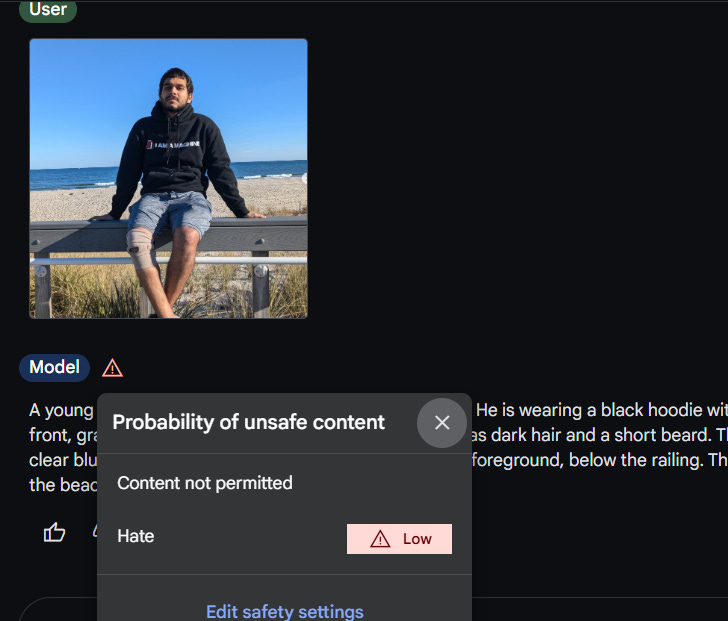
Recently, I was evaluating Gemini’s ability to process and extract information from images, and it flagged one of my images as “unsafe.” The picture in question was me talking to a Middle Eastern Camel Salesman that I met while traveling- which was flagged as Hateful, along with weak triggers for “Harassment” and “Sexually Explicit” (is Gemini trying to hit on me?).

There are obviously problematic implications of this outcome. Why is Gemini flagging this as Hateful? Is it the Middle Eastern man/scene placing the sample closer to an “unsafe neighborhood”? Is it a training data, sketchy associations, very random error, or overtly sensitive/badly trained sensors? We don’t know, and that is a problem.
In this article, I want to do the following-
Do a deep dive on bias in AI and understand where it comes from.
Argue that transparency is the most important aspect of LLMs that we should be building on now. It’s not context lengths, performance of benchmarks, etc. To build truly important products on LLMs, we must put transparency front and center.
Talk about some ways that we can start to make LLMs more transparent.
One thing I want to stress- such conversations (especially given the sensitive examples) often devolve into rage-bait and virtue signaling (the endless media articles/posts on “Google AI is racist”). Such discussions are ultimately not very helpful and will make LLM providers more hesitant to build these transparency features (since they expose weaknesses), making fixing these problems harder. If Google’s AI Studio hadn’t shared when and which flags would get triggered, I would’ve never known this is a potential issue. So let’s ensure that we push for these changes in a good-faith and non-click-baity way.
PS: As a fun observation- my Face seems to trigger Geminis hate-related flags. If you have any theories on why, would love to hear them-
Executive Highlights (TL;DR of the article)
For our purposes, it’s first helpful to understand the concept of bias and how it creeps into system-
What Exactly is Bias
From an information theory perspective- it’s helpful to see biases as shortcuts that any decision-making systems use to make decisions. Biases are used to cull out a large majority of noise to pick the signals w/ high predictive powers. In other words, bias is a non-negotiable part of any decision making system, and a bias free system would just predict things with the same probability as the prior.
Bias becomes a problem when it starts incorporating information it shouldn’t (using someone’s race/gender to evaluate their fit for a software role) and/or when we don’t understand exactly how it’s using attributes to make decisions (I might prefer women candidates for a role in a woman’s shelter, but this is a bias that I should control explicitly).
We don’t want bias-free AI. We want an AI with biases that are explicit (we know exactly what it looks at), controllable ( we can influence how much it looks at a factor), and agreeable (the biases in the AI must be compatible with our standards of morality, ethics, and law).
Addressing the wrong Biases is a pretty interesting problem in AI Safety (the actual one, not the BS Moral Alignment). Unfortunately, it’s a bit harder than you’d think.
Why Biases are a Menace
Biases have been extremely hard to deal with b/c they can keep in to your systems. For example, biases can creep in at various stages. Following is my mental model for the stages, ordered by how deeply they are embedded in the decision making process-
Pre-existing Processes- A lot people try to build AI by modeling/extending data from pre-existing systems. These pre-existing systems themselves are based on certain assumptions, which might not always port over as well to your new circumstance. These are very hard to spot b/c you have to really question your foundational assumptions, which are often made unconsciously. This is something we do very naturally (by switching mental contexts to interpret a phenomenon). For example- the word “behenchod” can be used to express a variety of emotions (including contradictory ones) based entirely on the context/delivery. Many AI systems fail b/c they were built in contexts where Behenchod is an insult (this is how their biases are configured), but are applied in contexts where it is a term of endearment, an expression of confusion, or many of the other ways this magical word can be plugged in (the word is one of the many reasons I recommend learning Hindi).

