


Unlocking Gen AI at the Edge: Speeding up Transformers by 80% by Removing Self Attention
A deep dive into FNet, FFT-based mixing, and why the future of AI might belong to fixed-structure models that don’t even try to learn what they can encode.

It takes a lot to create work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
The Transformer architecture, powered by self-attention, dominates modern AI. Yet, its core mechanism carries a steep computational price, scaling quadratically with sequence length and creating bottlenecks.

FNet, a Transformer variant from Google Research, offers a radical alternative: it completely removes self-attention and replaces it with a standard, parameter-free Fourier Transform. The surprising result? FNet achieves up to 97% of BERT’s accuracy on standard NLP benchmarks while training 70–80% faster, demonstrating remarkable efficiency, especially on long sequences.
This research isn’t just academic. By proving that a fixed transform like the Fast Fourier Transform (FFT) can replace costly attention layers, FNet directly challenges the economics of large models. It suggests that the expensive, adaptive mixing of attention is unnecessary overhead for many tasks. In my mind, this is especially important for
This efficiency translates directly into market dynamics and strategic bets.
Short-Term (~$50–100M unlocks, increasing 100–300M when we consider synergies): FNet slashes inference costs. This immediately benefits startups deploying NLP models in latency-sensitive areas (fintech, logistics, real-time UX) or on resource-constrained edge devices. Companies offering AI infrastructure can leverage FNet to provide cheaper, faster alternatives for classification and embedding tasks, improving margins and expanding market reach. It makes “good enough” AI dramatically more accessible.
Long-Term (~$2–5B disruption): This signals a shift away from monolithic, attention-heavy models. If efficient, structured mixers like FFT become standard, it enables new categories like low-power LLMs and truly ubiquitous on-device intelligence. Crucially, it erodes the moat of large API providers whose value relies partly on managing the complexity of attention at scale. It also pressures GPU-centric infrastructure plays by demonstrating that architectural innovation can bypass brute-force compute scaling.
Research like this is likely why Nvidia started shipping out their pocket super-computers to reduce their over-reliance on Hyper-scalers. The future of AI looks to be distributed and decentralized, both in the driver of innovation (the Open Source Movement) and now even in the concrete engineering/applied research trends.
On another note, this kind of research should trigger Jevons’ Paradox for Agentic AI and MoE since it should make it easier for more people to build those systems. I imagine FNet-inspired models can be great, simple worker models, or even lower-level orchestration bots for simpler coordination of agents. Here, their lower capacity isn’t as much of a problem, and the performance should still deliver.
To put it in a simpler way, this approach might never run as fast as your wonderfully engineered perfect transformers, but it is has the potential to be fast enough to outrun all many of the fat kids in the edge deployment space (using a fat kid analogy to represent lean edge-AI is why I am a creative genius of the highest category). Thus, it can still become a powerful player in the space (much of AI is about outrunning the fat kids until you find your space).

If I were an Investor, here’s how I would try to take advantage-
Fund inference optimization: Back companies building runtimes that excel with FFTs, sparsity, and modular architectures — not just bigger matrix multipliers. There’s a huge boom in the good research going on here, so the field is poised to do very well (it helps that costs are one of the highest concerns for any GenAI team). My favorite startup in this space is Clika, an early-stage model compression company. See my other favorite early-stage startups here.
Target latency-critical applications: Invest where speed and cost unlock markets previously inaccessible to heavy models. A lot of simpler Robotics looks to be primed to have a field day. I’m particularly interested in how this can be put into predictive maintenance, disaster recovery, and Quantum Computing.
All of this requires massive orchestration. Trends like MCPs, DeepSeek’s library for MoE, and other developments can make implementation much easier. Not sure if entire startups can be built here given how premature this ecosystem is, but I would at least push every portfolio company to actively spend some time monitoring and building in this space. The returns for pushing the space towards your goals is massive, and it’s easier given how nascent it is.
This article breaks down the FNet architecture, analyzes its performance, and explores the deeper implications of replacing attention with one of signal processing’s oldest tools.
Before we get into nerd stuff, here is a quick overview of the impacts. I’m going to group this within the larger “Enablement for AI at the Edge” technologies-

