
How we built an efficient Knowledge Intensive RAG for Legal AI at IQIDIS[RAG]
Lessons from our journey into Lowering Hallucinations and Improving Quality of Legal Generations without breaking the bank

Hey, it’s Devansh 👋👋
This article is part of a series on Retrieval Augmented Generation. RAG is one of the most important use-cases for LLMs, and in this series, we will study the various components of RAG in more detail. The goal is to build the best RAG systems possible. If you have anything to share, please do reach out.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget, and you can expense your subscription through that budget. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights (TL;DR of the article)
Knowledge-intensive RAG (KI-RAG) is a special kind of RAG that involves dealing with dense, specialized, and extensive knowledge sources when creating AI. While general RAG setups can be deployed in Knowledge-Intensive settings, this is not a good idea because they will fail to capture the nuances of the data. Building KI-RAG systems requires a lot more handling and constant maintenance, making them more expensive than traditional RAG.
However, there are certain fields, in which KI-RAG delivers extremely good returns. Law is one such domain, where KI-RAG is the best approach for 3 reasons-
Legal Expertise is expensive. If a law firm can cut down the time required for a project by even a few hours, they are already looking at significant savings. These savings (or extra earning potential by allocating lawyers elsewhere) would make up for the additional costs of the KI-NLP.
Mistakes are Costly- A mistake can cost a firm millions of dollars in settlements and serious loss of reputation. This high cost justifies the investment into better tools.
Law has Nuance- There is a lot of nuance to Law. Laws can change between regions, different sub-fields weigh different factors, and a lot of law is done in the gray areas- “In my experience, factually right or wrong answers are not that common in a business law context, most relevant issues are up for debate”. Furthermore, different firms might want to handle the same cases in different ways (using different cases/arguments), based on their specialization. All of this requires specialized handling and setup.

Over the last few months, I have worked with IQIDIS Legal AI to build and refine their proprietary KI-RAG-based Legal AI Platform. In this article, I will be sharing our learnings on how we built an effective, high-performing KI-RAG system for the legal domain. While I won’t dive into the proprietary implementations and techniques, the principles discussed will both into our innovative approach and into what kinds of challenges you might have to solve when building KI-RAG systems.
PS- After phenomenal early user feedback, we’re moving beyond early development and are looking to scale up our operations. If you are a law firm interested in a demo, an investor looking to invest in legal AI, or want to explore partnership opportunities, please reach out to us at info@iqidis.ai.

Before we get into the technical details, it is important to review the overall impact of KI-RAG from various perspectives. In terms of impact, it is fairly isomorphic to traditional RAG (covered below) but with a greater energy impact and a much higher need for good transparency/observability (so you can monitor/massage your system).

Now is a good time to get into the technical details. Following is a high-level overview (we keep trying various models and architectures, so use specific names like BM25 or DPR more as examples as opposed to final decisions)-

