


How Diffusion Models are Improving AI [Investigations]
AlphaFold 3, LLMs and much more are using diffusion to improve performance

Hey, it’s Devansh 👋👋
Some questions require a lot of nuance and research to answer (“Do LLMs understand Languages”, “How Do Batch Sizes Impact DL” etc.). In Investigations, I collate multiple research points to answer one over-arching question. The goal is to give you a great starting point for some of the most important questions in AI and Tech.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Officially moved to New York City this week. No more 1.5-hour commutes for me babbyyyy. If you wanna catch lunch or coffee- shoot me a message. I need more friends.
Executive Highlights (tl;dr of the article)
This article will be long and have a lot of references, so I would suggest bookmarking/saving it, and coming back to it periodically.
Google’s AlphaFold 3 is gaining a lot of attention for its potential to revolutionize bio-tech. One of the key innovations that led to its performance gains over previous methods was its utilization of diffusion models
AlphaFold 3’s capabilities come from its next-generation architecture and training that now covers all of life’s molecules. At the core of the model is an improved version of our Evoformer module — a deep learning architecture that underpinned AlphaFold 2’s incredible performance. After processing the inputs, AlphaFold 3 assembles its predictions using a diffusion network, akin to those found in AI image generators. The diffusion process starts with a cloud of atoms, and over many steps converges on its final, most accurate molecular structure.
AlphaFold 3’s predictions of molecular interactions surpass the accuracy of all existing systems. As a single model that computes entire molecular complexes in a holistic way, it’s uniquely able to unify scientific insights.
While we wait for the final publication, I figured this would be a good time to look into Diffusion Models and how they are pushing the boundaries in a few different domains.
The article is split largely into two ‘parts’. The first part goes over the background of Diffusion-
What are Diffusion Models in Machine Learning: Diffusion Models are generative models (they generate data similar to what they were trained on). Diffusion Models follow 2 simple steps. First, we destroy training data by incrementally adding Gaussian noise. Training consists of recovering the data by reversing this noising process. A well-trained Diffusion Model can create whatever we want from a pool of random noise. Replace noise with a space of embeddings, and you can probably see why we’re cooking here.

The advantages of DMs: Diffusion models have 3 major advantages that make them strong contenders for your generation based tasks- High-Quality Generation: Diffusion models generate data with exceptional quality and realism, surpassing previous generative models in many tasks; Versatility: They are applicable to a wide range of data modalities, including images, audio, molecules, etc; and Controllability: Diffusion models offer a degree of control over the generation process, allowing users to guide the output based on specific requirements or conditions.
The Drawback of Diffusion Models- As should be evident by their design, DMs are very expensive. There is research to mitigate their costs, but this is still a sore spot for DMs.
Why Diffusion Models Work Well (speculation by me)- By their very nature, Diffusion Models are trained to look at data points holistically at every inference step. Compared to generators like GANs- Diffusion has the luxury of creating outputs in multiple steps, giving us finer control (think about how hard it is to do anything complex in one go). Compared to auto-regression (used by LLMs like ChatGPT)- DMs have greater flexibility. Lastly, the process of noising and denoising plays a similar role to strong data augmentation, wherein the model is forced to build deeper relationships for features. We can also chain Diffusion Models with other models very well, leading to very cool applications