You’re on this side of the table, so clearly you like what you see. Let’s dance with the math to understand how it works.
Most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder with a standard, unparameterized Fourier Transform achieves 92–97% of the accuracy of BERT counterparts on the GLUE benchmark, but trains 80% faster on GPUs and 70% faster on TPUs at standard 512 input lengths. At longer input lengths, our FNet model is significantly faster: when compared to the “efficient Transformers” on the Long Range Arena benchmark, FNet matches the accuracy of the most accurate models, while outpacing the fastest models across all sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finally, FNet has a light memory footprint and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models outperform Transformer counterparts
Executive Highlights (TL;DR of the Article)
We’ll talk about the following-
The Problem with Attention: Standard Transformer self-attention is powerful but computationally brutal. Its core mechanism requires comparing every token pair, leading to O(N²) compute and memory scaling with sequence length (N). This makes processing long documents extremely expensive, limits deployment on resource-constrained hardware, and acts as a major bottleneck for both training and real-time inference.
How Attention Works: Attention allows each token to dynamically weigh the importance of all other tokens. It produces a context-rich, adaptively mixed representation for each token. Multi-head attention repeats this process in parallel for added complexity and capacity. Our main section will cover the math that enables this (image taken from the GOAT
)-
FNet’s Alternative — FFT: FNet boldly replaces the entire attention mechanism with a standard Discrete Fourier Transform (DFT). This decomposes the sequence into frequency components, providing global context through a fixed, parameter-free mathematical structure.
The Core Tradeoff: The choice boils down to learned flexibility versus structural efficiency. Self-Attention offers high adaptability, allowing the model to learn intricate, input-specific token relationships, but at a steep quadratic cost. FNet (FFT) offers massive computational savings (O(N log N), no parameters in mixing) by using a fixed, universal mixing pattern based on frequency analysis, sacrificing the ability to adapt the mixing strategy per input.
Performance Breakdown
FNet delivers a compelling efficiency-accuracy profile:
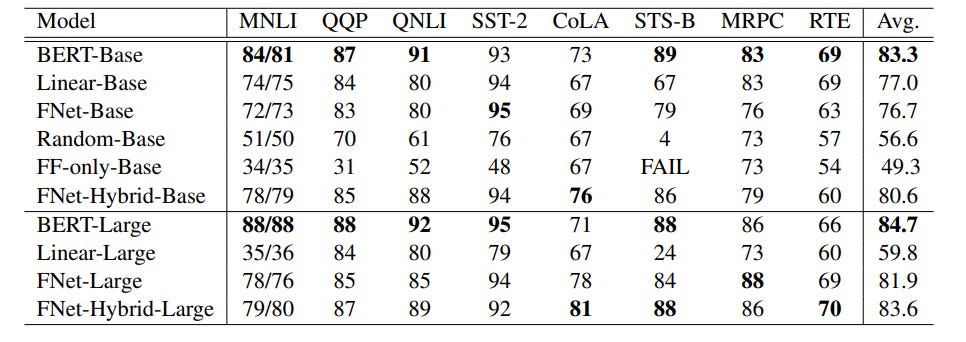
Accuracy: Pure FNet reaches ~92–97% of BERT’s accuracy on GLUE. While a gap exists, it proves viability.
Hybrid Success: Adding just two attention layers back (FNet-Hybrid) recovers most of the accuracy gap (97–99% of BERT’s), demonstrating a powerful synergy between fixed FFT mixing and targeted attention.
Speed & Memory: FNet drastically cuts computational cost. It trains 70- is a global mixing of information based on mathematical structure, requiring no learned parameters in the mixing step itself.
Long Sequences (LRA): FNet matches top efficient Transformers in accuracy on long-context tasks and is significantly faster and lighter than all competitors on GPUs across tested sequence lengths.
Ablations & Edge Cases
Experiments confirmed FNet’s design choices:
Mixing is Essential: Removing mixing entirely (FF-only) fails completely.
Structure Matters: Random mixing underperforms; the mathematical structure of FFT provides a strong, useful inductive bias.
FFT/Hartley are Effective: Among tested transforms (DCT, Hadamard, Hartley), FFT and the related Hartley transform performed best, suggesting frequency-domain analysis is well-suited for language.
Learnable FFT Doesn’t Help: Attempts to add parameters to the FFT layer itself degraded performance or offered no benefit, indicating the fixed structure is near-optimal for its mixing role.