This architecture is meant to help us hit the following goals-
High Performance- We break down performance into a few different metrics- time-saving (intelligent responses), monitoring (helping our users understand why our AI makes certain decisions), adaptability to feedback (adjusting behavior based on user feedback), and adherence (if the user specifies Texas law, then it should stick to Texas and not look at Cali law- which can lead to hallucinations). This allows us to get a lot more granular in our evaluations, helping with security.
Software Security- Using multiple, well defined modules allows us to implement ‘separation of concerns’ into our architecture and lets us quickly diagnose and fix problems.
Efficiency- Relying on a smaller, Mixture of experts style setup instead of letting bigger models do everything reduces our costs dramatically, allowing us to do more with less.
Flexibility- The best architecture is useless if it can’t fit into your client's processes. Being Lawyer-Led, IQIDIS understands the importance of working within a lawyer’s/firm's workflow. Splitting into the different components allows us to replace/modify pieces very quickly without too many problems (even move the entire setup within a secure environment for additional security).
No Hallucinations- Given how important hallucinations are, we break them down into various sub-hallucinations and tackle each family individually. In the legal context- we might have Hallucinations of fake case citations, for which we need to improve retrieval of information and use a generator that complies with our input contexts. We also have hallucinations of wrong analysis ( here, the case exists but doesn’t say what we want). -This has to be fixed by lawyer refinement and in the reranking stage.
The second bleeds into output quality issues as well (“AI Tool X sucks because it doesn’t match the style we need”). This is something that groups don’t account for. They try to blanket two very different problems into the same umbrella- which causes conflicted training signals, making the process more inefficient.
Let’s study the individual components in more detail.
Indexes (and Embeddings)
I’ll group embeddings and Indexes for this discussion since we looked at them together to improve our search performance.
Indexes are key in helping us search through large amounts of data quickly. We combine multiple indexing techniques to balance the tradeoff between cost and semantic matching. This combination of indexes is used to store most knowledge/data is stored/accessible in the indexed nodes. This is very different from the fine-tuning heavy approach of modern specialized Gen-AI solutions, where the knowledge is stored in the parameters LLMs.
There are various advantages to this. Firstly, by using indexes, we can switch between data sources easily. This reduces the chances of our picking the wrong case or making up a case because our platform got confused with conflicting information- something our competitors struggle with. To quote Stanford’s “Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries”-
In a new preprint study by Stanford RegLab and HAI researchers, we put the claims of two providers, LexisNexis (creator of Lexis+ AI) and Thomson Reuters (creator of Westlaw AI-Assisted Research and Ask Practical Law AI)), to the test. We show that their tools do reduce errors compared to general-purpose AI models like GPT-4. That is a substantial improvement and we document instances where these tools provide sound and detailed legal research. But even these bespoke legal AI tools still hallucinate an alarming amount of the time: the Lexis+ AI and Ask Practical Law AI systems produced incorrect information more than 17% of the time, while Westlaw’s AI-Assisted Research hallucinated more than 34% of the time.
- By searching indexed data, we remove the possibility of making up cases.
Secondly, fine-tuning on a lot of data (especially any KI-data) can be very expensive. OpenAI has a program for custom models for organizations, but it requires a billion tokens minimum and costs millions of dollars (lower limit)-

This is also probably why some of the big and shiny new players on the market have had to go for very large fund-raising rounds. Constantly having to fine-tune updated regulations, changing best practices, etc, will eat away at your computational budget very quickly.

Indexes allow us to side-step that problem. Updating the indexes with new information is much cheaper than retraining your entire AI model. Index-based search also allows us to see which chunks/contexts the AI picks to answer a particular query, improving transparency (and allowing us to adjust behaviors as needed). We can also restrict the AI to certain domains/areas by only searching the relevant indexes, providing a layer of precision you can’t get with the current LLM-based systems.
Of course, this assumes well-developed indexes, which relies on good semantic matching. The main section covers the details of our experiments with that. Let’s now discuss how we tune our various specialized AI Models.
Mixture of Experts-
Our team at IQIDIS loves the “mixture of experts” approach. It allows us to tackle the myriad of challenges a user would have very efficiently. Based on our user quality metrics earlier, we identified three kinds of tasks (the reality is a bit more fuzzy, but using harder classification helps make explainations clearer)
Sourcing- We need something to take a user query and search our indexes for important information. We can fine-tune this with user feedback to improve the quality of the citations- allowing different users to easily integrate their feedback directly into the system, following the process shown below-

Fact-Based Answers- Specialized models handle answering fact-based questions. This comes with 2 huge benefits- it’s much cheaper than fine-tuning a GPT-style decoder-only architecture, AND it won’t hallucinate on fact-based questions. It also points to sources directly improving the transparency and flexibility of the system. Google Search takes a similar approach when it throws up search cards-

Complex Generation- A generator combines multiple contexts into one coherent answer.-

The actual process of transforming user feedback into model feedback (and ultimately into system-level feedback) is one of our key innovations, but I will not talk how because beautiful people must always keep a few secrets. Just keep in mind that injecting user feedback w/o any thought at all can have consequences for the stability and convergence of your system.
BTS, we rely on an orchestrator to infer what kind of agent/what sets of agents would work best for what task. This sounds costly until you realize that it allows us to not use the most expensive model everywhere. Early iterations are also not super-difficult to set up, and then our goal is to rely on user-feedback to let our system adjust dynamically.
Our unique approach to involving the user in the generation process leads to a beautiful pair of massive wins against Hallucinations-
Type 1 Hallucinations are not a worry because our citations are guaranteed to be from the data source (and not from a model's internal knowledge, which is the source of errors).
Type 2 Hallucinations (which can’t ever be removed unless my quest to find a Genie bears fruit) will be reduced significantly through our unique process of constant refinement. Furthermore, since our system is designed to augment legal professionals (not replace them)- any errors will be easily detected and fixed on review.