Part 2 is a look at Diffusion Models in multiple fields to show how versatile Diffusion Models can be. These include-
Image Generation and Manipulation: This is what they became famous for. Diffusion models excel in image-related tasks due to their ability to learn the complex distribution of natural images. By gradually denoising random noise, they generate images with remarkable fidelity and diversity, making them ideal for creative applications and image restoration tasks. There is also some very exciting research using Diffusion Models for the reconstruction of Medical Images. We’ll cover all of this.
Audio Generation and Processing: The sequential nature of diffusion models makes them well-suited for audio generation and processing. They can capture the temporal dependencies within audio data, leading to realistic and high-quality audio synthesis and enhancement. We can also combine the two do video generation.
Molecule Design and Drug Discovery: Diffusion models offer a novel approach to molecule design by navigating the vast chemical space with ease. They can learn the underlying patterns in molecular structures, enabling the generation of molecules with desired properties for pharmaceutical and materials science applications.
Language Models: One of my inspirations for creating this article, Diffusion has shown some promise in NLP and text generation. Text Diffusion might be the next frontier of LLMs, at least for specific types of tasks. We will discuss the minutiae of Autoregressive vs Diffusion based text generation later in this article.
Temporal Data Modeling: Diffusion models are adept at handling sequential data like time series. They can fill in missing data points (imputation), predict future values (forecasting), and generate realistic audio waveforms (waveform signal processing).
Robust Learning: Diffusion models contribute to building more robust AI systems. They can “purify” images corrupted by adversarial attacks, removing malicious noise and restoring the original image. This helps make AI models more resilient to manipulation.
The rest of this article will explore these ideas in more detail. As we dig into the ideas (especially part 2)- I feel compelled to stress one point. My writing makes no claims of academic respectability or neutrality. A technique like Diffusion has tons of usage and relevant papers that you could refer to. This article is not a comprehensive overview of the technique. I talked to a few experts, looked at different publications, picked the ones that I found most interesting/useful, and wrote/experimented based on them. There are lots of use cases/publications that I missed or chose to skip. Do your research to evaluate its utility to your specific use case. This piece (all of my work) is intended to serve as a foundation for your own exploration into the topic rather than the final answer to your questions.
PS- For more comprehensive literature review-style articles, I would suggest following blogs like Lilian Weng (who has a great overview of Diffusion here), Deep (Learning) Focus, and Ahead of AI. All 3 have helped me a ton. For Diffusion Models specifically, read “Diffusion Models: A Comprehensive Survey of Methods and Applications” which is a very detailed exploration of the topic.
Caption- 7BBV - Enzyme: AlphaFold 3’s prediction for a molecular complex featuring an enzyme protein (blue), an ion (yellow sphere) and simple sugars (yellow), along with the true structure (gray). This enzyme is found in a soil-borne fungus (Verticillium dahliae) that damages a wide range of plants. Insights into how this enzyme interacts with plant cells could help researchers develop healthier, more resilient crops.
Part 1: Understanding Diffusion Models
Skip this section if you understand Diffusion Models (or scroll down to the relevant subsections)
What are Diffusion Models
As we talked about, Diffusion Models are based on the noising and denoising input. While the details vary, we can boil down Diffusion-based Generation into two steps-
Forward Diffusion: We take a data sample, like an image, and iteratively add small amounts of Gaussian noise at each step. This slowly corrupts the image until it becomes unrecognizable noise. The model learns the pattern of noise added at each step. This is crucial for the reverse process.

Reverse Diffusion: We begin with the pure noise from step 1 as input. The model predicts the noise added at each step in the forward process and removes it. This progressively denoises the input, gradually transforming it into a meaningful data sample.