2D Mixing is Better: Applying FFT across both sequence and hidden dimensions yields better results than mixing only along the sequence.
I think research along this direction will be key to AI’s larger mainstream adoption. Historically, large scale disruption from a technology comes from delivering existing technology with 20–30% lower functionality but 10x lesser cost- since this enables research and opens up use for the masses. And this is very much in that mold-
A key idea of disruption is that it’s not based on new technologies, it’s based on old technologies delivered in a cheaper way, targeted at a new set of customers. The cloud took an existing industry (enterprise-level hardware and software), created a new business model that lowered the barrier of entry to that technology, and sold it to a new market of companies (mostly technology startups).
The cloud’s importance came from the lowering of the barrier to entry. Prior to the cloud, companies had high upfront costs for computing power and lower maintenance costs over time. Lowering this upfront cost significantly expanded the market for computing power. This was most evident in startups, who could much more efficiently access computing power and build software. Those startups then delivered a funnel effect to the cloud providers. As cloud software generated billions of dollars in revenue, the hyperscalers collected a large % of that revenue. Over time, enterprises moved to the cloud as well. We’re still seeing the long tail of cloud migrations, nearly 20 years after AWS’ launch.
The main article will contain the following-
The Elephant in the Room: Why Attention Needs an Alternative
Attention’s Power and the O(N²) Cost
Economic and Practical Bottlenecks
Deconstructing the Incumbent: Self-Attention Under the Hood
Mechanism Explained: Query, Key, Value, Dot-Product, Softmax
What Attention Buys: Adaptability and Dynamic Context
The Real Cost: Compute, Memory, Complexity
The Core Assumption FNet Challenges
The Challenger: Structured Mixing via Fourier Transforms (FFT)
The FFT Mindset: From Relationships to Resonance
DFT: The Math of Frequencies
FFT: The Algorithmic Masterstroke (Divide-and-Conquer, Twiddle Factors)
What FFT Gives You: Efficiency, Global Context, Structural Bias
FNet Architecture: How FFT Replaces Attention in the Block
Minimalist Substitution in the Encoder Layer
The 2D FFT Mixer Operation
Why Only the Real Part? Pragmatism.
Synergy with the Feed-Forward Network (FFN)
Let’s take it down, one step at a time.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
2. The Elephant in the Room: Why Attention Needs an Alternative
Self-attention is the engine that powered the Transformer revolution. Its ability to dynamically weigh the importance of different tokens allows models to capture complex, long-range dependencies in data, unlocking state-of-the-art performance across NLP and beyond. For any given token, attention calculates how relevant every other token in the sequence is, creating a rich, context-aware representation. This mechanism effectively solved the limitations of previous sequence models like RNNs, which struggled to maintain information over long distances.

But this power comes at a steep, often prohibitive, cost. The core operation of self-attention requires comparing every token to every other token. This pairwise comparison fundamentally limits its scalability. Calculating and storing these attention scores incurs a computational and memory cost that grows quadratically with the sequence length, denoted as O(N²).