This separation allows us to tackle each type of error individually, leading to more efficient training. We can also train these components for various goals without their training conflicting. For instance, creativity and accuracy are often seen at odds with each other (hence the importance of the temperature param in LLMs). Our approach allows us to let the generator focus on creativity and the sourcing models worry about accuracy- hitting the best of both worlds. This is much better than the standard approach of RLHF’ing with millions of examples- which has been shown to reduce output variety significantly.
Our flexible architecture allows us to adapt to various client requirements, including specific preferences about model usage. Since each individual model only does a very specific task, our system does not suffer performance degradation to the same extent that other systems without this specialization would suffer if they had to replace their models.
Along with this, we have a bunch of auxiliary steps that help us when needed. A reranker can be great for picking out the most important contexts, and very complicated contexts might benefit from enrichment, repacking, and summarization. These are context-dependent, and we usually make the judgment call on if they’re needed after plugging it into client data and seeing how it works.

There’s so much potential that is left on the table just in exploring how we can use the user input to eventually build specialized preprocessing techniques that will significantly boost performance without needing costlier setups. An example that I am interested in, but have to study in more detail is the use of control tokens to give our users greater degree of refinement over their input prompts-
Most people only tokenize text. Our first release contains tokenization. Our tokenizers go beyond the usual text <-> tokens, adding parsing of tools and structured conversation. We also release the validation and normalization code that is used in our API. Specifically, we use control tokens, which are special tokens to indicate different types of elements.
Or-
We enhanced the DPR model by incorporating control tokens, achieving significantly superior performance over the standard DPR model, with a 13% improvement in Top-1 accuracy and a 4% improvement in Top-20 accuracy.
Transparency
A large part of KI-RAG is model transparency. Since a few trigger words/phrases can change the meaning/implication of a clause, a user needs to have complete insight into every step of the process. We’ve made great efforts to establish that, showing the users which data is pulled out of the index for a query, which ones get ranked highly, how we weigh various relationships and so on-

Because reading a wall of text is ugly and hard to edit, we allow our users to understand the relationships between various entities visually. Following is an example showing how two entities, Form 1003 and The Desktop Underwriter are linked (this was created automatically, with no supervision)-

Users can inspect multiple alternative paths to verify the quality of secondary/tertiary relationships. Here is another for the same endpoints-

By letting our users both verify and edit each step of the AI process, we let them make the AI adjust to their knowledge and insight, instead of asking them to change for the tool. It also reduces the chances of an AI making a sneaky mistake that’s hard to spot because every step of the process is laid bare.
We are developing many more refinements/features to allow our users to interact with, mold, and use IQIDIS with confidence. While our competitors are busy building expensive black boxes, we have a solution that is transparent, efficient, and performant.
I’ll share the rest of this article on some approaches that we’ve tried for each step and how things have looked. If you’d suggest some alternatives, lmk.
Indexes and Search
As mentioned, our search is based on a combination of various kinds of indexes. Let’s break it down.
As a first layer (for keyword-specific search), I’ll be basic and recommend something like BM-25. It’s robust, has worked, well for all kinds of use-cases, and will be good enough for to filter out absolutely useless contexts. I’m not in the habit of reinventing the wheel. Depending on how things play out/what kinds of data we end up dealing with- we might explore using BM25F, which extends BM25 to handle structured documents, which potentially useful for different sections of legal texts or BM25+ for longer docs/chunks. This is the part of the system we’re most confident in, although nothing is sacred, and we might come across insights that make us change our minds.
There are several ways to integrate the semantic match side. The obvious contender is DPR, and you won’t go wrong with it. Then we have some other promising contenders like-
HNSW (Hierarchical Navigable Small World)
Efficient algorithm for approximate nearest neighbor search
Extremely fast search times
Scales well to large document collections
It has a cool-sounding name, which should count for something.
Generates semantically meaningful sentence embeddings
Computationally efficient
Good for semantic similarity tasks.
Sentence-based embeddings seem to be really good for absolutely no reason (seriously, if someone can tell me why, I would really appreciate it)

Pre-trained on legal corpora
Captures domain-specific language and concepts
Can be further fine-tuned for specific legal subdomains
I like BERT Models.
We actually use this for some of our evaluations and to translate user feedback (given by lawyers, which I don’t understand) into signals that act as system feedback. This works well, so translating it into other semantic tasks is promising.