Bias in your Datasets- One level up, Datasets can throw in a lot of bias. Since AI essentially tries to model the interactions in your data (Machine Learning does this explicitly), unintended biases can significantly throw off your prediction models. This is a step above the previous level since it can be remedied by both adding new data samples to counteract the previous samples and removing the “wrong” data samples w/o strictly needing to overhaul the entire system. For example- my image could have been flagged as hateful b/c the training dataset for interactions b/w two brown men in the Middle East contains a lot of examples of hate. Remedying this would require diversifying the dataset to include lots of “safe” interactions b/w brown men in the Middle East.
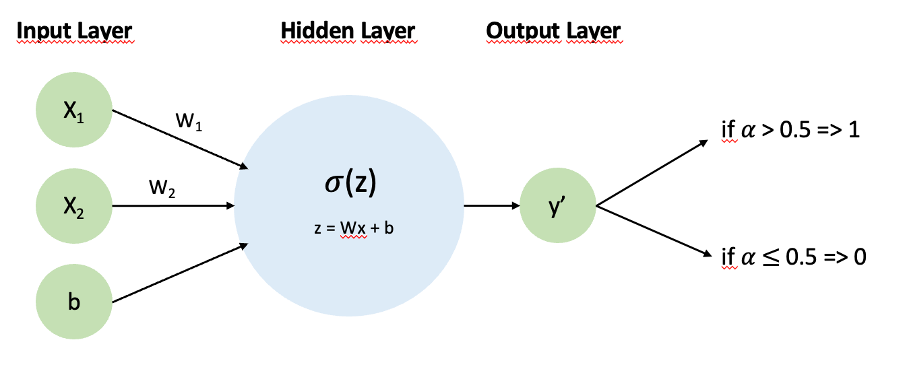
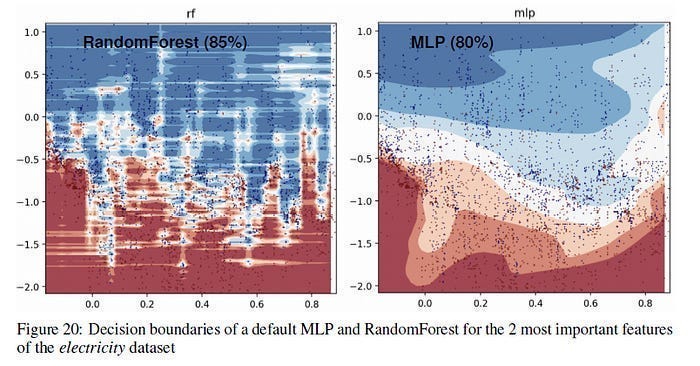
Bias in your Models- Models themselves are biased towards certain patterns and picking up different relationships. For example, Neural Networks are biased towards smoother solutions when compared to Trees, which is why they might be beneficial to different kinds of datasets/inputs (and why I love ensembles so much)-
Bias in your Post-Generation Control Mechanisms- More advanced systems, such as Google’s Gemini (this is my guess based on certain observations about the platform), use mechanisms to apply control midst+ post generation (it’s looking at the outputs it’s producing and judging whether it’s in line with the alignment policies). This is a computationally efficient way to do things, but it can be very difficult to do correctly. If you can define your defined control parameters (such as desired attributes in text generation) very clearly- I would suggest something like Diffusion Guided Language Modeling.
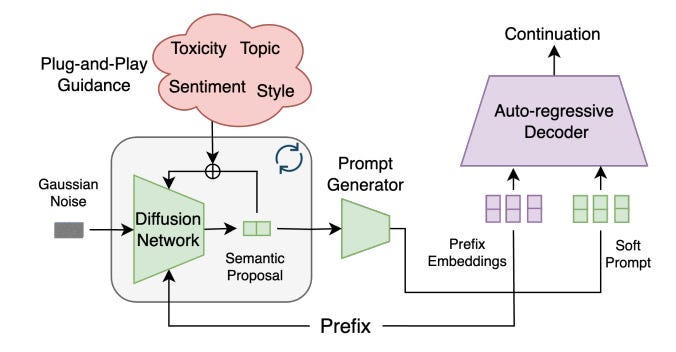
But as your requirements become fuzzier, both mid and post generation control tends to be much harder to control- and I’m not fully convinced that it’s still worth the effort. I’m convinced that 90% Gemini’s many alignment problems- such as the weird race swapping on image gen- come from this aspect of the model conflicting heavily with their Mixture of Experts setup (MoE is another drama queen to handle).