At the risk of oversimplification, we will move from here. Diffusion has a lot of important math details that are hidden in the details, but I think it’s more important to discuss how/why Diffusion is being used to solve various challenges. I also don’t have any insightful commentary to add to the math/derivation. If you’re interested in that, please refer to either Weng’s aforementioned article or check out this piece by Assembly AI.
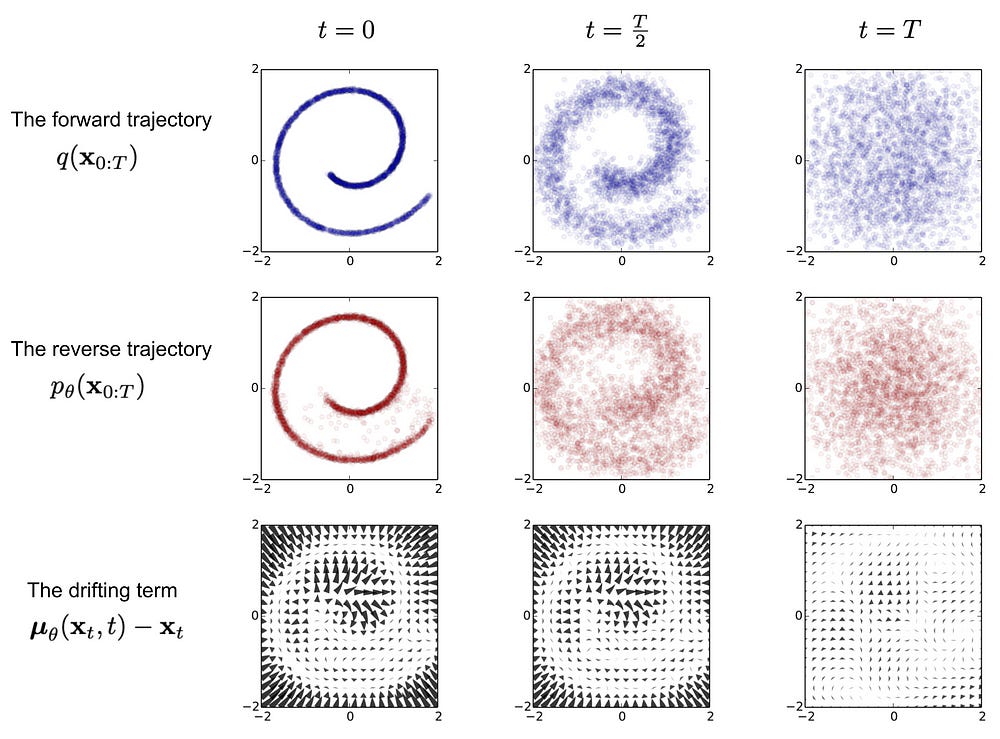
For now, we move on to the next section. Why use Diffusion Models when other techniques exist (as you might imagine, they can be very expensive)? There are two ways to answer this question. First, we will talk about why DMs are good. Then, I will speculate why Diffusion is an advantage over techniques.
Their High Cost
The iterative nature of the generation process, involving numerous denoising steps, demands substantial computing power and time, especially for high-resolution data. This makes them less practical for real-time applications or resource-constrained environments and has been a huge blocker.

To enhance the efficiency of DMs, researchers are exploring several avenues. Optimized sampling techniques aim to reduce the number of denoising steps while maintaining sample quality. This includes employing smarter discretization schemes, developing specialized ODE/SDE solvers tailored for diffusion, and leveraging knowledge distillation to train faster samplers.
Furthermore, exploring latent space diffusion can significantly reduce computational burden by performing the diffusion process in a lower-dimensional representation of the data.

Lastly, it’s always good to combine DMs with other techniques like compression and other generators to boost efficiency.
What makes Diffusion Models Useful
At its core, the entire Diffusion process gives us three advantages
High-Quality Generation: Diffusion models generate data with exceptional quality and realism, often surpassing previous generative models in many tasks. This stems from their ability to learn the underlying data distribution in a granular manner through the iterative denoising process. The slow and steady refinement from pure noise to a coherent data sample results in highly realistic outputs.

Versatility: Diffusion models are remarkably flexible and can be applied to a wide range of data modalities, including images, audio, molecules, and more. This versatility comes from the model’s core mechanism of manipulating noise, a concept that can be applied to any data type represented digitally. Whether it’s pixels in an image, amplitudes in a sound wave, or atoms in a molecule, diffusion models can learn to generate and manipulate them. Diffusion can also be molded into different use-cases.
Step-by-Step Control: The step-by-step generation process in diffusion models allows users to exert greater control over the final output. Unlike traditional generative models that produce an output in one shot, diffusion models progressively refine the generated data from noise to a final sample. This gives us greater transparency and the ability to jump in the middle to take experiments in new directions.
Okay but why do DMs work as well as they do? I couldn’t find any concrete theoretical explanations, so let’s do some theory-crafting.
Why Diffusion Models are So Good
Take a complex generation task like writing this article. Traditional generators like GANs generate everything in one shot. As complexity scales up, this becomes exceedingly difficult. Think about how hard it would be paint a detailed scene by throwing paint at a canvas once. This is essentially what a GAN does. If you’ve read JJK (you absolutely should), this is very similar to the whole “giving someone water w/o giving them the bottle” explanation for Sukuna’s Domain.