ColBERT (Contextualized Late Interaction over BERT)
Preserves context-sensitive term representations
Allows fine-grained word-level interactions between query and document
Efficient for large-scale retrieval
Performs well on passage retrieval tasks
Also BERT-based.
I remember reading something about it being very good for a base-legal search engine, but I can’t find it (I wonder if I’ve started hallucinating).
Amazing Street-Cred.
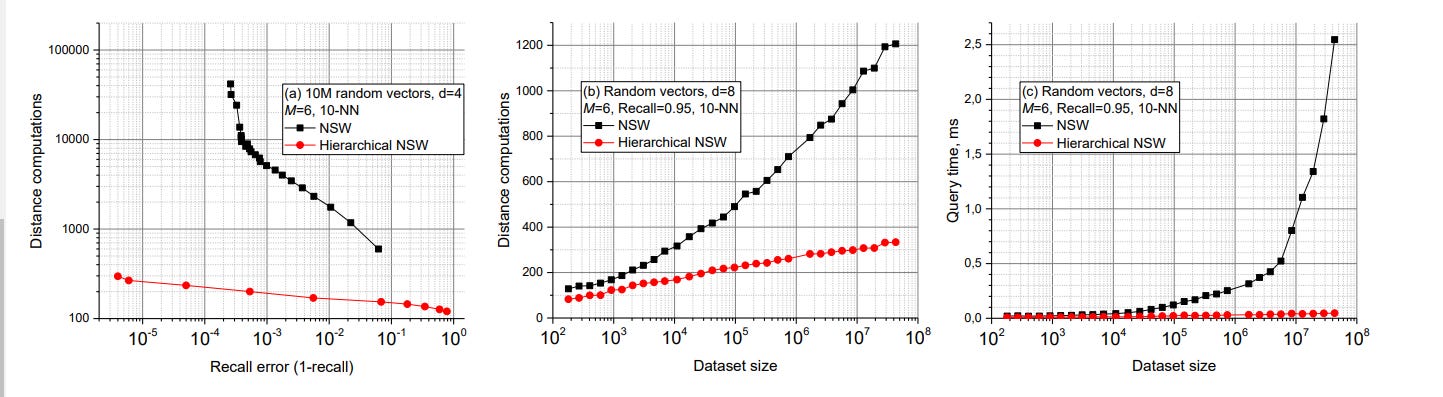
Given that we’re already working on graphs, another promising direction for us has been integrating graph-based indexes and search. Haven’t done too much of this yet, given how lean we have to be with our resources at this stage. But the approach described in, “FINGER: Fast inference for graph-based approximate nearest neighbor search”, by Amazon is worth highlighting for two reasons. Firstly, their approach is universal and can be applied to any graph constructed (since the optimization is done on the search side, not on the graph construction). Secondly, it hits some amazing numbers, “FINGER significantly outperforms existing acceleration approaches and conventional libraries by 20% to 60% across different benchmark datasets”
The secret to this performance lies in a fairly simple, but important insight- “when calculating the distance between the query and points that are farther away than any of the candidates currently on the list, an approximate distance measure will usually suffice.” Essentially, if I only want to consider top-5 similarity scores, then the exact distance of no. 6 and below is irrelevant to me. I can skip the heavy-duty distance computations in that case. I also don’t want to consider points beyond my upper-bound distance. And as it turns out after a while, “over 80 % of distance calculations are larger than the upper-bound. Using greedy graph search will inevitably waste a significant amount of computing time on non-influential operations.”
This leads Amazon to explore approximations for the distance measurement for the points further away. They finally settle on an approximation based on geometry + some vector algebra. Take a query vector, q, our current node whose neighbors are being explored, c, and one of c’s neighbors, d, whose distance from q we’ll compute next. “Both q and d can be represented as the sums of projections along c and “residual vectors” perpendicular to c. This is, essentially, to treat c as a basis vector of the space.”
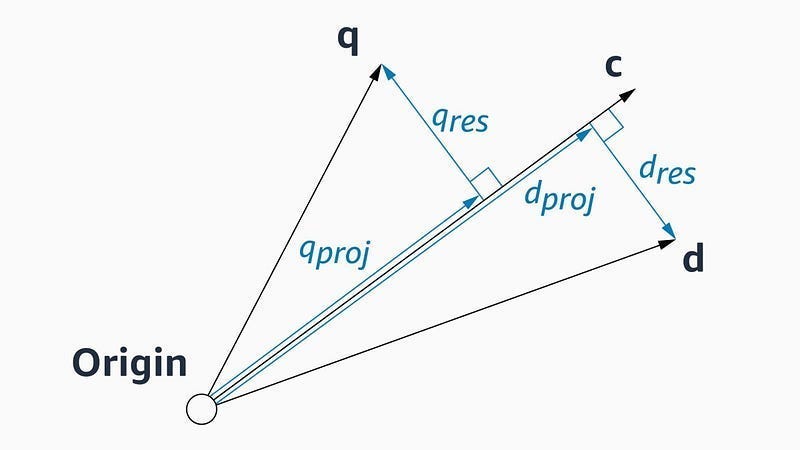
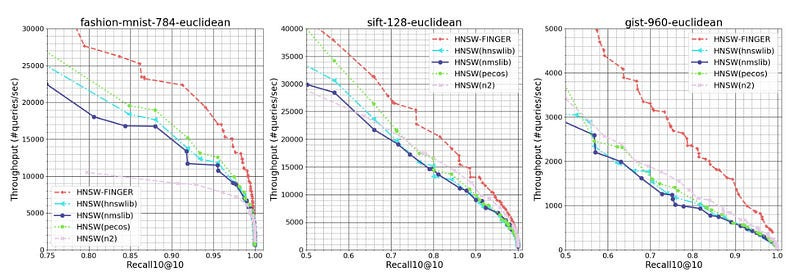
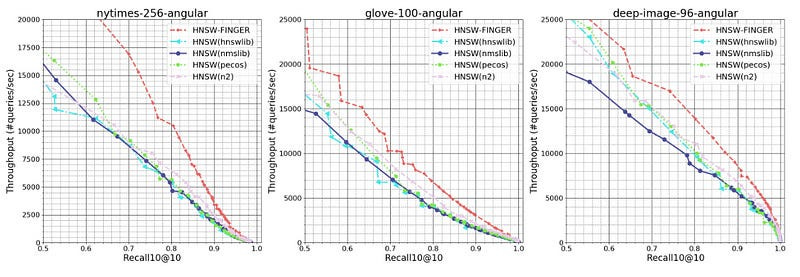
This approach works swimmingly-