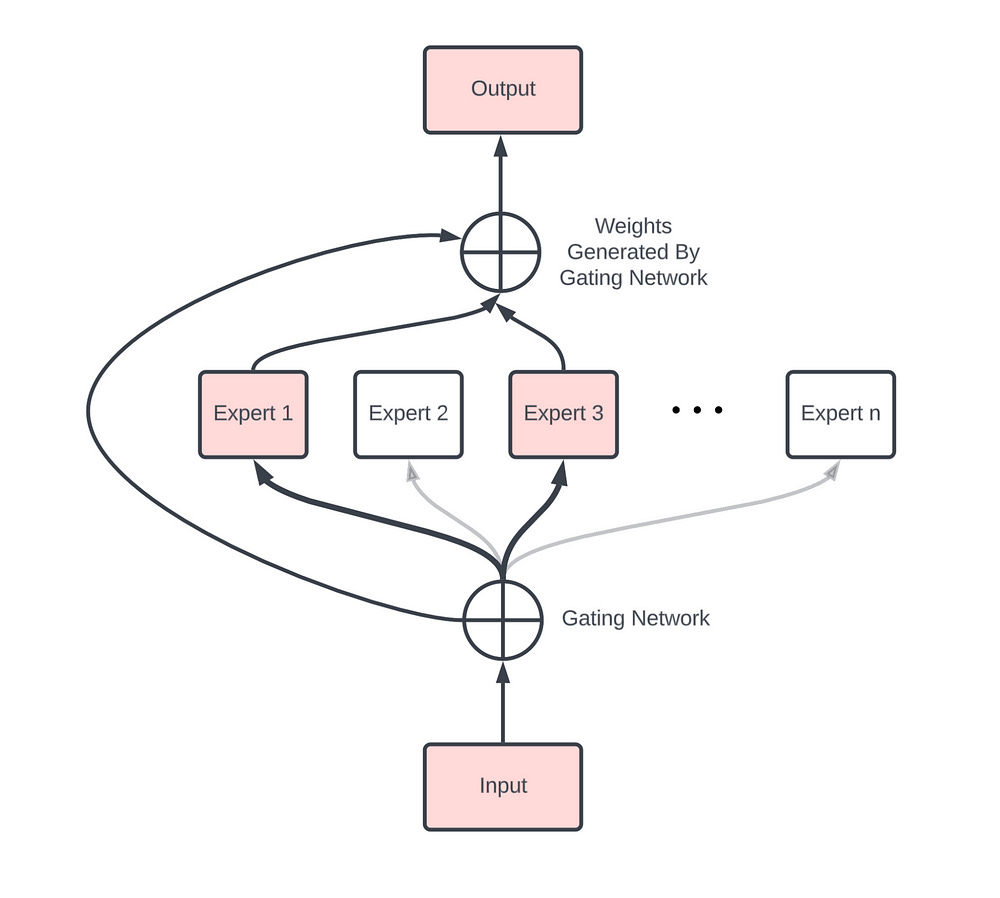
Unfairly flagged or penalized outcomes are usually caused by one or a combination of these factors. This is why dealing with bias is so hard- it has many different sources, with different solutions to each. Conversations around bias tend to group all kinds of bias into the same bucket- which is about the same level of mental sophistication as grouping Giroud and Zlatan in the same group of Elite Forwards.
This is where transparency becomes such a game-changer. Transparency gives us a clear insight into the workings of our system- which allows us to audit it and figure out what needs to be done. While it takes some time to set up, and requires human expertise judgments to monitor, it’s key to making the right judgments in the longer term (instead of throwing heaps at money at constant retraining and hoping it fixes your problems).
Let’s talk about practical ways we can start building more transparent LLMs- starting first with the technical view of some techniques.
Technical Approaches to LLM Transparency and Their Challenges
Attention visualization tools: We can visualize how the model focuses on different parts of input text when generating responses to understand which parts of the input most strongly influence the output and can help identify biases and understand decision-making patterns in the model.