While manageable for short sequences (a few hundred tokens), this quadratic scaling becomes a crippling bottleneck as we push towards longer contexts — processing entire documents, codebases, or high-resolution time-series data. Doubling the sequence length quadruples the compute and memory demands for the attention layers. This isn’t just a theoretical limitation; it’s a hard economic reality. It dictates the feasibility of training large models, the latency of real-time inference, the necessary hardware specifications (often requiring powerful, expensive GPUs/TPUs), and ultimately, the cost-effectiveness of deploying these models in production.
The O(N²) barrier is the primary reason why processing very long sequences efficiently remains a major challenge, gating progress in numerous applications and driving the search for more scalable alternatives. FNet enters the scene precisely to address this fundamental cost-performance constraint.
In this work, we investigate whether simpler token mixing mechanisms can wholly replace the relatively complex self-attention layers in Transformer encoder architectures. We first replace the attention sublayer with two parameterized matrix multiplications — one mixing the sequence dimension and one mixing the hidden dimension. Seeing promising results in this simple linear mixing scheme, we further investigate the efficacy of faster, structured linear transformations. Surprisingly, we find that the Fourier Transform, despite having no parameters at all, achieves nearly the same performance as dense linear mixing and scales very efficiently to long inputs, especially on GPUs (owing to the O(N log N) Fast Fourier Transform (FFT) algorithm). We call the resulting model FNet
3. Deconstructing the Incumbent: Self-Attention Under the Hood
To appreciate FNet’s radical departure, we first need to understand precisely what self-attention brings to the table and the assumptions underpinning its design. What people get wrong when discussing the math on Self Attention is that what’s important is not the matrix multiplications it does, but rather its “philosophy” about how context should be processed.
To do so, let’s remind ourselves of the formula-

and then look at why it’s created the way it was-
The Self-Attention Mechanism Explained:
Imagine each token in a sequence needs to update itself by incorporating relevant information from its neighbours (near and far). Self-attention provides a dynamic, learned way to do this. It starts by projecting each input token’s embedding into three distinct vectors:
Query (Q): Represents what this token is looking for or interested in. Think of it as the token formulating a question about the context.
Key (K): Represents what information this token offers or what kind of queries it can answer. It’s like a label or identifier for the token’s content.
Value (V): Represents the actual content or substance of the token that will be passed along if attended to. This is the payload.
The core interaction happens between Queries and Keys. For a given token’s Query, the mechanism compares it against every other token’s Key, typically using a scaled dot product. This comparison generates a raw score indicating the relevance or compatibility between the Query and each Key. A high score means the Key token is highly relevant to the Query token’s current information need.
These raw scores are then passed through a Softmax function. This step is crucial: it normalizes the scores across all tokens, turning them into a probability distribution that sums to 1. These normalized scores act as attention weights — essentially, the percentage of “attention” the Query token should pay to each Value token.
Finally, the mechanism computes a weighted sum of all Value vectors in the sequence, using the attention weights derived from the Softmax step. The result is the updated representation for the initial Query token — a new vector that has selectively blended information from across the entire sequence based on learned relevance.