To evaluate our approach, we compared FINGER’s performance to that of three prior graph-based approximation methods on three different datasets. Across a range of different recall10@10 rates — or the rate at which the model found the query’s true nearest neighbor among its 10 top candidates — FINGER searched more efficiently than all of its predecessors. Sometimes the difference was quite dramatic — 50%, on one dataset, at the high recall rate of 98%, and almost 88% on another dataset, at the recall rate of 86%.
It’s a neat approach, makes sense to me, and would complement the results well. So it’s high on my priority on list for experiments.
Another high-priority approach would be look into other kinds of embeddings to capture semantic nuance better. This is an approach that seeks to handle a a critical limitation of the cosine similarity function (used a lot in NLP): saturation zones. When two embeddings are highly similar or dissimilar, the cosine function’s gradient becomes very small. This can lead to vanishing gradients during optimization, making it difficult to learn subtle semantic distinctions between text embeddings.
For supervised STS (Reimers & Gurevych, 2019; Su, 2022), most efforts to date employed the cosine function in their training objective to measure the pairwise semantic similarity. However, the cosine function has saturation zones, as shown in Figure 1. It can impede the optimization due to the gradient vanishing issue and hinder the ability to learn subtle distinctions between texts in backpropagation. Additionally, many STS datasets such as MRPC 1 and QQP 2 provide binary labels representing dissimilar (0) and similar (1), which naturally fall within the saturation zone of the cosine function.
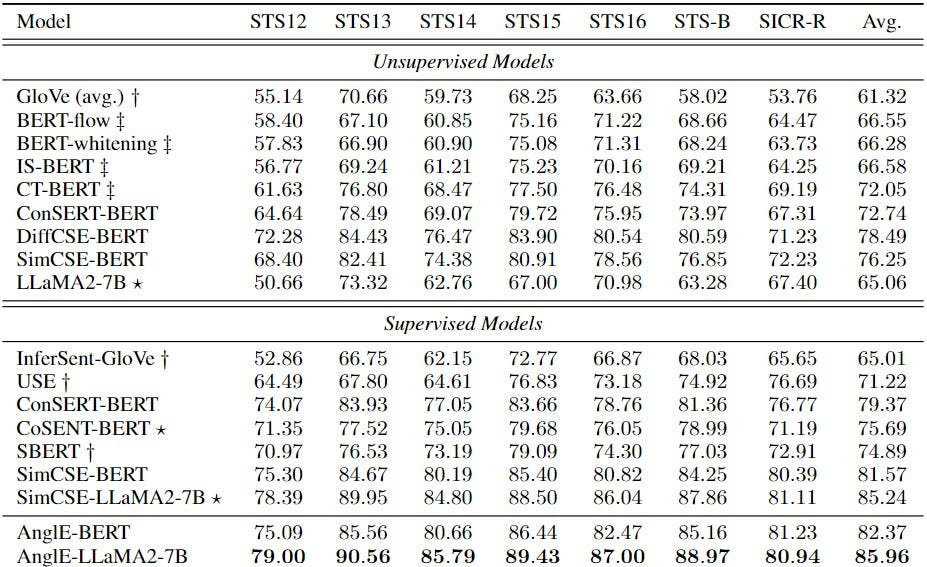
The “AnglE-optimized Text Embeddings” paper addresses this challenge with AnglE, a text embedding model that optimizes angle differences in complex space. “It optimizes not only the cosine similarity between texts but also the angle to mitigate the negative impact of the saturation zones of the cosine function on the learning process. Specifically, it first divides the text embedding into real and imaginary parts in a complex space. Then, it follows the division rule in complex space to compute the angle difference between two text embeddings. After normalization, the angle difference becomes an objective to be optimized. It is intuitive to optimize the normalized angle difference, because if the normalized angle difference between two text embeddings is smaller, it means that the two text embeddings are closer to each other in the complex space, i.e., their similarity is larger.” This was demonstrated in the figure shown in the highlights-