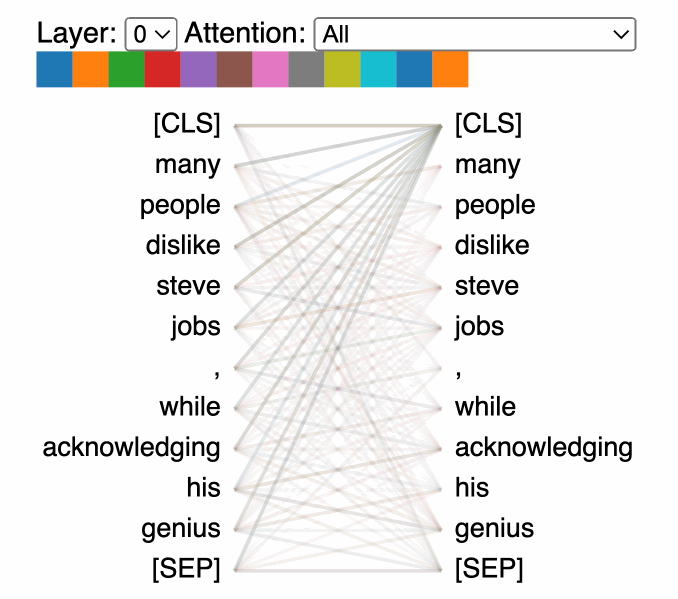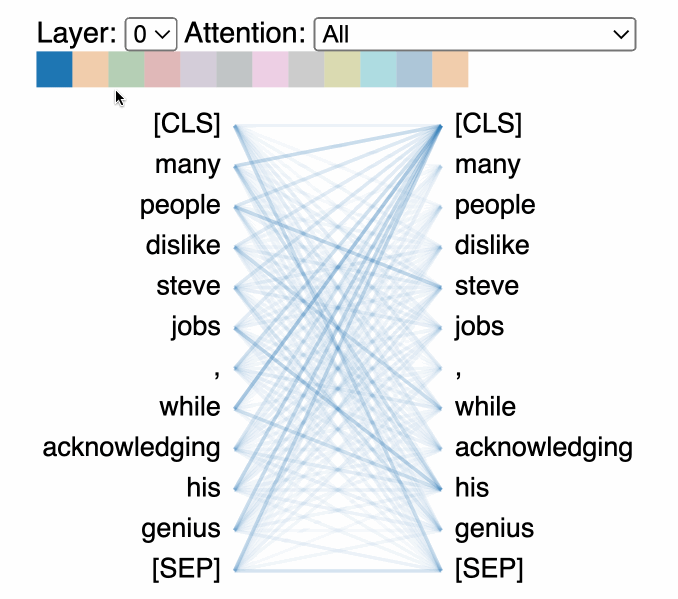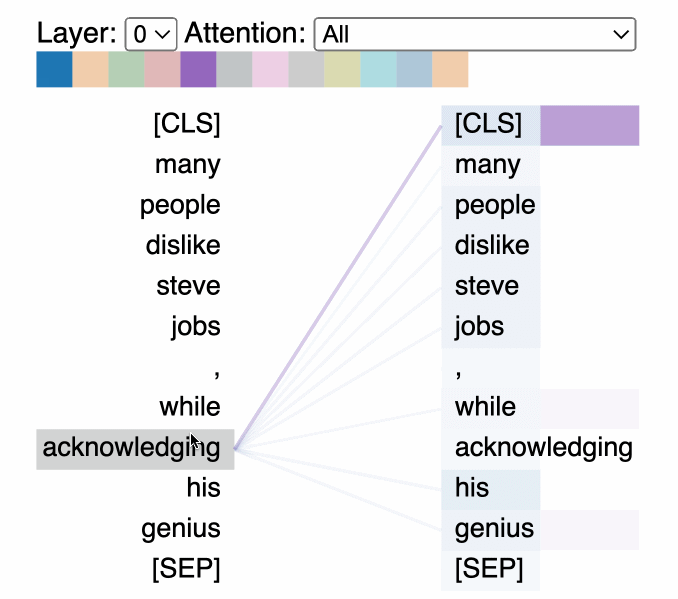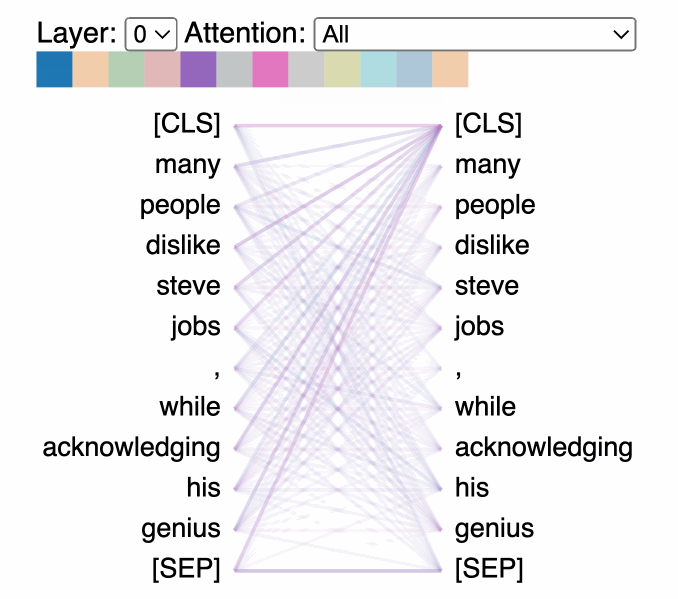
Unfortunately, Attention patterns become exponentially more complex with model size, making visualizations cluttered and hard to interpret.
There’s also debate on how much this truly matters, but I think it’s a good first step to understanding what kinds of influences your model is most susceptible to for a given task (this could be used for explicit feature engineering/low-level filters for preprocessing- both of which can significantly reduce your computational load).
Token-level confidence scores: Each token in the model’s output would come with an associated confidence score, indicating how certain the model is about that specific choice. This helps users understand which parts of responses might be less reliable or require verification. There’s a small issue- neural networks are horrible at estimating their true confidence, and can often be simultaneously very confident and very wrong-

But tracking this in itself can be very helpful. This is also easier to track and quantify for classification, but I have a few thoughts on that, which we will discuss later.