What Attention Buys You:
The genius of this mechanism lies in its adaptability. The attention weights are not fixed; they are calculated dynamically based on the specific input sequence and the learned Q, K, V projection matrices. This allows the model:
Token-Dependent Context: Different tokens can attend to different parts of the sequence based on their specific role or information need.
Input-Specific Routing: The patterns of attention can change dramatically for different inputs, enabling flexible handling of syntax, semantics, and long-range dependencies.
Focus: The model can learn to ignore irrelevant tokens (assigning them near-zero weights) and focus intensely on crucial ones.
However, you gotta pay for quality, and this quality comes with a pretty hefty price tag.
The Real Cost of Self-Attention:
This sophisticated, adaptive routing is powerful but expensive.
Quadratic Compute: The Q-K comparison requires O(N²) dot products.
Quadratic Memory: Storing the N x N attention matrix for backpropagation consumes significant memory, often becoming the limiting factor for long sequences.
Implementation Overhead: Multi-head attention (running multiple attention mechanisms in parallel) adds further complexity and parameter count.
Potential Instabilities: The Softmax can saturate, and the dynamic nature of the scores can sometimes lead to training difficulties compared to more fixed operations.
Essentially, self-attention invests heavily in computing fine-grained, adaptive relevance scores for every token pair at every layer. And in a world that celebrates mediocrity and the bare minimum under the garb of efficiency, being effortless/playing it cool and “just living life”, this intense and attention-heavy approach (ha!) is too outdated. It gives AI Builders the ick by being “too much”.
All great technological developments reflect the spirit of their times (question for you- does great technology reshape society in its image, or do societal trends get reflected in the technologies it develops?), and that is where FNet gets us swooning.
How FNet Challenges Self-Attention:
The widespread adoption of self-attention rests on the implicit assumption that this level of learned, dynamic, token-specific routing is essential for high performance in sequence modeling. It presumes that a model must learn precisely which parts of the context matter most for each token, moment by moment.
FNet directly questions this assumption. It proposes that this expensive adaptability is overkill for many tasks. Maybe a less flexible, but far more efficient, method of ensuring global information mixing is sufficient, allowing the subsequent feed-forward layers to handle the task-specific feature extraction.
Essentially, do you need to have cracked stats across the board (Mighty Mouse, Volk) or can you get to a position of overwhelming dominance by repeating one main playbook extremely well (GSP, Khabib). SA bets on the former, FNet goes to the latter.
Let’s understand more about how next-
4. The Challenger: Structured Mixing via Fast Fourier Transforms (FFT)
Self-attention embodies the snowflake philosophy of treating each token as special and investing heavily to let each token decide what matters. FNet represents a profoundly different worldview. It draws inspiration from one of humanity’s greatest and proudest traditions- prejudice. Essentially, it uses a Fourier Transform to posit that language has an inherent mathematical structure, and we can achieve sufficient global mixing far more efficiently.
No need to understand every token and its contexts individually, our generalized representations on this global structure can hard carry our model well enough to get top-tier performance.
The mechanics of FT are honestly art-

How Fourier Transforms Work (high-level)
Instead of asking “Which tokens are most relevant to this one?”, the Fourier approach asks, “What are the underlying frequencies and patterns present across this entire sequence?” Think of a sequence of token embeddings less like a committee meeting (Attention) and more like a complex sound wave. The Fourier Transform decomposes that wave into its constituent sine and cosine frequencies: revealing the fundamental rhythms, periodicities, and structural components hidden within the sequence data.
Applying this to language might seem abstract, but the intuition holds: sentences have structure, rhythm, and recurring patterns. The FFT captures these global characteristics implicitly. Instead of learning connections token-by-token, it projects the entire sequence onto a basis of frequencies, providing a holistic, structured view where every output component reflects influences from all input components.
We study the fractal structure of language, aiming to provide a precise formalism for quantifying properties that may have been previously suspected but not formally shown. We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately H=0.70±0.09. Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can lead to a comprehension of the structure of text at multiple levels of granularity, from words and clauses to broader contexts and intents.
- “Fractal Patterns May Unravel the Intelligence in Next-Token Prediction”. There is a some interesting NLP Research that shows credence to this idea we discussed.
The math is worth understanding, given how much I’m bullish on Complex Numbers Based AI, and how important FTs are there.
DFT: The Math of Frequencies
The Discrete Fourier Transform (DFT) is the tool for this. For a sequence x0,...,x_(N−1) , it computes frequency components X_0,…, X_(n-1) (the (n-1) are subscripts and notice the difference in lower and upper case)-
")
Each X_k is a complex number representing the strength and phase of the k-th frequency. This formula ensures every X_k depends on all x_n, achieving global mixing. However, calculating this directly requires N sums, each with N terms, resulting in the same O(N²) complexity that plagues naive attention implementations. If DFT stopped there, it wouldn’t be a compelling alternative.
That is where FFT- Fast FT comes in.
How Fast Fourier Transform Speed up FTs
The Fast Fourier Transform (FFT), specifically algorithms like Cooley-Tukey, doesn’t change the result of the DFT, but revolutionizes its computation. It’s a classic example of divide-and-conquer. The core insight is that a DFT of size N (if N is a power of 2, for simplicity) can be broken down into two DFTs of size N/2 — one on the even-indexed inputs and one on the odd-indexed inputs.
These smaller DFTs are computed recursively. The magic happens during recombination. To reconstruct the full N-point DFT from the two N/2-point DFTs (let’s call them E_k for even and O_k for odd), you use the formula:

The critical element here is the twiddle factor, W_k = exp(-2 * pi * i * k / N).

This isn’t just a random coefficient; it’s a precisely calculated complex rotation. It represents a point on the unit circle in the complex plane, effectively phase-shifting the results from the odd-indexed sub-problem (O_k) so they align correctly with the even-indexed results (E_k) in the frequency domain of the full N-point sequence. Multiplying by W_k rotates the complex vector O_k. These rotations are mathematically inherent to the structure of the DFT, not learned parameters.
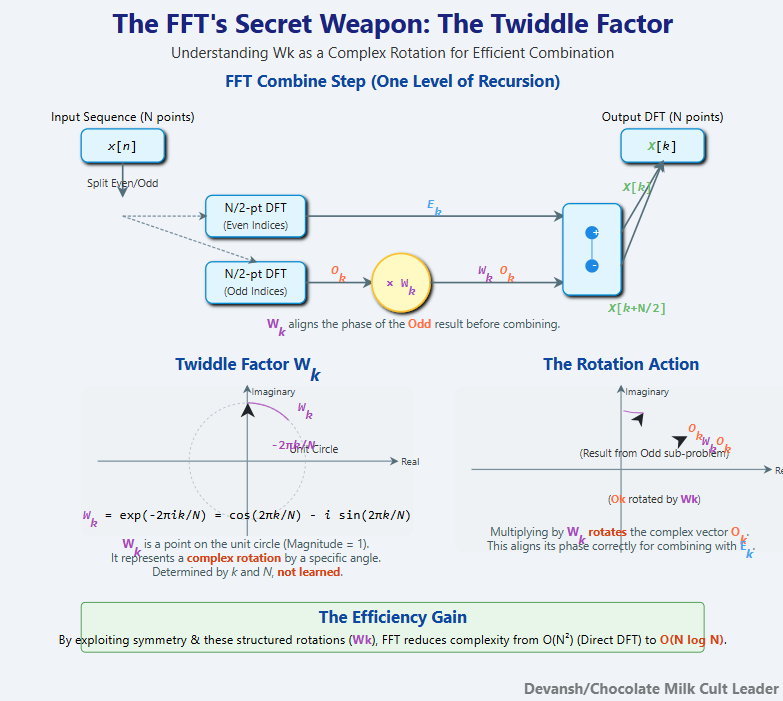
By exploiting this symmetry and the structured nature of these rotations, the FFT reduces the computational cost dramatically. Each level of recursion involves O(N) operations (for the twiddle factor multiplications and additions/subtractions), and there are logN levels. The total cost drops to O(N log N) — a huge improvement over O(N²).
What FFT Gives You:
This algorithmic efficiency makes the Fourier approach viable. FNet leverages the FFT to get:
Parameter-Free Mixing: The transformation is fixed by mathematics, not learned weights.
Global Context: Every output element is a function of all inputs.
Structural Bias: It inherently captures periodicities and frequency patterns.
Computational Efficiency: O(N log N) complexity and highly optimized hardware implementations (especially on GPUs).
FNet bets that this structured, efficient, global mixing provides a sufficient foundation for the subsequent feed-forward layers to extract meaning, sidestepping the costly adaptability of attention entirely. It champions mathematical structure over learned flexibility.
If they weren’t accurate, stereotypes wouldn’t exist :))
Having established the contrasting philosophies of attention and FFT-based mixing, let’s see how FNet integrates this Fourier approach into the familiar Transformer encoder structure. It’s surprisgly easy-