This is why modern text generators are based on Autoregression. AR scales a lot better, which gives our models the ability to handle more complex tasks. Since AR goes step by step, you also have the ability to stop generation mid-way through or take it in a new direction. Those are two advantages of Autoregression over trad generators. However, AR models can get lost in their sauce (I’m sure we’ve all had experiences with this). Going back to our article example- it’s really hard to write good articles just using autocomplete without having a very clear picture of what you want to do. Pure AR also degrades quickly b/c we can’t go back and edit previously generated components (if I was writing an article word by word, then I could not go back to an earlier para for restructuring).
Diffusion has the same step-by-step advantage as AR but with a twist. Since we denoise/input the entire input at every time step, Diffusion allows us to be a lot more contextual. This is closest to how I write. I generally have a fuzzy idea of what I want to cover, which is refined as I write more. At every step, I might go back and fix a much earlier component. This makes the end result much more cohesive.
With all that background out of the way, let’s finally start looking at the use of Diffusion Models in various contexts.
This approach allows us to rapidly learn, sample from, and evaluate probabilities in deep generative models with thousands of layers or time steps, as well as to compute conditional and posterior probabilities under the learned model.
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Fun fact- Physics is what inspired Diffusion Models. Don’t just study AI/Tech papers. Boxing your knowledge will only hurt you.
Part 2: Generation with Diffusion Models
Vision Related Tasks
Note: I will be leaving out a LOT of details in the specific image generation/videos. Diffusion for Vision is a massive field, and I’m going to group them into general families. Look into the deets yourself.
SDEdit does not require task-specific training or inversions and can naturally achieve the balance between realism and faithfulness. SDEdit significantly outperforms state-of-the-art GAN-based methods by up to 98.09% on realism and 91.72% on overall satisfaction scores
-SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Diffusion Models have shown amazing raw-generation capabilities-

But they can go beyond that to help with tasks like-
Super-Resolution: Enhancing the resolution of low-resolution images to create higher-resolution versions. Diffusion models like SR3 and CDM progressively refine the image by iteratively denoising, resulting in high-quality upscaling. We shared an example earlier (the pig wearing a hat).
Editing: Diffusion can be used for more than just filling in missing or damaged parts of an image. It can be used to fill in entirely new sections in specific sections.

Generative Pre-Training: Diffusion-based models might be very good for pertaining vision models.
Point Cloud Completion and Generation: Point clouds are 3D representations of objects. Diffusion models help in in both generation and completion. “Luo et al. 2021 [173] has taken the approach of treating point clouds as particles in a thermodynamic system, using a heat bath to facilitate diffusion from the original distribution to a noise distribution. Meanwhile, the Point-Voxel Diffusion (PVD) model [346] joins denoising diffusion models with the pointvoxel representation of 3D shapes. The Point Diffusion-Refinement (PDR) model [178] uses a conditional DDPM to generate a coarse completion from partial observations; it also establishes a point-wise mapping between the generated point cloud and the ground truth.”
Medical Image Reconstruction- Medical Images are expensive to obtain. They are even harder to annotate since only professionals can do that. (as much as you love me, you probably don’t want me looking at your X-rays to tell you if your bones are in good condition). DMs have shown great promise in reconstructing Medical Images.
Robust Learning: Diffusion models can be used to purify adversarial examples by adding noise and reconstructing clean versions, mitigating the impact of adversarial perturbations. We can also diffusion-based pre-processing steps to enhance the robustness of models against adversarial attacks.