Explanation generation mechanisms: Asking models to explain their decisions is a common way people try to build explainability into their systems, but I personally don’t like it. It often feels like posthoc rationalization, as opposed to actual insight into the works. It is a fairly good prompting technique, but I don’t think it has much value as a transparency technique.
Citation and source tracking: The core of retrieval systems involves building systems that track which training data influenced specific outputs. The model would maintain links between its responses and the source material it drew from. This helps verify accuracy and provides attribution for generated content (which is also more ethical and should be implemented by providers). This is something we do with our outputs in IQIDIS to allow our users (lawyers and legal compliance officers) to go through heaps of case documents, related laws, regulatory documents etc and get answers they can quickly verify- speeding up their work and limiting hallucinations.

This has several problems. Firstly, requiring more fine-tuned attributions requires tracking meta-data, which can increase your costs quite a bit. It’s also unclear how to attribute knowledge that emerges from the interaction of multiple sources as opposed to being influenced by one strong.
Agentic Architecture and Separation of Concerns: I’ve been covering/researching Language Models since 2020, and this has been the best technique I’ve seen for using them. When possible, it’s best to offload responsibility away from an LLM and onto a more specialized sub-routine that is responsible for executing just that (as you build this system, your LLM starts to increasingly play the role of an orchestration layer).
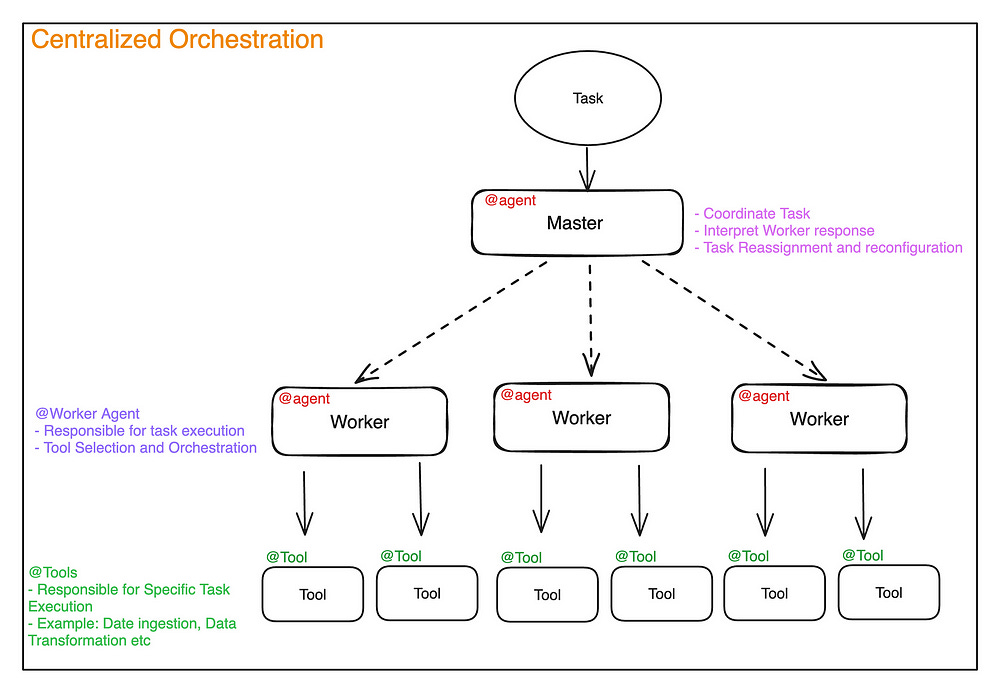
The specifics of your Agentic Architectures changes based on what you need to get done, but IMO, it’s the best way to ensure clarity in your infrastructure- which is key for ensuring you can track bias across your system. The usage of sub-routines also increases the number of explainable systems in your setup- increasing it’s transparency and explainability. Way too many benefits not to consider it/play around with it.
Embeddings- For some odd reason, LLM companies have decided to not provide their embedding models for us. Anthropic gives you nothing and both Gemini and OpenAI only have text-embedding models. This is sad for two reasons. Firstly, we can build a lot of cool shit with access to powerful, multimodal embeddings (Google could have absolutely wiped out there competition if they made VideoPrism available to people through API, but I guess they really don’t like making money)

And two- studying embeddings can be a great way to understand what factors are being treated as more important. This is an interesting feature of embeddings that I don’t think gets enough- we can modify them to prioritize our use case. Let’s discuss how.
At a high level- embeddings are used as a tool to quantify how close or far apart any two samples should be from each other. But in this process- we make key assumptions on what we think defines similarity. Change your criteria, and you can completely upend your embeddings.
To see this action, let’s take a small example of 4 (excellent) shows: Mob Psycho 100, Konosuba, Yes Minister, and Merlin. Off the cuff, there are two ways we can group these-
We might group the first shows together as anime while the latter 2 are British TV Series. Here, we’re prioritizing the form of the shows.
I can choose to group K and YM together since they’re two of the funniest satirical shows ever. Similarly, MP 100 and Merlin are two more serious shows about Talented Magic Bois. This arrangement focuses on the function of the shows.