The results end up resulting- “On the other hand, AnglE consistently outperforms SBERT, achieving an absolute gain of 5.52%. This can support the idea that angle-optimized text embedding can mitigate the negative impact of the cosine function, resulting in better performance.” AnglE ends up improving LLMs, “It is evident that AnglE-BERT and AnglE-LLaMA consistently outperform the baselines with a gain of 0.80% and 0.72% in average score, respectively, over the previous SOTA SimCSE-BERT and SimCSE-LLaMA.”
Very cool.
AnglE’s superiority in transfer and non-transfer settings, its ability to produce high-quality text embeddings, and its robustness and adaptability to different backbones
This would be great for very dense texts where inches of difference have miles of impact. Which Law happens to be.
These are the main aspects of the text-based search/embedding that are promising based on research and our own experiments. Ultimately, the final result depends on the protocol that adapts best to your/your clients data, which can be one, two, or none of the approaches discussed. There’s too much variance in this process, so I’d be lying if I said that there is one definitive approach (or that what we’ve done is absolutely the best approach). What I can promise you is that our team is obsessed with listening to users- and we’ve designed our system to be very flexible to quickly be fit into their workflow.
I’ve spent a long time experimenting and discussing our research into indexing and embeddings for two important reasons-
Good embeddings/indexing has very good ROI- which is important for us at this stage. We rely on this (and our detailed internal evaluations) to drive our performance improvements in a cost-effective way. It also has a pretty good carryover of our focus on user feedback, model transparency, and general AI Safety.
It would be better to discuss the orchestration in a separate article on Agentic RAG- where we spend more time talking splitting roles between agents and about how to translate user queries into an interpretable set of instructions for them.
At the moment, we’re keeping our Agent system very low-key to save on cost and to focus on the user-feedback. But building upon this is a priority after our next round of fund-raising (or for any client that specifically requests this).
For now, if what we’re doing interests you, shoot us a message at info@iqidis.ai. We’ve gotten phenomenal early user feedback and are now actively looking to expand with partnerships and funding. The Legal AI space is difficult for anyone to crack but our unique mixture of Lawyer Led Development, extremely flexible architecture, and technical skill gives us a really good shot.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819