Anomaly Detection: Diffusion models can be applied to identify unusual or unexpected patterns in images. “These approaches may perform better than alternatives based on adversarial training as they can better model smaller datasets with effective sampling and stable training schemes.”
Text Diffusion for Natural Language Processing and LLMs
I’ve been researching a lot of large context-length RAG for some clients, and that’s when I came across, “Transfer Learning for Text Diffusion Models”. This report wants to “see whether pretrained AR models can be transformed into text diffusion models through a lightweight adaptation procedure we call ``AR2Diff’'”.
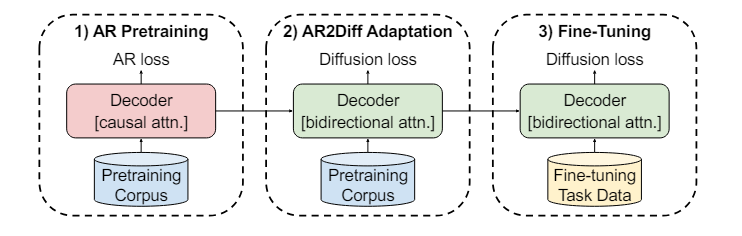
While text diffusion lags behind in machine translation, it shows promise in code synthesis and question answering, even outperforming autoregressive models. These findings suggest text diffusion, which can be faster for long text, deserves further exploration.

Microsoft’s GENIE, introduced in the paper “Text generation with diffusion language models: a pre-training approach with continuous paragraph denoise” is another interesting example of Diffusion for LLMs.
GENIE is a large-scale pre-trained diffusion language model that consists of an encoder and a diffusion-based decoder, which can generate text by gradually transforming a random noise sequence into a coherent text sequence. … Our experimental results show that GENIE achieves comparable performance with the state-of-the-art autoregressive models on these benchmarks, and generates more diverse text samples.
I don’t know if it’s just me, but Text Diffusion seems to act as a bridge b/w Encoder-based and Decoder-based LMs. This is why I’m particularly excited about their potential.
Audio + Video Generation
A lot of high-quality audio and video generators also rely on Diffusion Models. DMs have been making waves in Text-Audio Generation: “Grad-TTS [215] presents a novel text-to-speech model with a score-based decoder and diffusion models. It gradually transforms noise predicted by the encoder and is further aligned with text input by the method of Monotonic Alignment Search [219]. Grad-TTS2 [136] improves Grad-TTS in an adaptive way. Diffsound [310] presents a non-autoregressive decoder based on the discrete diffusion model [6, 254], which predicts all the mel-spectrogram tokens in every single step, and then refines the predicted tokens in the following steps. EdiTTS [267] leverages the score-based text-to-speech model to refine a mel-spectrogram prior that is coarsely modified. Instead of estimating the gradient of data density, ProDiff [109] parameterizes the denoising diffusion model by directly predicting the clean data”
DM-based video editors are also popular, with big names like Imagen being very well known.
Temporal Data Modeling
Time Series Imputation: Missing data can be a huge menace for time-series-based data. Given how they’re trained, it’s not too surprising that DMs can handle data imputation for TS. CSDI Utilizes score-based diffusion models, trained in a self-supervised manner to capture temporal correlations, for effective time series imputation. “Unlike existing score-based approaches, the conditional diffusion model is explicitly trained for imputation and can exploit correlations between observed values. On healthcare and environmental data, CSDI improves by 40–65% over existing probabilistic imputation methods on popular performance metrics. In addition, deterministic imputation by CSDI reduces the error by 5–20% compared to the state-of-the-art deterministic imputation methods. Furthermore, CSDI can also be applied to time series interpolation and probabilistic forecasting, and is competitive with existing baselines.”

Time Series Forecasting: Predicting future values in a time series, important for various prediction tasks. Take TimeGrad, an autoregressive model that employs diffusion probabilistic models to estimate gradients of the data distribution. The authors show that the approach “is the new state-of-the-art multivariate probabilistic forecasting method on real-world data sets with thousands of correlated dimensions.”

As you can see, Diffusion Models are way more than simple image generators. They also have other uses in material design and drug discovery, but I will cover them in special articles dedicated to those topics (we have articles dedicated to AI for drug discovery, chip design, material development, and more in the works). If you want me to push any of them up top, shoot me a message. Otherwise- take it easy, keep working, and I’ll catch y’all soon. Peace.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Great to share
The Sora team at OpenAI just confirmed it uses a Transformer / Diffusion architecture. Diffusion is going to be a big part of the next wave. Actually just wrote about this. Would love your thoughts!
https://open.substack.com/pub/matthewharris/p/what-comes-after-llms?r=298d1j&utm_medium=ios