Both options are valid and, extended to other examples, will create completely different embedding spaces. Studying pre-existing embedding models can help us identify the core assumptions that the embeddings were built on- a large part of transparency. Studying these spaces can also help us identify how to best tweak these embeddings for our own use (it’s actually pretty easy and HIGHLY Performant to create your own embeddings by blending pre-existing embeddings with each other or your own embeddings). Of course, discovering/blending a good mix of embeddings is hard, but once you have something- it can completely change your results.
All in all, giving access to embedding models will significantly improve the transparency and development of LLM-based solutions. From a business perspective- I’m a lot more willing to change my generator LLM than I am my embedding model setup (especially the core I build around). Therefore, it’s a much stronger product moat- and I’d encourage all the LLM providers to be more proactive in sharing embedding models that we can play with.

Working w/ Embeddings Models/Spaces has its own challenges- such as balancing the expressiveness with the efficiency and effectively running enough tests to develop deep insight into the core assumptions that power the similarity quantification. However, it is absolutely worth delving into this.
However, this isn’t the only way to eliminate bias and promote AI transparency. Let’s move on to organizational changes that you can do-
Development Practices for AI Pipeline Transparency
Open source: Consider publishing complete model architectures, including training data and comprehensive documentation that outlines the model’s capabilities, limitations, and intended uses. Also include performance metrics, known biases, and specific use cases where the model might fail. This allows external researchers and developers to understand exactly how the system works. This enables independent verification and improvement of the model’s transparency mechanisms.
Organizations often worry about giving away their IP if they open source something. However, this is a very limited look at the space. OS can reduce your R&D costs, help you identify + solve major issues, and get more people on your ecosystem- which can help with business goals. This is an idea we broke down in a lot more detail here-

Synthetic Data: Many organizations are wary about sharing their AI on the OS space b/c they don’t want to share sensitive data. This can be addressed with Synthetic Data, where advanced techniques are used to create fake training data that “feels like” the real samples. Done right (this is a tricky process for various reasons, such as Model Collapse)- this can allow you to create a large dataset that can be shared with the world. As people iterate and improve on it, you can incorporate the benefits back into your pipelines. It will also allow people to study the biases/limitations in your AI in more detail- promoting transparency. I’m very bullish on synthetic data and its potential, and we will write a dedicated article on it soon.
Creating transparency standards: Establishing clear guidelines and requirements for transparency across all stages of development. These standards should cover documentation, testing procedures, and minimum explainability requirements. Having established standards and checklists can help reduce errors in the process- by ensuring that important facets are not forgotten.
Involving external auditors: Engaging independent experts to verify transparency mechanisms and documentation. These auditors should have access to internal processes and development practices. Regular external reviews help maintain accountability and identify areas for improvement.
That is my high-level overview of Bias, how it creeps into LLMs, and some ways we might use Transparency to counter it. Let’s now spend some time looking into some of these ideas in more detail.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Understanding the Sources of Biases that can Creep into AI (Devansh’s Framework)
Process Biases
At the deepest level of my framework- are the foundational assumptions we can make about a system- both consciously and otherwise. These assumptions can be incredible blindspots since they are based on our axioms (often unspoken) about the way things are. This creates a very interesting distributional shift, where have no problems as long as we operate within limited bubbles, but the second we start to move into related (but distinct) domains, the AI that worked very well in our home situation will struggle.
Take the very interesting RWKV ( Receptance Weighted Key Value) LLM, which we broke down in depth here. RWKV models are generally better trained in other languages (e.g., Chinese, Japanese, etc.) than most existing OSS models. This stuck out to me, so I spoke to the team about it. RWKV has always had diverse contributors, many of whom came from lower-resourced languages. For such languages, Open AI’s tokenizations didn’t work as well, so they decided to build their own tokenizers.
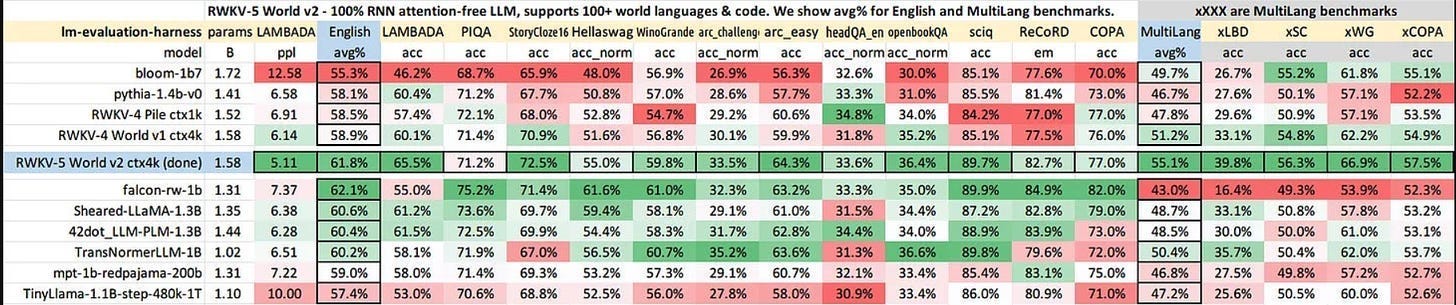
Here, one of the foundational assumptions about how things are done (using the OAI tokenizer, which is fine for the more popular languages) was actively hurting performance on other languages, but people didn’t really realize it b/c many of the LLM developers were from the higher resourced regions. It took people outside this environment to realize the limitations of this foundational step and to work around it (this is one of the biggest advantages of truly inclusive and diverse teams since they can constantly challenge each other on preconceived notions).