5. FNet Architecture: How FFT Replaces Attention in the Block
As shown in the image above, the multi-head self-attention sublayer is entirely removed and replaced by the FFT-based mixing operation. Crucially, the surrounding components — the residual connections (Add), the layer normalization (Norm), and the position-wise Feed-Forward Network (FFN) — remain largely unchanged.
Speaking in more detail, we must first discuss the following-
The 2D FFT Mixer in Action:
The “Fourier Transform Mixer” block takes the input token embeddings (a matrix of size sequence_length x hidden_dimension) and applies the FFT operation across both dimensions:
FFT along the hidden dimension: This mixes information within each token’s embedding vector, capturing relationships and patterns across the feature space.
FFT along the sequence dimension: This mixes information across different tokens, capturing global context, positional patterns, and long-range dependencies based on frequency components.
The order doesn’t strictly matter mathematically, but applying it across both ensures comprehensive mixing of all available information.

I found one design decision very interesting, and a great opportunity for future attacks-
Keeping it Real
After the 2D DFT/FFT computes the complex-valued frequency representation, FNet takes only the real part of the result:
Output = Real( FFT_seq( FFT_hidden( Input ) ) ) (equation 3 w/o the weird symbols)
This isn’t necessarily because the imaginary part contains no useful information (it encodes phase). Instead, it’s a pragmatic design choice. Standard deep learning components like LayerNorm and the typical FFN (often using GELU or ReLU activations) are designed to work with real numbers. Discarding the imaginary part avoids the need to modify these subsequent layers to handle complex arithmetic, keeping the overall architecture simpler and compatible with existing hardware and software optimization routines.
Experiments in the paper confirmed that simply taking the real part yielded the best empirical results compared to using magnitude or other combinations. However, I think if people invest into switching from Real Numbers to Complex Valued NNs, I think the results will be higher-

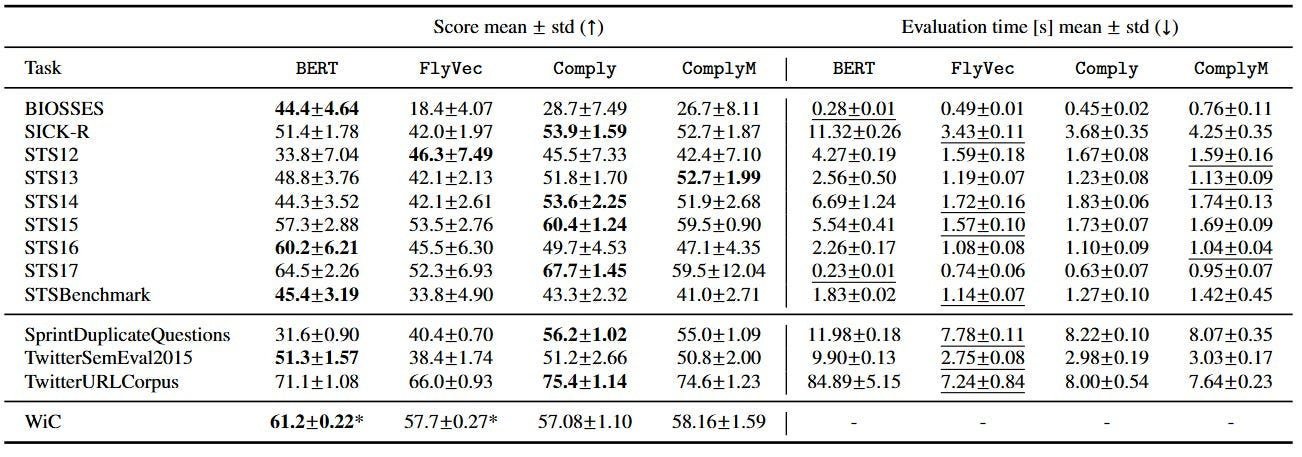
When I first started covering Complex-Valued Neural Networks, this seemed like speculation. However, I think isn’t as far-feteched any more. Earlier this month, we covered Comply, which uses Complex Encodings inspired by Fruit Flies (for reals) to outperform standard encodings at fractions of the cost-
Finally, this is speculation by me, but I think it’s worth discussing-
Synergy with the Feed-Forward Network (FFN): The Unsung Hero?
It’s critical to recognize that the FFT mixer doesn’t work in isolation. The standard FFN sublayer, which typically consists of two linear transformations with a non-linear activation function in between (e.g., GELU), plays a vital role.
The FFT mixer provides efficient, structured, global linear mixing. It ensures all parts of the input sequence influence each other.
The FFN then applies a non-linear transformation independently to each token’s mixed representation. This is where the model learns complex features, abstractions, and task-specific logic based on the globally mixed information provided by the FFT step.
FNet’s success suggests that perhaps the power of Transformers relies significantly on this potent combination: an effective global mixing mechanism (which doesn’t have to be attention) followed by strong, independent non-linear processing at each token position via the FFN. The FFN might be doing more heavy lifting in interpreting context than previously assumed (it might’ve just been me that was sleeping on the FFN side), provided it receives a sufficiently rich, globally mixed input.