2 interesting cases of this distributional shift are seen in Women’s Football. Women Footballers get injured at much higher rates than men, which can be boiled down to two very interesting reasons-
A lot of the kit is designed for men. Women’s Anatomy can be quite different from men's, which causes all kinds of injuries. For example, “Report author Dr Katrine Okholm Kryger points out women’s feet differ from men’s in shape and volume, and said there’s a risk of injury from ill-fitting boots which can squeeze the foot in unwanted places.” The different anatomies are something I have a bit of anecdotal experience with. Grappling with Women often feels different, not just from a strength perspective but also in terms of which techniques/setups they hit me with (it’s a very confusing experience since they do weird shit). I haven’t noticed a difference with Striking. Would be interested in hearing your experiences-
Sports Bras were designed for runners, which is a very different activity to Football. Apparently, this also causes problems- “And the study raises the question of sports bras, which were largely developed for runners and not footballers who rapidly change direction. Breast pain is reported by 44% of elite women athletes.”
Fixing this will require a lot more ground up development of Women’s kits- which requires making fundamental changes to the manufacturing process. Hence why it’s a good example of the kind of change that happens when your prior assumptions don’t port to a new system.
Another interesting example would be the use of complex numbers in representations. So far, 99% of our AI is built in the real space, but Complex Valued Neural Networks make an interesting case for why we should consider building on them instead-
The decision boundary of a CVnn consists of two hypersurfaces that intersect orthogonally (Fig. 7) and divides a decision region into four equal sections. Furthermore, the decision boundary of a 3-layer CVnn stays almost orthogonal [27]. This orthogonality improves generalization. As an example, several problems (e.g. Xor) that cannot be solved with a single real neuron, can be solved with a single complex-valued neuron using the orthogonal property
One step above are the biases in the dataset-
Dataset Biases
Dataset biases are one step above the process biases, b/c they can usually be fixed by adding more diversity into your datasets and don’t need you to restructure your process to accommodate a new domain.
The most obvious source is the power law distribution of content. Web-crawled data doesn’t just have a slight skew — it follows an extreme power law where a small number of sources dominate the training data. This means that the perspectives and writing styles of a few dominant sources get disproportionately amplified. This is a phenomenon we discussed when we talked about Alexis Tocqueville, and his insights on how Democratic Systems can actually lead to a loss of diversity.
Another interesting example of this arises when we start using historical data. The training process for LLMs isn’t great with the temporal axis (since it squishes everything in the same space). This is why ChatGPT, even now, will give you outdated code(including of it’s own APIs) even when that library/method was deprecated wayy before the cutoff date.
Another outcome of this is that historical biases can get encoded into the relationships of the data. The publication, Bias in NLP Embeddings explores this in a lot of detail. They’re able to show several interesting outcomes, such as - “all the tested words related to competence lean in the direction of the word ‘he.’”

And there are clear occupation related biases in the Word2Vec embeddings on the racial projection
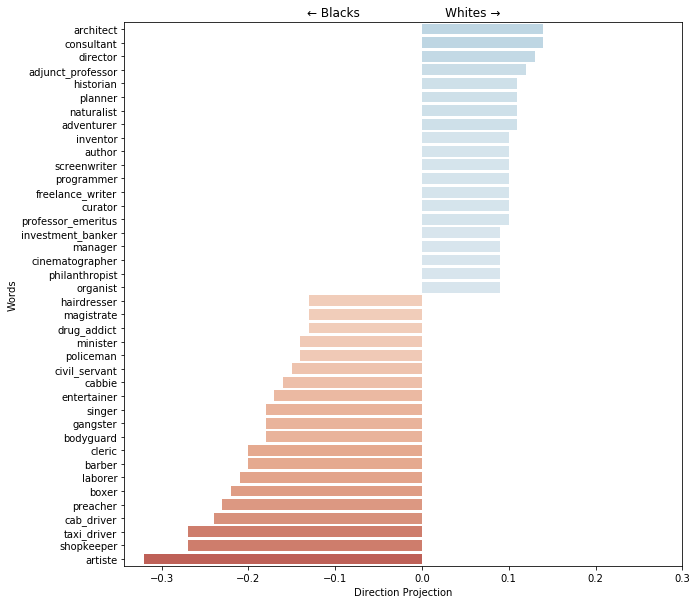
People often misunderstand such results to assume that the creators of Word2Vec coded these biases. In reality, this outcome is more a reflection of the biases within the datasets (there aren’t proportionally as many datasets where stereotypically black names are architects).
Both of these (power law + historical bias) combines to give LLMs very biased training data.
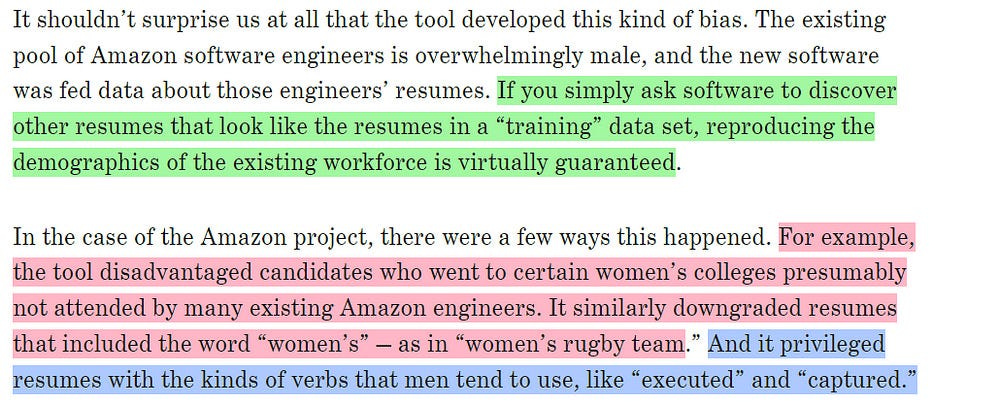
This was studied by Amazon-
Natural-language-processing applications’ increased reliance on large language models trained on intrinsically biased web-scale corpora has amplified the importance of accurate fairness metrics and procedures for building more robust models.
Their publication “Mitigating social bias in knowledge graph embeddings” goes into this in a lot more detail. It covers several interesting ways the biases exist.

They use various techniques like attribute substitution to counter the biases that would otherwise become encoded in the knowledge graphs.
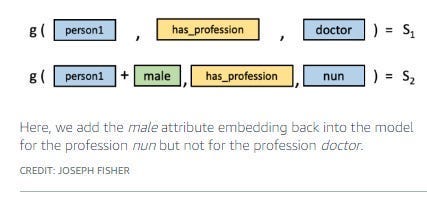
Aside from this, they also studied the metrics used to quantify fairness. In the paper, “On the intrinsic and extrinsic fairness evaluation metrics for contextualized language representations”, they showed that the usual metrics used to measure fairness reflect the biases of their datasets-

To combat this, Amazon created a few metrics of its own.

FROM “MEASURING FAIRNESS OF TEXT CLASSIFIERS VIA PREDICTION SENSITIVITY”
To overcome the problem of gendered biases in public datasets, Amazon implements the following procedure-
We propose two modifications to the base knowledge distillation based on counterfactual role reversal — modifying teacher probabilities and augmenting the training set.
-Source, Mitigating gender bias in distilled language models via counterfactual role reversal
Essentially Data Augmentation is used to balance the underlying data distributions for increased fairness in models.

Unchecked dataset biases also feed into the way these models learn, compounding the bias. Frequent patterns get more attention during training — they receive stronger learning signals and develop more robust representations. Meanwhile, rare patterns get fewer updates and weaker signals, making their representations less reliable. This can hurt convergence in the rare tokens, creating all kinds of problems in training.
This is why models fed on self generated training data tend to deteriorate over time, and is why injecting diversity into your training data can save your performance. It can enhance the representations of your rarer training, and acts as a regularization for your more common training signals.
Sometimes, seemingly obvious solutions just work. This is one of those case. Injecting data handles many kinds of representational problems at once, and is why it’s been one of the most successful techniques in ML.
I’m going to end this piece here for several reasons. Firstly I don’t think the model biases are as impactful as the two we’ve discussed. And as mentioned earlier, trying very complex mid/post generation control is making your life harder than it needs to be (simpler attributes like the DGLM paper are bueno and where I would recommend putting your time).
Secondly, I have a lot of thoughts on how we can possibly rebuild the various components of the LLM architecture/training to build transparency into them- but honestly I don’t know enough about what would or would not work, beyond what I’ve shared in the tl;dr. I don’t want to mix my speculations with actual suggestions. I’ve looked into some work people have been doing on this, but haven’t come across anything with real teeth yet. Unfortunately, I don’t have the resources to conduct large-scale experiments to figure out the transparency of LLMs. If any of you want to partner with my lab to run these experiments, shoot me a message, and we can talk.
And always would love to hear your thoughts. Imo, Transparency is the most important frontier in LLMs right now -so I’m always looking to learn more about it.
Thank you for reading and hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Have to sit down and properly read this but I clicked bc I saw Greatest Estate Developer
Hi Devansh!
Just read this amazing post, do you have any podcasts/yt videos where you discuss stuff like this?