Conclusion
The success of FNet, particularly its dominance in long-sequence benchmarks on GPUs and the effectiveness of FNet-Hybrid models, suggests that the expensive, adaptive routing of attention might be overkill for a significant portion of language understanding tasks. Global context mixing appears to be the more fundamental requirement, and attention is just one — albeit powerful — way to achieve it. FNet proves that structured linear transforms, when coupled with capable non-linear layers like the standard Transformer FFN, provide a potent and vastly more efficient alternative.
This has immediate practical implications. FNet offers a compelling path towards lighter, faster models suitable for edge deployment, latency-sensitive applications, and processing extremely long sequences where attention becomes computationally infeasible. It lowers the barrier to entry for deploying sophisticated NLP capabilities.
More profoundly, FNet shifts the architectural discourse. Instead of focusing solely on better approximations of attention, it opens the door to exploring entirely different classes of mixing mechanisms rooted in mathematical structure rather than learned parameters. This is exciting b/c it will push research in all kinds of new directions. I’m excited to see where this leads.
If you want to keep up with this, you’ll need to get good at Math. Check out the guide below if you’re interested in learning how you can teach yourself math, and what topics you need-
What Math do you need to be Good at AI

Based on the messages I get, people trying to get into AI are trapped in the paradox of choice-

Thank you for being here, and I hope you have a wonderful day.
Living at the edge,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Fascinating read—and a compelling case for FNet’s role in the future of efficient inference. But I wonder if what we’re witnessing isn’t a replacement of self-attention so much as its redistribution across a tiered architecture. In constraint-rich edge environments, fixed-structure models like FNet shine as high-speed intake layers—but their strength is also their boundary. The absence of adaptive context binding may limit resilience when asymmetry strikes.
There’s a case to be made for coupling these encoders with recursive agents downstream: systems that selectively intervene when novelty, ambiguity, or deviation from encoded priors emerges. In that sense, FNet isn’t the brain—it’s the nervous system. What’s missing is the cortex that knows when to listen harder.
Curious if you’ve considered this kind of hybrid layering in your vision of the edge.
this is a great article. good work. i love this idea. i spent most of my phd in the frequency domain so to speak - this fractal structure of language is very cool thing to think about. im seeing that this works out of the box by exploiting some of this natural structure in language and getting better performance means achieving higher order corrections via whatever tricks. its reminding me somehow of the esoteric renormalization group which i spent a bit of time thinking about. exciting stuff